Vanliga frågor
1. Frågor relaterade till demo, betalning och köp
1.1. Hur laddar man ner resultat i Demo-versionen?
I Demo-versionen är resultaten inte tillgängliga för nedladdning. Vi tillhandahåller dem på begäran. Skicka dina frågor och berätta vilken scraper du är intresserad av, så skickar vi resultaten till dig (antalet är begränsat inom ramen för demon).
1.2. Behöver man betala extra för något efter köp av A-Parser?
Nej. Mer detaljerat: licenser och tillägg, köpsida.
1.3. Var och hur kan man betala för proxy?
När du köper en licens får du bonusproxyer.
Lite - 20 trådar i 2 veckor, Pro och Enterprise - 50 trådar i en månad.
Du kan köpa fler trådar eller förlänga i Medlemsområdet under fliken Butik, underavdelning Proxy.
1.4. Kan ni ställa in en uppgift åt mig mot betalning?
Teknisk support för frågor relaterade till A-Parsers arbete tillhandahålls kostnadsfritt. Angående betald hjälp med att ställa in uppgifter kan du vända dig hit: Betalda tjänster för konfiguration av uppgifter, hjälp med inställningar och utbildning i A-Parser.
1.5. Kan jag betala för scrapern via Privat24? Via KIWI?
Listan över betalningssystem som vi arbetar med finns här: köp A-Parser.
1.6. Om jag bara behöver skrapa antalet indexerade sidor i Yandex, vilken scraper bör jag köpa?
För sådana ändamål räcker det med Lite-versionen, men Pro är mer praktisk och flexibel i arbetet.
1.7. Var kan jag se information om min licens?
1.8. Är det möjligt att använda köpta proxyer från flera IP-adresser?
Nej.
2. Frågor om installation, start och uppdateringar
2.1. Jag trycker på knappen Download - men arkivet laddas inte ner. Vad ska jag göra?
Kontrollera om du har ledigt utrymme på hårddisken, stäng av antivirusprogrammet. Följ installationsinstruktionerna. Läs även Hur man börjar arbeta.
2.2. Köpte Enterprise-versionen, men PRO installeras fortfarande. Vad ska jag göra?
Ta bort den tidigare versionen. Kontrollera i Members Area om din IP-adress är korrekt angiven. Tryck på knappen Update (Uppdatera) innan du laddar ner. Ladda ner en nyare version. Mer detaljer i installationsinstruktionerna.
2.3. Installerade programmet, men det startar inte, vad ska jag göra?
Kontrollera startade applikationer, stäng av antivirus, kontrollera tillgängligt ledigt RAM-minne. Kontrollera även i Medlemsområdet om din IP-adress är korrekt angiven. Mer detaljerat: installationsinstruktioner.
2.4. Vad gör jag om jag har en dynamisk IP-adress?
Det är ingen fara, A-Parser stöder arbete med dynamiska IP-adresser. Varje gång den ändras måste du helt enkelt ange den i Members Area. För att undvika dessa moment rekommenderas att använda en statisk IP-adress.
2.5. Vilka är de optimala parametrarna för server eller dator för installation av scrapern?
Alla systemkrav kan ses här: systemkrav.
2.6. Startade uppgiften. Scrapern kraschade och startar inte längre, vad ska jag göra?
Du måste stoppa servern, kontrollera att processen inte ligger kvar i minnet och försöka starta igen. Du kan också försöka starta A-Parser med stopp av alla uppgifter. För att göra detta måste du starta med parametern -stoptasks. Detaljerat om start med parameter.
2.7. Vilket lösenord ska jag ange när jag öppnar adressen 127.0.0.1:9091?
Om det är första starten är lösenordet tomt. Om det inte är den första - det lösenord som du har angett. Om du har glömt lösenordet - återställning av lösenord.
2.8. I Medlemsområdet anger jag min IP, men den ändras inte i fältet Din nuvarande IP. Varför?
Fältet Your current IP (Din nuvarande IP) visar den IP som är giltig för dig just nu, och den ska inte ändras. Det är den du ska skriva in i fältet IP 1.
2.9. Kan jag köra två kopior samtidigt?
Du kan bara köra två kopior på samma maskin om de har olika portar angivna i konfigurationsfilen.
Du kan bara köra två A-Parser på olika maskiner samtidigt om du har köpt en extra IP i Medlemsområdet.
2.10. Är scrapern bunden till hårdvaran?
Nej. Din IP används för licenskontroll.
2.11. Fråga om uppdatering - ska bara .exe uppdateras? config/config.db och files/Rank-CMS/apps.json - vad är dessa filer till för?
Om inget annat anges, uppdatera endast .exe. Den första filen är för att lagra konfigurationen för A-Parser, och den andra är databasen för att identifiera CMS och för själva driften av scrapern ![]() Rank::CMS.
Rank::CMS.
2.12. Jag har Win Server 2008 Web Edition - scrapern startar inte...
A-Parser fungerar inte på denna OS-version. Det enda alternativet är att byta OS.
2.13. Jag har en 4-kärnig processor. Varför använder A-Parser bara en kärna?
A-Parser använder från 2 till 4 kärnor, extra kärnor används endast vid filtrering, Resultatkonstruktören, Parse custom result
2.14. Jag har börjat få segmenteringsfel (segmentation failed, segmentation error). Vad ska jag göra?
Troligtvis har din IP ändrats. Kontrollera i Medlemsområdet.
2.15. Jag har Linux. A-Parser startade, men öppnas inte i webbläsaren. Hur löser jag det?
Kontrollera brandväggen - troligtvis blockerar den åtkomsten.
2.16. Jag har Windows 7. A-Parser startade, men öppnas inte i webbläsaren och det finns ingen Node.js-process i aktivitetshanteraren. Hur löser jag det?
Du behöver kontrollera Windows-uppdateringar och installera de senaste tillgängliga. Specifikt behövs Windows 7 SP1-uppdateringen.
2.17. A-Parser startar inte och i aparser.log skrivs felet FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20.
Troligtvis uppstår ett problem med någon uppgift (mappen /config/tasks/) till följd av ett diskfel (till exempel om datorns ström stängdes av utan korrekt avstängning), mer information kan fås om du startar A-Parser med flaggan -morelogs
Lösning: starta A-Parser med parametern -stoptasks. Om det inte hjälpte, rensa hela /config/tasks/. Om problemet kvarstår även efter detta, installera scrapern på nytt i en ny katalog och lägg in konfigurationen från den gamla (om den inte är skadad).
3. Frågor om inställning av A-Parser och andra inställningar
3.1. Hur ställer man in proxycheckern?
Detaljerad instruktion finns här: inställning av proxy.
3.2. Inga fungerande proxyer - varför?
Kontrollera din internetanslutning samt att proxycheckern är korrekt inställd. Om allt är korrekt gjort betyder det att din proxylista för närvarande inte innehåller några fungerande servrar. Lösning på detta problem: antingen använda andra proxyer eller försök igen senare. Om du använder våra proxyer, kontrollera IP-adressen i Medlemsområdet under avsnittet Proxies (Proxy). Det är också möjligt att din leverantör blockerar åtkomst till andra DNS, försök att utföra stegen som beskrivs här: http://a-parser.com/threads/1240/#post-3582
3.3. Hur ansluter man Antigate?
Detaljerad instruktion för inställning av Antigate här.
3.4. Jag ändrade parametrar i scraperns inställningar, men de tillämpades inte. Varför?
Standardförinställningen (default) kan inte ändras. Om några ändringar görs måste du klicka på Save as New Preset (Spara som ny förinställning) och därefter använda den i din uppgift.
3.5. Kan man ändra inställningar för en pågående uppgift?
Det går, men inte alla. I en pågående uppgift kan du trycka på paus och i rullgardinsmenyn där välja Edit (Redigera).
3.6. Hur importerar man en förinställning?
Tryck på knappen bredvid fältet för val av uppgift i Uppgiftsredigeraren. Detaljerat här.
3.7. Hur ställer man in scrapern så att den inte använder proxy?
I inställningarna för den önskade scrapern, avmarkera rutan Use proxy.
3.8. Jag har ingen knapp för Lägg till åsidosättning / Override option!
Detta alternativ kan läggas till direkt i Uppgiftsredigeraren. Scraper-alternativ.
3.9. Hur skriver man över till samma resultatfil?
När du skapar uppgiften, ställ in alternativet Overwrite file (Skriv över fil).
3.10. Var ändrar man lösenordet för scrapern?
3.11. Lade in 6 miljoner nycklar för dataskrapning, och angav även att alla domäner ska vara unika. Hur gör jag så att när jag lägger in nya 6 miljoner nycklar, sparas endast unika domäner som inte överlappar med den förra skrapningen?
Du måste använda alternativet Keep unique (Spara dubblettkontrollstatus) när du skapar den första uppgiften och ange den sparade basen i den andra. Detaljerat i Ytterligare alternativ i uppgiftsredigeraren.
3.12. Hur kringgår man begränsningen på 1000 resultat för Google?
Använd alternativet Spara alla resultat / Parse all results.
3.13. Hur kringgår man begränsningen på 1024 trådar i Linux?
3.14. Vad är trådgränsen i Windows?
Upp till 10 000 trådar.
3.15. Hur gör man frågorna unika?
Använd alternativet Unique queries (Unika frågor) i blocket Queries (Frågor) i Uppgiftsredigeraren.
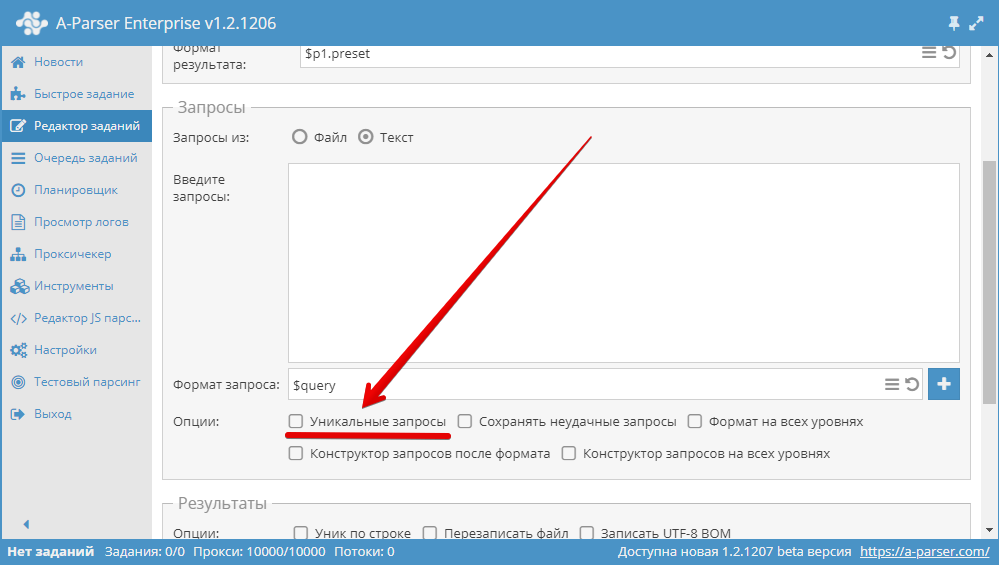
3.16. Hur stänger man av proxykontroll?
I Inställningar - Inställningar för proxychecker, välj önskad proxychecker och markera rutan No check proxies (Kontrollera inte proxy). Spara och välj den sparade förinställningen.
3.17. Vad är Proxy ban time? Kan jag sätta den till 0?
Tiden för proxy-ban i sekunder. Ja, det kan du.
3.18. Vad är skillnaden mellan Exact Domain och Top Level Domain i scrapern  SE::Google::Position
SE::Google::Position
Exact Domain är en strikt matchning, dvs. om resultatet är www.domain.com och vi söker efter domain.com, blir det ingen matchning. Top Level Domain jämför hela toppdomänen, dvs. här blir det en matchning.
3.19. Om jag kör en test-skrapning fungerar allt, men vid vanlig får jag felet Some error.
Troligtvis är problemet med DNS, försök att följa denna instruktion för DNS-inställning.
3.20. Var ställs resultatformatet in?
Använd \n vid formatering av resultatet. Exempel:
3.21. I  SE::Google saknas nederländska språket, trots att det finns i Googles inställningar. Varför?
SE::Google saknas nederländska språket, trots att det finns i Googles inställningar. Varför?
Nederländska språket är Dutch, det finns i listan. Detaljer i förbättringen gällande tillägg av nederländska språket.
4. Frågor om dataskrapning och fel under dataskrapning
4.1. Vad är trådar?
Alla moderna processorer kan utföra uppgifter i flera trådar, vilket avsevärt ökar hastigheten på deras utförande. Som jämförelse kan man ta en vanlig buss som transporterar ett visst antal personer per tidsenhet - detta skulle vara vanlig enkeltrådad bearbetning, och en dubbeldäckarbuss som transporterar dubbelt så många personer under samma tid - detta skulle vara flertrådning. A-Parser kan hantera upp till 10 000 trådar samtidigt.
4.2. Uppgiften startar inte - det står Some Error - varför?
Kontrollera IP-adressen i Medlemsområde.
4.3. Alla frågor hamnar som misslyckade, vad ska jag göra?
Troligtvis är uppgiften felaktigt utformad eller så används ett felaktigt frågeformat. Kontrollera även om det finns fungerande proxyer. Du kan också prova att öka alternativet Request retries (mer detaljer här: misslyckade förfrågningar).
4.4. Hur många konton behöver registreras för att skrapa 1 000 000 sökord med  SE::Yandex::Wordstat?
SE::Yandex::Wordstat?
Det går inte att säga exakt hur många konton som behövs, eftersom ett konto kan sluta fungera efter ett okänt antal förfrågningar. Men du kan alltid registrera nya konton med scrapern  SE::Yandex::Register eller helt enkelt lägga till befintliga konton i filen files/SE-Yandex/accounts.txt.
SE::Yandex::Register eller helt enkelt lägga till befintliga konton i filen files/SE-Yandex/accounts.txt.
4.5. Uppgiften startar inte, det står Error: Lock 100 threads failed(20 of limit 100 used) vad ska jag göra?
Du måste höja det maximalt tillgängliga antalet trådar i scraperns inställningar, eller sänka det i uppgiftens inställningar. Detaljer i Inställningar.
4.6. Kan man köra 2 uppgifter samtidigt?
Ja, A-Parser stöder körning av flera uppgifter samtidigt. Antalet samtidigt aktiva uppgifter regleras i Inställningar - Allmänna inställningar: Max aktiva uppgifter.
4.7. Var ligger resultatfilen?
På fliken Tasks Queue (Uppgiftskö), efter att varje uppgift har slutförts, kan du ladda ner resultaten. Fysiskt finns de i mappen results.
4.8. Kan man ladda ner resultatfilen om dataskrapningen inte är klar?
Nej, så länge dataskrapning pågår kan resultaten inte laddas ner. Men de kan kopieras från mappen aparser/results när uppgiften är stoppad eller på paus.
4.9. Kan man med er scraper skrapa 1 000 000 länkar på en enda fråga?
Ja, genom att använda alternativet Spara alla resultat / Parse all results.
4.10. Kan man skrapa  Rank::CMS,
Rank::CMS,  Net::Whois utan proxy?
Net::Whois utan proxy?
Net::Whois - inte önskvärt.4.11. Hur skrapar man länkar från Google?
Du bör använda SE::Google.
4.12. Kan scrapern följa länkar?
Ja, detta kan göras med scrapern  HTML::LinkExtractor genom att använda alternativet Skrapa till nivå / Parse to level
HTML::LinkExtractor genom att använda alternativet Skrapa till nivå / Parse to level
4.13. Google skrapas mycket långsamt, vad ska jag göra?
Först och främst bör du titta i uppgiftsloggarna, det är möjligt att alla förfrågningar misslyckas. Om så är fallet måste du hitta orsaken till varför förfrågningarna misslyckas och åtgärda den. Vid dataskrapning med SE::Google är misslyckade försök i loggarna ofta relaterade till att Google visar captchas, vilket är normalt. Du kan ansluta Antigate för att kringgå captchas så att scrapern inte förbrukar alla försök.
Det finns också en artikel som beskriver faktorer som påverkar hastigheten på dataskrapning och hur de påverkar: hastighet och funktionsprincip för scrapers.
4.14. Kan man med er scraper skrapa länkar där texten bara är på japanska?
Ja, för att göra detta måste du ställa in önskat språk i scraperns inställningar och även använda japanska sökord.
4.15. Kan man med er scraper skrapa länkar endast i domänzonen .de eller .ru?
Ja. För att göra detta bör du använda ett filter.
4.16. Hur får man varje resultat i filen på en ny rad?
Använd \n vid formatering av resultat. Exempel:
$serp.format('$link\n')
4.17. Hur skrapar man topp 10 webbplatser från Google?
Här är en förinställning:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. Jag lägger till en uppgift, går till fliken Uppgiftskö - men den finns inte där! Varför?
Antingen har ett fel gjorts vid skapandet av uppgiften, eller så är den redan slutförd och har flyttats till Completed (Slutförda).
4.19. Det står att filen inte är i utf-8, men jag har inte ändrat den och den är redan utf-8, vad ska jag göra?
Kontrollera igen. Prova även att ändra kodningen, till exempel med hjälp av Notepad++.
4.20. I resultatfilen är allt på en rad, fast jag i uppgiften satte radbrytning - varför?
I ytterligare inställningar för A-Parser bör du använda radbrytning CRLF (Windows).
Men om du redan har skrapat utan detta alternativ, använd en mer avancerad visare för att titta på filen, till exempel Notepad++.
4.21. Hur lång tid tar det att kontrollera sökfrekvens i Yandex för 1 000 frågor?
Detta värde beror mycket på uppgiftens parametrar, serverns specifikationer, kvaliteten på proxyer etc., så det är omöjligt att ge ett entydigt svar.
4.22. Hur ställer jag in scrapern så att resultatet blir fråga-länk?
Resultatformat:
$p1.serp.format('$query: $link\n')
Resultatet blir:
fråga: länk 1
fråga: länk 2
fråga: länk 3
4.23. Hur skrapar jag om misslyckade frågor och var lagras de?
För att misslyckade förfrågningar ska sparas bör du välja motsvarande alternativ i blocket Queries (Förfrågningar) i Uppgiftsredigeraren. Misslyckade förfrågningar lagras i queries\failed. Du behöver skapa en ny uppgift och ange filen med misslyckade förfrågningar som frågefil.
4.24. Hur blir man av med HTML-taggar vid textskrapning?
Använd alternativet Remove HTML tags i Resultatbyggaren.
4.25. Hur gör man så att endast domäner skrapas?
Använd alternativet Extract Domain i Resultatbyggaren.
4.26. Vad är den maximala storleken på frågefilen som kan användas i scrapern?
Storleken på fråge- och resultatfiler är inte begränsad och kan nå terabyte-nivåer.
4.27. Varför ger scrapern Queries length limited to 8192 characters när jag skriver in text i frågefältet?
Detta beror på att frågelängden är begränsad till 8192 tecken. För att använda längre förfrågningar, använd filer som källor för förfrågningar.
4.28. Vad betyder Väntande trådar - 3?
Detta betyder att det saknas proxyer. Minska antalet trådar eller öka antalet proxyer.
4.29. I test-skrapningen står det 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) och den skrapar inte, varför?
Detta tyder på icke-fungerande proxyer.
4.30. Vad är skillnaden mellan resultatspråk och sökland i Google-scrapern?
Skillnaden är följande: söklandet är kopplingen mellan resultaten och ett specifikt land. Till exempel, om du söker efter köpa fönster med koppling till ett specifikt land, kommer webbplatser som erbjuder att köpa fönster just i det landet att prioriteras. Och resultatspråket är det språk som resultaten ska visas på.
4.31. En viss webbplats skrapas inte för mig. Vad kan det vara?
Ofta beror problemet på att en blockering sker på grund av en gammal user-agent på serversidan. Det löses med en ny user-agent eller följande kod i parametern User agent:
[% tools.ua.random() %]
4.32. Scrapern hänger sig, kraschar. I loggen finns raden syswrite: No space left on device
A-Parser har slut på hårddiskutrymme. Frigör mer utrymme.
4.33. Min scraper har börjat ge none i resultaten (eller uppenbart felaktigt resultat)
4.34. Ett fönster med texten Failed fetch news dyker ständigt upp
4.35. Hur visar man de n första resultaten i sökresultaten?
4.36. Hur spårar man en kedja av omdirigeringar?
4.37. Hur kontrollerar man om en länk är indexerad på källan?
För sådana ändamål finns en separat scraper:  Check::BackLink.
Mer detaljer i diskussionen.
Check::BackLink.
Mer detaljer i diskussionen.
4.38. Scrapern kraschar på Linux. I loggen finns denna post: EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Troligtvis behöver du justera antalet trådar, som beskrivs i Dokumentation: Linux-trimning för fler trådar.
4.39. Var kan man se alla möjliga parametrar för användning via API?
Hämta API-förfrågan i gränssnittet.
Du kan också generera en fullständig uppgiftskonfiguration i JSON. För att göra detta måste du ta uppgiftskoden och avkoda den från base64.
4.40. Jag laddar ner bilder med  Net::HTTP, men de är alla trasiga. Vad ska jag göra?
Net::HTTP, men de är alla trasiga. Vad ska jag göra?
1) Kontrollera parametern Max body size - du kan behöva öka den. 2) Kontrollera radbrytningsformatet i A-Parsers inställningar: Ytterligare inställningar - Radbrytning.
För att bilden inte ska bli trasig måste UNIX-format användas.
4.41. Hur hämtar man admin contact från WHOIS?
En sådan uppgift löses enkelt med funktionen Parse custom result och ett reguljärt uttryck. Detaljer i diskussionen.
4.42. Reguljärt uttryck för dataskrapning av telefonnummer
4.43. Identifiering av webbplatser utan mobilversion
4.44. Hur får man reda på namnet på en ns-server?
4.45. Hur skrapar man länkar till Yandex-cache?
4.46. Hur skrapar man länkar till alla sidor på en webbplats?
4.47. Hur skrapar man title från en sida?
4.48. Hur skrapar man alla webbplatser i en given domänzon?
4.49. Hur samlar man alla url med parametrar?
4.50. Hur filtrerar man resultat efter flera kriterier och delar upp dem i rapporten?
4.51. Hur förenklar man filterkonstruktionen?
4.52. Hur sorterar man efter filer beroende på resultat?
4.53. Create new result directory every X number of files (English)
4.54. Första stegen i arbetet med WordStat
4.55. Insamling av textblock >1000 tecken
4.56. Utmatning av en viss mängd text från en sida
Detta löses också med Template Toolkit. Mer detaljer i diskussionen.
4.57. Kontroll av konkurrens och förekomst i rubrik i Google
4.58. Filtrering efter antal förekomster av frågan i ankare och snippet
4.59. Hur får man artikelns innehåll på en enda rad?
4.60. Hur jämför man två strängdatum?
4.61. Hur skrapar man markerade ord från snippet?
4.62. Exempel på uppgift med användning av flera scrapers
4.63. Hur blandar man rader i resultatet och hur visar man ett slumpmässigt antal resultat?
4.64. Hur signerar man resultatet med MD5?
4.65. Hur omvandlar man datum från Unix timestamp till en strängrepresentation?
4.66. Parse to level, hur skrapar man med begränsning?
4.67. Scrapern kraschar på Linux vid start av uppgift. I loggen finns dessa rader: Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
Du måste köra följande kommando i konsolen:
apt-get --reinstall --purge install netbase
4.68. Fel Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
Du bör starta A-Parser utan root-rättigheter. Specifikt: från root-användaren måste du skapa en ny användare utan root-rättigheter (om en sådan redan finns, använd den bara) och sedan tillåta denna användare att interagera med A-Parser, logga sedan in som den nya användaren och starta programmet därifrån.
Skapa en användare under root-användaren, du kan följa denna guide.
För att tillåta den skapade användaren att interagera med A-Parser måste du ge användaren rättigheter. För att göra detta, logga in som root-användare och ge rättigheter med kommandot:
chown -R user:user aparser
4.69. Fel Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Kör kommandot under root-användaren:
sysctl -w kernel.unprivileged_userns_clone=1
Omstart av A-Parser krävs inte.
För CentOS 7 finns lösningen i denna tråd.
Kör kommandot under root-användaren:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Starta sedan om sysctl med kommandot:
sysctl -p
4.70. Fel JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
Felet uppstår på grund av att bibliotek saknas i operativsystemet för att Chrome ska fungera.
Listan över nödvändiga bibliotek för att Chrome ska fungera finns i Chrome headless doesn't launch on UNIX.
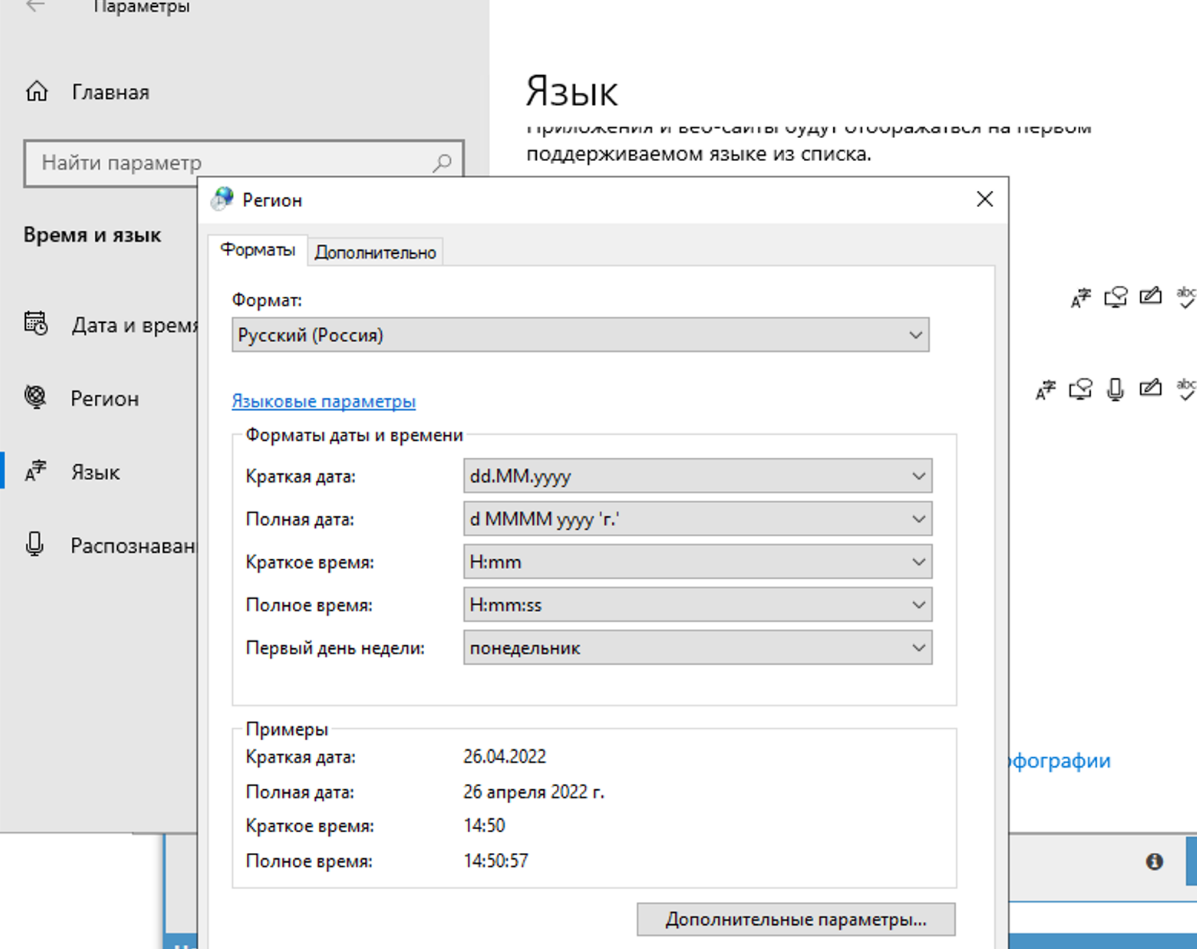
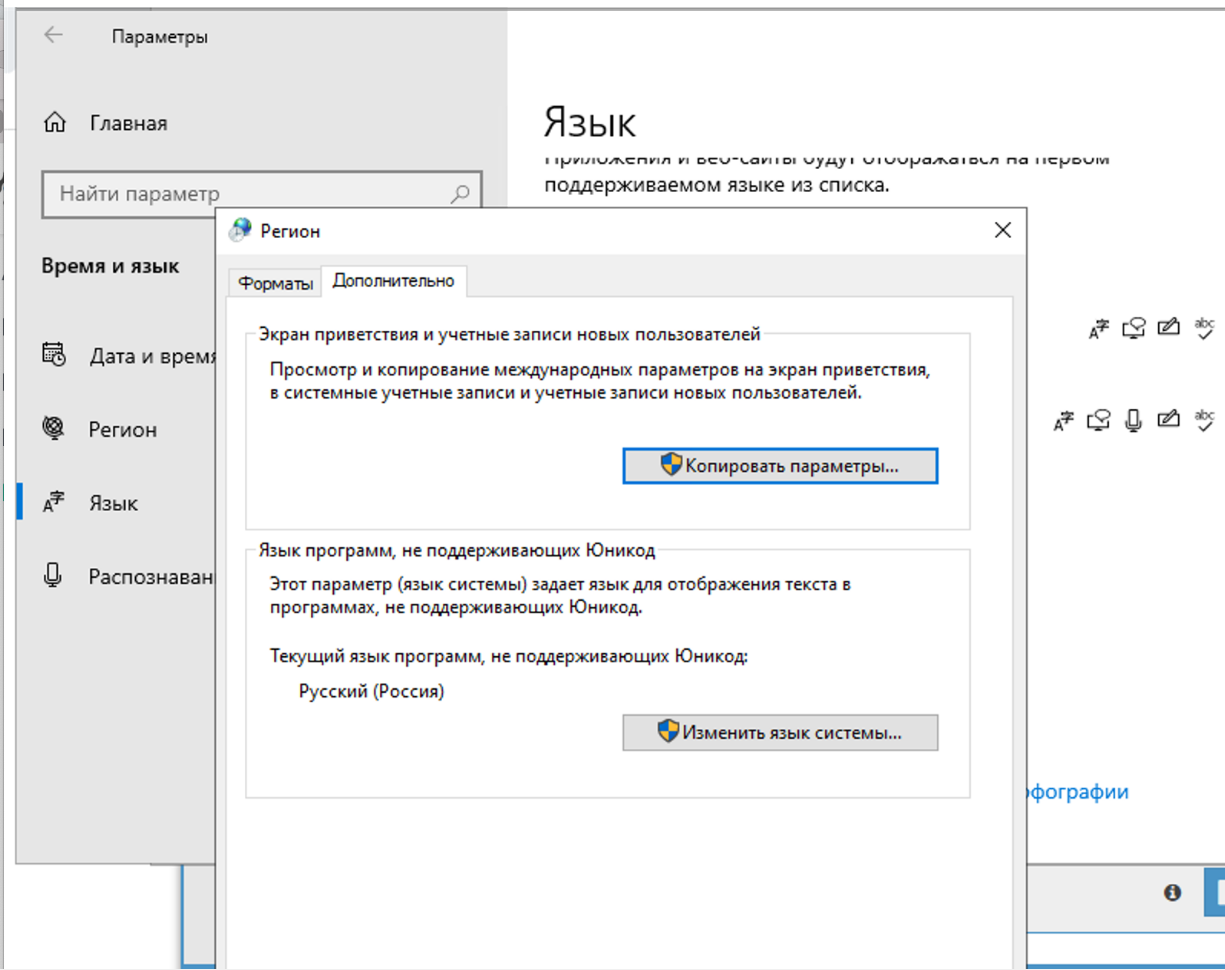
4.71. Varför löses inte captcha? I loggen syns att A-Parser fick frågetecken från Xevil istället för captcha-svaret
I regioninställningarna måste du ändra till ryska.
Du bör endast ändra på fliken Avancerat. Detta påverkar inte captcha-lösning, men i själva Xumer kommer det att uppstå problem med kodningen om du ändrar på båda ställena.