Waarom zijn updates nodig en waarom zijn ze betaald?
A-Parser ontwikkelt zich voortdurend. Met de release van nieuwe versies worden verbeteringen en correcties doorgevoerd. In dit artikel bespreken we wat updates inhouden, hoe ze verschillen van de licentie, welke rol ze spelen en waarom het noodzakelijk is om ervoor te betalen.
Licentie ≠ updates
Bij de aanschaf van A-Parser ontvangt u een licentie voor onbepaalde tijd voor het gebruik ervan en 3-6 maanden gratis updates, afhankelijk van de gekochte licentie. Na afloop van de gratis updateperiode kunt u updaten naar de laatst beschikbare stabiele versie en de scraper volledig blijven gebruiken — voor zover de versie die beschikbaar was op het moment dat het abonnement afliep dit toelaat.
Om het abonnement te verlengen, kunt u een van de drie updatepakketten aanschaffen: voor 3 maanden, één jaar of levenslang voor respectievelijk $49, $149 en $399.
U hoeft niet constant voor updates te betalen. De periode waarin er geen abonnement op updates was, hoeft niet te worden betaald.
Waarom zijn updates betaald?
🐞 Correcties
Websites en diverse soorten bronnen ontwikkelen zich vrij snel. Elke wijziging aan de kant van de doelsite, hoe onbeduidend ook, kan invloed hebben op de gegevensextractie. Dit komt doordat scrapers oorspronkelijk zijn afgestemd op een specifieke structuur; wijzigingen in de lay-out, beveiliging of andere interne mechanismen leiden tot onjuiste gegevens in de resultaten, het volledig ontbreken daarvan of andere fouten. De gegevensextractie zelf heeft een negatieve invloed op de servers van de websites: het aantal verzoeken en daarmee de belasting neemt toe. Diensten die inkomsten verliezen, worden gedwongen een uitweg te zoeken, waardoor nieuwe soorten beveiligingen verschijnen en oude worden doorontwikkeld.
Bij elke dergelijke wijziging moeten aanpassingen worden gedaan. Achter elke aanpassing zit een analyse van het probleem, het zoeken naar een oplossing en de implementatie daarvan.
🧰 Dagelijks ondergaat elke ingebouwde scraper een systeem van interne tests. Als de testverzoeken succesvol zijn afgerond, worden de verkregen resultaatwaarden gecontroleerd. Een mislukte test signaleert fouten in de scraper. Dankzij deze tests reageren we snel op defecten en beginnen we direct met het herstelwerk.
Enkele van de meest complexe, veelgevraagde en daarom prioritaire scrapers voor ons zijn die voor de zoekmachines Yandex en Google. Elke scraper bestaat uit vele onderdelen die een specifieke taak oplossen. Denk hierbij aan het voorbereiden van het verzoek, het vormen van headers, het ophalen van de broncode van de pagina, diverse formattering van resultaten, het werken met captcha's, enz. Dit alles moet in werkende staat worden gehouden. De scraper voorziet in variabelen die alle benodigde gegevens van de pagina bevatten: zoekresultaten, advertenties, gerelateerde zoekwoorden en andere waarden. Deze worden geëxtraheerd met behulp van reguliere expressies die uitgaan van een bepaalde documentstructuur op de pagina (volgorde van elementen, hun types, klassen en andere kenmerken). Bij een kritieke wijziging in deze structuur stopt de regex die bij de vorige versie paste met het ophalen van het juiste fragment, en wordt de scraper teruggestuurd voor revisie.
✨ Verbeteringen
Naast het operationeel houden van de ingebouwde scrapers, worden er met elke versie nieuwe functies toegevoegd en diverse verbeteringen doorgevoerd die invloed hebben op zowel de prestaties als de hoeveelheid verkregen gegevens. In de versie worden nieuwe scrapers opgenomen en worden nieuwe methoden in de JavaScript API geïmplementeerd.
U kunt alle wijzigingen hier bekijken.
Problemen gerelateerd aan het ontbreken van updates
Het ontbreken van tijdige updates veroorzaakt een onjuiste werking van de ingebouwde scrapers. De redenen kunnen variëren. De lay-out van pagina's kan bijvoorbeeld zijn gewijzigd. Een scraper die geen update heeft ontvangen, probeert gegevens te verzamelen met oude reguliere expressies die niet zijn aangepast aan het nieuwe formaat. Als gevolg hiervan ontstaan er mislukte verzoeken, treden er diverse fouten op en is er geen resultaat.
Voorbeeld met de Google scraper
Een gebruiker nam contact op met de support met het volgende probleem:
Ik verzamel Google-zoekresultaten met jullie proxy's. Er zijn 300 pogingen ingesteld per verzoek. Alle verzoeken mislukken. Gisteren werkte alles nog.
Op het eerste gezicht lijkt het een probleem met de proxy's, maar tests met identieke instellingen en verzoeken op de nieuwste versie verlopen succesvol. Dat betekent dat het probleem ergens anders ligt. Tijdens het gesprek blijkt dat de gebruiker een verouderde versie van A-Parser gebruikt. Dit is de werkelijke reden voor de onjuiste werking van de Google scraper.
Voorbeeld met de Yandex scraper
Bij Yandex is de lay-out van pagina's met captcha's gewijzigd, waardoor deze niet meer opgelost konden worden. Op het forum in de sectie Taken werd een bijbehorend topic aangemaakt.
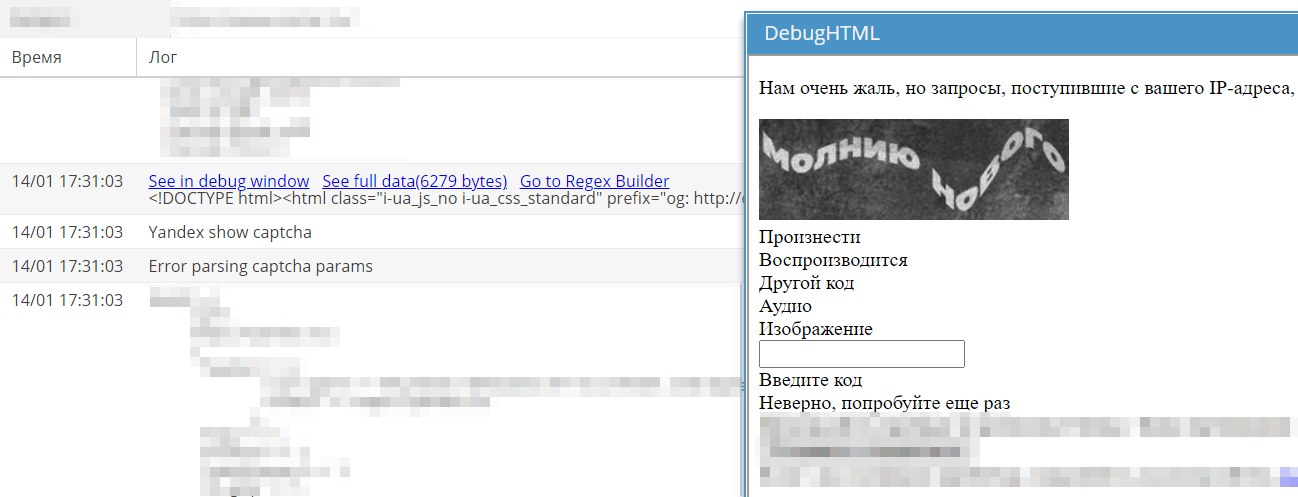
De volgende ochtend verscheen er een fix. De taak werd gesloten en verplaatst naar de sectie Next release. Daar bevinden zich de topics van alle correcties en verbeteringen die in de volgende stabiele versie zullen worden opgenomen.
Dienovereenkomstig werden in een A-Parser die geen recente update had ontvangen, de captcha's in Yandex niet meer opgelost.
Conclusie
Bij de aanschaf van A-Parser ontvangt u een licentie voor gebruik van het programma voor onbepaalde tijd en een pakket gratis updates voor een bepaalde periode. Indien nodig kunt u na afloop van de abonnementsperiode deze verlengen door een van de aangeboden updatepakketten aan te schaffen.
Websites zijn instabiel – scrapers vereisen voortdurende aanpassingen en verbeteringen. Het in werkende staat houden ervan is ons werk. Een prioritaire taak waar we veel moeite in steken om zo snel mogelijk werkende correcties uit te brengen. De kosten van de updates worden gerechtvaardigd door de arbeid die erachter schuilt. Elke versie is niet zomaar een lijst met correcties en verbeteringen – het zijn maanden van geconcentreerd werk door het A-Parser team.