Ordre de traitement des requêtes
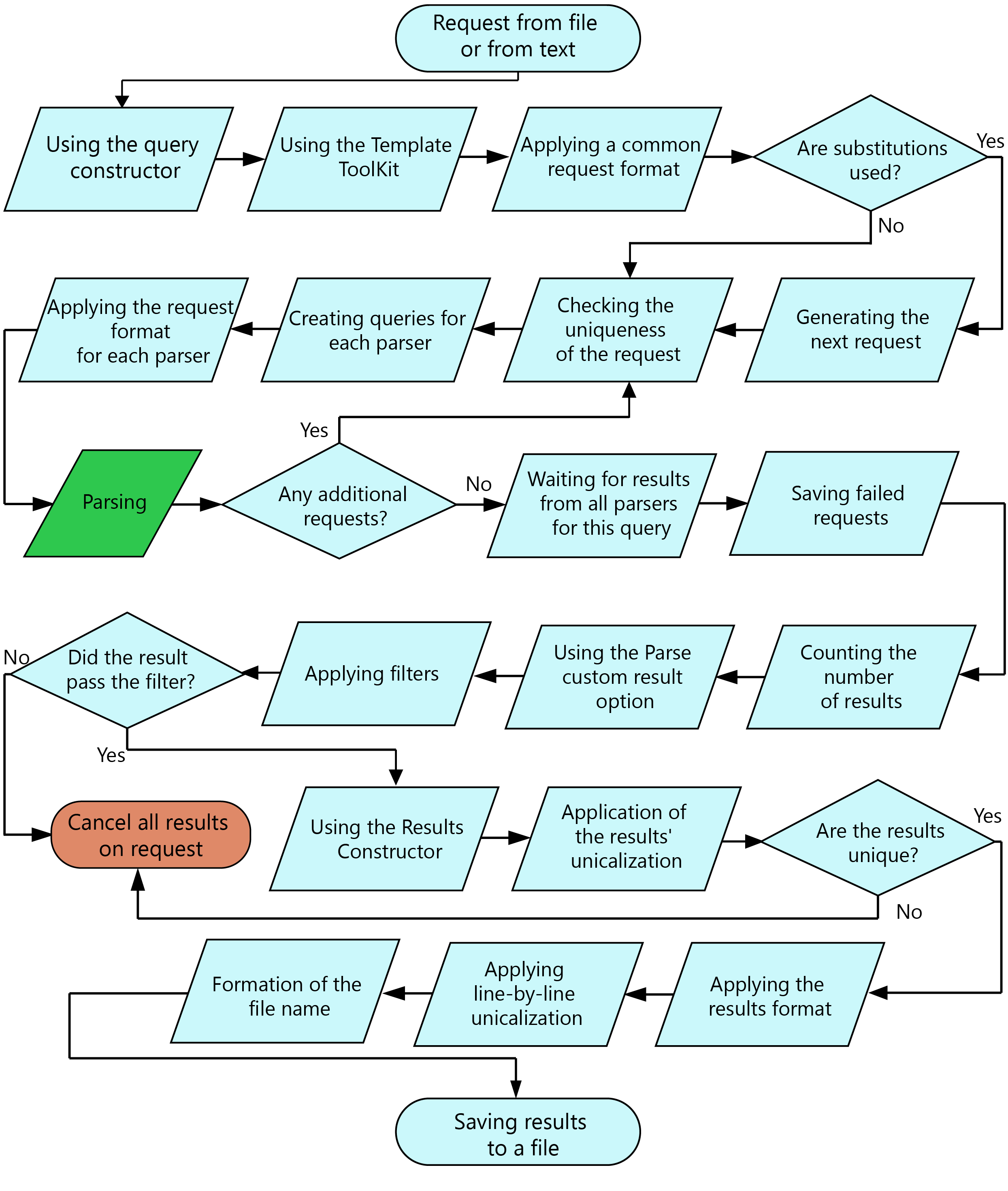
Dans A-Parser, il existe de nombreuses fonctions et possibilités ; ce diagramme présente l'ordre de traitement d'une requête, de sa lecture depuis un fichier (ou texte) jusqu'à la sauvegarde du résultat final dans un fichier.
Schéma de l'ordre de traitement d'une requête
Remarques
- Lors du filtrage et de la déduplication des résultats, la requête et ses résultats sont annulés entièrement si un résultat simple est utilisé comme base de comparaison ; si un tableau est utilisé dans la comparaison, les éléments de ce tableau sont supprimés.
- De nombreuses étapes du diagramme sont optionnelles et dépendent des paramètres indiqués dans l'Éditeur de tâches.
- Des requêtes supplémentaires peuvent apparaître lors de l'utilisation des options Parser tous les résultats / Parse all results et Parser jusqu'au niveau / Parse to level. Toutes les requêtes supplémentaires ont un niveau suivant par rapport à la requête dont elles sont issues ; le décompte des niveaux commence à zéro, c'est-à-dire que les requêtes initiales provenant d'un fichier ou d'un texte ont toujours le niveau 0. Les requêtes après application des substitutions ont également le niveau 0.
Requêtes échouées
Une requête est considérée comme échouée et est ignorée si elle n'a pas pu être exécutée après le nombre de tentatives indiqué.
Comment déterminer pourquoi une requête a échoué ? Activez la journalisation ou lancez un Test de tâche. Toutes les erreurs sont enregistrées dans le log. En étudiant le log, vous pourrez comprendre ce qui n'a pas fonctionné.
Exemple d'une requête échouée. Les logs indiquent que la requête n'a pas pu être exécutée à cause d'un captcha et que les tentatives sont épuisées. Dans ce cas, l'utilisation d'un service de résolution de captcha ou l'augmentation du nombre de tentatives peut aider (uniquement si vous utilisez des proxies, sinon augmenter les tentatives est inutile).
Comment augmenter le nombre de tentatives ? Vous devez redéfinir l'option Request retries et définir une valeur plus élevée.