Gerenciamento do Chrome (puppeteer)
O A-Parser permite utilizar o navegador Chrome (Chromium) como motor para descarregar e renderizar páginas, utilizando a popular biblioteca puppeteer.
Principais vantagens de trabalhar com puppeteer em conjunto com o A-Parser:
- suporte a proxies separados para cada aba do navegador
- gerenciamento de abas do navegador em múltiplas threads
- interceptação de requisições
- todos os recursos do A-Parser para gerenciamento de fila, formação de consultas e processamento de resultados
O uso do navegador Chrome abre as seguintes possibilidades:
- renderização de
DOMeJavaScript - possibilidade de trabalho interativo com elementos dos sites:
- preenchimento de formulários
- navegação por links
- drag & drop
- download de arquivos
- emulação de mouse
- e muito mais, qualquer ação padrão pode ser automatizada
- contorno mais simples de diversas proteções contra extração de dados, pois o navegador Chromium é o mais semelhante possível ao utilizado pelos usuários
- possibilidade de trabalhar no modo
Headless, ou seja, sem interface gráfica do navegador, o que permite economizar recursos, além de executar o navegador em servidores sem ambiente gráfico
É necessário considerar que o funcionamento do navegador é muito mais exigente em termos de recursos (CPU, Memória) do que as threads comuns do A-Parser
Dependendo da complexidade do site, recomenda-se utilizar um número de threads (abas do navegador) não superior a 1-2 para cada núcleo de processador disponível, por exemplo, para processadores de 8 núcleos - de 8 a 16 abas
Exemplo de uso
Vamos analisar o exemplo do scraper Chrome::ScreenshotMaker2:
- o scraper tira capturas de tela de sites no tamanho especificado e também pode reduzir (redimensionar) a imagem
- pode opcionalmente usar proxy
- cria uma aba de navegador separada para cada thread do A-Parser
import { BaseParser, PuppeteerTypes } from 'a-parser-types';
let browser: PuppeteerTypes.Browser;
let jimp;
class JS_Chrome_ScreenshotsMaker2 extends BaseParser {
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.2.1',
results: {
flat: [
['screenshot', 'PNG screenshot'],
]
},
results_format: '$screenshot',
load_timeout: 30,
width: 1024,
height: 768,
log_screenshots: 0,
headless: 1,
};
static editableConf: typeof BaseParser.editableConf = [
['log_screenshots', ['checkbox', 'Log Screenshots']],
['width', ['textfield', 'Viewport Width']],
['height', ['textfield', 'Viewport Height']],
['resize_width', ['textfield', 'Resize Width']],
['resize_height', ['textfield', 'Resize Height']],
['headless', ['checkbox', 'Chrome Headless']],
];
async init() {
// inicializamos o navegador
browser = await this.puppeteer.launch({
headless: this.conf.headless,
logConnections: false,
defaultViewport: {
width: parseInt(this.conf.width),
height: parseInt(this.conf.height),
}
});
if (this.conf.resize_width) {
// conectamos o módulo jimp se for necessário fazer resize da captura de tela
jimp = require('jimp');
};
};
async destroy() {
// fechamos o navegador ao concluir o trabalho da tarefa
if (browser)
await browser.close();
}
page: PuppeteerTypes.Page;
async threadInit() {
// criamos uma página do navegador ao inicializar a thread
this.page = await browser.newPage();
// métodos padrão do puppeteer
await this.page.setCacheEnabled(true);
await this.page.setDefaultNavigationTimeout(this.conf.timeout * 1000);
// indicamos ao A-Parser para usar proxy para esta página
await this.puppeteer.setPageUseProxy(this.page);
this.logger.put(`New page created for thread #${this.threadId}`);
}
async parse(set, results) {
const self = this;
const { conf, page } = self;
for (let attempt = 1; attempt <= conf.proxyretries; attempt++) {
try {
self.logger.put(`Attempt #${attempt}`);
// navegamos para a página especificada na consulta
await page.goto(set.query);
// ocultamos a barra de rolagem para a captura de tela
await page.evaluate(() => { document.querySelector('html').style.overflow = 'hidden'; });
// obtemos a captura de tela
results.screenshot = await page.screenshot();
if (parseInt(conf.resize_width)) {
// se necessário, redimensionamos a imagem
let image = await jimp.read(results.screenshot);
image.resize(parseInt(conf.resize_width), parseInt(conf.resize_height));
results.screenshot = await image.getBufferAsync('image/png');
}
self.logger.put(`Screenshot(${attempt}): OK, size: ${parseInt("" + (results.screenshot.length / 1024))}KB`);
if (conf.log_screenshots)
self.logger.putHTML("<img src='data:image/png;base64," + results.screenshot.toString('base64') + "'>");
results.success = 1;
// fechamos as conexões atuais, pois o navegador usa keep-alive
await self.puppeteer.closeActiveConnections();
break;
}
catch (error) {
self.logger.put(`Fetch page error: ${error}`);
// fechamos as conexões atuais, pois o navegador usa keep-alive
await self.puppeteer.closeActiveConnections();
// mudamos o proxy para a aba do navegador
await self.proxy.next();
}
}
return results;
}
}
Este exemplo demonstra a simplicidade de usar diferentes proxies para cada aba, bem como o trabalho em múltiplas threads (1 thread = 1 aba do navegador)
Descrição dos métodos
await this.puppeteer.launch(opts?)
Este método é análogo ao método .launch da biblioteca puppeteer, ele inicia o navegador Chromium com as opções opts necessárias. A principal diferença reside na integração com o A-Parser e no suporte a proxy para cada aba, além da presença de opções adicionais:
logConnections?: boolean
Ativa o log de todas as conexões (independentemente de usar proxy ou não), a saída do log é feita separadamente por threads
stealth?: boolean
Usa o plugin puppeteer-extra para mascarar o Chromium como um Chrome real
stealthOpts?: any
Opções adicionais para o plugin puppeteer-extra
extraPlugins?: array
Uso de plugins adicionais, como por exemplo puppeteer-extra/packages
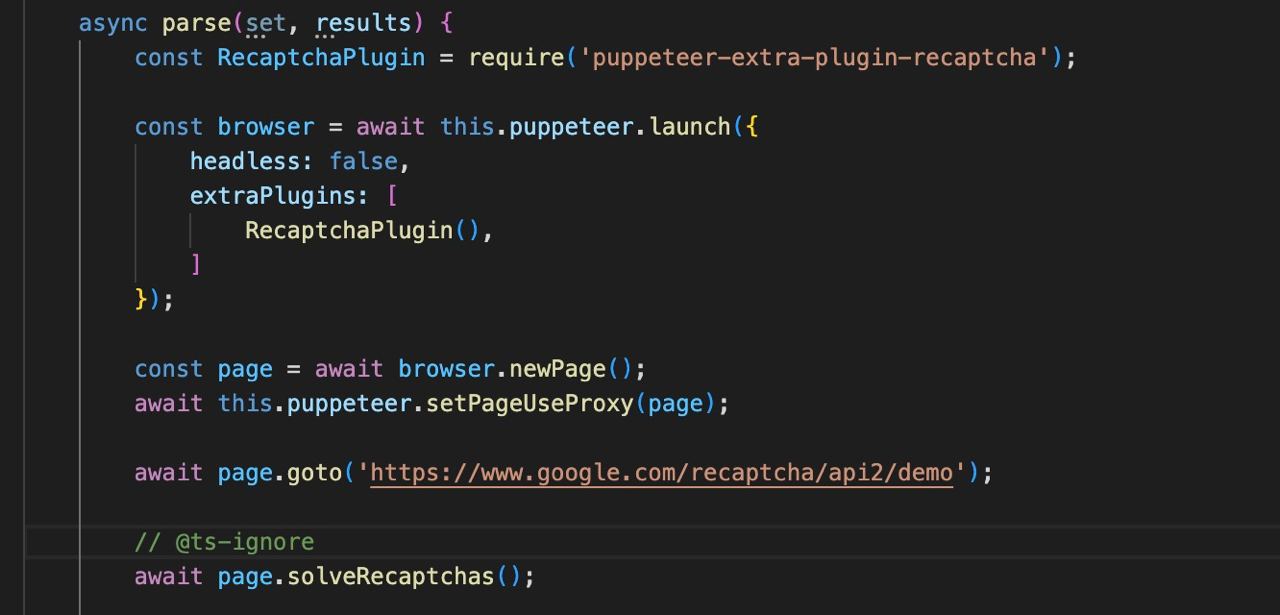
Outras opções
Todas as outras opções de inicialização podem ser consultadas na documentação original do puppeteer
await this.puppeteer.setPageUseProxy(page)
Este método vincula a página do navegador à thread do A-Parser para o funcionamento correto do proxy; ele deve ser chamado imediatamente após a criação da página:
const page = await browser.newPage();
await this.puppeteer.setPageUseProxy(page);
await this.puppeteer.closeActiveConnections(page?)
Este método deve ser chamado após a conclusão do processamento da consulta ou antes de mudar o proxy para processar a próxima tentativa
O navegador Chrome por padrão mantém conexões abertas com os sites aos quais se conecta; este método permite controlar o número de recursos utilizados, além de reduzir a carga no proxy
O argumento page é opcional; quando chamado sem argumento, o A-Parser fechará as conexões para a aba vinculada à thread atual
await this.puppeteer.logScreenshot()
O método registra a captura de tela da página atual