Zarządzanie Chrome (puppeteer)
A-Parser pozwala na wykorzystanie przeglądarki Chrome (Chromium) jako silnika do pobierania i renderowania stron, korzystając z popularnej biblioteki puppeteer.
Główne zalety pracy puppeteer wspólnie z A-Parser:
- wsparcie dla oddzielnych proxy dla każdej karty przeglądarki
- wielowątkowe zarządzanie kartami przeglądarki
- przechwytywanie żądań
- wszystkie możliwości A-Parser w zakresie zarządzania kolejką, formowania zapytań i przetwarzania wyników
Wykorzystanie przeglądarki Chrome otwiera następujące możliwości:
- renderowanie
DOMiJavaScript - możliwość interaktywnej pracy z elementami stron:
- wypełnianie formularzy
- przechodzenie po linkach
- drag & drop
- pobieranie plików
- emulacja myszy
- i wiele więcej, zautomatyzować można dowolne standardowe działania
- łatwiejsze omijanie różnych zabezpieczeń przed scrapowaniem, ponieważ przeglądarka Chromium jest maksymalnie zbliżona do tej używanej przez użytkowników
- możliwość pracy w trybie
Headless, tj. bez interfejsu graficznego przeglądarki, co pozwala oszczędzać zasoby, a także uruchamiać przeglądarkę na serwerach bez środowiska graficznego
Należy wziąć pod uwagę, że praca przeglądarki jest znacznie bardziej wymagająca pod względem zasobów (CPU, Memory) niż zwykłe wątki A-Parser
W zależności od złożoności strony, zaleca się stosowanie liczby wątków (kart przeglądarki) nie większej niż 1-2 na każdy dostępny rdzeń procesora, na przykład dla procesorów 8-rdzeniowych - od 8 do 16 kart
Przykład użycia
Przeanalizujmy na przykładzie scrapera Chrome::ScreenshotMaker2:
- scraper wykonuje zrzuty ekranu stron o określonym rozmiarze, a także może pomniejszać (skalować) obraz
- może opcjonalnie korzystać z proxy
- tworzy oddzielną kartę przeglądarki dla każdego wątku A-Parser
import { BaseParser, PuppeteerTypes } from 'a-parser-types';
let browser: PuppeteerTypes.Browser;
let jimp;
class JS_Chrome_ScreenshotsMaker2 extends BaseParser {
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.2.1',
results: {
flat: [
['screenshot', 'PNG screenshot'],
]
},
results_format: '$screenshot',
load_timeout: 30,
width: 1024,
height: 768,
log_screenshots: 0,
headless: 1,
};
static editableConf: typeof BaseParser.editableConf = [
['log_screenshots', ['checkbox', 'Log Screenshots']],
['width', ['textfield', 'Viewport Width']],
['height', ['textfield', 'Viewport Height']],
['resize_width', ['textfield', 'Resize Width']],
['resize_height', ['textfield', 'Resize Height']],
['headless', ['checkbox', 'Chrome Headless']],
];
async init() {
// inicjalizujemy przeglądarkę
browser = await this.puppeteer.launch({
headless: this.conf.headless,
logConnections: false,
defaultViewport: {
width: parseInt(this.conf.width),
height: parseInt(this.conf.height),
}
});
if (this.conf.resize_width) {
// podłączamy moduł jimp jeśli konieczne jest wykonanie resize zrzutu ekranu
jimp = require('jimp');
};
};
async destroy() {
// zamykamy przeglądarkę po zakończeniu pracy zadania
if (browser)
await browser.close();
}
page: PuppeteerTypes.Page;
async threadInit() {
// tworzymy stronę przeglądarki podczas inicjalizacji wątku
this.page = await browser.newPage();
// standardowe metody puppeteer
await this.page.setCacheEnabled(true);
await this.page.setDefaultNavigationTimeout(this.conf.timeout * 1000);
// wskazujemy A-Parser, aby używał proxy dla danej strony
await this.puppeteer.setPageUseProxy(this.page);
this.logger.put(`New page created for thread #${this.threadId}`);
}
async parse(set, results) {
const self = this;
const { conf, page } = self;
for (let attempt = 1; attempt <= conf.proxyretries; attempt++) {
try {
self.logger.put(`Attempt #${attempt}`);
// przechodzimy na stronę wskazaną w zapytaniu
await page.goto(set.query);
// ukrywamy pasek przewijania dla zrzutu ekranu
await page.evaluate(() => { document.querySelector('html').style.overflow = 'hidden'; });
// pobieramy zrzut ekranu
results.screenshot = await page.screenshot();
if (parseInt(conf.resize_width)) {
// w razie potrzeby zmieniamy rozmiar obrazu
let image = await jimp.read(results.screenshot);
image.resize(parseInt(conf.resize_width), parseInt(conf.resize_height));
results.screenshot = await image.getBufferAsync('image/png');
}
self.logger.put(`Screenshot(${attempt}): OK, size: ${parseInt("" + (results.screenshot.length / 1024))}KB`);
if (conf.log_screenshots)
self.logger.putHTML("<img src='data:image/png;base64," + results.screenshot.toString('base64') + "'>");
results.success = 1;
// zamykamy bieżące połączenia, ponieważ przeglądarka używa keep-alive
await self.puppeteer.closeActiveConnections();
break;
}
catch (error) {
self.logger.put(`Fetch page error: ${error}`);
// zamykamy bieżące połączenia, ponieważ przeglądarka używa keep-alive
await self.puppeteer.closeActiveConnections();
// zmieniamy proxy dla karty przeglądarki
await self.proxy.next();
}
}
return results;
}
}
Ten przykład demonstruje prostotę użycia różnych proxy dla każdej karty, a także pracę wielowątkową (1 wątek = 1 karta przeglądarki)
Opis metod
await this.puppeteer.launch(opts?)
Ta metoda jest analogiczna do metody .launch biblioteki puppeteer, uruchamia ona przeglądarkę Chromium z niezbędnymi opcjami opts. Główna różnica polega na integracji z A-Parser i wsparciu dla proxy dla każdej karty, a także na obecności dodatkowych opcji:
logConnections?: boolean
Włącza logowanie wszystkich połączeń (niezależnie od tego, czy z użyciem proxy, czy bez), wyprowadzanie logu odbywa się oddzielnie dla każdego wątku
stealth?: boolean
Używa wtyczki puppeteer-extra do maskowania Chromium jako prawdziwego Chrome
stealthOpts?: any
Dodatkowe opcje dla wtyczki puppeteer-extra
extraPlugins?: array
Użycie dodatkowych wtyczek, takich jak na przykład puppeteer-extra/packages
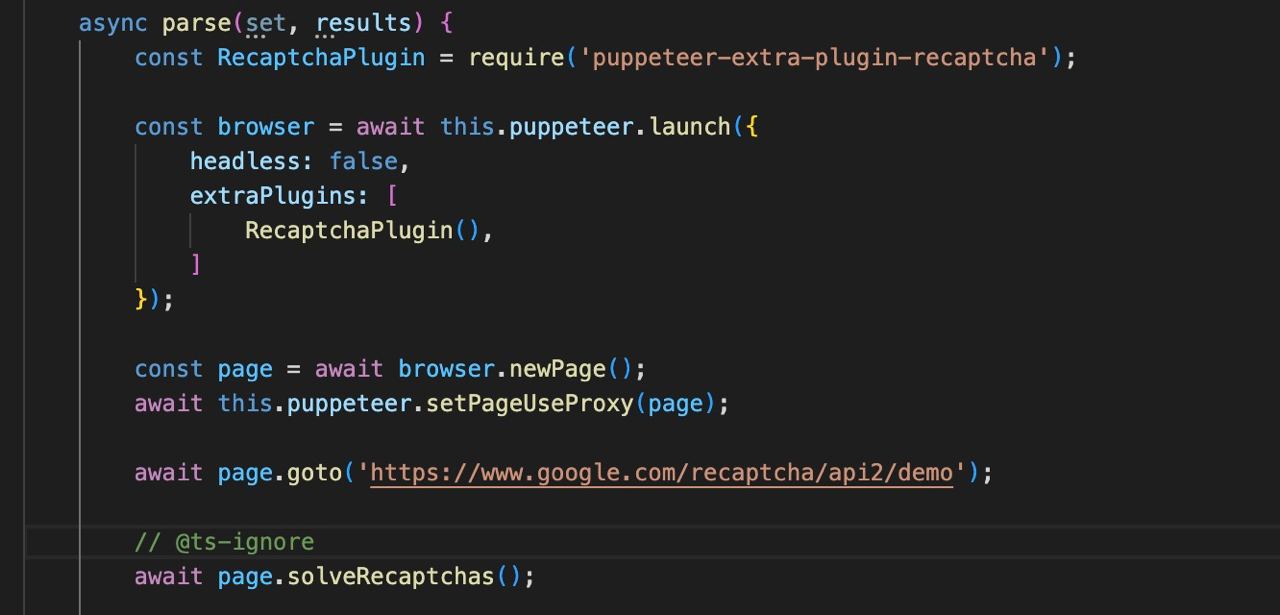
Pozostałe opcje
Wszystkie pozostałe opcje uruchamiania można sprawdzić w oryginalnej dokumentacji puppeteer
await this.puppeteer.setPageUseProxy(page)
Ta metoda wiąże stronę przeglądarki z wątkiem A-Parser w celu poprawnego działania proxy, należy ją wywołać natychmiast po utworzeniu strony:
const page = await browser.newPage();
await this.puppeteer.setPageUseProxy(page);
await this.puppeteer.closeActiveConnections(page?)
Tę metodę należy wywołać po zakończeniu przetwarzania zapytania lub przed zmianą proxy w celu przetworzenia kolejnej próby
Przeglądarka Chrome domyślnie pozostawia otwarte połączenia z witrynami, z którymi się łączy, ta metoda pozwala kontrolować liczbę używanych zasobów, a także zmniejsza obciążenie proxy
Argument page jest opcjonalny, przy wywołaniu bez argumentu A-Parser zamknie połączenia dla karty powiązanej z bieżącym wątkiem
await this.puppeteer.logScreenshot()
Metoda loguje zrzut ekranu bieżącej strony