Unicidad de resultados
Unificación, deduplicación, eliminación de duplicados, eliminación de repeticiones: todo esto implica que no necesitamos resultados repetidos. En A-Parser hay 2 métodos de unificación, analicemos cada uno en detalle.
Unificación de resultados por cadena
Este método funciona después de la formación del resultado, justo antes de escribir el resultado en el archivo, cada cadena se comprueba para verificar su unicidad y solo se escriben en el archivo las nuevas cadenas únicas.
Ver también: Orden de procesamiento de consultas
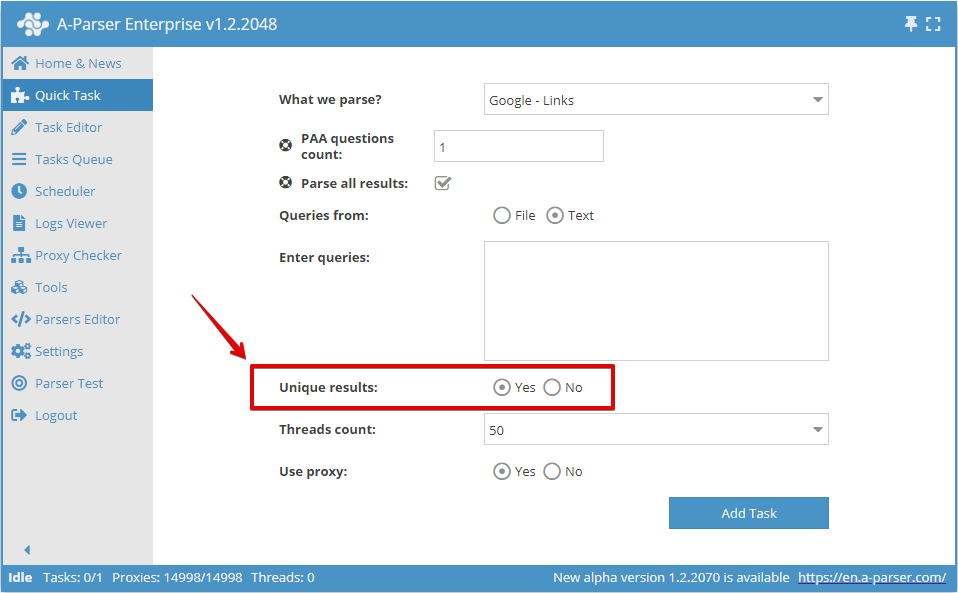
Puede activar la unicidad por cadena en la Tarea rápida:
O en el Editor de tareas:
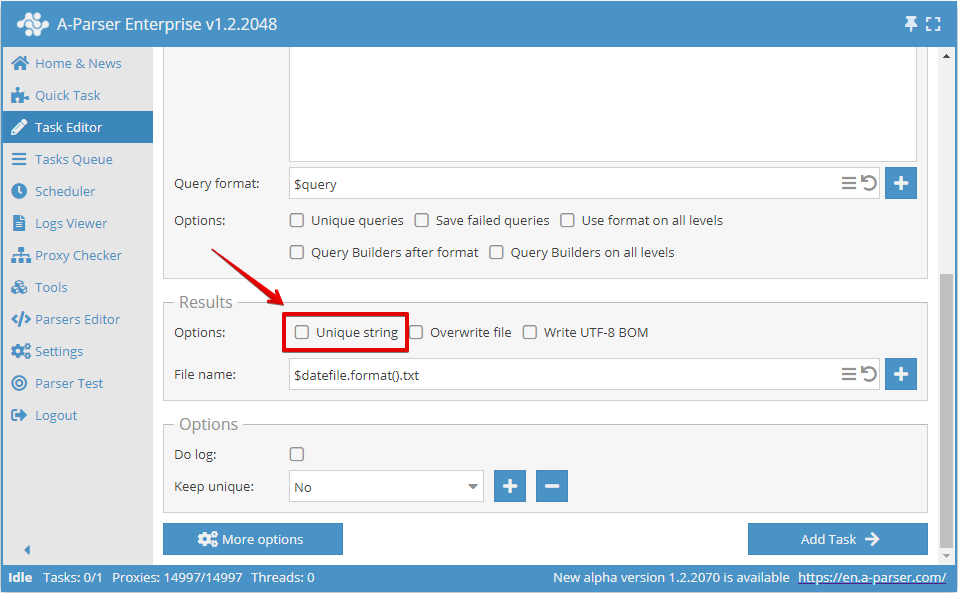
Unificación por cualquier resultado
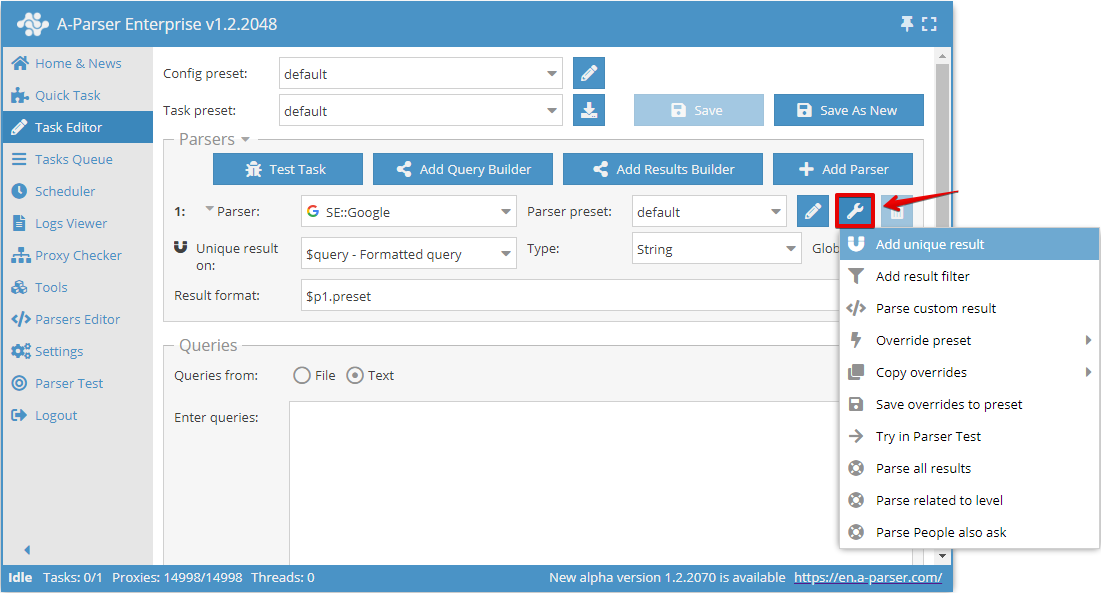
La unificación por cualquier resultado permite realizar la unificación directamente sobre el resultado seleccionado de un extractor específico. Puede añadir este tipo de unificación en el Editor de tareas, haciendo clic en el icono de herramienta a la derecha del extractor y pulsando Add unique result (Añadir unificación):
Ahora puede elegir sobre qué resultado realizar la unificación y el tipo de unificación:
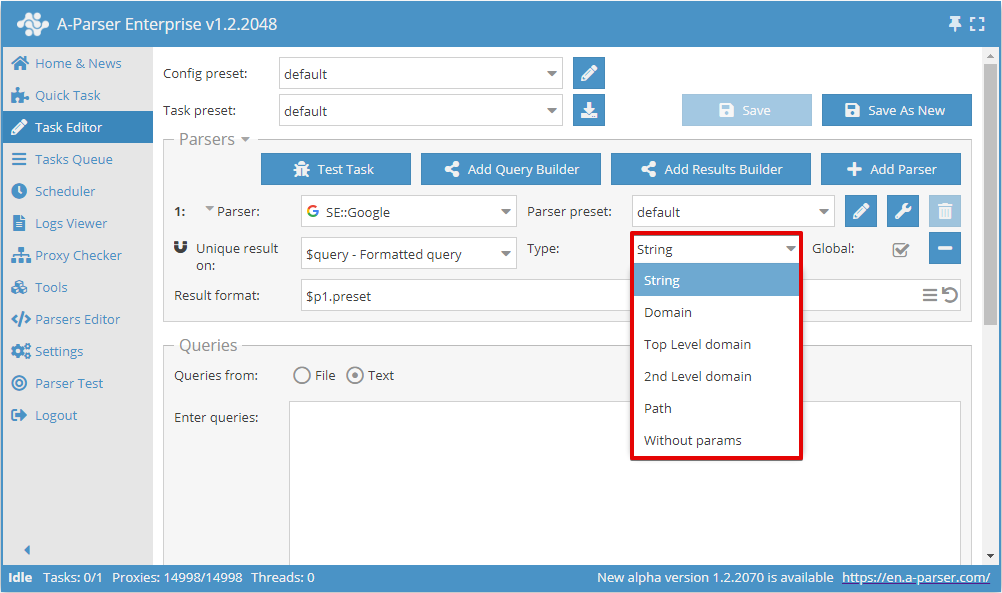
El interruptor Global (Globalmente) se utiliza cuando se seleccionan 2 o más extractores; este determina si se realiza una unificación general o por cada extractor por separado.
Tipos de unificación
| Parámetro | Descripción |
|---|---|
| String | Unificación por cadena (se compara la cadena de resultado completa) |
| Domain | Unificación por dominio (se compara el dominio completo, por ejemplo, www.domain.com y domain.com son dominios diferentes) |
| Top Level domain | Unificación por dominio principal teniendo en cuenta dominios regionales, comerciales, educativos y otros (por ejemplo, domain.co.uk y domain2.co.uk son dominios diferentes, mientras que sub1.domain.com y sub2.domain.com son iguales) |
| Dominio de 2º nivel | Unificación por dominio de segundo nivel (se comparan los dominios de segundo nivel, por ejemplo, www.domain.com, domain.com y user.subdomain.domain.com son todos el mismo dominio) |
| Path | Unificación por ruta (se comparan las partes del enlace hasta el archivo, por ejemplo, http://domain.com/path1/file.php y http://domain.com/path1/file2.php son partes de enlace hasta el archivo iguales) |
| Without params | Unificación por enlace sin parámetros (se comparan los enlaces sin parámetros, por ejemplo, http://domain.com/file.php?page=1 y http://domain.com/file.php?page=2 son enlaces iguales) |
Unificación de consultas
La unificación de consultas envía directamente a la extracción de datos solo las consultas únicas que no han sido extraídas previamente en la tarea actual. Casos de uso principales:
- Si hay duplicados en las consultas de origen y no es deseable extraerlos (doble trabajo)
- Al utilizar la opción Parse to level (Extraer hasta el nivel), es necesario utilizar únicamente consultas únicas para evitar el crecimiento desmedido y el bucle de consultas (por ejemplo, al utilizar el extractor
 HTML::LinkExtractor)
HTML::LinkExtractor)
En todos los demás casos, el uso innecesario de la unificación de consultas solo ralentizará el funcionamiento general del extractor
Guardar la unificación entre tareas
Existe la posibilidad de guardar la base de datos de uniquización para su uso en futuras tareas, lo que permite guardar solo nuevos resultados únicos en las nuevas tareas (por ejemplo, enlaces al realizar la extracción de datos de las SERP en  SE::Google)
SE::Google)
Para guardar la base de datos de unificación, es necesario crear un nuevo nombre de base de datos al añadir la primera tarea:
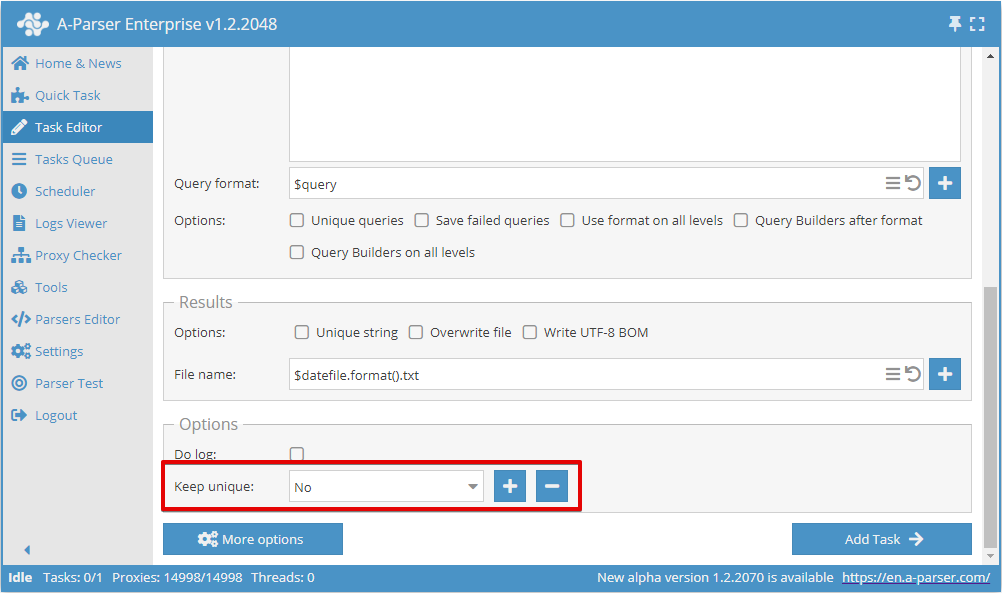
Para todas las tareas posteriores, es necesario seleccionar el nombre de la base de datos creado anteriormente; de este modo, solo se guardarán los nuevos resultados únicos, independientemente de si los resultados se escriben en el mismo archivo que en la primera tarea o en un archivo nuevo.