HTTP-förfrågningar (+hantering av kakor, proxy, sessioner)
Basklassmetoder
För att samla in data från en webbsida måste man utföra en HTTP-förfrågan. I JavaScript API v2 för A-Parser finns en
lättanvänd metod för att utföra HTTP-förfrågningar, som returnerar ett JSON-objekt beroende på de angivna
metodargumenten. Här får du lära dig: hur en HTTP-förfrågan utförs, vilka argument och alternativ metoden har, resultaten
av angivna alternativ, hur man anger villkor för en lyckad HTTP-förfrågan, och mycket mer.
Här beskrivs även metoder som gör det enkelt att manipulera kakor (cookies), proxyer och sessioner i den scraper som skapas. Efter en lyckad HTTP-förfrågan, eller före utförandet, kan du ställa in/ändra data för proxy/kakor/session för att utföra HTTP-förfrågningar eller spara dem för att utföras av en annan tråd med hjälp av Sessionshanteraren.
Dessa metoder ärvs från BaseParser och utgör grunden för att skapa egna scrapers.
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Hämtning av HTTP-svar på begäran, som argument anges:
method- anropsmetod (GET, POST...)url- länk för anropetqueryParams- en hash med get-parametrar eller en hash med innehållet för en post-förfråganopts- en hash med alternativ för anropet
opts.check_content
check_content: [ villkor1, villkor2, ...] - en array med villkor för att kontrollera det mottagna innehållet. Om kontrollen
misslyckas kommer anropet att upprepas med en annan proxy.
Möjligheter:
- användning av strängar som villkor (sökning efter förekomst av sträng)
- användning av reguljära uttryck som villkor
- användning av egna kontrollfunktioner, som tar emot data och svarshuvuden (headers)
- man kan ange flera olika typer av villkor samtidigt
- för logisk negation, placera villkoret i en array, t.ex.
check_content: ['xxxx', [/yyyy/]]betyder att anropet anses lyckat om det mottagna innehållet innehåller delsträngenxxxxoch samtidigt som det reguljära uttrycket/yyyy/inte hittar några matchningar på sidan
För ett lyckat anrop måste alla kontroller som anges i arrayen godkännas.
Exempel (i kommentarerna anges vad som krävs för att anropet ska anses lyckat):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // det reguljära uttrycket måste matcha på den mottagna sidan
['XXXX'], // denna delsträng får inte finnas på den mottagna sidan
'</html>', // denna delsträng måste finnas på den mottagna sidan
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // denna funktion måste returnera true
]
});
opts.decode
decode: 'auto-html' - automatisk identifiering av kodning och konvertering till utf8
Möjliga värden:
auto-html- baserat på rubriker, meta-taggar och sidans innehåll (det optimala rekommenderade alternativet)utf8- anger att dokumentet är i utf8-kodning<encoding>- vilken annan kodning som helst
opts.headers
headers: { ... } - hash med rubriker, rubrikens namn anges med små bokstäver, man kan även ange bland annat cookie.
Exempel:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - gör det möjligt att åsidosätta sorteringsordningen för rubriker
opts.onlyheaders
onlyheaders: 0 - definierar läsning av data, om aktiverat (1) hämtas endast rubriker
opts.recurse
recurse: N - maximalt antal omdirigeringar, standard är 7, använd 0 för att inaktivera omdirigeringar
proxyretries: N - antal försök att utföra anropet, standardvärdet hämtas från scraperns inställningar
opts.proxyretries
proxyretries: N - ## Anropsmetoder await this.request{#query-methods}
opts.parsecodes
parsecodes: { ... } - Anropsparametrar kan skickas direkt i anropssträngen https://a-parser.com/users/?type=staff:
POST-metod
Om POST-metoden används kan anropets innehåll skickas på två sätt:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - Skicka en fil med ett POST-anrop med hjälp av modulen form-data:
opts.do_gzip
do_gzip: 1 - avgör om komprimering ska användas (gzip/deflate/br), som standard aktiverat (1), för att inaktivera
måste värdet sättas till 0
opts.max_size
max_size: N - maximal storlek på svaret i bytes, som standard hämtas detta från inställningarna för scraper
opts.cookie_jar
cookie_jar: { ... } - hash med cookies. Exempel på hash:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - anger numret på det aktuella försöket; när denna parameter används ignoreras den inbyggda försökshanteraren för
denna begäran
opts.browser
browser: 1 - automatisk emulering av webbläsarhuvuden (1 - aktiverat, 0 - inaktiverat)
opts.use_proxy
use_proxy: 1 - åsidosätter användningen av proxy för en enskild begäran inuti JS-scraper ovanpå den globala
parametern Use proxy (1 - aktiverat, 0 - inaktiverat)
opts.noextraquery
noextraquery: 0 - inaktiverar tillägg av Extra query string till begärans URL (1 - aktiverat, 0 - inaktiverat)
opts.save_to_file
save_to_file: file - låter dig ladda ner filen direkt till disken, utan att skriva till minnet. Istället för file anges namnet och
sökväg för var filen ska sparas. När detta alternativ används ignoreras allt som rör data (innehållskontroll
i opts.check_content kommer inte att utföras, response.data kommer att vara tom, etc.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - automatisk kringgång av CloudFlares JavaScript-skydd med webbläsaren Chrome (1 - aktiverat, 0 -
inaktiverat)
Styrning av Chrome Headless i detta fall sker via scraper-inställningarna bypassCloudFlareChromeMaxPages
och bypassCloudFlareChromeHeadless, som måste anges i static defaultConf och static editableConf:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - tillåter att följa omdirigeringar som deklarerats via HTML-metataggar:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - gör det möjligt att definiera en filtreringsfunktion för omdirigeringar; om funktionen
returnerar 1, kommer scraper att följa omdirigeringen (med hänsyn till parametern opts.recurse), vid retur av 0 kommer
omdirigeringarna att upphöra:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - avgör om standardomdirigeringar ska följas (t.ex. http -> https
och/eller www.domain.com -> domain.com), om du anger 1 kommer scrapern att följa standardomdirigeringar utan att ta hänsyn till
parametern opts.recurse
opts.http2
opts.http2: 0 - avgör om HTTP/2-protokollet ska användas vid förfrågningar, som standard
används HTTP/1.1
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - detta alternativ gör det möjligt att kringgå blockeringar av webbplatser baserat på TLS-fingeravtryck (1 - aktiverat, 0 -
inaktiverat)
opts.tlsOpts
tlsOpts: { ... } – gör det möjligt
att skicka inställningar för
https-anslutningar
await this.cookies.*
Arbeta med cookies för den aktuella begäran
.getAll()
Hämta en array med cookies
await this.cookies.getAll();
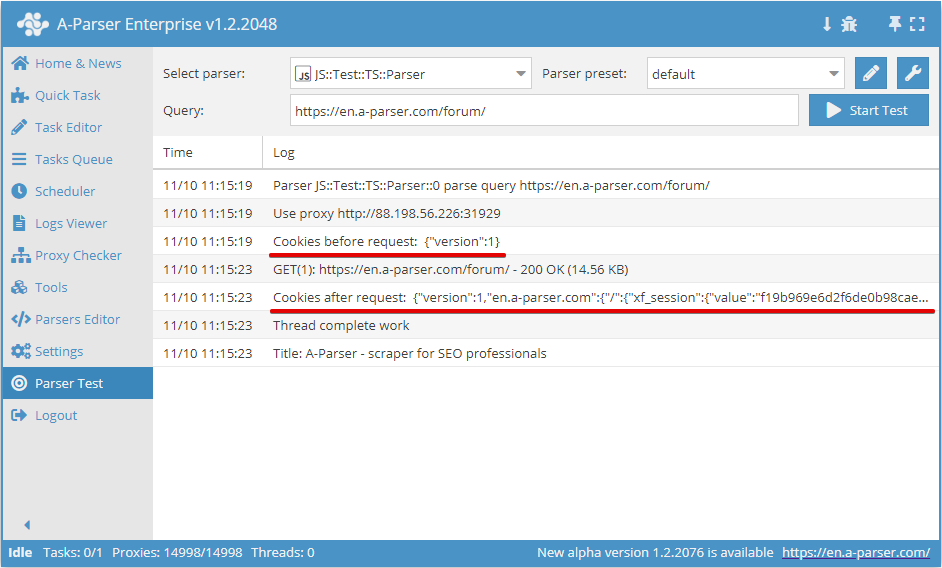
.setAll(cookie_jar)
Sätta cookies, en hash med cookies måste skickas som argument
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
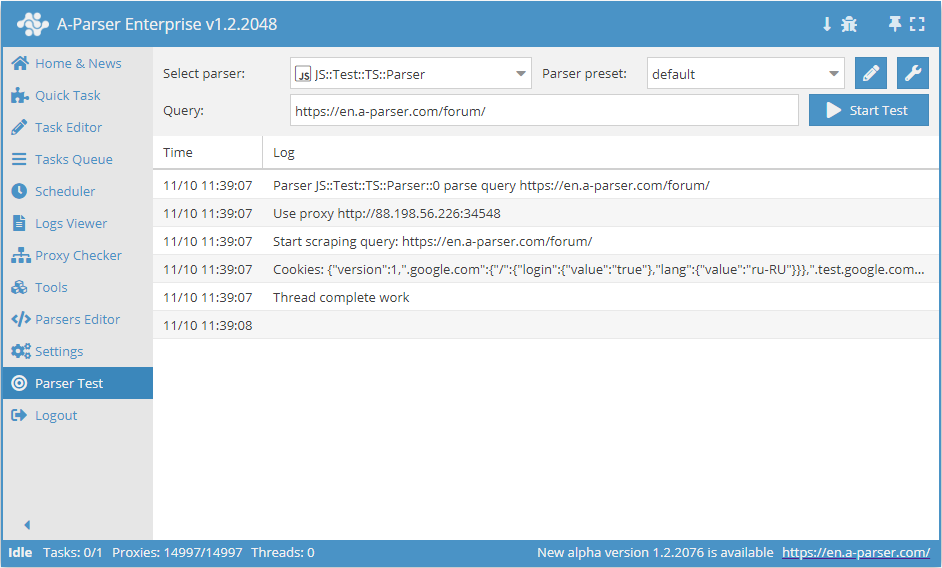
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - sätta en enskild cookie.
Giltighetsområdet för en cookie beror direkt på formatet för den angivna domänen, därför tas hänsyn till punkten före värden i host:
- om en punkt anges (
this.cookies.set('.domain.com', ...)), kommer cookien att användas för alla underdomäner (t.ex. a.domain.com, b.a.domain.com) - om värden anges utan punkt framför (
this.cookies.set('site.com', ...)), kommer cookien att användas strikt för den angivna värden (host-only cookie) och skickas inte till underdomäner
Denna skillnad är kritisk, eftersom samtidig förekomst av cookies med och utan punkt kan leda till dubblering och oförutsägbart beteende på webbplatsen. För korrekt emulering bör du alltid kontrollera exakt hur målwebbplatsen sätter cookies (med eller utan Domain-attribut) och använda motsvarande format.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
await this.proxy.*
Arbeta med proxy
.next()
Byt proxy till nästa, den gamla proxyn kommer inte längre att användas för den aktuella begäran
.ban()
Byt och banna proxy (bör användas när tjänsten blockerar åtkomst via IP), proxyn kommer att bannas under den tid
som anges i scraper-inställningarna (proxybannedcleanup)
.get()
Hämta aktuell proxy (den senaste proxyn som användes för en begäran)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - ställ in proxyn för nästa förfrågan. Parametern noChange är valfri, om den är true kommer proxyn inte att ändras mellan försöken. Som standard noChange = false
await this.sessionManager.*
Metoder för att arbeta med sessioner. Varje session lagrar obligatoriskt använd proxy och cookies. Det går även att spara godtycklig data extra.
För att använda sessioner i en JS-scraper måste man först initiera Sessionshanteraren. Detta görs med metoden await this.sessionManagerinit() i init()
.init(opts?)
Initiering av Sessionshanteraren. Som argument kan ett objekt (opts) med ytterligare parametrar skickas (alla parametrar är valfria):
name- gör det möjligt att åsidosätta namnet på den scraper som sessionerna tillhör, som standard är det namnet på den scraper där initieringen skerwaitForSession- anger åt scrapern att vänta på en session tills den dyker upp (detta är bara relevant när flera jobb körs, till exempel när ett genererar sessioner och ett annat använder dem), dvs..get()och.reset()kommer alltid att vänta på sessionendomain- anger att sessioner ska sökas bland alla som sparats för denna scraper (om inget värde anges), eller endast för en specifik domän (domänen måste anges med en punkt först, till exempel.site.com)sessionsKey- låter dig ange namnet på sessionslagret manuellt, om det inte anges skapas namnet automatiskt utifrånname(eller scraperns namn omnameinte anges), domänen och proxycheckernexpire- anger sessionens livslängd i minuter, som standard obegränsad
Exempel på användning:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Hämta en ny session, måste anropas innan en begäran utförs (före det första försöket). Returnerar ett objekt med godtycklig data sparad i sessionen. Som argument kan ett objekt (opts) med ytterligare parametrar skickas (alla parametrar är valfria):
waitTimeout- möjlighet att ange hur många minuter man ska vänta på att sessionen dyker upp, fungerar oberoende av parameternwaitForSessioni.init()(ignorerar den), när tiden löper ut används en tom sessiontag- hämta en session med en specifik tagg, man kan till exempel använda domännamnet för att binda sessioner till de domäner de hämtats från
Exempel på användning:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Rensa cookies och hämta en ny session. Bör användas om begäran med den aktuella sessionen inte lyckades. Returnerar ett objekt med godtycklig data sparad i sessionen. Som argument kan ett objekt (opts) med ytterligare parametrar skickas (alla parametrar är valfria):
waitTimeout- möjlighet att ange hur många minuter man ska vänta på att sessionen dyker upp, fungerar oberoende av parameternwaitForSessioni.init()(ignorerar den), när tiden löper ut används en tom sessiontag- hämta en session med en specifik tagg, man kan till exempel använda domännamnet för att binda sessioner till de domäner de hämtats från
Exempel på användning:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Spara en lyckad session med möjlighet att spara godtycklig data i sessionen. Stöder 2 valfria argument:
sessionOpts- godtycklig data att lagra i sessionen, kan vara ett tal, en sträng, en array eller ett objektsaveOpts- objekt med parametrar för att spara sessionen:multiply- valfri parameter, gör det möjligt att duplicera sessionen, ett tal måste anges som värdetag- valfri parameter, anger en tagg för den sparade sessionen, man kan till exempel använda domännamnet för att binda sessioner till de domäner de hämtats från
Exempel på användning:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Returnerar antalet sessioner för den aktuella Sessionshanteraren
Exempel på användning:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Tar bort alla sessioner med ett givet id. Returnerar antalet borttagna sessioner. Id för den aktuella sessionen finns i variabeln this.sessionId
Exempel på användning:
const removedCount = await this.sessionManager.removeById(this.sessionId);
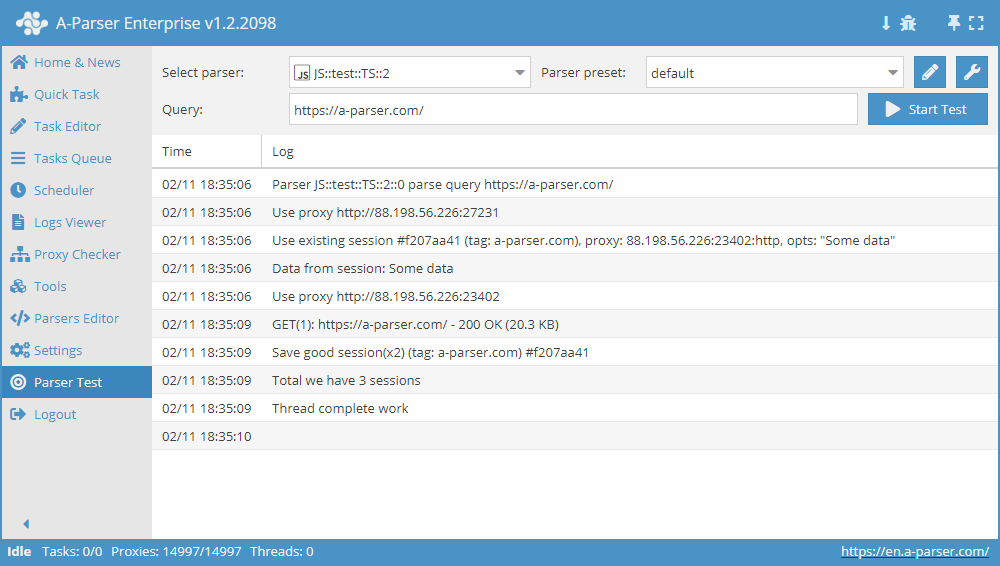
Komplext exempel på användning av Sessionshanteraren
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Metoder för förfrågningar await this.request
GET-metoden
Parametrar för begäran kan skickas direkt i frågesträngen https://a-parser.com/users/?type=staff:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
Eller som ett objekt i queryParams, där key: value motsvarar param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
POST-metoden
Om metoden POST används kan begärans kropp skickas på två sätt:
Lista variabelnamn och deras värden i
queryParams, till exempel:{
"key": set.query,
"id": 1234,
"type": "text"
}Lista dem i
opts.body, till exempel:body: 'key=' + set.query + '&id=1234&type=text'
Om begärans body skickas som ett objekt omvandlas den automatiskt till formatet form-urlencoded. Om body anges
och inget content-type-huvud anges, tilldelas automatiskt content-type: application/x-www-form-urlencoded:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Om kroppen i en POST-begäran är en sträng eller en buffer, skickas den som den är:
// anrop med sträng
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// anrop med buffer
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Filuppladdning
Skicka en fil med en POST-begäran med modulen form-data:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Exempel på att skicka en fil i en POST-begäran med innehållstypen multipart/form-data:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});