Para que servem as atualizações e por que elas são pagas?
O A-Parser está em constante evolução. Com o lançamento de novas versões, melhorias e correções são introduzidas. Neste artigo, analisaremos o que são as atualizações, como elas diferem da licença, qual papel desempenham e por que é necessário pagar por elas.
Licença ≠ atualizações
Ao adquirir o A-Parser, você recebe uma licença vitalícia para seu uso e de 3 a 6 meses de atualizações gratuitas, dependendo da licença comprada. Após o término do período de atualizações gratuitas, você pode atualizar para a última versão estável disponível e continuar usando o scraper integralmente — tanto quanto a versão disponível no momento do término da assinatura permitir.
Para renovar a assinatura, você pode adquirir um dos três pacotes de atualizações: por 3 meses, um ano e vitalício por $49, $149 e $399, respectivamente.
Você não precisa pagar pelas atualizações constantemente. Não há necessidade de pagar pelo período em que não houve assinatura de atualizações.
Por que as atualizações são pagas?
🐞 Correções
Sites e diversos tipos de recursos evoluem rapidamente. Quaisquer mudanças, mesmo as mais insignificantes por parte do site de destino, podem impactar a extração de dados. Isso ocorre porque, inicialmente, os scrapers são ajustados para uma estrutura específica, e mudanças no layout, proteção ou outras mecânicas internas resultam em dados incorretos nos resultados, ausência total deles e outros erros. A própria extração de dados afeta negativamente os servidores dedicados aos sites: as consultas aumentam e, consequentemente, a carga. Serviços que perdem lucro são forçados a buscar uma saída para essa situação, razão pela qual surgem novos tipos de proteção e as antigas evoluem.
A cada mudança dessas, é necessário fazer ajustes. Por trás de cada um deles está a análise do problema, a busca por uma solução e sua implementação.
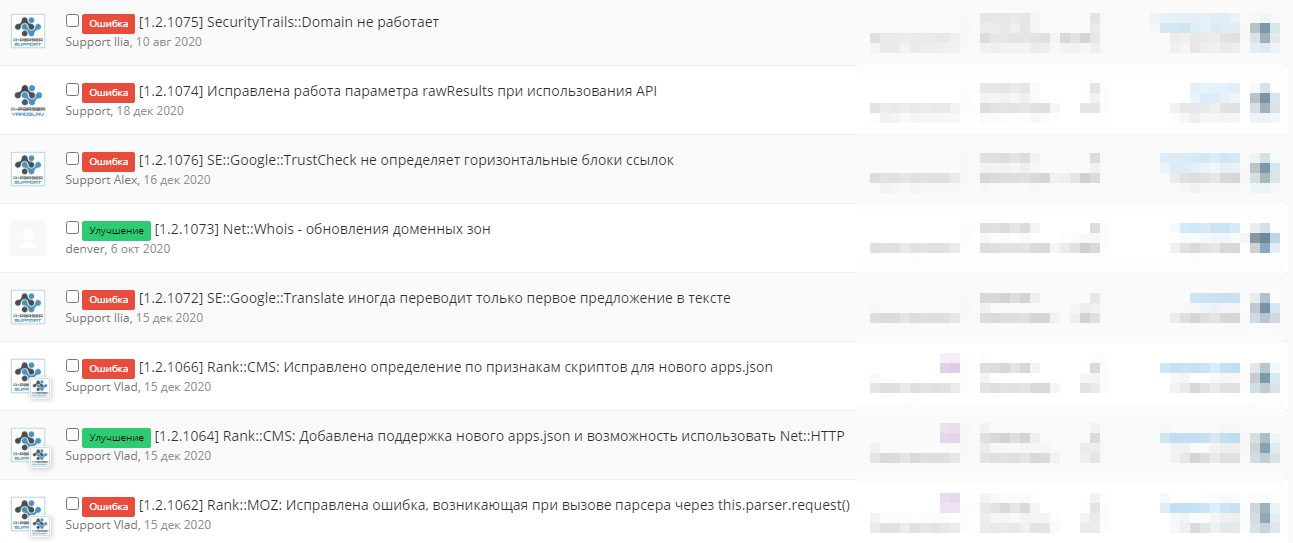
🧰 Diariamente, cada scraper integrado passa por um sistema de testes internos. Se as consultas de teste forem concluídas com sucesso, os valores obtidos como resultado são verificados. Um teste reprovado sinaliza erros presentes no scraper. Graças aos testes, reagimos prontamente a falhas e começamos imediatamente a trabalhar em sua correção.
Alguns dos mais complexos, requisitados e, portanto, prioritários para nós são os scrapers dos sistemas de busca Yandex e Google. Cada um consiste em muitas partes que resolvem uma tarefa específica. Entre elas estão a preparação da consulta, a formação de cabeçalhos, a obtenção do código-fonte da página, vários tipos de formatação de resultados, trabalho com captcha, etc. Tudo isso precisa ser mantido em estado funcional. O scraper prevê a presença de variáveis contendo todos os dados necessários da página: resultados de busca, anúncios publicitários, palavras-chave relacionadas e outros valores. Eles são extraídos usando expressões regulares que pressupõem a presença de uma estrutura de documento específica na página (ordem dos elementos, seus tipos, classes e outros atributos possíveis). Com uma mudança crítica nessa estrutura, a regex que se adequava à versão anterior deixa de extrair o fragmento necessário, e o scraper é enviado para revisão.
✨ Melhorias
Além de manter a funcionalidade dos scrapers integrados, a cada versão são adicionadas novas funções e introduzidas várias melhorias que afetam tanto o desempenho quanto a quantidade de dados obtidos. Novos scrapers são incluídos na versão e novos métodos são implementados na API JavaScript.
Você pode ver todas as alterações aqui.
Problemas relacionados à falta de atualizações
A falta de atualizações oportunas provoca o funcionamento incorreto dos scrapers integrados. Os motivos podem ser variados. Por exemplo, o layout das páginas pode ter mudado. Um scraper que não recebeu a atualização tenta coletar dados com expressões regulares antigas, não adaptadas ao novo formato. Como consequência, surgem consultas malsucedidas, aparecem diversos tipos de erros e o resultado fica ausente.
No exemplo do scraper Google
Um usuário entrou em contato com o suporte com o seguinte problema:
Estou coletando resultados do Google com seus proxies. Defini 300 tentativas para a consulta. Todas as consultas falham. Ontem tudo estava funcionando.
À primeira vista, parece que o problema está nos proxies, mas testes com configurações e consultas idênticas na versão mais recente funcionam com sucesso. Portanto, o problema é outro. Durante o diálogo, descobre-se que o usuário possui uma versão desatualizada do A-Parser. Esta é a verdadeira causa do funcionamento incorreto do scraper Google.
No exemplo do scraper Yandex
No Yandex, o layout das páginas com captcha mudou, fazendo com que ele parasse de ser resolvido. No fórum, na seção de Tarefas, foi criado um tópico correspondente.
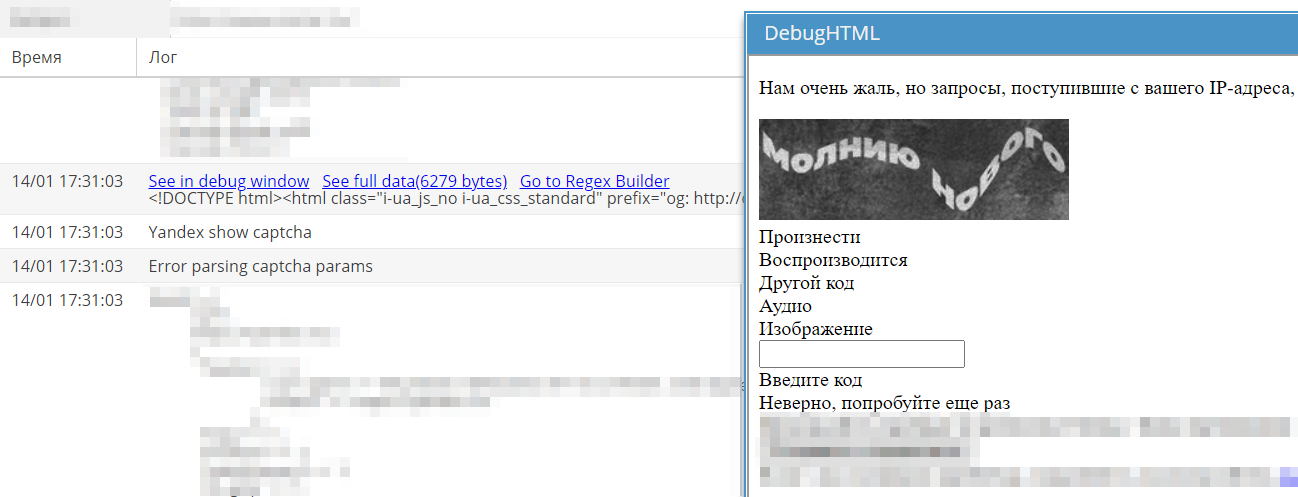
Na manhã seguinte, uma correção foi lançada. A tarefa foi encerrada e movida para a seção Next release. Lá encontram-se os tópicos de todas as correções e melhorias que serão incluídas na próxima versão estável.
Consequentemente, no A-Parser que não recebeu a atualização recente, o captcha no Yandex não era mais resolvido.
Conclusão
Ao adquirir o A-Parser, você recebe uma licença de uso vitalícia do programa e um pacote de atualizações gratuitas por um período determinado. Se necessário, após o término do prazo da assinatura, você pode renová-la adquirindo um dos pacotes de atualizações oferecidos.
Os sites são instáveis – os scrapers exigem ajustes e melhorias constantes. Manter seu estado operacional é o nosso trabalho. Uma tarefa prioritária na qual empenhamos grandes esforços para lançar correções funcionais o mais rápido possível. O custo das atualizações justifica o trabalho que está por trás delas. Cada versão não é apenas uma lista de correções e melhorias – são meses de trabalho focado da equipe do A-Parser.