Richieste HTTP (+gestione cookie, proxy, sessioni)
Metodi della classe base
Per raccogliere dati da una pagina web è necessario eseguire una richiesta HTTP. In JavaScript API v2 di A-Parser è implementato un metodo di facile
utilizzo per l'esecuzione di richieste HTTP, che restituisce come risposta un oggetto JSON a seconda degli
argomenti specificati del metodo. Di seguito scoprirai: come viene effettuata una richiesta HTTP, quali argomenti e opzioni ha il metodo, i risultati
delle opzioni specificate, come specificare la condizione di successo di una richiesta HTTP e altro ancora.
Vengono inoltre descritti i metodi che consentono di manipolare facilmente cookie, proxy e sessioni nello scraper creato. Dopo l'esecuzione con successo di una richiesta HTTP, o prima dell'esecuzione, è possibile impostare/modificare i dati di proxy/cookie/sessione per l'esecuzione delle richieste HTTP o salvarli per l'esecuzione da parte di un altro thread utilizzando il Gestore sessioni.
Questi metodi sono ereditati da BaseParser e costituiscono la base per la creazione di scraper personalizzati
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Ottenimento di una risposta HTTP su richiesta, come argomenti si specifica:
method- metodo della richiesta (GET, POST...)url- link per la richiestaqueryParams- hash con parametri get o hash con il corpo della richiesta postopts- hash con le opzioni della richiesta
opts.check_content
check_content: [ condizione1, condizione2, ...] - array di condizioni per verificare il contenuto ricevuto; se la verifica non
va a buon fine, la richiesta verrà ripetuta con un altro proxy.
Possibilità:
- utilizzo di stringhe come condizioni (ricerca per occorrenza della stringa)
- utilizzo di espressioni regolari come condizioni
- utilizzo di proprie funzioni di verifica, a cui vengono passati i dati e gli header della risposta
- è possibile impostare contemporaneamente diversi tipi di condizioni
- per la negazione logica, inserire la condizione in un array, ovvero
check_content: ['xxxx', [/yyyy/]]significa che la richiesta sarà considerata riuscita se i dati ricevuti contengono la sottostringaxxxxe allo stesso tempo l'espressione regolare/yyyy/non trova corrispondenze nella pagina
Per una richiesta riuscita, devono passare tutte le verifiche specificate nell'array
Esempio (nei commenti è indicato cosa serve affinché la richiesta sia considerata riuscita):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // questa espressione regolare deve corrispondere nella pagina ricevuta
['XXXX'], // questa sottostringa non deve essere presente nella pagina ricevuta
'</html>', // questa sottostringa deve essere presente nella pagina ricevuta
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // questa funzione deve restituire true
]
});
opts.decode
decode: 'auto-html' - rilevamento automatico della codifica e conversione in utf8
Valori possibili:
auto-html- basato su header, tag meta e contenuto della pagina (opzione consigliata ottimale)utf8- indica che il documento è in codifica utf8<encoding>- qualsiasi altra codifica
opts.headers
headers: { ... } - hash con gli header, il nome dell'header va specificato in minuscolo, è possibile indicare anche i cookie.
Esempio:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - consente di ridefinire l'ordine di ordinamento degli header
opts.onlyheaders
onlyheaders: 0 - determina la lettura di data, se abilitato (1), riceve solo gli header
opts.recurse
recurse: N - numero massimo di passaggi per i redirect, predefinito 7, usa 0 per disabilitare il passaggio per i
redirect
opts.proxyretries
proxyretries: N - numero di tentativi di esecuzione della richiesta, per impostazione predefinita viene preso dalle impostazioni dello scraper
opts.parsecodes
parsecodes: { ... } - elenco dei codici di risposta HTTP che lo scraper considererà riusciti, per impostazione predefinita viene preso dalle
impostazioni dello scraper. Se si specifica '*': 1 allora tutte le risposte saranno considerate riuscite.
Esempio:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - timeout della risposta in secondi, per impostazione predefinita viene preso dalle impostazioni dello scraper
opts.do_gzip
do_gzip: 1 - determina se utilizzare la compressione (gzip/deflate/br), per impostazione predefinita abilitato (1), per disabilitare
è necessario impostare il valore 0
opts.max_size
max_size: N - dimensione massima della risposta in byte, per impostazione predefinita viene preso dalle impostazioni dello scraper
opts.cookie_jar
cookie_jar: { ... } - hash con i cookie. Esempio di hash:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - indica il numero del tentativo corrente, quando si utilizza questo parametro il gestore dei tentativi integrato per
questa richiesta viene ignorato
opts.browser
browser: 1 - emulazione automatica degli header del browser (1 - abilitato, 0 - disabilitato)
opts.use_proxy
use_proxy: 1 - ridefinisce l'uso del proxy per una singola richiesta all'interno dello scraper JS rispetto al parametro globale
Use proxy (1 - abilitato, 0 - disabilitato)
opts.noextraquery
noextraquery: 0 - disabilita l'aggiunta di Extra query string all'url della richiesta (1 - abilitato, 0 - disabilitato)
opts.save_to_file
save_to_file: file - consente di scaricare un file direttamente su disco, evitando la scrittura in memoria. Al posto di file si specifica il nome e il
percorso con cui salvare il file. Quando si utilizza questa opzione, viene ignorato tutto ciò che riguarda data (la verifica del contenuto
in opts.check_content non verrà eseguita, response.data sarà vuoto, ecc.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - bypass automatico della protezione JavaScript di CloudFlare utilizzando il browser Chrome (1 - abilitato, 0 -
disabilitato)
Il controllo di Chrome Headless in questo caso è gestito dalle impostazioni dello scraper bypassCloudFlareChromeMaxPages
e bypassCloudFlareChromeHeadless, che devono essere specificate in static defaultConf e static editableConf:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - consente di seguire i redirect dichiarati tramite il meta tag HTML:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - consente di impostare una funzione di filtraggio per il passaggio dei redirect; se la funzione
restituisce 1, lo scraper passerà al redirect (considerando il parametro opts.recurse), se restituisce 0 il passaggio per i
redirect si interromperà:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - determina se seguire i redirect standard (ad esempio http -> https
e/o www.domain.com -> domain.com); se si specifica 1 lo scraper seguirà i redirect standard senza considerare il
parametro opts.recurse
opts.http2
opts.http2: 0 - determina se utilizzare il protocollo HTTP/2 durante l'esecuzione delle richieste; per impostazione predefinita
viene utilizzato HTTP/1.1
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - questa opzione consente di bypassare il ban dei siti tramite l'impronta TLS (1 - abilitato, 0 -
disabilitato)
opts.tlsOpts
tlsOpts: { ... } – consente di
passare le impostazioni per
le connessioni https
await this.cookies.*
Lavoro con i cookie per la richiesta corrente
.getAll()
Ottenimento di un array di cookie
await this.cookies.getAll();
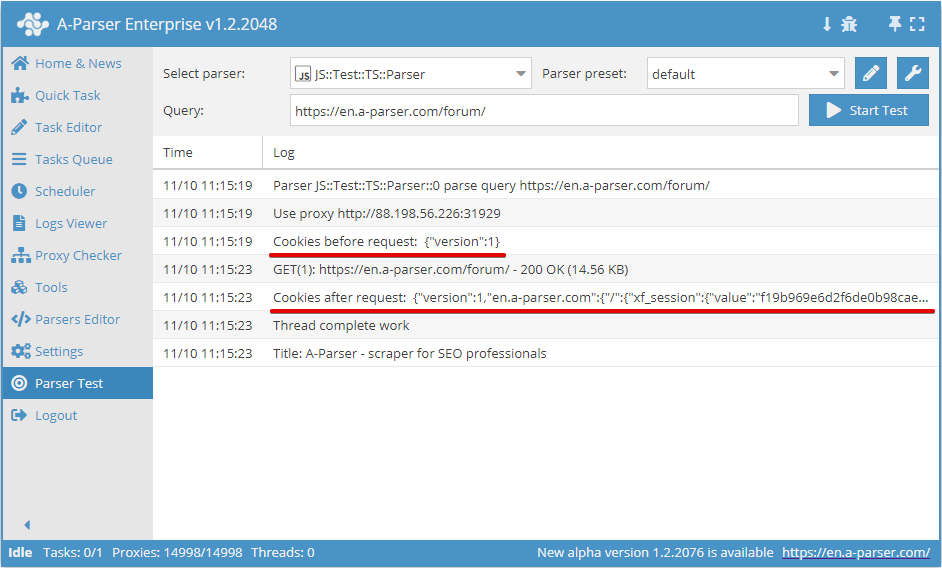
.setAll(cookie_jar)
Impostazione dei cookie, come argomento deve essere passato un hash con i cookie
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
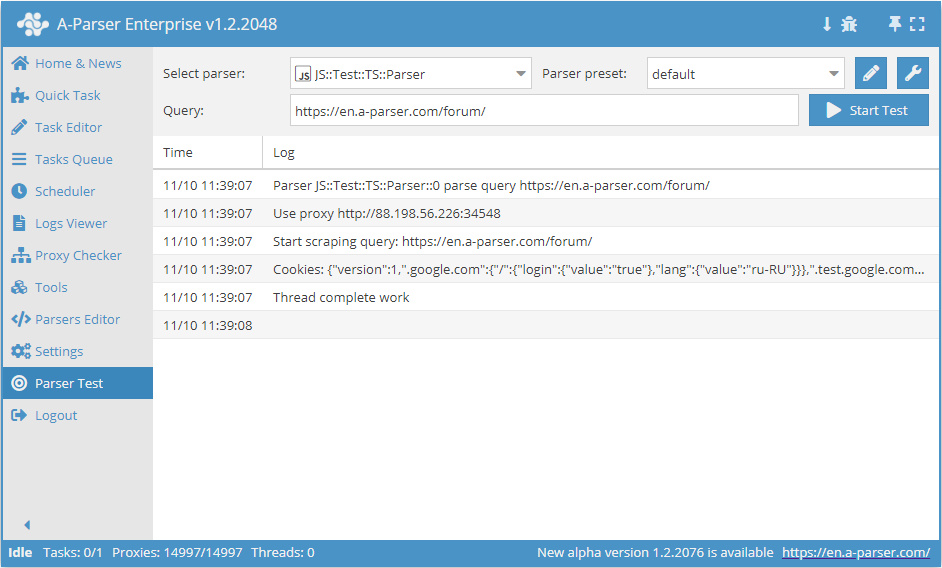
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - impostazione di un singolo cookie.
L'ambito di visibilità del cookie dipende direttamente dal formato del dominio specificato, pertanto in host si tiene conto della presenza del punto prima dell'host:
- se il punto è specificato (
this.cookies.set('.domain.com', ...)), il cookie verrà utilizzato per tutti i sottodomini (ad esempio a.domain.com, b.a.domain.com) - se l'host è specificato senza punto davanti (
this.cookies.set('site.com', ...)), il cookie verrà utilizzato rigorosamente per l'host specificato (host-only cookie) e non viene trasmesso ai sottodomini
Questa differenza è di fondamentale importanza, poiché l'esistenza simultanea di cookie con e senza punto può portare alla loro duplicazione e a un comportamento imprevedibile del sito. Per una corretta emulazione, controlla sempre come esattamente il sito di destinazione imposta i cookie (con l'attributo Domain o senza) e utilizza il formato corrispondente.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
await this.proxy.*
Lavoro con i proxy
.next()
Cambia il proxy con il successivo, il vecchio proxy non verrà più utilizzato per la richiesta corrente
.ban()
Cambia e banna il proxy (necessario quando il servizio blocca l'attività per IP), il proxy verrà bannato per il tempo
indicato nelle impostazioni dello scraper (proxybannedcleanup)
.get()
Ottieni il proxy corrente (l'ultimo proxy con cui è stata effettuata la richiesta)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - imposta il proxy per la richiesta successiva. Il parametro noChange è facoltativo; se impostato su true, il proxy non cambierà tra i tentativi. Per impostazione predefinita noChange = false
await this.sessionManager.*
Metodi per lavorare con le sessioni. Ogni sessione memorizza obbligatoriamente il proxy e i cookie utilizzati. È inoltre possibile salvare dati arbitrari aggiuntivi.
Per utilizzare le sessioni nello scraper JS, è prima necessario inizializzare il Gestore sessioni. Questo viene fatto utilizzando il metodo await this.sessionManagerinit() in init()
.init(opts?)
Inizializzazione del Gestore sessioni. Come argomento è possibile passare un oggetto (opts) con parametri aggiuntivi (tutti i parametri sono facoltativi):
name- consente di ridefinire il nome dello scraper a cui appartengono le sessioni, per impostazione predefinita è uguale al nome dello scraper in cui avviene l'inizializzazionewaitForSession- indica allo scraper di attendere una sessione finché non appare (questo è rilevante solo quando sono in esecuzione più task, ad esempio uno genera sessioni, il secondo le utilizza), ovvero.get()e.reset()aspetteranno sempre una sessionedomain- indica di cercare le sessioni tra tutte quelle salvate per questo scraper (se il valore non è impostato), o solo per un dominio specifico (è necessario specificare il dominio con un punto davanti, ad esempio.site.com)sessionsKey- consente di impostare manualmente il nome del database delle sessioni; se non impostato, il nome viene formato automaticamente in base aname(o al nome dello scraper senamenon è impostato), al dominio e al proxycheckerexpire- imposta il tempo di vita della sessione in minuti, per impostazione predefinita illimitato
Esempio di utilizzo:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Ottenimento di una nuova sessione, deve essere chiamato prima di effettuare la richiesta (prima del primo tentativo). Restituisce un oggetto con dati arbitrari salvati nella sessione. Come argomento è possibile passare un oggetto (opts) con parametri aggiuntivi (tutti i parametri sono facoltativi):
waitTimeout- possibilità di specificare quanti minuti attendere la comparsa di una sessione, funziona indipendentemente dal parametrowaitForSessionin.init()(lo ignora); alla scadenza verrà utilizzata una sessione vuotatag- ottenimento di una sessione con un tag specificato; è possibile utilizzare ad esempio il nome del dominio per collegare le sessioni ai domini da cui sono state ottenute
Esempio di utilizzo:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Pulizia dei cookie e ottenimento di una nuova sessione. Deve essere utilizzato se con la sessione corrente la richiesta non è andata a buon fine. Restituisce un oggetto con dati arbitrari salvati nella sessione. Come argomento è possibile passare un oggetto (opts) con parametri aggiuntivi (tutti i parametri sono facoltativi):
waitTimeout- possibilità di specificare quanti minuti attendere la comparsa di una sessione, funziona indipendentemente dal parametrowaitForSessionin.init()(lo ignora); alla scadenza verrà utilizzata una sessione vuotatag- ottenimento di una sessione con un tag specificato; è possibile utilizzare ad esempio il nome del dominio per collegare le sessioni ai domini da cui sono state ottenute
Esempio di utilizzo:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Salvataggio di una sessione riuscita con la possibilità di salvare dati arbitrari nella sessione. Supporta 2 argomenti facoltativi:
sessionOpts- dati arbitrari da memorizzare nella sessione, può essere un numero, una stringa, un array o un oggettosaveOpts- oggetto con i parametri di salvataggio della sessione:multiply- parametro facoltativo, consente di moltiplicare la sessione; come valore è necessario indicare un numerotag- parametro facoltativo, imposta un tag per la sessione salvata; è possibile utilizzare ad esempio il nome del dominio per collegare le sessioni ai domini da cui sono state ottenute
Esempio di utilizzo:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Restituisce il numero di sessioni per il Gestore sessioni corrente
Esempio di utilizzo:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Elimina tutte le sessioni con un determinato id. Restituisce il numero di sessioni eliminate. L'id della sessione corrente è contenuto nella variabile this.sessionId
Esempio di utilizzo:
const removedCount = await this.sessionManager.removeById(this.sessionId);
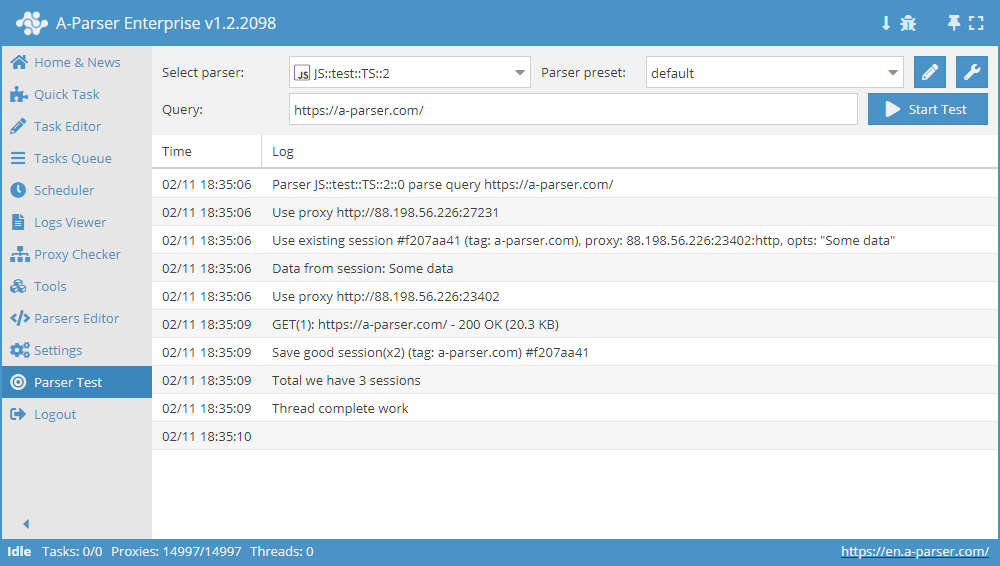
Esempio complesso di utilizzo del Gestore sessioni
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Metodi di richiesta await this.request
Metodo GET
È possibile passare i parametri della richiesta direttamente nella stringa di richiesta https://a-parser.com/users/?type=staff:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
Oppure come oggetto in queryParams, dove key: value è uguale a param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
Metodo POST
Se viene utilizzato il metodo POST, il corpo della richiesta può essere passato in due modi:
Elencare i nomi delle variabili e i loro valori in
queryParams, ad esempio:{
"key": set.query,
"id": 1234,
"type": "text"
}Elencarli in
opts.body, ad esempio:body: 'key=' + set.query + '&id=1234&type=text'
Se il corpo della richiesta viene passato come oggetto, viene automaticamente convertito nel formato form-urlencoded; inoltre, se viene specificato body e non viene specificato l'header content-type, verrà assegnato automaticamente content-type: application/x-www-form-urlencoded:
Se il corpo della richiesta POST è una stringa o un buffer, viene trasmesso così com'è:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Caricamento file
// richiesta con stringa
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// richiesta con buffer
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Caricamento dei file
Invio di un file tramite richiesta POST utilizzando il modulo form-data:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Esempio di invio di un file in una richiesta POST con tipo di contenuto multipart/form-data:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});