Varför behövs uppdateringar och varför är de avgiftsbelagda?
A-Parser utvecklas ständigt. Med lanseringen av nya versioner införs förbättringar och korrigeringar. I den här artikeln kommer vi att gå igenom vad uppdateringar innebär, hur de skiljer sig från licensen, vilken roll de spelar och varför det är nödvändigt att betala för dem.
Licens ≠ uppdateringar
När du köper A-Parser får du en livstidslicens för dess användning och 3-6 månader av gratis uppdateringar beroende på vilken licens som köpts. Efter att perioden för gratis uppdateringar har löpt ut kan du uppdatera till den senaste tillgängliga stabila versionen och fortsätta använda din scraper i full omfattning — så långt den version som var tillgänglig vid prenumerationens slut tillåter.
För att förnya prenumerationen kan du köpa ett av tre uppdateringspaket: för 3 månader, ett år eller livstid för $49, $149 respektive $399.
Du behöver inte betala för uppdateringar hela tiden. Det finns inget krav på att betala för den period då du inte hade en aktiv prenumeration på uppdateringar.
Varför är uppdateringar avgiftsbelagda?
🐞 Rättelser
Webbplatser och olika typer av resurser utvecklas ganska snabbt. Alla, även de minsta förändringarna på målwebbplatsen, kan påverka dataskrapning. Detta beror på att scrapers ursprungligen är anpassade för en specifik struktur, och ändringar i layout, skydd eller andra interna mekanismer leder till inkorrekta data i resultaten, att data saknas helt eller andra fel. Själva dataskrapningen påverkar servrarna som webbplatserna ligger på negativt: antalet anrop ökar och därmed belastningen. Tjänster som förlorar vinst tvingas söka lösningar på situationen, vilket leder till att nya typer av skydd uppstår och gamla utvecklas.
Vid varje sådan förändring måste ändringar göras. Bakom varje ändring ligger en analys av problemet, sökande efter en lösning och dess implementering.
🧰 Dagligen genomgår varje inbyggd scraper ett system av interna tester. Om testanropen lyckas kontrolleras de resulterande värdena. Ett misslyckat test signalerar att det finns fel i scrapern. Tack vare testerna reagerar vi snabbt på fel och påbörjar omedelbart arbetet med att åtgärda dem.
Några av de mest komplexa, efterfrågade och därför prioriterade för oss är scrapers för sökmotorerna Yandex och Google. Varje scraper består av många delar som löser en specifik uppgift. Bland dessa finns förberedelse av anrop, utformning av headers, hämtning av sidans källkod, olika typer av formatering av resultat, arbete med captcha osv. Allt detta måste hållas i fungerande skick. Scrapern innehåller variabler som rymmer all nödvändig data från sidan: sökresultat, annonser, relaterade sökord och andra värden. Dessa extraheras med hjälp av reguljära uttryck som förutsätter en viss dokumentstruktur på sidan (ordning på element, deras typer, klasser och andra kännetecken). Vid en kritisk ändring av denna struktur slutar det reguljära uttrycket, som passade den tidigare versionen, att hämta rätt fragment, och scrapern skickas för omarbetning.
✨ Förbättringar
Förutom att upprätthålla funktionaliteten hos de inbyggda scrapers, läggs nya funktioner till och olika förbättringar införs i varje version, vilket påverkar både prestanda och mängden data som erhålls. I varje version inkluderas nya scrapers och nya metoder implementeras i JavaScript API.
Du kan se alla ändringar här.
Problem relaterade till saknade uppdateringar
Frånvaron av snabba uppdateringar orsakar inkorrekt funktion hos de inbyggda scrapers. Orsakerna kan variera. Till exempel kan sidlayouten ha ändrats. En scraper som inte har fått uppdateringen försöker samla in data med gamla reguljära uttryck som inte är anpassade till det nya formatet. Som en följd uppstår misslyckade anrop, olika typer av fel dyker upp och resultat saknas.
Exempel med Google-scraper
En användare kontaktade supporten med följande problem:
Jag samlar in Google-sökresultat med era proxyer. Har ställt in 300 försök per anrop. Alla anrop misslyckas. Igår fungerade allt.
Vid en första anblick verkar det som att problemet ligger hos proxyerna, men tester med identiska inställningar och anrop på den senaste versionen fungerar utan problem. Det betyder att problemet är något annat. Under dialogen framkommer det att användaren har en föråldrad version av A-Parser. Detta är den verkliga orsaken till att Google-scrapern inte fungerar korrekt.
Exempel med Yandex-scraper
I Yandex ändrades layouten för sidor med captcha, vilket gjorde att den slutade lösas. På forumet i avsnittet Uppgifter skapades en motsvarande tråd.
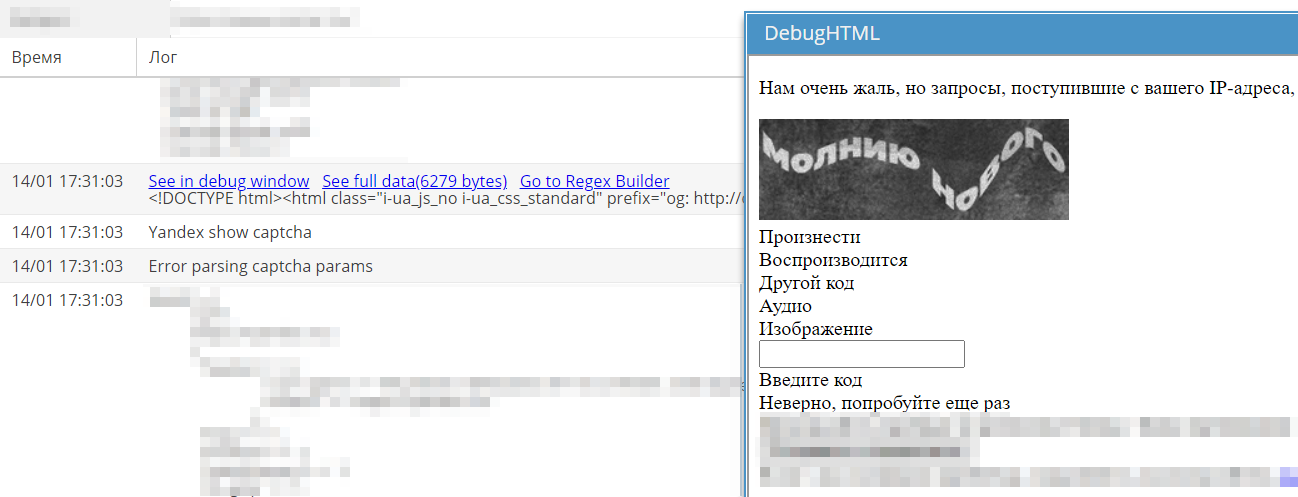
Nästa morgon släpptes en fix. Uppgiften stängdes och flyttades till avsnittet Next release. Där finns trådar för alla rättelser och förbättringar som kommer att inkluderas i nästa stabila version.
Följaktligen slutade captchan i Yandex att lösas i en A-Parser som inte hade fått den senaste uppdateringen.
Slutsats
När du köper A-Parser får du en livstids licens för användning av programmet och ett paket med gratis uppdateringar för en viss period. Vid behov kan du, när prenumerationstiden har löpt ut, förnya den genom att köpa ett av de erbjudna uppdateringspaketen.
Webbplatser är instabila – scrapers kräver ständiga justeringar och förbättringar. Att upprätthålla deras funktionalitet är vårt jobb. Det är en prioriterad uppgift som vi lägger stora ansträngningar på för att släppa fungerande rättelser så snabbt som möjligt. Kostnaden för uppdateringar motiveras av det arbete som ligger bakom. Varje version är inte bara en lista över rättelser och förbättringar – det är månader av fokuserat arbete från A-Parser-teamet.