Często zadawane pytania
1. Pytania dotyczące wersji demo, płatności i zakupu
1.1. Jak pobrać wyniki w wersji Demo?
W wersji Demo wyniki pracy nie są dostępne do pobrania. Udostępniamy je na Państwa prośbę. Prosimy o przesłanie zapytań i wskazanie, który scraper Państwa interesuje, a my prześlemy wyniki (w ramach demo ich liczba jest ograniczona).
1.2. Czy po zakupie A-Parser trzeba za coś dopłacać?
Nie. Bardziej szczegółowo: licencje i dodatki, strona zakupu.
1.3. Gdzie i jak można zapłacić za proxy?
Przy zakupie licencji otrzymują Państwo bonusowe proxy.
Lite - 20 wątków na 2 tygodnie, Pro i Enterprise - 50 wątków na miesiąc.
Kupić więcej wątków lub przedłużyć usługę można w Strefie użytkownika w zakładce Sklep, podsekcja Proxy.
1.4. Czy mogliby Państwo skonfigurować mi zadanie odpłatnie?
Wsparcie techniczne w kwestiach związanych z działaniem A-Parser jest bezpłatne. W sprawie płatnej pomocy w konfiguracji zadań można kontaktować się tutaj: Płatne usługi tworzenia zadań, pomoc w konfiguracji i nauka obsługi A-Parser.
1.5. Czy mogę dokonać płatności za scraper przez bank Privat24? Przez KIWI?
Lista systemów płatności, z którymi współpracujemy, jest wskazana tutaj: kup A-Parser.
1.6. Jeśli muszę sparsować tylko liczbę zaindeksowanych stron w Yandex, który scraper najlepiej kupić?
Do takich celów wystarczy wersja Lite, ale Pro jest bardziej praktyczna i elastyczna w pracy.
1.7. Gdzie sprawdzić informacje o mojej licencji?
1.8. Czy zakupione proxy można wykorzystywać z kilku adresów IP?
Nie.
2. Pytania dotyczące instalacji, uruchamiania i aktualizacji
2.1. Klikam przycisk Download - a archiwum się nie pobiera. Co robić?
Proszę sprawdzić, czy mają Państwo wolne miejsce na dysku twardym, wyłączyć antywirusa. Należy postępować zgodnie z instrukcją instalacji. Prosimy również zapoznać się z sekcją Jak zacząć pracę.
2.2. Kupiłem wersję Enterprise, ale nadal instaluje się PRO. Co robić?
Proszę usunąć poprzednią wersję. W Members Area sprawdzić, czy poprawnie wpisano adres IP. Przed pobraniem kliknąć przycisk Update (Aktualizuj). Pobrać nowszą wersję. Więcej szczegółów w instrukcji instalacji.
2.3. Zainstalowałem program, a on się nie uruchamia, co robić?
Proszę sprawdzić uruchomione aplikacje, wyłączyć antywirusa, sprawdzić dostępną ilość wolnej pamięci RAM. Również w Strefie użytkownika sprawdzić, czy poprawnie wpisano adres IP. Więcej szczegółów: instrukcje instalacji.
2.4. Co zrobić, jeśli mam dynamiczny adres IP?
Nic strasznego, A-Parser obsługuje pracę z dynamicznymi adresami IP. Po prostu za każdym razem, gdy się on zmienia, należy go wpisać w Members Area. Aby uniknąć tych czynności, zaleca się korzystanie ze statycznego adresu IP.
2.5. Jakie są optymalne parametry serwera lub komputera do instalacji scrapera?
Wszystkie wymagania systemowe można sprawdzić tutaj: wymagania systemowe.
2.6. Uruchomiłem zadanie. Scraper się wyłączył i nie chce się ponownie uruchomić, co robić?
Należy zatrzymać serwer, sprawdzić, czy proces nie widnieje w pamięci, i spróbować uruchomić ponownie. Można również spróbować uruchomić A-Parser z zatrzymaniem wszystkich zadań. W tym celu należy go uruchomić z parametrem -stoptasks. Szczegóły dotyczące uruchamiania z parametrem.
2.7. Jakie hasło wpisać przy otwieraniu adresu 127.0.0.1:9091?
Jeśli jest to pierwsze uruchomienie, hasło jest puste. Jeśli nie pierwsze - to takie, które Państwo ustawili. Jeśli zapomnieli Państwo hasła - resetowanie hasła.
2.8. W Strefie użytkownika wpisuję swój IP, a on nie zmienia się w polu Twój aktualny IP. Dlaczego?
Pole Your current IP (Twój aktualny IP) wyświetla IP, który jest obecnie aktywny, i nie powinien on ulegać zmianie. To właśnie ten adres należy wpisać w pole IP 1.
2.9. Czy mogę uruchomić jednocześnie dwie kopie?
Uruchomienie dwóch kopii na jednej maszynie jest możliwe tylko wtedy, gdy będą miały przypisane różne porty w pliku konfiguracji.
Uruchomienie dwóch A-Parserów na różnych maszynach jednocześnie jest możliwe tylko wtedy, gdy wykupili Państwo dodatkowy IP w Strefie użytkownika.
2.10. Czy scraper jest przypisany do sprzętu?
Nie. Do kontroli licencji używany jest Państwa adres IP.
2.11. Pytanie o aktualizację - aktualizować tylko .exe? config/config.db i files/Rank-CMS/apps.json - do czego służą te pliki?
Jeśli nie określono inaczej, należy aktualizować tylko .exe. Pierwszy plik służy do przechowywania konfiguracji A-Parser, a drugi to baza do wykrywania CMS i właściwej pracy samego scrapera ![]() Rank::CMS.
Rank::CMS.
2.12. Mam Win Server 2008 Web Edition - scraper się nie uruchamia...
Na tej wersji systemu operacyjnego A-Parser nie będzie działać. Jedyną opcją jest zmiana systemu operacyjnego.
2.13. Mam procesor 4-rdzeniowy. Dlaczego A-Parser używa tylko jednego rdzenia?
A-Parser wykorzystuje od 2 do 4 rdzeni, dodatkowe rdzenie są używane tylko podczas filtrowania, w Konstruktorze wyników oraz Parse custom result.
2.14. Zaczął pojawiać się błąd segmentacji (segmentation failed, segmentation error). Co robić?
Najprawdopodobniej zmienił się Państwa adres IP. Proszę sprawdzić w Strefie użytkownika.
2.15. Mam Linuxa. A-Parser się uruchomił, ale nie otwiera się w przeglądarce. Jak to rozwiązać?
Proszę sprawdzić firewall - najprawdopodobniej blokuje on dostęp.
2.16. Mam Windows 7. A-Parser się uruchomił, ale nie otwiera się w przeglądarce i w menedżerze zadań nie ma procesu Node.js. Jak to rozwiązać?
Należy sprawdzić aktualizacje Windows i zainstalować najnowsze dostępne. Konkretnie wymagana jest aktualizacja Windows 7 SP1.
2.17. A-Parser nie uruchamia się, a w aparser.log widnieje błąd FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20.
Najprawdopodobniej występuje problem z jakimś zadaniem (folder /config/tasks/) w wyniku błędu dysku (na przykład jeśli zasilanie komputera zostało odłączone bez poprawnego zamknięcia systemu), więcej szczegółów można uzyskać uruchamiając A-Parser z flagą -morelogs
Rozwiązanie: uruchomienie A-Parser z parametrem -stoptasks. Jeśli to nie pomoże, należy wyczyścić całą zawartość /config/tasks/. Jeśli i po tym problem nie ustąpi, należy zainstalować scraper ponownie w nowym katalogu i przenieść konfigurację ze starego (jeśli nie jest uszkodzona).
3. Pytania dotyczące konfiguracji A-Parser i innych ustawień
3.1. Jak skonfigurować proxychecker?
Szczegółowa instrukcja znajduje się tutaj: konfiguracja proxy.
3.2. Brak działających proxy - dlaczego?
Proszę sprawdzić połączenie internetowe oraz poprawność konfiguracji proxycheckera. Jeśli wszystko jest zrobione poprawnie, oznacza to, że obecnie Państwa lista proxy nie zawiera działających serwerów. Rozwiązanie tego problemu: albo użyć innych proxy, albo spróbować ponownie później. Jeśli korzystają Państwo z naszych proxy, proszę sprawdzić adres IP w Strefie użytkownika w sekcji Proxies (Proxy). Możliwe jest również, że Państwa dostawca blokuje dostęp do innych DNS, proszę spróbować wykonać kroki opisane tutaj: http://a-parser.com/threads/1240/#post-3582
3.3. Jak podłączyć antigate?
Szczegółowa instrukcja konfiguracji antigate tutaj.
3.4. Zmieniłem parametry w ustawieniach scrapera, ale nie zostały zastosowane. Dlaczego?
Presetu domyślnego (default) nie można zmieniać. Jeśli wprowadzono jakiekolwiek zmiany, należy kliknąć Save as New Preset (Zapisz jako nowy preset) i następnie używać go w swoim zadaniu.
3.5. Czy można zmienić ustawienia pracującego zadania?
Można, ale nie wszystkie. W trakcie wykonywania zadania można kliknąć pauzę i tam w rozwijanym menu wybrać Edit (Edytuj).
3.6. Jak zaimportować preset?
Kliknąć przycisk obok pola wyboru zadania w Edytorze zadań. Szczegóły tutaj.
3.7. Jak skonfigurować scraper, aby nie używał proxy?
W ustawieniach danego scrapera odznaczyć opcję Use proxy.
3.8. Nie mam przycisku Dodaj nadpisanie / Override option!
Tę opcję można dodać bezpośrednio w Edytorze zadań. Opcje scrapera.
3.9. Jak nadpisać ten sam plik z wynikami?
Przy tworzeniu zadania ustawić opcję Overwrite file (Nadpisz plik).
3.10. Gdzie zmienić hasło do scrapera?
3.11. Ustawiłem 6 milionów kluczy do scrapowania i zaznaczyłem, aby domeny były unikalne. Jak zrobić, aby przy kolejnych 6 milionach kluczy zapisywały się tylko unikalne domeny, które nie wystąpiły wcześniej?
Należy skorzystać z opcji Keep unique (Zapisywanie stanu usuwania duplikatów) przy tworzeniu pierwszego zadania i wskazać zapisaną bazę w drugim. Szczegóły w Dodatkowych opcjach edytora zadań.
3.12. Jak obejść ograniczenie 1000 wyników dla Google?
Skorzystaj z opcji Sparsować wszystkie wyniki / Parse all results.
3.13. Jak obejść ograniczenie 1024 wątków na Linuxie?
3.14. Jaki jest limit wątków na Windowsie?
Do 10000 wątków.
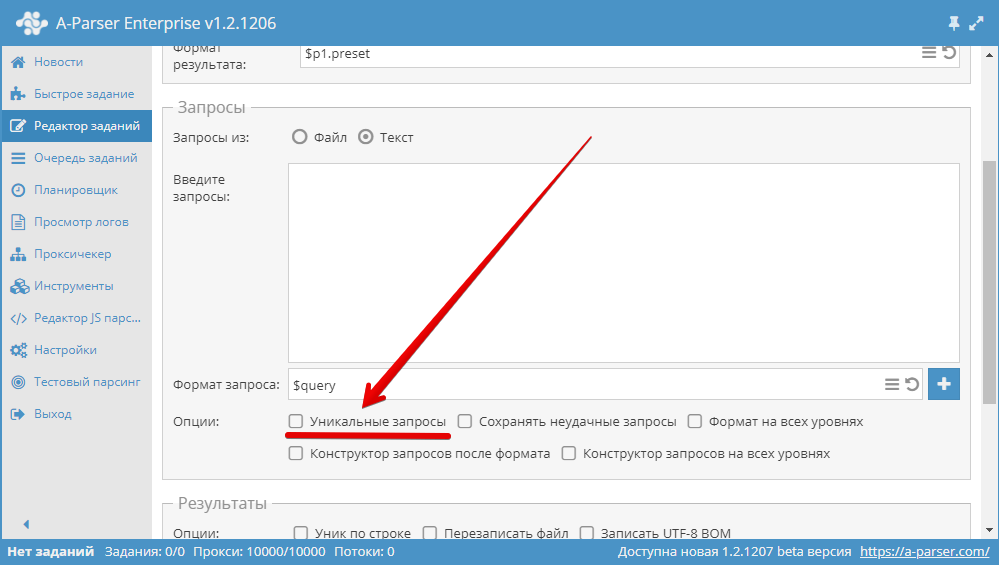
3.15. Jak sprawić, by zapytania były unikalne?
Użyć opcji Unique queries (Unikalne zapytania) w bloku Queries (Zapytania) w Edytorze zadań.
3.16. Jak wyłączyć sprawdzanie proxy?
W Ustawienia - Ustawienia proxycheckera wybrać odpowiedni proxychecker i zaznaczyć opcję No check proxies (Nie sprawdzaj proxy). Zapisać i wybrać zapisany preset.
3.17. Co to jest Proxy ban time? Czy mogę ustawić tam 0?
Czas blokady proxy w sekundach. Tak, można.
3.18. Jaka jest różnica między Exact Domain a Top Level Domain w scraperze  SE::Google::Position
SE::Google::Position
Exact Domain to ścisłe dopasowanie, tzn. jeśli w wynikach jest www.domain.com, a szukamy domain.com, to dopasowania nie będzie. Top Level Domain sprawdza całą domenę najwyższego poziomu, tzn. tutaj dopasowanie wystąpi.
3.19. Jeśli uruchamiam testowe scrapowanie - wszystko działa, jeśli zwykłe - otrzymuję błąd Some error.
Najprawdopodobniej problem leży w DNS, proszę spróbować wykonać tę instrukcję konfiguracji DNS.
3.20. Gdzie ustawia się Format wyniku?
3.21. W  SE::Google brakuje języka niderlandzkiego, mimo że jest on dostępny w ustawieniach Google. Dlaczego?
SE::Google brakuje języka niderlandzkiego, mimo że jest on dostępny w ustawieniach Google. Dlaczego?
Język niderlandzki to Dutch, znajduje się on na liście. Szczegóły w zgłoszeniu dotyczącym dodania języka niderlandzkiego.
4. Pytania dotyczące scrapowania i błędów podczas scrapowania
4.1. Co to są wątki?
Wszystkie nowoczesne procesory mogą wykonywać zadania w kilku wątkach, co znacznie zwiększa prędkość ich realizacji. Dla porównania można przywołać zwykły autobus, który w jednostce czasu przewozi określoną liczbę osób - to będzie zwykłe przetwarzanie jednowątkowe, oraz autobus piętrowy, który w tym samym czasie przewozi dwa razy więcej osób - to będzie wielowątkowość. A-Parser może przetwarzać jednocześnie do 10000 wątków.
4.2. Zadanie się nie uruchamia - komunikat Some Error - dlaczego?
Proszę sprawdzić adres IP w Strefie użytkownika.
4.3. Wszystkie zapytania trafiają do nieudanych, co robić?
Najprawdopodobniej zadanie jest błędnie skonfigurowane lub używany jest niewłaściwy format zapytania. Proszę również sprawdzić, czy są dostępne działające proxy. Można także spróbować zwiększyć opcję Request retries (szczegóły tutaj: nieudane zapytania).
4.4. Ile kont należy zarejestrować, aby zeskrapować 1 000 000 słów kluczowych za pomocą  SE::Yandex::Wordstat?
SE::Yandex::Wordstat?
Nie można dokładnie określić, ile kont jest potrzebnych, ponieważ konto może przestać być zdatne do użytku po nieznanej liczbie zapytań. Zawsze jednak można zarejestrować nowe konta, używając scrapera  SE::Yandex::Register lub po prostu dodać istniejące konta do pliku files/SE-Yandex/accounts.txt.
SE::Yandex::Register lub po prostu dodać istniejące konta do pliku files/SE-Yandex/accounts.txt.
4.5. Zadanie się nie uruchamia, komunikat Error: Lock 100 threads failed(20 of limit 100 used) co robić?
Należy zwiększyć maksymalną dostępną liczbę wątków w ustawieniach scrapera lub zmniejszyć ją w ustawieniach zadania. Szczegóły w Ustawienia.
4.6. Czy można uruchomić 2 zadania jednocześnie?
Tak, A-Parser obsługuje wykonywanie kilku zadań jednocześnie. Liczbę jednocześnie pracujących zadań reguluje się w Ustawienia - Ustawienia ogólne: Maksimum aktywnych zadań.
4.7. Gdzie znajduje się plik z wynikami?
W zakładce Tasks Queue (Kolejka zadań), po zakończeniu każdego zadania, mogą Państwo pobrać wyniki pracy. Fizycznie znajdują się one w folderze results.
4.8. Czy można pobrać plik z wynikami, jeśli scrapowanie nie jest zakończone?
Nie, dopóki scrapowanie nie zostanie zakończone, wyników nie można pobrać. Można je jednak skopiować z folderu aparser/results przy zatrzymanym zadaniu lub na pauzie.
4.9. Czy Państwa scraperem można sparsować 1 000 000 linków dla jednego zapytania?
Tak, używając opcji Sparsować wszystkie wyniki / Parse all results.
4.10. Czy można skrapować  Rank::CMS,
Rank::CMS,  Net::Whois bez proxy?
Net::Whois bez proxy?
Net::Whois - nie jest to zalecane.4.11. Jak sparsować linki z Google?
Należy użyć SE::Google.
4.12. Czy scraper może przechodzić po linkach?
Tak, potrafi to zrobić scraper  HTML::LinkExtractor przy użyciu opcji Parsować do poziomu / Parse to level
HTML::LinkExtractor przy użyciu opcji Parsować do poziomu / Parse to level
4.13. Google scrapuje się bardzo wolno, co robić?
W pierwszej kolejności należy sprawdzić logi zadania, być może wszystkie zapytania są nieudane. Jeśli tak, należy znaleźć przyczynę niepowodzenia zapytań i ją naprawić. Podczas skrapowania z SE::Google w logach zadania nieudane próby często wiążą się z tym, że Google wyświetla captche, co jest normalne. Możesz podłączyć Antigate w celu omijania captch, aby scraper nie ponawiał prób bezskutecznie.
Istnieje również artykuł opisujący czynniki wpływające na prędkość scrapowania i ich działanie: prędkość i zasada działania scraperów.
4.14. Czy Państwa scraperem można sparsować linki, w których tekst jest tylko w języku japońskim?
Tak, w tym celu należy w ustawieniach scrapera ustawić wymagany język, a także użyć japońskich słów kluczowych.
4.15. Czy Państwa scraperem można scrapować linki tylko w strefie domenowej .de lub .ru?
Tak. W tym celu należy skorzystać z filtra.
4.16. Jak uzyskać każdy wynik w pliku od nowej linii?
Przy formatowaniu wyniku należy użyć \n. Przykład:
$serp.format('$link\n')
4.17. Jak sparsować top 10 stron z Google?
Oto preset:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. Dodaję zadanie, przechodzę do zakładki Kolejka zadań - a go tam nie ma! Dlaczego?
Albo popełniono błąd przy tworzeniu zadania, albo zostało ono już wykonane i przeszło do sekcji Completed (Zakończone).
4.19. Pojawia się komunikat, że plik nie jest w utf-8, ale go nie zmieniałem i jest w utf-8, co robić?
Proszę sprawdzić jeszcze raz. Proszę również spróbować zmienić kodowanie, na przykład za pomocą Notepad++.
4.20. W pliku z wynikami wszystko jest w jednej linii, mimo że w zadaniu ustawiłem przenoszenie linii - dlaczego?
W dodatkowych ustawieniach A-Parser należy użyć znaku końca linii CRLF (Windows).
Jeśli jednak już Państwo sparsowali dane bez tej opcji, do przeglądania należy użyć bardziej zaawansowanego edytora, na przykład Notepad++.
4.21. Ile czasu zajmuje sprawdzenie częstotliwości zapytań w Yandex dla 1 000 zapytań?
Wskaźnik ten bardzo zależy od parametrów zadania, charakterystyki serwera, jakości proxy itp., dlatego nie można podać jednoznacznej odpowiedzi.
4.22. Jak skonfigurować scraper, aby w wyniku otrzymać zapytanie-link?
Format wyniku:
$p1.serp.format('$query: $link\n')
W rezultacie otrzymamy:
zapytanie: link 1
zapytanie: link 2
zapytanie: link 3
4.23. Jak ponownie sparsować nieudane zapytania i gdzie są one przechowywane?
Aby nieudane zapytania były zapisywane, należy wybrać odpowiednią opcję w bloku Queries (Zapytania) w Edytorze zadań. Nieudane zapytania są przechowywane w queries\failed. Należy utworzyć nowe zadanie i jako plik zapytań wskazać plik z nieudanymi zapytaniami.
4.24. Jak pozbyć się tagów HTML podczas scrapowania tekstu?
Skorzystaj z opcji Remove HTML tags w Konstruktorze wyników.
4.25. Jak zrobić, aby scrapowane były tylko domeny?
Skorzystaj z opcji Extract Domain w Konstruktorze wyników.
4.26. Jaki jest maksymalny rozmiar pliku z zapytaniami, który można użyć w scraperze?
Rozmiary plików zapytań i wyników nie są niczym ograniczone i mogą osiągać wartości liczone w terabajtach.
4.27. Dlaczego, gdy wpisuję tekst w pole zapytań, scraper wyświetla Queries length limited to 8192 characters?
Dzieje się tak, ponieważ długość zapytania jest ograniczona do 8192 znaków. Aby używać dłuższych zapytań, należy korzystać z plików jako źródła zapytań.
4.28. Co oznacza Oczekiwanie na wątki - 3?
Oznacza to, że brakuje proxy. Należy zmniejszyć liczbę wątków lub zwiększyć liczbę proxy.
4.29. W testowym scrapowaniu pojawia się 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) i nie scrapuje, dlaczego?
Świadczy to o niedziałających proxy.
4.30. Jaka jest różnica między językiem wyników a krajem wyszukiwania w scraperze Google?
Różnica jest następująca: kraj wyszukiwania to powiązanie wyników z konkretnym krajem. Na przykład, jeśli szukają Państwo kupić okna z powiązaniem z konkretnym krajem, priorytet będą miały strony oferujące zakup okien właśnie w tym kraju. Natomiast język wyników to język, w jakim mają być wyświetlane wyniki.
4.31. Nie mogę sparsować określonej strony. Co może być przyczyną?
Często problemem jest blokada ze względu na stary user-agent po stronie serwera. Rozwiązaniem jest nowy user-agent lub następujący kod w parametrze User agent:
[% tools.ua.random() %]
4.32. Scraper zawiesza się, wyłącza. W logu pojawia się linia syswrite: No space left on device
A-Parserowi brakuje miejsca na dysku twardym. Proszę zwolnić więcej miejsca.
4.33. Mój scraper zaczął zwracać none w wynikach (lub ewidentnie błędny wynik)
4.34. Ciągle pojawia się okno z napisem Failed fetch news
4.35. Jak wyświetlić n pierwszych wyników wyszukiwania?
4.36. Jak śledzić łańcuch przekierowań?
4.37. Jak sprawdzić zaindeksowanie linku na stronie dawcy?
Do takich celów istnieje oddzielny scraper:  Check::BackLink.
Więcej szczegółów w dyskusji.
Check::BackLink.
Więcej szczegółów w dyskusji.
4.38. Scraper wyłącza się na Linuxie. W logu jest taki wpis: EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Najprawdopodobniej należy dostroić liczbę wątków, jak opisano w Dokumentacja: Tuning Linux dla większej liczby wątków.
4.39. Gdzie można zobaczyć wszystkie możliwe parametry do użycia przez API?
Pobieranie zapytania API w interfejsie.
Można również wygenerować pełną konfigurację zadania w formacie JSON. W tym celu należy wziąć kod zadania i zdekodować go z base64.
4.40. Pobieram obrazy za pomocą  Net::HTTP, ale z jakiegoś powodu wszystkie są uszkodzone. Co robić?
Net::HTTP, ale z jakiegoś powodu wszystkie są uszkodzone. Co robić?
1) Proszę sprawdzić parametr Max body size - być może należy go zwiększyć. 2) Proszę sprawdzić w ustawieniach A-Parser format końca linii: Dodatkowe ustawienia - Przenoszenie linii.
Aby obrazek nie był uszkodzony, należy używać formatu UNIX.
4.41. Jak uzyskać admin contact z WHOIS?
Takie zadanie można łatwo rozwiązać za pomocą funkcji Parse custom result i wyrażenia regularnego. Szczegóły w dyskusji.
4.42. Wyrażenie regularne do scrapowania numerów telefonów
4.43. Wykrywanie stron bez wersji mobilnej
4.44. Jak poznać nazwę serwera NS?
4.45. Jak sparsować linki do cache Yandex?
4.46. Jak sparsować linki do wszystkich stron witryny?
4.47. Jak sparsować title ze strony?
4.48. Jak sparsować wszystkie strony w danej strefie domenowej?
4.49. Jak zebrać wszystkie URL z parametrami?
4.50. Jak filtrować wyniki według kilku kryteriów i rozdzielić je w raporcie?
4.51. Jak uprościć konstrukcję filtra?
4.52. Jak sortować do plików w zależności od wyniku?
4.53. Create new result directory every X number of files (English)
4.54. Pierwsze kroki w pracy z WordStat
4.55. Zbieranie bloków tekstu >1000 znaków
4.56. Wyświetlanie określonej ilości tekstu ze strony
Można to również rozwiązać za pomocą Template Toolkit. Więcej szczegółów w dyskusji.
4.57. Sprawdzanie konkurencji i występowania w tytule w Google
4.58. Filtrowanie według liczby wystąpień zapytania w kotwicy i opisie
4.59. Jak uzyskać treść artykułu w jednej linii?
4.60. Jak porównać dwie daty tekstowe?
4.61. Jak scrapować wyróżnione słowa z opisu?
4.62. Przykład zadania z użyciem kilku scraperów
4.63. Jak wymieszać linie w wyniku i jak wyświetlać losową liczbę wyników?
4.64. Jak podpisywać wynik za pomocą MD5?
4.65. Jak przekonwertować datę z Unix timestamp na reprezentację tekstową?
4.66. Parse to level, jak scrapować z ograniczeniem?
4.67. Scraper wyłącza się na Linuxie przy uruchamianiu zadania. W logu są takie linie: Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
Należy w konsoli wykonać polecenie:
apt-get --reinstall --purge install netbase
4.68. Błąd Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
Należy uruchomić A-Parser nie z konta root. Konkretnie: jako użytkownik root należy utworzyć nowego użytkownika bez uprawnień root (jeśli taki już istnieje, po prostu go używamy), a następnie zezwolić temu użytkownikowi na interakcję z katalogiem A-Parser, po czym zalogować się jako nowy użytkownik i z jego poziomu uruchomić program.
Jako użytkownik root można utworzyć użytkownika, korzystając z tego poradnika.
Aby zezwolić utworzonemu użytkownikowi na interakcję z katalogiem A-Parser, należy nadać mu uprawnienia. W tym celu wchodzimy jako użytkownik root i wydajemy polecenie:
chown -R user:user aparser
4.69. Błąd Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Jako użytkownik root wykonać polecenie:
sysctl -w kernel.unprivileged_userns_clone=1
Restart A-Parsera nie jest wymagany.
Dla CentOS 7 rozwiązanie znajduje się w tym temacie.
Jako użytkownik root wykonać polecenie:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Następnie zrestartować sysctl poleceniem:
sysctl -p
4.70. Błąd JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
Błąd wynika z braku bibliotek w systemie operacyjnym wymaganych do działania Chrome.
Listę potrzebnych bibliotek dla Chrome można znaleźć w Chrome headless doesn't launch on UNIX.
4.71. Dlaczego captcha nie jest rozwiązywana? W logu widać, że od Xevil A-Parser otrzymał znaki zapytania zamiast odpowiedzi
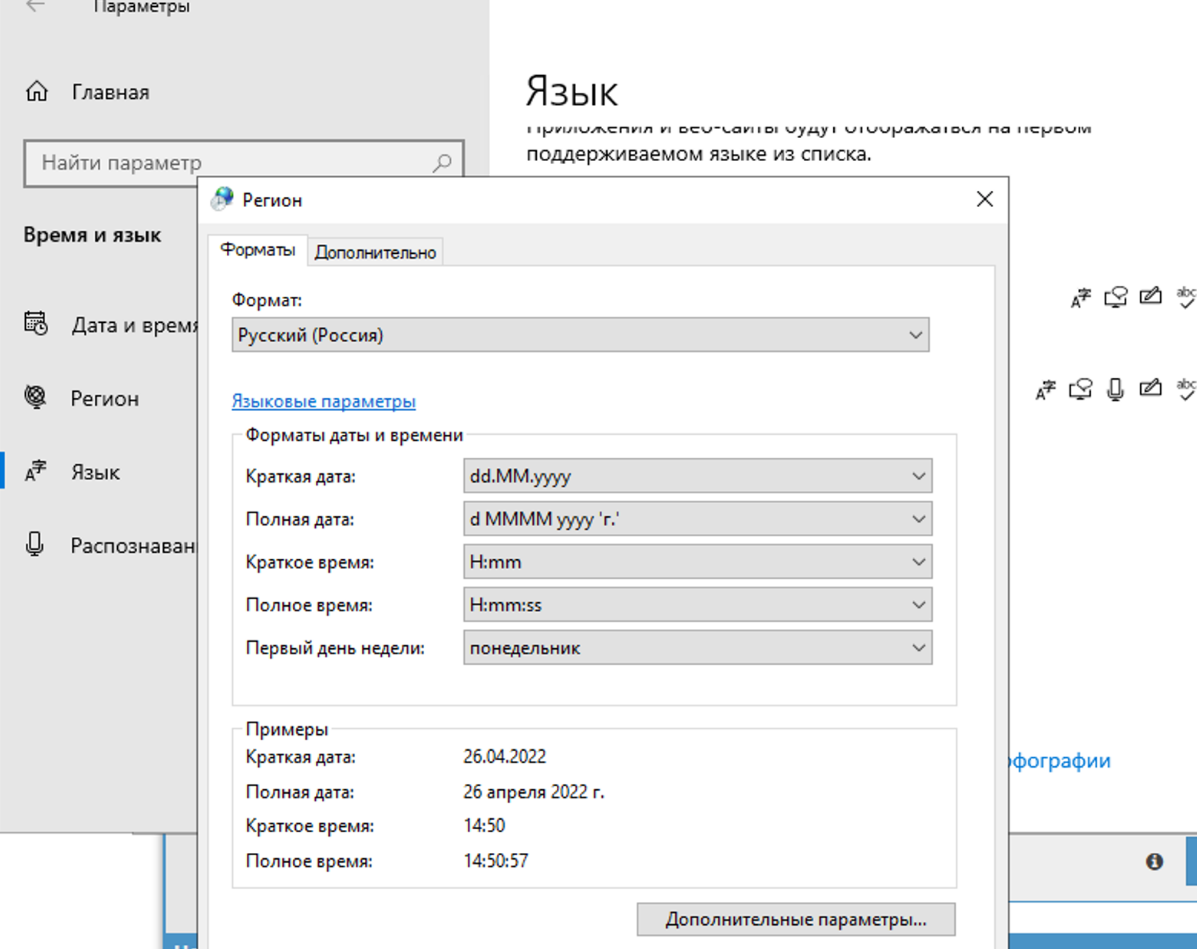
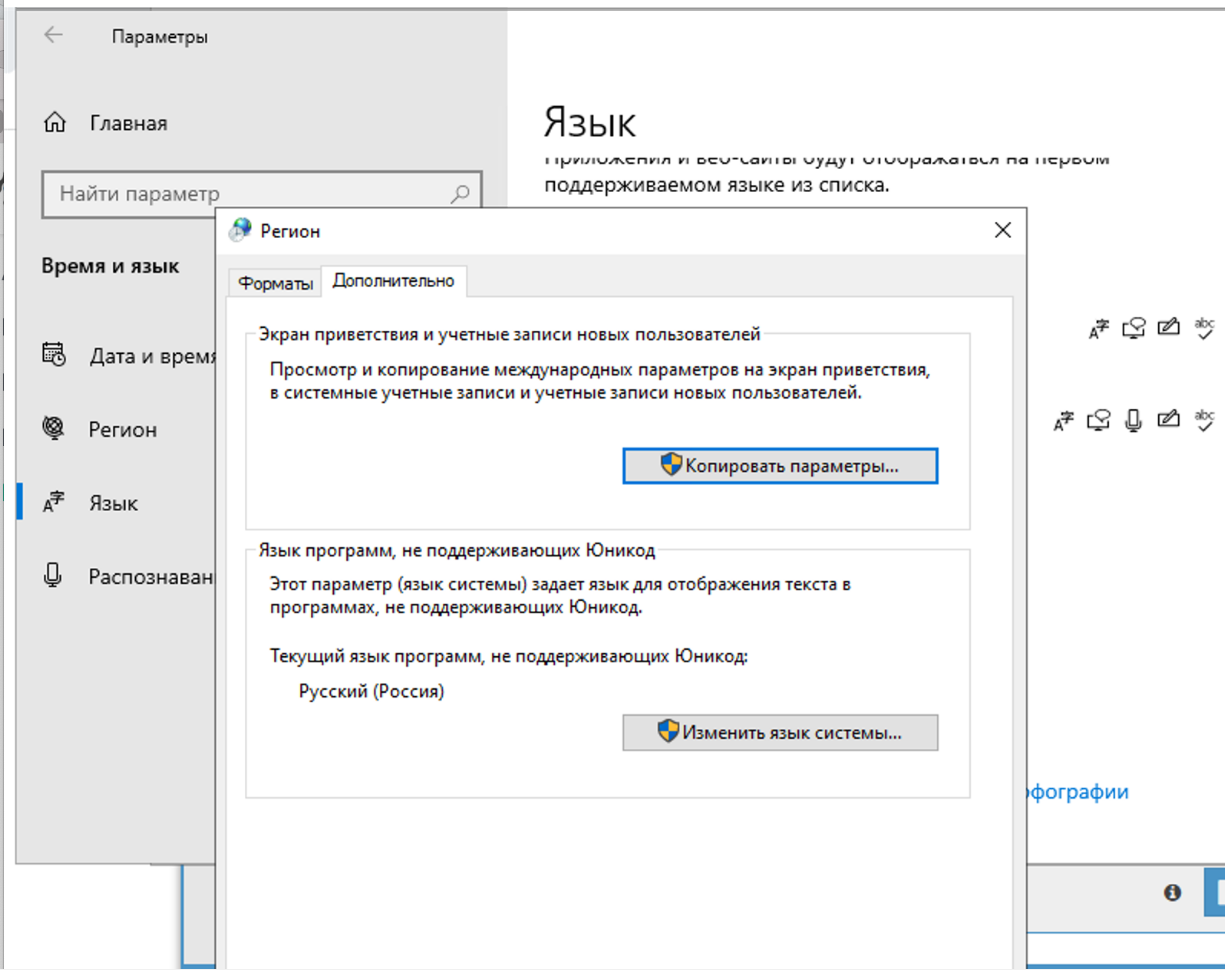
W ustawieniach regionalnych należy zmienić na rosyjski.
Zmiany należy dokonać tylko w zakładce zaawansowane. Nie wpływa to na rozwiązywanie captcha, ale w samym Xrumerze wystąpi problem z kodowaniem, jeśli zmieni się to w obu miejscach.