Ustawienia
A-Parser zawiera następujące grupy ustawień:
- Global Settings - podstawowe ustawienia programu: język, hasło, parametry aktualizacji, liczba aktywnych zadań
- Config Presets - ustawienia wątków i metod usuwania duplikatów dla zadań
- Parser Presets - możliwość skonfigurowania każdego pojedynczego scrapera
- Ustawienia sprawdzania proxy - liczba wątków i wszystkie ustawienia dla proxycheckera
- Advanced Settings - opcjonalne ustawienia dla zaawansowanych użytkowników
- Task presets - zapisywanie zadań do późniejszego wykorzystania
Wszystkie ustawienia (oprócz ogólnych i dodatkowych) są zapisywane w tzw. presetach - zestawach wcześniej zapisanych ustawień, na przykład:
- Różne presety ustawień dla scrapera
 SE::Google - jeden do scrapowania linków z maksymalną głębokością 10 stron, drugi - do oceny konkurencji dla zapytania, głębokość scrapowania 1 strona
SE::Google - jeden do scrapowania linków z maksymalną głębokością 10 stron, drugi - do oceny konkurencji dla zapytania, głębokość scrapowania 1 strona - Różne presety ustawień proxycheckera - osobne dla proxy HTTP i SOCKS
Dla wszystkich ustawień istnieje preset domyślny (default), którego nie można zmienić; wszystkie zmiany muszą być zapisywane w presetach z nowymi nazwami.
Ustawienia ogólne
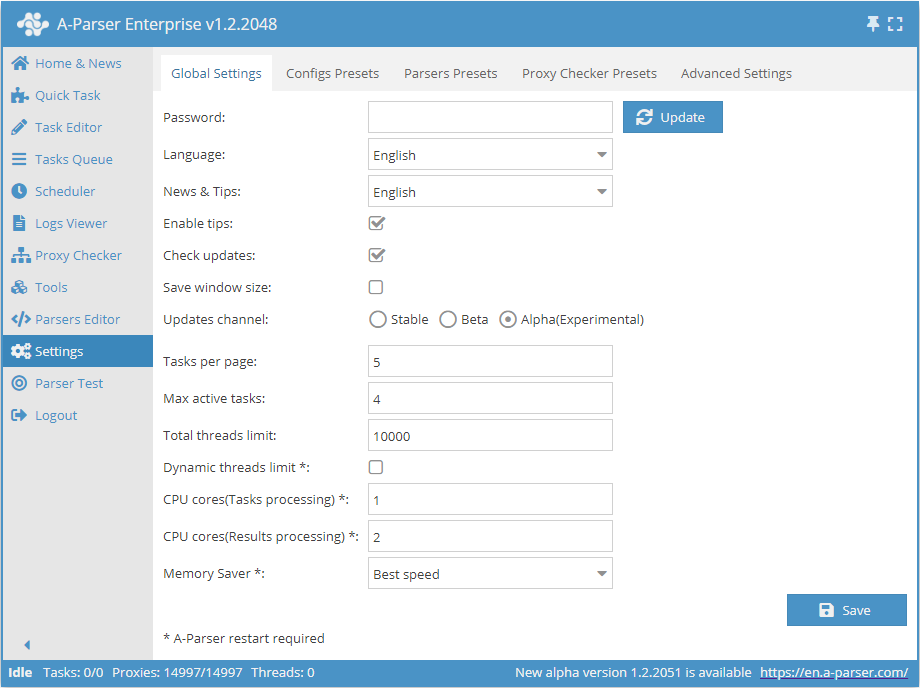
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Password | Brak hasła | Ustaw hasło dostępu do A-Parsera |
| Language | English | Język interfejsu |
| News & Tips | English | Język aktualności i podpowiedzi |
| Enable tips | ☑ | Określa, czy wyświetlać podpowiedzi |
| Check updates | ☑ | Określa, czy wyświetlać informacje o dostępności nowej aktualizacji w Pasku statusu |
| Save window size | ☐ | Określa, czy zapisywać rozmiar okna |
| Updates channel | Stable | Wybór kanału aktualizacji (Stabilny, Beta, Alfa) |
| Tasks per page | 5 | Liczba zadań na stronę w Kolejce zadań |
| Max active tasks | 1 | Maksymalna liczba aktywnych zadań |
| Total threads limit | 10000 | Ogólny limit wątków w A-Parserze. Zadanie nie uruchomi się, jeśli ogólny limit wątków jest mniejszy niż liczba wątków w zadaniu |
| Dynamic thread limit | ☐ | Określa, czy używać Dynamicznego limitu wątków |
| CPU cores (task processing) | 2 | Wsparcie dla przetwarzania zadań na różnych rdzeniach procesora (tylko dla licencji Enterprise). Szczegóły opisano poniżej |
| CPU cores (result processing) | 4 | Wiele rdzeni jest używanych tylko przy filtrowaniu, Konstruktorze wyników, Parse custom result (wszystkie typy licencji) |
| Memory Saver | Best speed | Pozwala określić, jak dużo pamięci może używać scraper (Best speed / Medium memory usage / Save max memory). Więcej... |
Rdzenie CPU (przetwarzanie zadań)
Wsparcie dla przetwarzania zadań na różnych rdzeniach procesora, ta funkcja jest dostępna tylko dla licencji Enterprise
Ta opcja przyspiesza (wielokrotnie) przetwarzanie kilku zadań w kolejce (Settings -> Max active tasks), przy czym w żaden sposób nie przyspiesza wykonywania pojedynczego zadania
Zaimplementowano również inteligentną dystrybucję zadań na rdzenie robocze na podstawie obciążenia CPU każdego procesu Liczba używanych rdzeni procesora jest określana w ustawieniach, domyślnie - 2, maksymalnie - 32
Podobnie jak w przypadku wątków, wybór liczby rdzeni najlepiej przeprowadzić drogą eksperymentalną; rozsądne będą wartości 2-3 rdzenie dla procesorów 4-rdzeniowych, 4-6 dla ośmiordzeniowych itd. Należy wziąć pod uwagę, że przy dużej liczbie rdzeni i ich dużym obciążeniu może wystąpić 100% obciążenie głównego procesu sterującego (aparser/aparser.exe), przy którym dalsze zwiększanie procesów do przetwarzania zadań spowoduje jedynie ogólne spowolnienie lub niestabilną pracę. Warto również pamiętać, że każdy proces przetwarzania zadań może generować dodatkowe obciążenie do 300% (tj. obciążać po 100% jednocześnie 3 rdzenie), co jest związane z wielowątkowym przetwarzaniem odśmiecania pamięci (garbage collection) w silniku JavaScript v8
Ustawienia wątków
Praca A-Parser opiera się na zasadzie wielowątkowego przetwarzania danych. Scraper równolegle wykonuje zadania w oddzielnych wątkach, których liczbę można elastycznie zmieniać w zależności od konfiguracji serwera.
Opis działania wątków
Przyjrzyjmy się, czym są wątki w praktyce. Załóżmy, że musisz sporządzić raport za trzy miesiące.
Wariant 1
Możesz sporządzić raport najpierw za 1. miesiąc, potem za 2., a następnie za 3. To przykład pracy jednowątkowej. Zadania są rozwiązywane po kolei.
Wariant 2
Zatrudnić trzech księgowych, z których każdy będzie sporządzał raport za jeden miesiąc. Następnie, po otrzymaniu wyników od całej trójki, sporządzić raport ogólny. To przykład pracy wielowątkowej. Zadania są rozwiązywane jednocześnie.
Jak widać z tych przykładów, praca wielowątkowa pozwala wykonać zadanie szybciej, ale jednocześnie wymaga więcej zasobów (potrzebujemy 3 księgowych zamiast 1). Analogicznie działa wielowątkowość w A-Parserze. Załóżmy, że musisz scrapować informacje z kilku linków:
- przy jednym wątku aplikacja będzie scrapować każdą stronę po kolei
- przy pracy w wielu wątkach każdy będzie przetwarzał swój link, a po jego zakończeniu przystąpi do kolejnego nieprzetworzonego na liście
W ten sposób w drugim wariancie całe zadanie zostanie wykonane znacznie szybciej, ale wymaga to więcej zasobów serwera, dlatego zaleca się przestrzeganie Wymagań systemowych
Konfiguracja wątków
Konfiguracja wątków w programie A-Parser odbywa się oddzielnie dla każdego zadania, w zależności od parametrów wymaganych do jego wykonania. Domyślnie dostępne są 2 konfiguracje wątków: na 20 i 100 wątków, odpowiednio dla default i 100 Threads.
Aby przejść do ustawień wybranej konfiguracji, należy kliknąć ikonę ołówka ![]() , po czym otworzą się jej ustawienia.
, po czym otworzą się jej ustawienia. 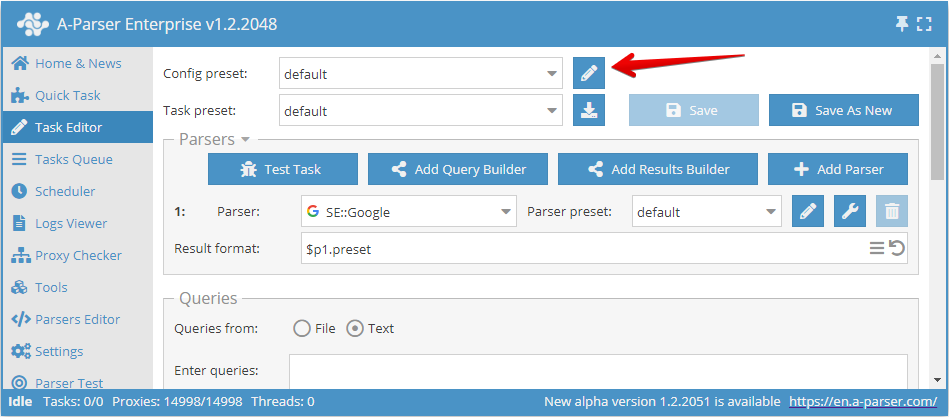
Można również przejść do ustawień wątków poprzez punkt menu: Settings -> Config Presets
Tutaj możemy:
- utworzyć nową konfigurację z własnymi ustawieniami i zapisać ją pod własną nazwą (przycisk Dodaj nowy)
- wprowadzić zmiany w istniejącej konfiguracji, wybierając ją z listy rozwijanej (przycisk Zapisz)
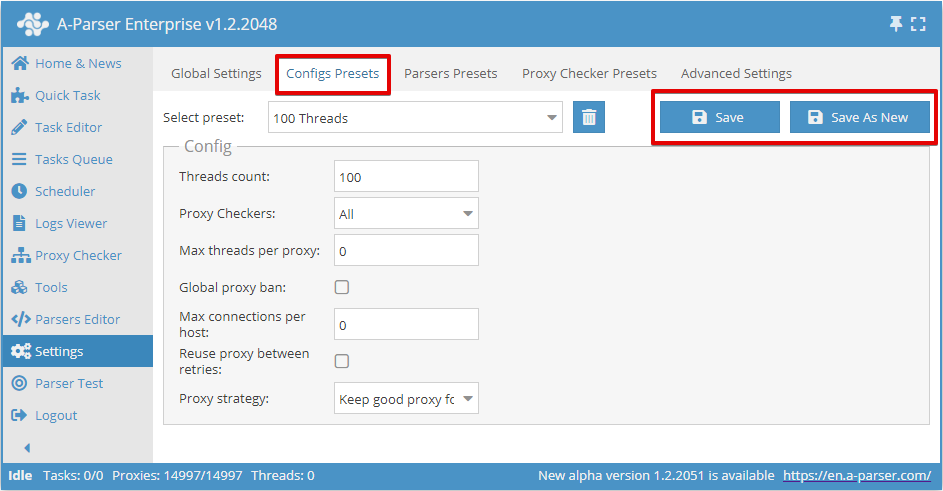
Liczba wątków (Threads count)
Ten parametr określa liczbę wątków, w których będzie pracować zadanie uruchomione z tą konfiguracją. Liczba wątków może być dowolna, ale należy wziąć pod uwagę możliwości serwera, a także ograniczenia planu proxy, jeśli takie ograniczenie przewidziano. Na przykład dla naszych proxy można wskazać nie więcej niż wybrany plan.
Ważne jest również, aby pamiętać, że całkowita liczba wątków w scraperze jest równa sumie pracujących zadań i włączonych proxycheckerów z weryfikacją proxy. Na przykład, jeśli uruchomione jest jedno zadanie na 20 wątków i dwa zadania po 100 wątków każde, a także działa jeden proxychecker, w którym włączona jest weryfikacja proxy w 15 wątkach, to łącznie A-Parser będzie używał 20+100+100+15=235 wątków. Przy tym, jeśli plan proxy jest przewidziany na 200 wątków, wystąpi wiele nieudanych zapytań. Aby ich uniknąć, należy obniżyć używaną liczbę wątków. Na przykład wyłączyć weryfikację proxy (jeśli nie jest potrzebna, zaoszczędzi to 15 wątków) i obniżyć liczbę wątków w którymś z zadań o kolejne 20 wątków. W ten sposób dla jednego z pracujących zadań należy utworzyć konfigurację na 80 wątków, a pozostałe zostawić bez zmian
Proxycheckery (Proxy Checkers)
Ten parametr umożliwia wybór proxycheckera z określonymi ustawieniami. Tutaj można wybrać parametr All, co oznacza użycie wszystkich działających proxycheckerów, lub tylko te, które mają być użyte w zadaniu (dostępny wybór wielu pozycji)
To ustawienie pozwala uruchamiać zadanie tylko z wybranymi proxycheckerami. Proces konfiguracji proxycheckera został omówiony tutaj
Maksimum wątków na jedno proxy (Max threads per proxy)
Tutaj określa się maksymalną liczbę wątków, w których jednocześnie będzie używane to samo proxy. Pozwala to na ustawienie różnych parametrów, na przykład pracy 1 wątek = 1 proxy.
Domyślnie parametr ten wynosi 0, co wyłącza tę funkcję. W większości przypadków jest to wystarczające. Jeśli jednak wymagane jest ograniczenie obciążenia każdego proxy, warto zmienić tę wartość
Globalny ban proxy (Global proxy ban)
Wszystkie zadania uruchomione z tą opcją mają wspólną bazę banów proxy. Cechą charakterystyczną tego parametru jest to, że lista zbanowanych proxy dla każdego scrapera jest wspólna dla wszystkich pracujących zadań.
Na przykład, zbanowane proxy w SE::Google w zadaniu 1 będzie również zbanowane dla SE::Google w zadaniu 2, ale jednocześnie może swobodnie pracować w  SE::Yandex w obu zadaniach
SE::Yandex w obu zadaniach
Maksimum połączeń na jeden host (Max connections per host)
Ten parametr wskazuje maksymalną liczbę połączeń na host, co ma na celu zmniejszenie obciążenia strony podczas scrapowania z niej informacji. W praktyce określenie tego parametru daje możliwość kontrolowania liczby zapytań w jednym momencie na każdą konkretną domenę. Włączenie tego parametru dotyczy zadania; jeśli uruchomisz kilka zadań jednocześnie z tą samą konfiguracją wątków, limit będzie liczony dla wszystkich zadań.
Domyślnie ten parametr ma wartość 0, czyli jest wyłączony.
Ponowne użycie proxy między próbami (Reuse proxy between retries)
To ustawienie wyłącza sprawdzanie unikalności proxy dla każdej próby, a także nie będzie działać banowanie proxy. Oznacza to z kolei możliwość użycia 1 proxy dla wszystkich prób.
Zaleca się włączanie tego parametru na przykład w przypadkach, gdy planowane jest użycie 1 proxy, przy każdym połączeniu z którym zmienia się wyjściowy adres IP.
Strategia użycia proxy (Proxy strategy)
Pozwala zarządzać strategią wyboru proxy przy użyciu sesji: zachować proxy z udanego zapytania dla następnego zapytania lub zawsze używać losowego proxy.
Rekomendacje
W tym artykule omówiono wszystkie ustawienia umożliwiające zarządzanie wątkami. Warto zauważyć, że przy konfiguracji wątków nie trzeba ustawiać wszystkich parametrów wymienionych w artykule; wystarczy ustawić tylko te, które zapewnią uzyskanie poprawnego wyniku. Zazwyczaj wystarczy zmienić tylko Threads count, pozostałe ustawienia można zostawić domyślne.
Ustawienia scraperów
Każdy scraper posiada wiele ustawień i pozwala na zapisywanie różnych zestawów ustawień w presetach. System presetów pozwala na używanie tego samego scrapera z różnymi ustawieniami w zależności od sytuacji, co przeanalizujemy na przykładzie scrapera SE::Google:
Preset 1: "Scrapowanie maksymalnej liczby linków"
- Liczba stron (Pages count):
10
W ten sposób scraper będzie zbierał maksymalną liczbę linków, przechodząc przez wszystkie strony wyników wyszukiwania
Preset 2: "Scrapowanie konkurencji dla zapytania"
- Liczba stron (Pages count):
1 - Format wyniku (Results format):
$query: $totalcount\n
W tym przypadku otrzymujemy liczbę wyników wyszukiwania dla zapytania (konkurencja zapytania) i dla większej szybkości wystarczy nam zescrapować tylko pierwszą stronę
Tworzenie presetów
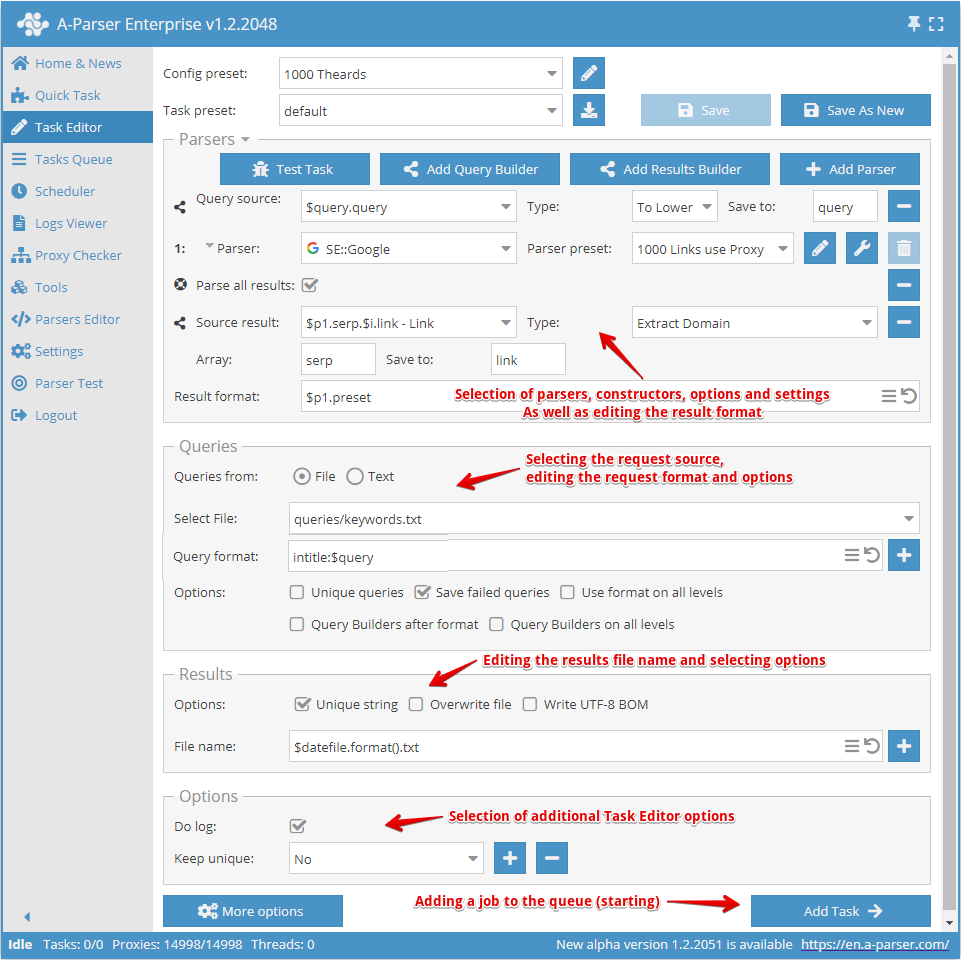
Tworzenie presetu zaczyna się od wyboru scrapera/scraperów i określenia wyniku, który chcemy otrzymać.
Następnie należy zrozumieć, jakie będą dane wejściowe dla wybranego scrapera; na powyższym zrzucie ekranu wybrano scraper SE::Google, jego dane wejściowe to dowolne ciągi znaków, tak jakbyś szukał czegoś w przeglądarce. Można wybrać plik z zapytaniami lub wpisać zapytania w polu tekstowym.
Teraz należy nadpisać ustawienia (wybrać opcje) dla scrapera, dodać usuwanie duplikatów. Można użyć konstruktora zapytań, jeśli trzeba przetworzyć zapytania, lub użyć konstruktora wyników, jeśli trzeba w jakiś sposób przetworzyć wyniki.
Następnie należy zwrócić uwagę na edycję nazwy pliku wyników i w razie potrzeby zmienić ją według własnego uznania.
Ostatnim punktem jest wybór dodatkowych opcji, w szczególności opcji Do log (Prowadź log). Jest ona bardzo przydatna, jeśli chcesz poznać przyczynę błędu scrapowania.
Po tym wszystkim należy zapisać preset i dodać go do kolejki zadań.
Nadpisywanie ustawień
Override preset - szybkie nadpisywanie ustawień dla scrapera; tę opcję można dodać bezpośrednio w Edytorze zadań. Jednym kliknięciem można dodać kilka parametrów. Na liście ustawień wskazane są wartości domyślne, a jeśli opcja jest pogrubiona, oznacza to, że została już nadpisana w presecie
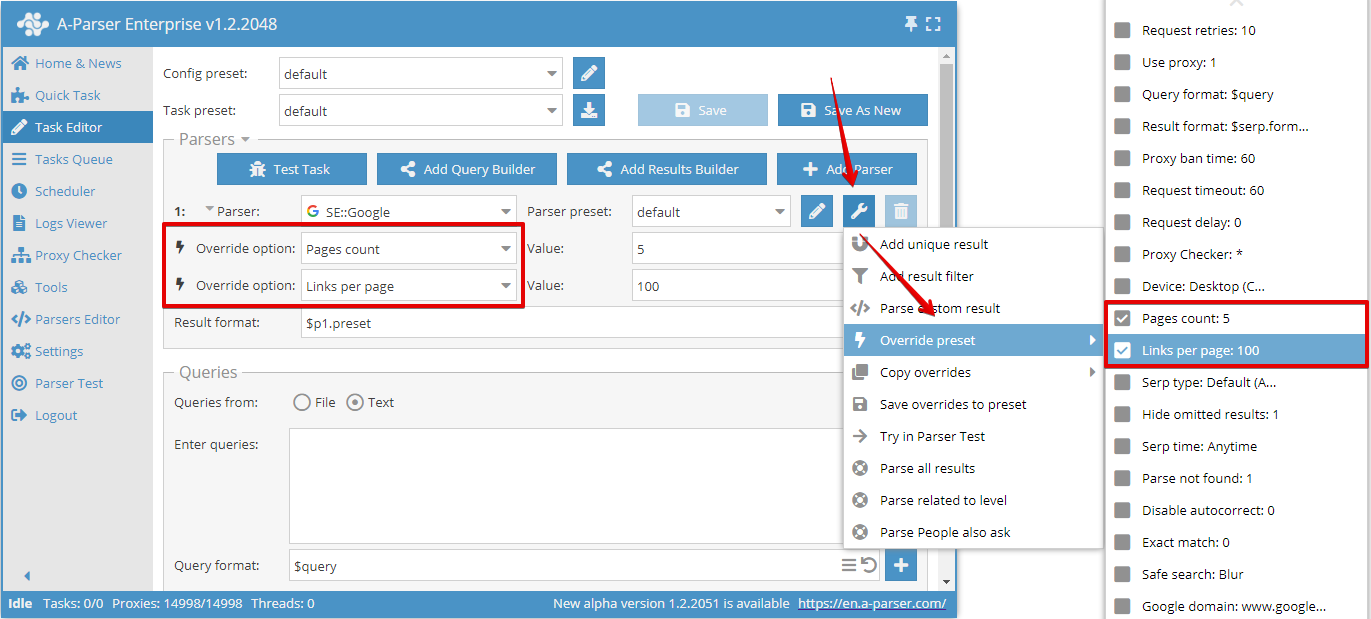
W tym przykładzie nadpisano opcję Pages count (Liczba stron), ustawiając ją na 5.
W zadaniu można użyć nieograniczonej liczby opcji Override preset, ale jeśli zmian jest dużo, wygodniej jest utworzyć nowy preset i w nim zapisać wszystkie zmiany.
Można również łatwo zapisać nadpisania za pomocą funkcji Save overrides to preset (Zapisz nadpisania). Zostaną one zapisane jako oddzielny preset dla wybranego scrapera.
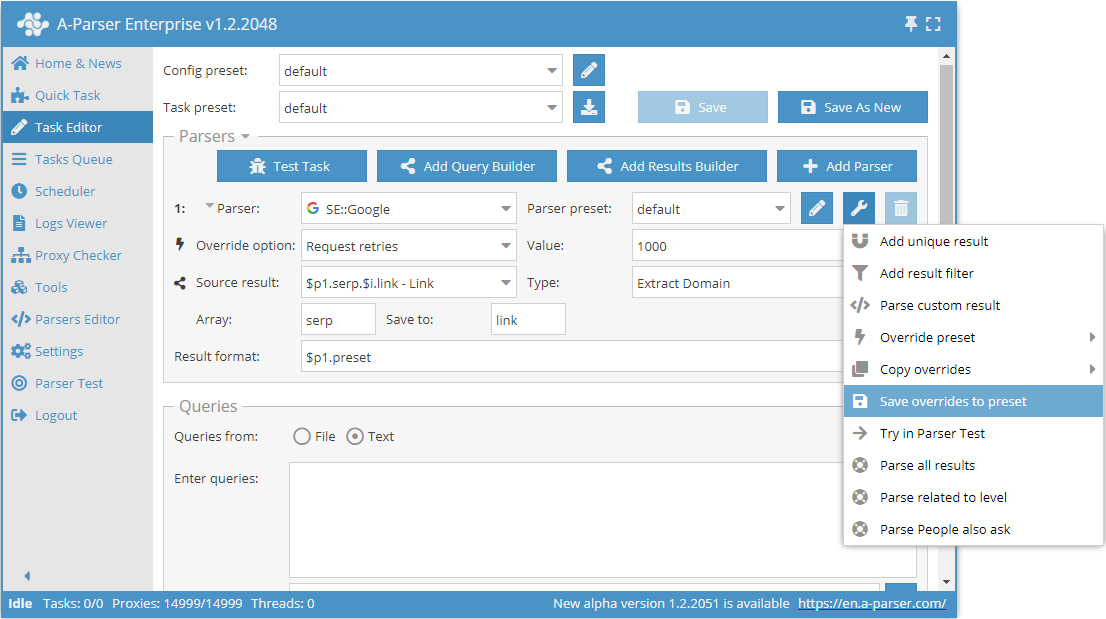
Dzięki temu w przyszłości wystarczy po prostu wybrać ten zapisany preset z listy i go użyć.
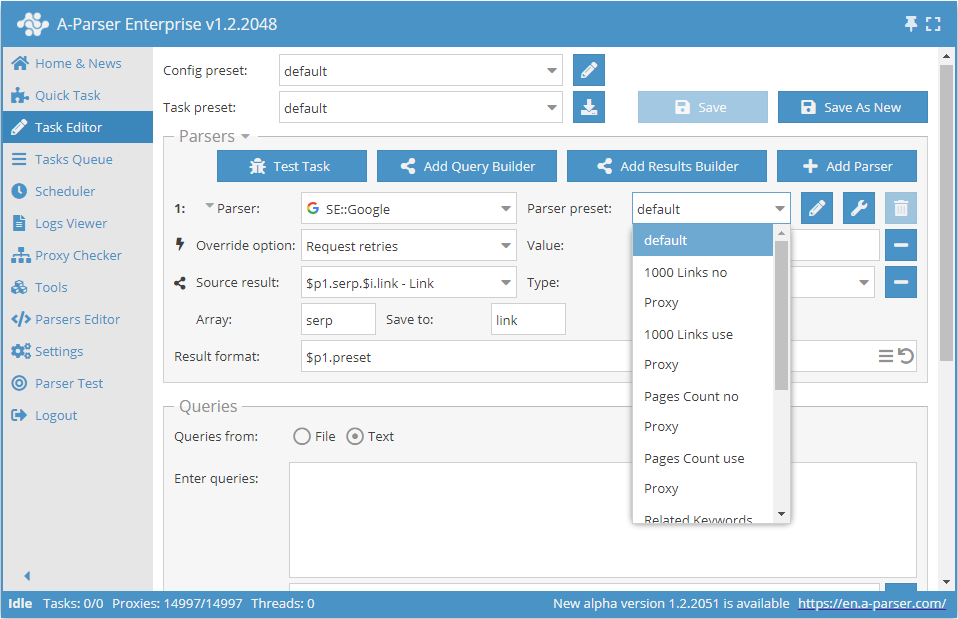
Ogólne ustawienia dla wszystkich scraperów
Każdy scraper posiada własny zestaw ustawień; informacje o ustawieniach każdego scrapera można znaleźć w odpowiedniej sekcji
W poniższej tabeli przedstawiliśmy ogólne ustawienia dla wszystkich scraperów
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Request retries | 10 | Liczba prób dla każdego zapytania; jeśli zapytania nie uda się wykonać w określonej liczbie prób, jest ono uważane za nieudane i pomijane |
| Use proxy | ☑ | Określa, czy używać proxy |
| Query format | $query | Format zapytania |
| Result format | Każdy scraper ma własną wartość | Format wyjściowy wyniku |
| Proxy ban time | Każdy scraper ma własną wartość | Czas banowania proxy w sekundach |
| Request timeout | 60 | Maksymalny czas oczekiwania na zapytanie w sekundach |
| Request delay | 0 | Opóźnienie między zapytaniami w sekundach; można ustawić losową wartość z zakresu, np. 10,30 - opóźnienie od 10 do 30 sekund |
| Proxy Checker | All | Proxy z których checkerów powinny być używane (wybór między wszystkimi a wyliczeniem konkretnych) |
Ogólne dla wszystkich scraperów pracujących przez protokół HTTP
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Max body size | Każdy scraper ma własną wartość | Maksymalny rozmiar strony wyników w bajtach |
| Use gzip | ☑ | Określa, czy używać kompresji przesyłanego ruchu |
| Extra query string | Pozwala wskazać dodatkowe parametry w ciągu zapytania |
Domyślne ustawienia dla każdego scrapera mogą się różnić. Są one przechowywane w presecie default w ustawieniach każdego scrapera.
Ustawienia proxycheckerów
Więcej o Konfiguracji proxycheckerów
Dodatkowe ustawienia
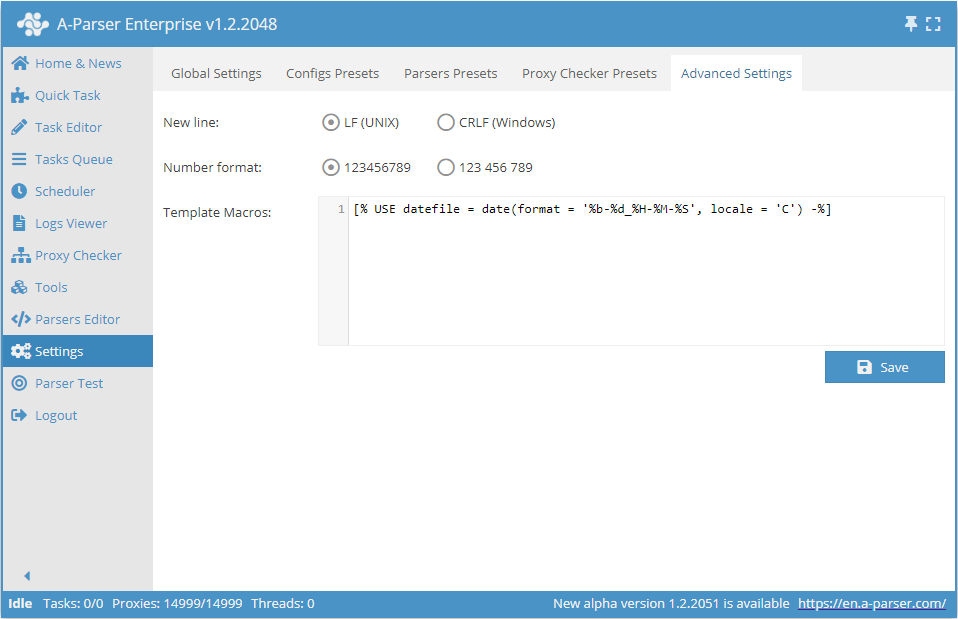
- Znak końca linii pozwala wybrać między wariantem Unix a Windows zakończenia linii podczas zapisywania wyników do pliku
- Format liczb - określa sposób wyświetlania liczb w interfejsie A-Parser
- Makra szablonów