Ergebnis-Unique-Prüfung
Unikalisierung, Deduplizierung, Entfernen von Duplikaten, Entfernen von Wiederholungen – all dies bedeutet, dass wir keine sich wiederholenden Ergebnisse benötigen. In A-Parser gibt es 2 Methoden der Unikalisierung, wir werden jede im Detail analysieren.
Unikalisierung der Ergebnisse nach Zeile
Diese Methode arbeitet nach der Ergebnisformatierung; unmittelbar vor dem Schreiben des Ergebnisses in die Datei wird jede Zeile auf Einzigartigkeit geprüft, und es werden nur neue, einzigartige Zeilen in die Datei geschrieben.
Siehe auch: Reihenfolge der Abfrageverarbeitung
Die Unikalisierung nach Zeile kann im Schnell-Auftrag aktiviert werden:
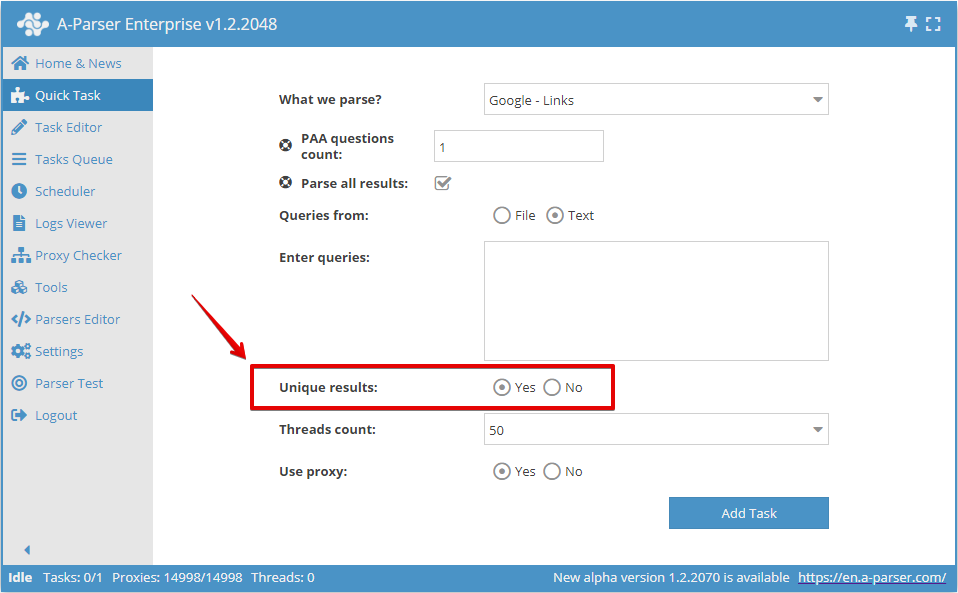
Oder im Task-Editor:
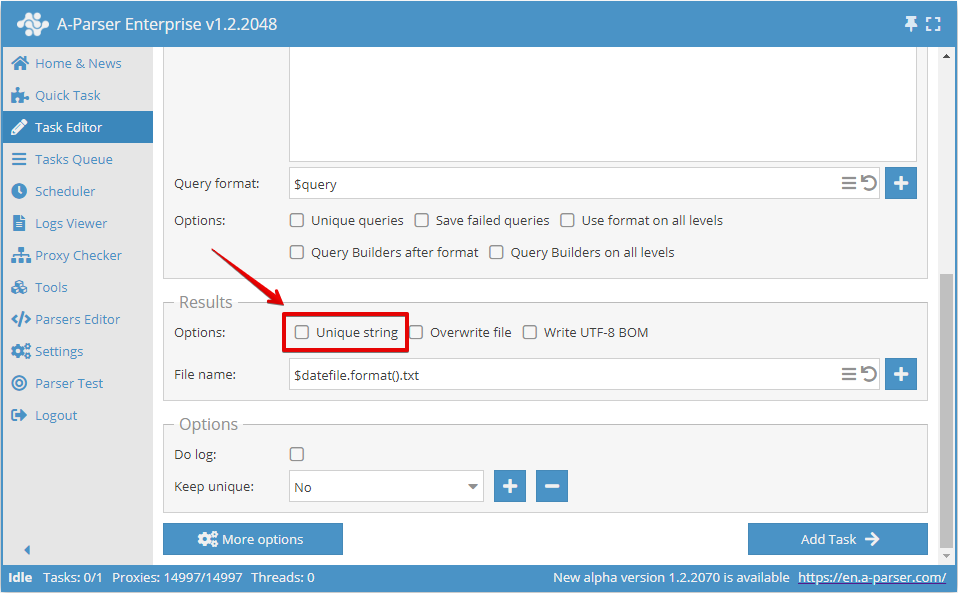
Unikalisierung nach beliebigem Ergebnis
Die Unikalisierung nach beliebigem Ergebnis ermöglicht die Unikalisierung direkt am ausgewählten Ergebnis eines bestimmten Scrapers. Sie können diesen Unikalisierungstyp im Task-Editor hinzufügen, indem Sie auf das Werkzeug-Icon rechts neben dem Scraper klicken und auf Add unique result (Unikalisierung hinzufügen) drücken:
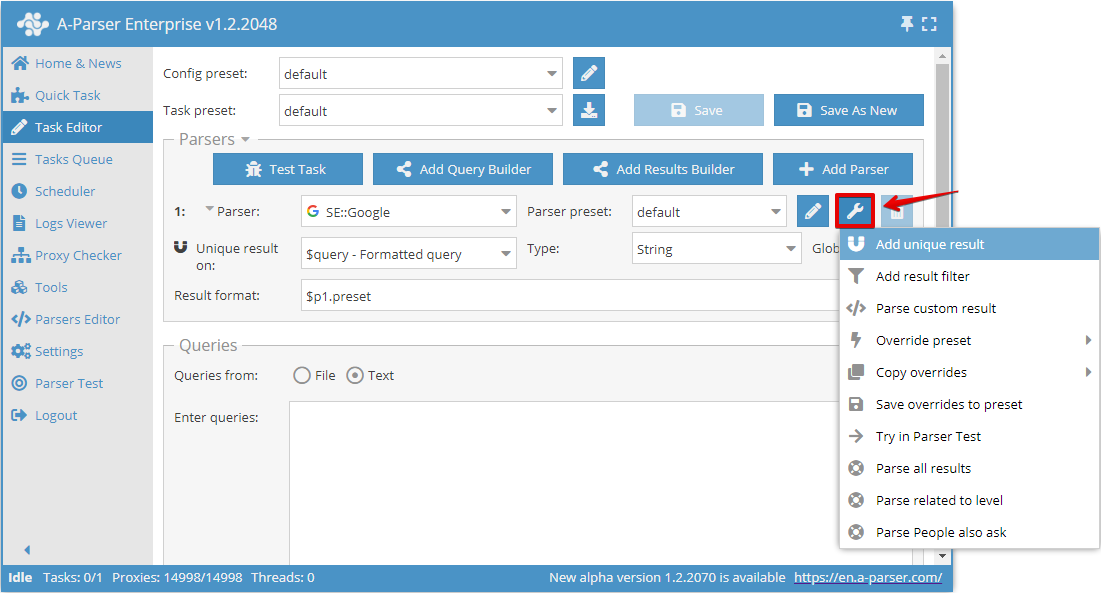
Nun können Sie wählen, für welches Ergebnis die Unikalisierung durchgeführt werden soll und den Unikalisierungstyp festlegen:
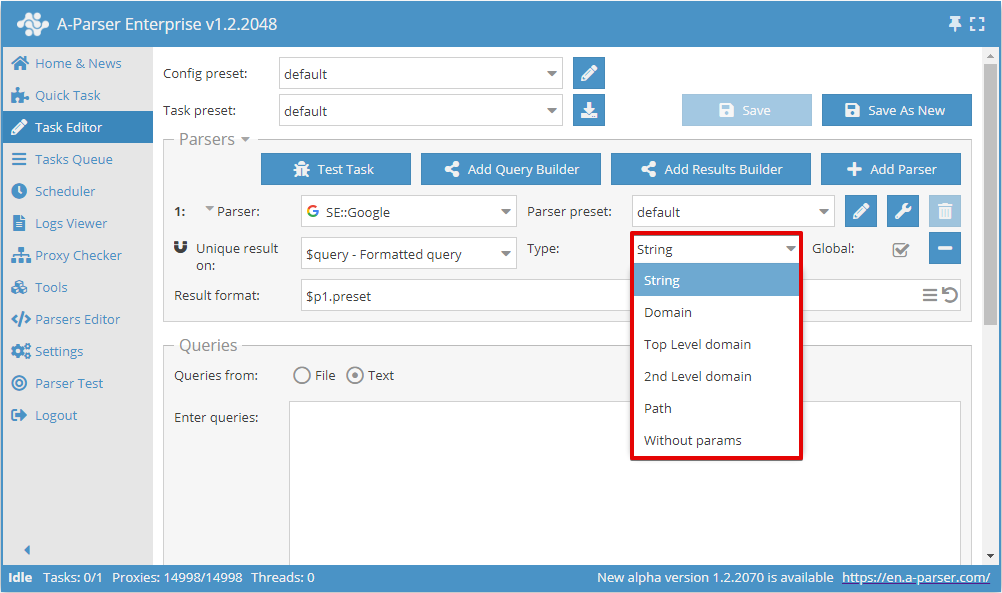
Der Schalter Global wird verwendet, wenn 2 oder mehr Scraper ausgewählt sind; er bestimmt, ob eine gemeinsame Unikalisierung oder eine separate für jeden Scraper durchgeführt werden soll.
Unikalisierungstypen
| Parameter | Beschreibung |
|---|---|
| String | Unikalisierung nach Zeile (die gesamte Ergebniszeile wird verglichen) |
| Domain | Unikalisierung nach Domain (die gesamte Domain wird verglichen, z. B. sind www.domain.com und domain.com unterschiedliche Domains) |
| Top Level domain | Unikalisierung nach der Hauptdomain unter Berücksichtigung regionaler, kommerzieller, bildungsbezogener und anderer Domains (z. B. sind domain.co.uk und domain2.co.uk unterschiedliche Domains, während sub1.domain.com und sub2.domain.com gleich sind) |
| Second-Level-Domain | Unikalisierung nach der Second-Level-Domain (es werden Domains der zweiten Ebene verglichen, z. B. sind www.domain.com, domain.com und user.subdomain.domain.com alle dieselbe Domain) |
| Path | Unikalisierung nach Pfad (Teile des Links bis zur Datei werden verglichen, z. B. sind http://domain.com/path1/file.php und http://domain.com/path1/file2.php identische Linkteile bis zur Datei) |
| Without params | Unikalisierung nach Link ohne Parameter (Links werden ohne Parameter verglichen, z. B. sind http://domain.com/file.php?page=1 und http://domain.com/file.php?page=2 identische Links) |
Unikalisierung von Abfragen
Die Unikalisierung von Abfragen sendet nur einzigartige Abfragen zur Datenerfassung, die im aktuellen Auftrag noch nicht verarbeitet wurden. Hauptanwendungsfälle:
- Wenn die ursprünglichen Abfragen Duplikate enthalten und deren Datenerfassung unerwünscht ist (doppelte Arbeit)
- Bei Verwendung der Option Parse to level (Bis zur Ebene extrahieren / Parse to level) ist es erforderlich, nur eindeutige Abfragen zu verwenden, um ein unkontrolliertes Anwachsen oder Endlosschleifen von Abfragen zu verhindern (zum Beispiel bei Verwendung des Parsers
 HTML::LinkExtractor)
HTML::LinkExtractor)
In allen anderen Fällen verlangsamt die unnötige Verwendung der Abfrage-Unikalisierung lediglich die Gesamtgeschwindigkeit des Parsers
Speichern der Unikalisierung zwischen Aufgaben
Es besteht die Möglichkeit, die Unique-Datenbank zu speichern, um sie in zukünftigen Aufgaben zu verwenden. Dies ermöglicht es, in neuen Aufgaben nur neue, eindeutige Ergebnisse zu speichern (zum Beispiel Links bei der Datenerfassung von SERPs in  SE::Google)
SE::Google)
Um die Unikalisierungsdatenbank zu speichern, müssen Sie beim Hinzufügen der ersten Aufgabe einen neuen Datenbanknamen erstellen:
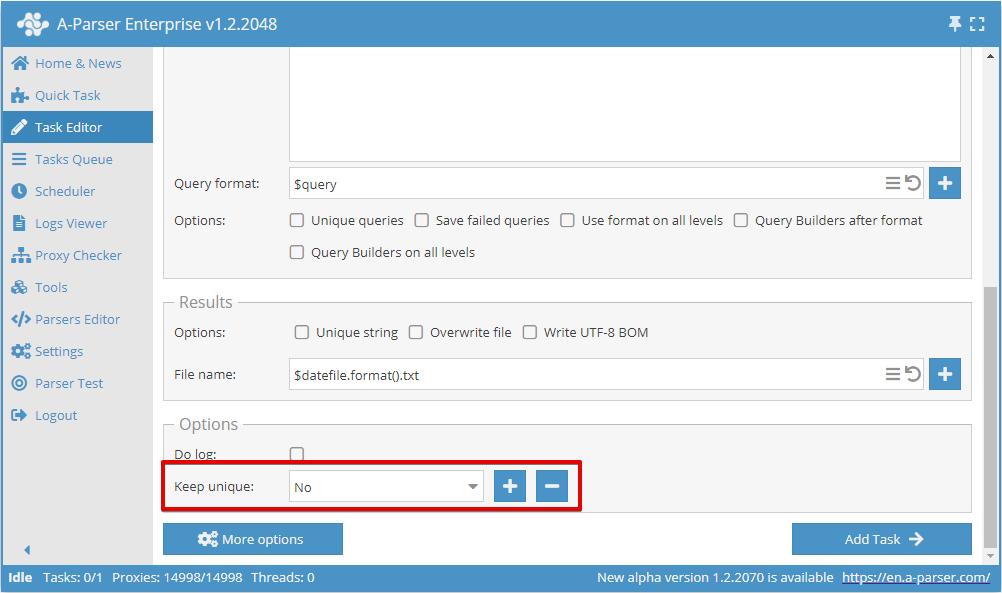
Für alle nachfolgenden Aufgaben müssen Sie den zuvor erstellten Datenbanknamen auswählen. Dadurch werden nur neue, einzigartige Ergebnisse gespeichert, unabhängig davon, ob die Ergebnisse in dieselbe Datei wie in der ersten Aufgabe oder in eine neue Datei geschrieben werden.