HTTP-verzoeken (+werken met cookies, proxy's, sessies)
Methoden van de basisklasse
Om gegevens van een webpagina te verzamelen, moet een HTTP-verzoek worden uitgevoerd. In de JavaScript API v2 van A-Parser is een eenvoudig te
gebruiken methode voor het uitvoeren van HTTP-verzoeken geïmplementeerd, die als antwoord een JSON-object retourneert, afhankelijk van de opgegeven
argumenten van de methode. Hierna leert u: hoe een HTTP-verzoek wordt gedaan, welke argumenten en opties de methode heeft, de resultaten
van de opgegeven opties, hoe u de voorwaarde voor een succesvol HTTP-verzoek instelt, en meer.
Ook worden methoden beschreven waarmee u eenvoudig cookies, proxy's en de sessie in de gemaakte scraper kunt manipuleren. Na een succesvolle uitvoering van een HTTP-verzoek, of voorafgaand aan de uitvoering, kunt u proxy-/cookie-/sessiegegevens instellen/wijzigen voor het uitvoeren van HTTP-verzoeken of deze opslaan voor uitvoering door een andere thread met behulp van de Sessiebeheerder.
Deze methoden worden overgeërfd van BaseParser en vormen de basis voor het maken van eigen scrapers
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Het verkrijgen van een HTTP-antwoord op een verzoek, waarbij als argumenten worden opgegeven:
method- de methode van het verzoek (GET, POST...)url- de link voor het verzoekqueryParams- een hash met get-parameters of een hash met de body van een post-verzoekopts- een hash met opties voor het verzoek
opts.check_content
check_content: [ voorwaarde1, voorwaarde2, ...] - een array van voorwaarden om de ontvangen content te controleren; als de controle niet
slaagt, wordt het verzoek herhaald met een andere proxy.
Mogelijkheden:
- gebruik van strings als voorwaarden (zoeken op voorkomen van de string)
- gebruik van reguliere expressies als voorwaarden
- gebruik van eigen controlefuncties, waaraan de data en headers van het antwoord worden doorgegeven
- er kunnen direct meerdere verschillende typen voorwaarden worden opgegeven
- voor logische ontkenning plaatst u de voorwaarde in een array, d.w.z.
check_content: ['xxxx', [/yyyy/]]betekent dat het verzoek als succesvol wordt beschouwd als de ontvangen data de substringxxxxbevat en tegelijkertijd de reguliere expressie/yyyy/geen overeenkomsten vindt op de pagina
Voor een succesvol verzoek moeten alle in de array opgegeven controles slagen
Voorbeeld (in de commentaren staat wat er nodig is om het verzoek als succesvol te beschouwen):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // op de ontvangen pagina moet deze reguliere expressie werken
['XXXX'], // op de ontvangen pagina mag deze substring niet voorkomen
'</html>', // op de ontvangen pagina moet deze substring voorkomen
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // deze functie moet true retourneren
]
});
opts.decode
decode: 'auto-html' - automatische detectie van de codering en conversie naar utf8
Mogelijke waarden:
auto-html- op basis van headers, meta-tags en de inhoud van de pagina (de optimale aanbevolen optie)utf8- geeft aan dat het document in utf8-codering is<encoding>- elke andere codering
opts.headers
headers: { ... } - hash met headers, de naam van de header wordt in kleine letters opgegeven, u kunt o.a. cookie opgeven.
Voorbeeld:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - maakt het mogelijk om de sorteervolgorde van de headers te overschrijven
opts.onlyheaders
onlyheaders: 0 - bepaalt het lezen van data, indien ingeschakeld (1), worden alleen headers opgehaald
opts.recurse
recurse: N - het maximale aantal redirects dat gevolgd wordt, standaard 7, gebruik 0 om het volgen van
redirects uit te schakelen
opts.proxyretries
proxyretries: N - het aantal pogingen om het verzoek uit te voeren, standaard wordt dit overgenomen uit de instellingen van de scraper
opts.parsecodes
parsecodes: { ... } - lijst met HTTP-antwoordcodes die de scraper als succesvol zal beschouwen, standaard wordt dit overgenomen uit de
instellingen van de scraper. Als u '*': 1 opgeeft, worden alle antwoorden als succesvol beschouwd.
Voorbeeld:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - time-out voor het antwoord in seconden, standaard wordt dit overgenomen uit de instellingen van de scraper
opts.do_gzip
do_gzip: 1 - bepaalt of compressie (gzip/deflate/br) moet worden gebruikt, standaard ingeschakeld (1), om uit te schakelen
moet de waarde 0 worden opgegeven
opts.max_size
max_size: N - maximale grootte van het antwoord in bytes, standaard wordt dit overgenomen uit de instellingen van de scraper
opts.cookie_jar
cookie_jar: { ... } - hash met cookies. Voorbeeld van een hash:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - geeft het nummer van de huidige poging aan; bij gebruik van deze parameter wordt de ingebouwde pogingen-afhandelaar voor
dit verzoek genegeerd
opts.browser
browser: 1 - automatische emulatie van browserheaders (1 - ingeschakeld, 0 - uitgeschakeld)
opts.use_proxy
use_proxy: 1 - overschrijft het gebruik van proxy's voor een afzonderlijk verzoek binnen de JS-scraper bovenop de globale
parameter Use proxy (1 - ingeschakeld, 0 - uitgeschakeld)
opts.noextraquery
noextraquery: 0 - schakelt het toevoegen van de Extra query string aan de URL van het verzoek uit (1 - ingeschakeld, 0 - uitgeschakeld)
opts.save_to_file
save_to_file: file - maakt het mogelijk om een bestand direct naar de schijf te downloaden, zonder het in het geheugen op te slaan. In plaats van file wordt de naam en
het pad opgegeven waaronder het bestand moet worden opgeslagen. Bij gebruik van deze optie wordt alles wat met data te maken heeft genegeerd (de contentcontrole
in opts.check_content wordt niet uitgevoerd, response.data zal leeg zijn, enz.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - automatische omzeiling van CloudFlare JavaScript-beveiliging met behulp van de Chrome-browser (1 - ingeschakeld, 0 -
uitgeschakeld)
De controle over Chrome Headless wordt in dit geval uitgevoerd door de scraperinstellingen bypassCloudFlareChromeMaxPages
en bypassCloudFlareChromeHeadless, die moeten worden opgegeven in static defaultConf en static editableConf:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - maakt het mogelijk om redirects te volgen die zijn gedeclareerd via een HTML meta-tag:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - maakt het mogelijk om een filterfunctie in te stellen voor het volgen van redirects; als de functie
1 retourneert, zal de scraper de redirect volgen (rekening houdend met de parameter opts.recurse), bij het retourneren van 0 stopt het volgen van
redirects:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - bepaalt of standaard redirects gevolgd moeten worden (bijvoorbeeld http -> https
en/of www.domain.com -> domain.com); als u 1 opgeeft, zal de scraper standaard redirects volgen zonder rekening te houden met
de parameter opts.recurse
opts.http2
opts.http2: 0 - bepaalt of het HTTP/2-protocol moet worden gebruikt bij het uitvoeren van verzoeken; standaard
wordt HTTP/1.1 gebruikt
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - deze optie maakt het mogelijk om verbanningen van websites op basis van TLS-fingerprint te omzeilen (1 - ingeschakeld, 0 -
uitgeschakeld)
opts.tlsOpts
tlsOpts: { ... } – maakt het mogelijk om
instellingen voor
https-verbindingen door te geven
await this.cookies.*
Werken met cookies voor het huidige verzoek
.getAll()
Verkrijgen van een array van cookies
await this.cookies.getAll();
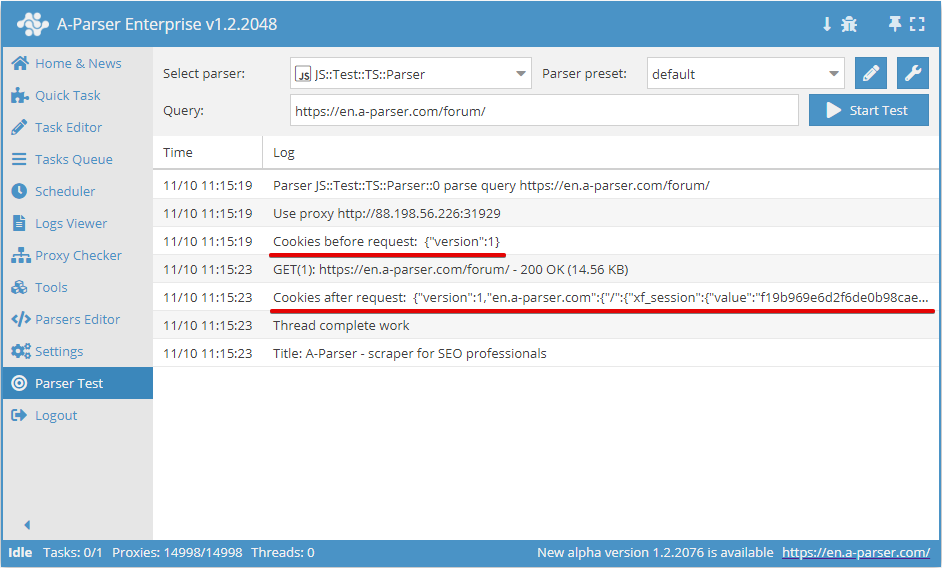
.setAll(cookie_jar)
Instellen van cookies, als argument moet een hash met cookies worden doorgegeven
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
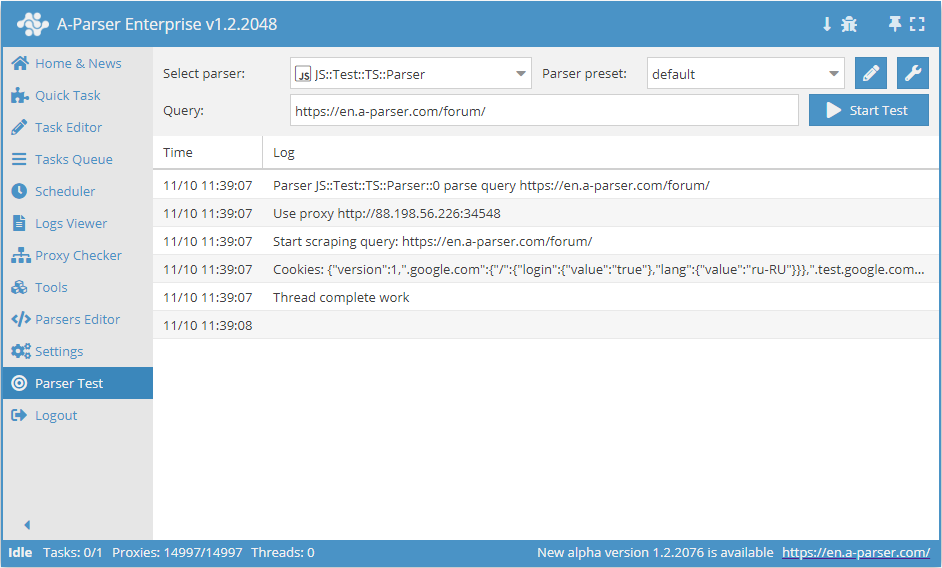
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - instellen van een enkele cookie.
De zichtbaarheid van de cookie hangt direct af van het formaat van het opgegeven domein, daarom wordt in host rekening gehouden met de aanwezigheid van een punt voor de host:
- als er een punt is opgegeven (
this.cookies.set('.domain.com', ...)), dan zal de cookie worden gebruikt voor alle subdomeinen (bijvoorbeeld a.domain.com, b.a.domain.com) - als de host is opgegeven zonder punt vooraf (
this.cookies.set('site.com', ...)), dan zal de cookie strikt voor de opgegeven host worden gebruikt (host-only cookie) en niet worden doorgegeven aan subdomeinen
Dit onderscheid is cruciaal, omdat het gelijktijdig bestaan van cookies met en zonder punt kan leiden tot hun duplicatie en onvoorspelbaar gedrag van de site. Controleer voor een correcte emulatie altijd hoe de doelsite cookies instelt (met het Domain-attribuut of zonder) en gebruik het overeenkomstige formaat.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
await this.proxy.*
Werken met proxy's
.next()
Wissel de proxy naar de volgende; de oude proxy zal niet meer worden gebruikt voor het huidige verzoek
.ban()
Wissel en ban de proxy (moet worden gebruikt wanneer de service de werking op basis van IP blokkeert); de proxy wordt verbannen voor de tijd
die is opgegeven in de instellingen van de scraper (proxybannedcleanup)
.get()
Verkrijg de huidige proxy (de laatste proxy waarmee een verzoek is gedaan)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - stel een proxy in voor het volgende verzoek. De parameter noChange is optioneel; indien ingesteld op true, zal de proxy niet veranderen tussen pogingen. Standaard is noChange = false
await this.sessionManager.*
Methoden voor het werken met sessies. Elke sessie slaat verplicht de gebruikte proxy en cookies op. Ook kunnen er aanvullende willekeurige gegevens worden opgeslagen.
Om sessies in een JS-scraper te gebruiken, moet eerst de Sessiebeheerder worden geïnitialiseerd. Dit gebeurt met de methode await this.sessionManagerinit() in init()
.init(opts?)
Initialisatie van de Sessiebeheerder. Als argument kan een object (opts) met aanvullende parameters worden doorgegeven (alle parameters zijn optioneel):
name- maakt het mogelijk om de naam van de scraper waartoe de sessies behoren te overschrijven; standaard gelijk aan de naam van de scraper waarin de initialisatie plaatsvindtwaitForSession- geeft de scraper de opdracht om op een sessie te wachten totdat deze verschijnt (dit is alleen relevant wanneer er meerdere taken draaien, bijvoorbeeld één die sessies genereert en een tweede die ze gebruikt), d.w.z..get()en.reset()zullen altijd op een sessie wachtendomain- geeft aan om sessies te zoeken tussen alle opgeslagen sessies voor deze scraper (als er geen waarde is opgegeven), of alleen voor een specifiek domein (het domein moet worden opgegeven met een punt vooraf, bijvoorbeeld.site.com)sessionsKey- maakt het mogelijk om handmatig de naam van de sessieopslag in te stellen; als deze niet is opgegeven, wordt de naam automatisch gevormd op basis vanname(of de naam van de scraper alsnameniet is opgegeven), het domein en de proxycheckerexpire- stelt de levensduur van de sessie in minuten in; standaard onbeperkt
Gebruiksvoorbeeld:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Verkrijgen van een nieuwe sessie; moet worden aangeroepen voordat het verzoek wordt uitgevoerd (vóór de eerste poging). Retourneert een object met willekeurige gegevens die in de sessie zijn opgeslagen. Als argument kan een object (opts) met aanvullende parameters worden doorgegeven (alle parameters zijn optioneel):
waitTimeout- mogelijkheid om aan te geven hoeveel minuten er gewacht moet worden op het verschijnen van een sessie; werkt onafhankelijk van de parameterwaitForSessionin.init()(negeert deze); na afloop wordt een lege sessie gebruikttag- verkrijgen van een sessie met een opgegeven tag; kan bijvoorbeeld worden gebruikt voor de domeinnaam om sessies te koppelen aan de domeinen waarvan ze zijn verkregen
Gebruiksvoorbeeld:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Wissen van cookies en verkrijgen van een nieuwe sessie. Moet worden gebruikt als het verzoek met de huidige sessie niet succesvol was. Retourneert een object met willekeurige gegevens die in de sessie zijn opgeslagen. Als argument kan een object (opts) met aanvullende parameters worden doorgegeven (alle parameters zijn optioneel):
waitTimeout- mogelijkheid om aan te geven hoeveel minuten er gewacht moet worden op het verschijnen van een sessie; werkt onafhankelijk van de parameterwaitForSessionin.init()(negeert deze); na afloop wordt een lege sessie gebruikttag- verkrijgen van een sessie met een opgegeven tag; kan bijvoorbeeld worden gebruikt voor de domeinnaam om sessies te koppelen aan de domeinen waarvan ze zijn verkregen
Gebruiksvoorbeeld:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Opslaan van een succesvolle sessie met de mogelijkheid om willekeurige gegevens in de sessie op te slaan. Ondersteunt 2 optionele argumenten:
sessionOpts- willekeurige gegevens voor opslag in de sessie; dit kan een getal, string, array of object zijnsaveOpts- object met parameters voor het opslaan van de sessie:multiply- optionele parameter, maakt het mogelijk om de sessie te vermenigvuldigen; als waarde moet een getal worden opgegeventag- optionele parameter, stelt een tag in voor de opgeslagen sessie; kan bijvoorbeeld worden gebruikt voor de domeinnaam om sessies te koppelen aan de domeinen waarvan ze zijn verkregen
Gebruiksvoorbeeld:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Retourneert het aantal sessies voor de huidige Sessiebeheerder
Gebruiksvoorbeeld:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Verwijdert alle sessies met een opgegeven id. Retourneert het aantal verwijderde sessies. De id van de huidige sessie bevindt zich in de variabele this.sessionId
Gebruiksvoorbeeld:
const removedCount = await this.sessionManager.removeById(this.sessionId);
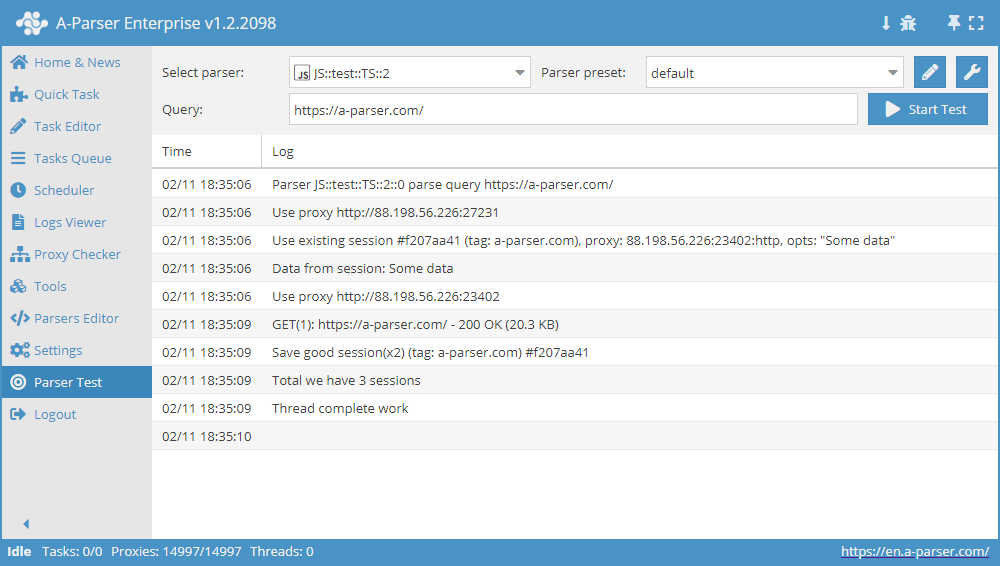
Complex gebruiksvoorbeeld van de Sessiebeheerder
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Verzoekmethoden await this.request
GET-methode
U kunt verzoekparameters direct in de verzoekstring doorgeven https://a-parser.com/users/?type=staff:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
Of als een object in queryParams, waarbij key: value gelijk is aan param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
POST-methode
Als de POST-methode wordt gebruikt, kan de body van het verzoek op twee manieren worden doorgegeven:
De namen van de variabelen en hun waarden opsommen in
queryParams, bijvoorbeeld:{
"key": set.query,
"id": 1234,
"type": "text"
}Ze opsommen in
opts.body, bijvoorbeeld:body: 'key=' + set.query + '&id=1234&type=text'
Als de body van het verzoek als een object wordt doorgegeven, wordt dit automatisch geconverteerd naar de vorm form-urlencoded. Ook als body is opgegeven en er geen
content-type header is opgegeven, wordt automatisch content-type: application/x-www-form-urlencoded toegewezen:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Als de body van het POST-verzoek een string of buffer is, wordt deze ongewijzigd doorgegeven:
// verzoek met een string
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// verzoek met een buffer
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Bestanden uploaden
Een bestand verzenden met een POST-verzoek met behulp van de module form-data:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Voorbeeld van het verzenden van een bestand in een POST-verzoek met het content-type multipart/form-data:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});