HTTP 请求(+Cookie 处理、代理、会话)
基类方法
要从网页采集数据,需要执行 HTTP 请求。在 A-Parser 的 JavaScript API v2 中,实现了一个易于使用的 HTTP 请求执行方法,该方法根据指定的方法参数返回一个 JSON 对象。接下来您将了解到:如何发起 HTTP 请求、该方法具有哪些参数和选项、指定选项的结果、如何指定 HTTP 请求成功的条件等。
这些方法继承自 BaseParser,是创建自定义爬虫工具的基础。
根据请求获取 HTTP 响应,参数说明如下:
method- 请求方法 (GET, POST...)url- 请求链接queryParams- 包含 GET 参数的哈希表或包含 POST 请求体的哈希表 HTTP 请求,或使用 会话管理器 保存以便由另一个线程执行。
这些方法继承自 BaseParser,是创建自定义爬虫工具的基础
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
根据请求获取 HTTP 响应,参数说明如下:
method- 请求方法 (GET, POST...)url- 请求链接queryParams- 包含 GET 参数的哈希表或包含 POST 请求体的哈希表opts- 包含请求选项的哈希表
opts.check_content
check_content: [ 条件1, 条件2, ...] - 用于检查所获取内容的条件数组,如果检查未
通过,则将使用另一个代理重试请求。
功能:
- 支持使用字符串作为条件(按字符串包含关系搜索)
- 支持使用正则表达式作为条件
- 支持使用自定义检查函数,函数会接收响应数据和响应头
- 可以同时指定多种不同类型的条件
- 如需逻辑非,请将条件放入数组中,例如
check_content: ['xxxx', [/yyyy/]]表示如果获取的数据 包含子字符串xxxx且正则表达式/yyyy/在页面上 未找到匹配项,则请求将被视为成功
为了使请求成功,必须通过数组中指定的所有检查
示例(注释中说明了请求被视为成功所需的条件):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // 在获取的页面上应触发此正则表达式
['XXXX'], // 在获取的页面上不应有此子字符串
'</html>', // 在获取的页面上应有此子字符串
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // 此函数应返回 true
]
});
opts.decode
decode: 'auto-html' - 自动检测编码并转换为 utf8
可选值:
auto-html- 基于响应头、meta 标签和页面内容(推荐的最佳方案)utf8- 指定文档编码为 utf8<encoding>- 任何其他编码
opts.headers
headers: { ... } - 包含响应头的哈希表,响应头名称需使用小写字母,也可以指定 cookie 等。
示例:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - 允许重新定义响应头的排序顺序
opts.onlyheaders
onlyheaders: 0 - 决定是否读取 data,如果启用(1),则只获取标头
opts.recurse
recurse: N - 最大重定向跳转次数,默认值为 7,可使用 0 来关闭
重定向
opts.proxyretries
proxyretries: N - 请求重试次数,默认取自爬虫工具设置
opts.parsecodes
parsecodes: { ... } - 爬虫工具视为成功的 HTTP 响应代码列表,默认取自
爬虫工具设置。如果指定 '*': 1,则所有响应都将被视为成功。
示例:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - 响应超时时间(秒),默认取自爬虫工具设置
opts.do_gzip
do_gzip: 1 - 确定是否使用压缩 (gzip/deflate/br),默认开启 (1),如需关闭
需设置为 0
opts.max_size
max_size: N - 最大响应大小(字节),默认取自爬虫工具设置
opts.cookie_jar
cookie_jar: { ... } - 包含 Cookie 的哈希表。哈希表示例:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - 指定当前尝试次数,使用此参数时将忽略该请求的
内置重试处理器
opts.browser
browser: 1 - 自动模拟浏览器请求头 (1 - 开启, 0 - 关闭)
opts.use_proxy
use_proxy: 1 - 在 JS 爬虫工具内部为单个请求覆盖全局参数
Use proxy 的设置 (1 - 开启, 0 - 关闭)
opts.noextraquery
noextraquery: 0 - 禁用在请求 URL 中添加 Extra query string (1 - 开启, 0 - 禁用)
opts.save_to_file
save_to_file: file - 允许将文件直接下载到磁盘,无需先写入内存。改为 file 时需指定保存文件的名称和
保存文件的路径。使用此选项时,将忽略所有与 data 相关的内容(不会执行
opts.check_content 中的内容检查,response.data 将为空等)
opts.bypass_cloudflare
bypass_cloudflare: 0 - 使用 Chrome 浏览器自动绕过 CloudFlare 的 JavaScript 防护 (1 - 开启, 0 -
关闭)
在这种情况下,Chrome Headless 的控制由爬虫工具设置 bypassCloudFlareChromeMaxPages 执行
和 bypassCloudFlareChromeHeadless 来实现,需要在 static defaultConf 和 static editableConf 中指定:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - 允许跟随通过 HTML meta 标签声明的重定向:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - 允许设置重定向跳转的过滤函数,如果函数
返回 1,则爬虫工具将执行重定向(考虑 opts.recurse 参数),返回 0 时将停止
重定向跳转:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - 决定是否跟随标准重定向(例如 http -> https
以及 www.domain.com -> domain.com),如果设置为 1,则爬虫工具会跟随标准重定向,不考虑
参数 opts.recurse
opts.http2
opts.http2: 0 - 确定在执行请求时是否使用 HTTP/2 协议,默认
使用 HTTP/1.1
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - 此选项允许通过 TLS 指纹绕过网站封禁 (1 - 开启, 0 -
关闭)
opts.tlsOpts
tlsOpts: { ... } – 允许
为 HTTPS 连接传递 设置
HTTPS 连接
await this.cookies.*
处理当前请求的 Cookie
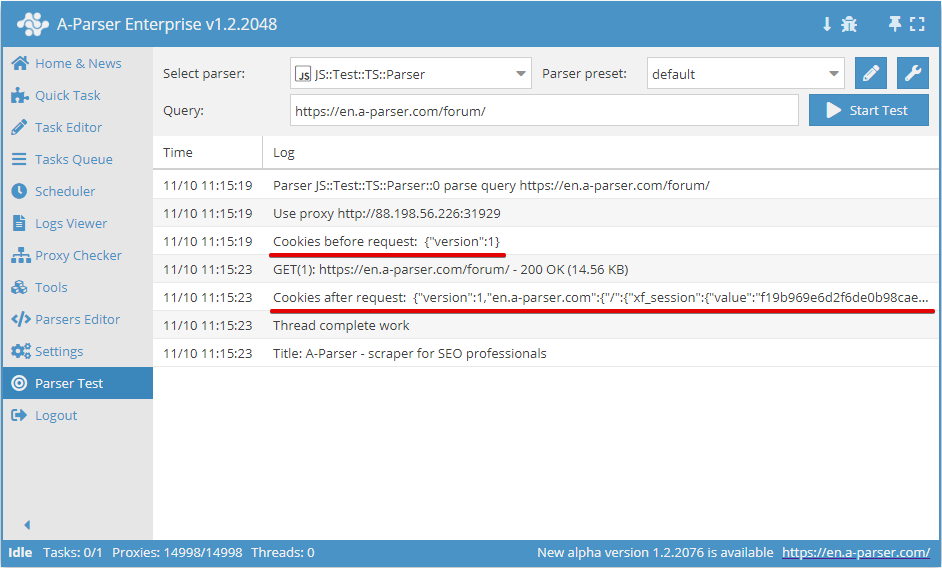
.getAll()
获取 Cookie 数组
await this.cookies.getAll();
.setAll(cookie_jar)
设置 Cookie,必须传递一个包含 Cookie 的哈希表作为参数
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
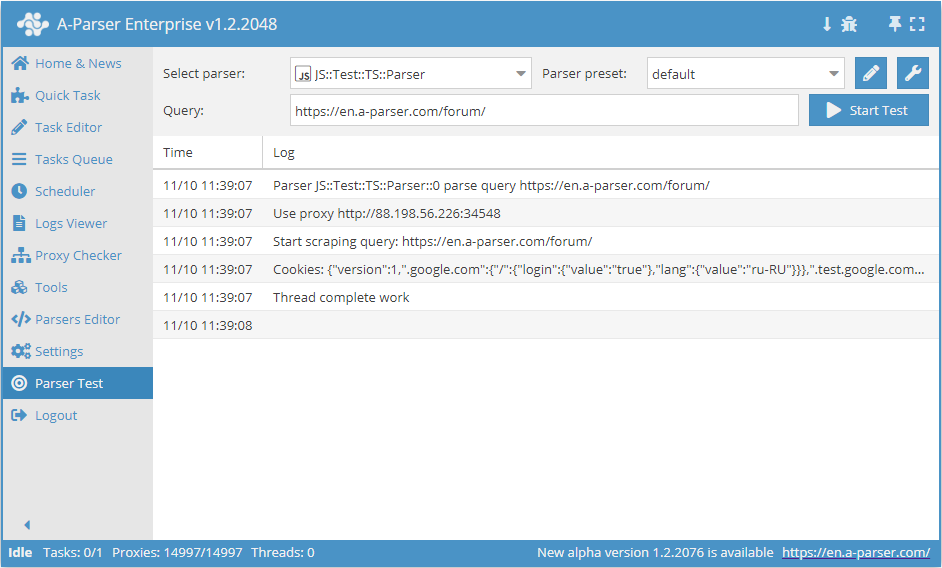
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - 设置单个 Cookie。
Cookie 的作用域直接取决于指定的域名格式,因此在 host 中会考虑主机名前是否有点:
- 如果指定了点 (
this.cookies.set('.domain.com', ...)),则 Cookie 将用于所有子域名(例如 a.domain.com, b.a.domain.com) - 如果主机名开头没有点 (
this.cookies.set('site.com', ...)),则 Cookie 将严格用于指定的主机(host-only cookie),不会传递给子域名
这种区别至关重要,因为带点和不带点的 Cookie 同时存在可能导致重复并引起网站运行不可预测。为了正确模拟,请务必检查目标网站是如何设置 Cookie 的(是否带有 Domain 属性),并使用相应的格式。
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
await this.proxy.*
处理代理
.next()
切换到下一个代理,旧代理将不再用于当前请求
.ban()
切换并封禁代理(当服务按 IP 封锁操作时需使用),代理将被封禁一段时间,
时长由爬虫工具设置 (proxybannedcleanup) 指定
.get()
获取当前代理(最后一次发出请求时使用的代理)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - 为下一次请求设置代理。参数 noChange 为可选,如果设为 true,代理在各次尝试之间不会变化。默认 noChange = false
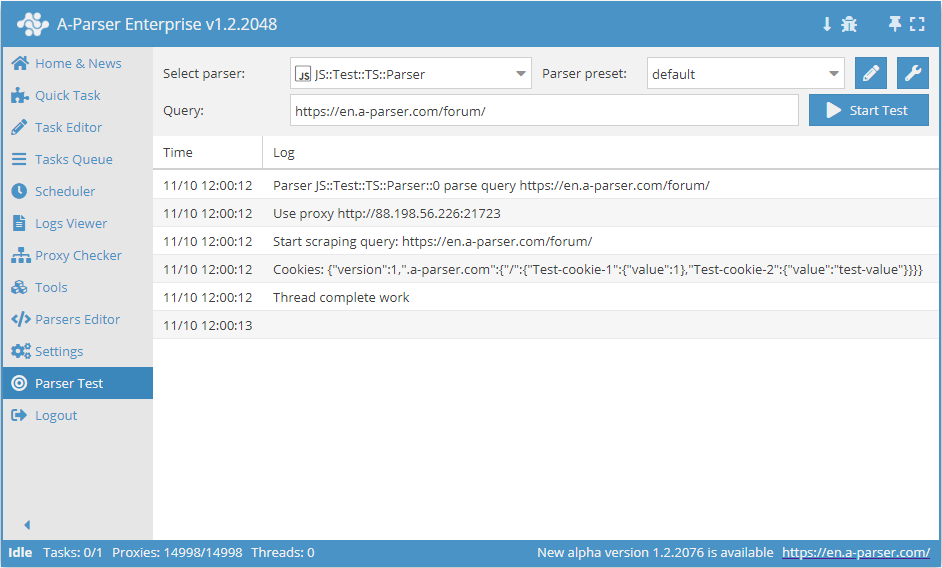
await this.sessionManager.*
会话处理方法。每个会话必须存储所使用的代理和 Cookie。此外还可以额外保存任意数据。
要在 JS 爬虫工具中使用会话,首先必须初始化会话管理器。这可以通过在 init() 中调用 await this.sessionManagerinit() 方法来完成
.init(opts?)
初始化会话管理器。可以传递一个包含附加参数的对象 (opts) 作为参数(所有参数均为可选):
name- 允许重新定义会话所属的爬虫工具名称,默认为执行初始化的爬虫工具名称waitForSession- 指示爬虫工具在会话出现之前一直等待(这只在多个任务同时运行时才相关,例如一个生成会话,另一个使用会话),也就是说.get()和.reset()将始终等待会话domain- 指示在该爬虫工具保存的所有会话中查找(如果未指定值),或者只针对特定域名查找(需要在域名前加点,例如.site.com)sessionsKey- 允许手动指定会话存储名称;如果未指定,则会根据name(或未指定name时的爬虫工具名称)、域名和代理检测器自动生成expire- 设置会话有效期(分钟),默认无限制
使用示例:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
获取新会话,必须在执行请求之前(第一次尝试之前)调用。返回保存在会话中的任意数据对象。可以传递一个包含附加参数的对象 (opts) 作为参数(所有参数均为可选):
waitTimeout- 可指定等待会话出现的分钟数,独立于.init()中的waitForSession参数(会忽略它),到期后将使用空会话tag- 获取带有指定标签的会话,例如可以使用域名将会话绑定到获取它们的域名
使用示例:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
清除 Cookie 并获取新会话。如果当前会话的请求不成功,则必须使用此方法。返回保存在会话中的任意数据对象。可以传递一个包含附加参数的对象 (opts) 作为参数(所有参数均为可选):
waitTimeout- 可指定等待会话出现的分钟数,独立于.init()中的waitForSession参数(会忽略它),到期后将使用空会话tag- 获取带有指定标签的会话,例如可以使用域名将会话绑定到获取它们的域名
使用示例:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
保存成功的会话,并支持在会话中保存任意数据。支持 2 个可选参数:
sessionOpts- 要存储在会话中的任意数据,可以是数字、字符串、数组或对象saveOpts- 包含会话保存参数的对象:multiply- 可选参数,允许复制会话,需指定一个数字作为值tag- 可选参数,为保存的会话设置标签,例如可以使用域名将会话绑定到获取它们的域名
使用示例:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
返回当前会话管理器的会话数量
使用示例:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
删除所有具有指定 id 的会话。返回已删除会话的数量。当前会话的 id 包含在变量 this.sessionId 中
使用示例:
const removedCount = await this.sessionManager.removeById(this.sessionId);
会话管理器综合使用示例
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
请求方法 await this.request
GET 方法
可以直接在请求字符串 https://a-parser.com/users/?type=staff 中传递请求参数:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
或者作为 queryParams 中的对象传入,其中 key: value 等同于 param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
POST 方法
如果使用 POST 方法,可以通过两种方式传递请求体:
在
queryParams中列出变量名及其值,例如:{
"key": set.query,
"id": 1234,
"type": "text"
}在
opts.body中列出它们,例如:body: 'key=' + set.query + '&id=1234&type=text'
如果 请求体 以对象形式传入,它会自动转换为 form-urlencoded 格式;同样,如果指定了 body 且未
指定 content-type 标头,则会自动设置为 content-type: application/x-www-form-urlencoded:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
如果 POST 请求体是字符串或 Buffer,则按原样传递:
// 带字符串的请求
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// 带 Buffer 的请求
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
文件上传
使用 form-data 模块通过 POST 请求发送文件:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
在内容类型为 multipart/form-data 的 POST 请求中发送文件的示例:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});