Perché sono necessari gli aggiornamenti e perché sono a pagamento?
A-Parser è in continua evoluzione. Con l'uscita di nuove versioni vengono introdotti miglioramenti e correzioni. In questo articolo analizzeremo cosa rappresentano gli aggiornamenti, in cosa differiscono dalla licenza, che ruolo giocano e perché è necessario pagarli.
Licenza ≠ aggiornamenti
Acquistando A-Parser, ricevi una licenza perpetua per il suo utilizzo e 3-6 mesi di aggiornamenti gratuiti a seconda della licenza acquistata. Al termine del periodo di aggiornamenti gratuiti, puoi aggiornare all'ultima versione stabile disponibile e continuare a utilizzare lo scraper a pieno regime — per quanto consentito dalla versione disponibile al momento della scadenza dell'abbonamento.
Per rinnovare l'abbonamento puoi acquistare uno dei tre pacchetti di aggiornamento: per 3 mesi, un anno e a vita rispettivamente a $49, $149 e $399.
Non è necessario pagare costantemente per gli aggiornamenti. Non c'è alcun obbligo di pagare per il periodo in cui non si è avuto un abbonamento attivo agli aggiornamenti.
Perché gli aggiornamenti sono a pagamento?
🐞 Correzioni
I siti e le varie risorse online si evolvono piuttosto rapidamente. Qualsiasi modifica, anche la più insignificante, da parte del sito di destinazione può influenzare lo scraping. Ciò accade perché inizialmente gli scraper sono tarati su una determinata struttura e i cambiamenti nel layout, nella protezione o in altre meccaniche interne comportano dati errati nei risultati, la loro totale assenza o altri errori. Lo scraping stesso influisce negativamente sui server dedicati ai siti: aumentano le richieste e di conseguenza il carico. I servizi che perdono profitti sono costretti a cercare una via d'uscita dalla situazione, motivo per cui compaiono nuovi tipi di protezioni e si evolvono quelle vecchie.
Con ogni cambiamento di questo tipo è necessario apportare correzioni. Dietro ognuna di esse c'è l'analisi del problema, la ricerca di una soluzione e la sua implementazione.
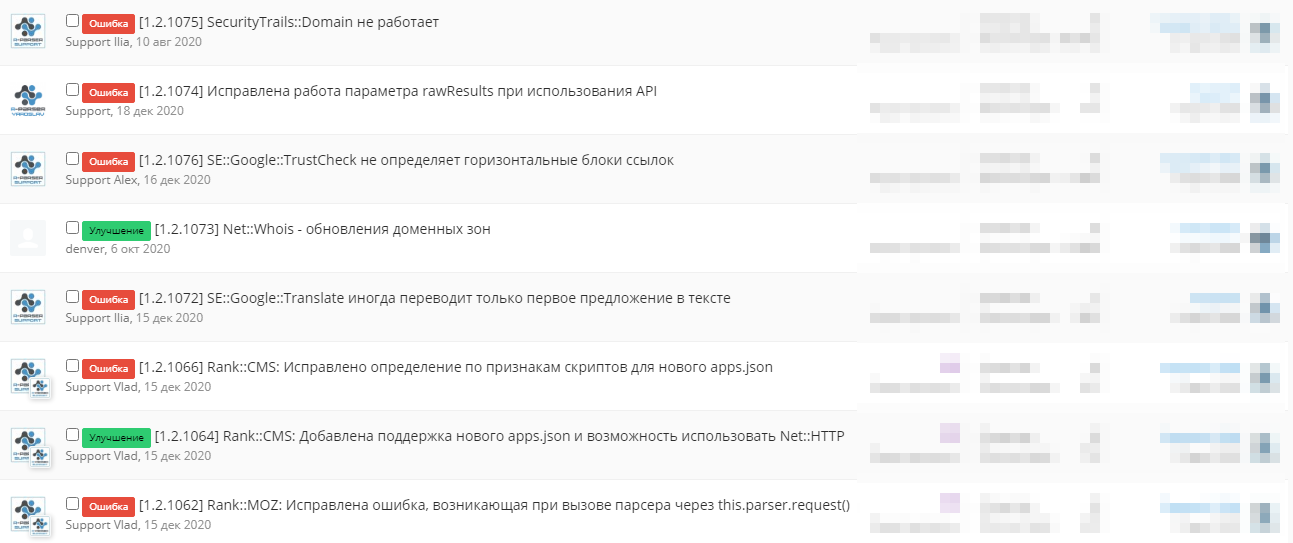
🧰 Ogni giorno ogni scraper integrato passa attraverso un sistema di test interni. Se le richieste di test hanno esito positivo, vengono verificati i valori ottenuti come risultato. Un test fallito segnala errori presenti nello scraper. Grazie ai test reagiamo tempestivamente ai guasti e iniziamo subito a lavorare sulla loro correzione.
Tra i più complessi, richiesti e quindi prioritari per noi ci sono gli scraper dei motori di ricerca Yandex e Google. Ognuno è composto da molte parti che risolvono un compito specifico. Tra queste la preparazione della query, la formazione degli header, l'ottenimento del codice sorgente della pagina, vari tipi di formattazione dei risultati, il lavoro con i captcha, ecc. Tutto questo deve essere mantenuto in stato funzionante. Lo scraper prevede la presenza di variabili contenenti tutti i dati necessari dalla pagina: risultati di ricerca, annunci pubblicitari, parole chiave correlate e altri valori. Questi vengono estratti tramite espressioni regolari che presuppongono la presenza sulla pagina di una determinata struttura del documento (ordine degli elementi, loro tipi, classi e altri possibili attributi). In caso di modifica critica di questa struttura, la regex che si adattava alla versione precedente smette di estrarre il frammento necessario e lo scraper viene inviato in revisione.
✨ Miglioramenti
Oltre a mantenere la funzionalità degli scraper integrati, con ogni versione vengono aggiunte nuove funzioni e apportati vari miglioramenti che influenzano sia le prestazioni che la quantità di dati ottenuti. Nella versione vengono inclusi nuovi scraper e implementati nuovi metodi nelle JavaScript API.
Puoi visualizzare tutte le modifiche qui.
Problemi legati all'assenza di aggiornamenti
L'assenza di aggiornamenti tempestivi provoca il funzionamento errato degli scraper integrati. Le ragioni possono essere diverse. Ad esempio, potrebbe essere cambiato il layout delle pagine. Lo scraper che non ha ricevuto l'aggiornamento tenta di raccogliere dati con vecchie espressioni regolari non adattate al nuovo formato. Di conseguenza, compaiono richieste fallite, emergono vari tipi di errori e il risultato è assente.
L'esempio dello scraper Google
Un utente ha contattato il supporto per il seguente problema:
Raccolgo i risultati di ricerca di Google con i vostri proxy. Ho impostato 300 tentativi per query. Tutte le richieste falliscono. Fino a ieri funzionava tutto.
A prima vista sembra che il problema risieda nei proxy, ma i test con impostazioni e query identiche sull'ultima versione funzionano correttamente. Quindi il problema è un altro. Durante il dialogo emerge che l'utente ha una versione obsoleta di A-Parser. Questa è la vera causa del funzionamento errato dello scraper Google.
L'esempio dello scraper Yandex
In Yandex è cambiato il layout delle pagine con captcha, motivo per cui non venivano più risolti. Sul forum nella sezione Task è stata creata una discussione dedicata.
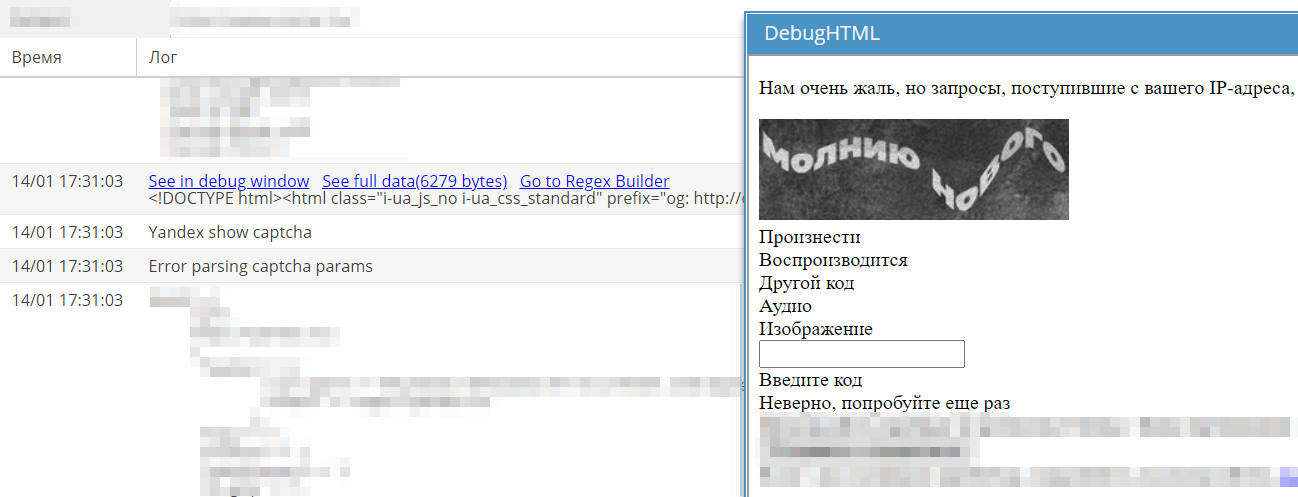
La mattina seguente è uscito il fix. Il task è stato chiuso e spostato nella sezione Next release. Lì si trovano le discussioni di tutte le correzioni e i miglioramenti che saranno inclusi nella prossima versione stabile.
Di conseguenza, in una versione di A-Parser che non ha ricevuto l'ultimo aggiornamento, i captcha di Yandex non venivano più risolti.
Conclusione
Acquistando A-Parser, ricevi una licenza d'uso perpetua del programma e un pacchetto di aggiornamenti gratuiti per un determinato periodo. Se necessario, alla scadenza dell'abbonamento puoi rinnovarlo acquistando uno dei pacchetti di aggiornamento proposti.
I siti sono instabili – gli scraper richiedono costanti correzioni e miglioramenti. Mantenere il loro stato operativo è il nostro lavoro. Un compito prioritario su cui investiamo grandi sforzi per rilasciare correzioni funzionanti il più rapidamente possibile. Il costo degli aggiornamenti giustifica il lavoro che c'è dietro. Ogni versione non è solo un elenco di correzioni e miglioramenti, ma sono mesi di lavoro concentrato del team di A-Parser.