Requisições HTTP (+trabalho com cookies, proxy, sessões)
Métodos da classe base
Para coletar dados de uma página web, é necessário realizar uma requisição HTTP. Na JavaScript API v2 do A-Parser, foi implementado um método de fácil
utilização para execução de requisições HTTP, que retorna um objeto JSON dependendo dos
argumentos do método especificados. A seguir, você aprenderá: como a requisição HTTP é feita, quais argumentos e opções o método possui, os resultados
das opções especificadas, como definir a condição de sucesso de uma requisição HTTP e muito mais.
Também são descritos métodos que permitem manipular facilmente cookies, proxies e sessões no scraper que está sendo criado. Após a execução bem-sucedida de uma requisição HTTP, ou antes da execução, você pode definir/alterar os dados de proxy/cookies/sessão para a execução de requisições HTTP ou salvar para execução por outra thread usando o Gerenciador de sessões.
Estes métodos são herdados de BaseParser e servem como base para a criação de scrapers personalizados
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Obtenção de resposta HTTP por requisição, os seguintes argumentos são especificados:
method- método da requisição (GET, POST...)url- link para a requisiçãoqueryParams- hash com parâmetros get ou hash com o corpo da requisição postopts- hash com opções da requisição
opts.check_content
check_content: [ condição1, condição2, ...] - array de condições para verificar o conteúdo recebido; se a verificação não
passar, a requisição será repetida com outro proxy.
Possibilidades:
- uso de strings como condições (busca por ocorrência de string)
- uso de expressões regulares como condições
- uso de funções de verificação personalizadas, nas quais são passados os dados e os headers da resposta
- é possível definir vários tipos diferentes de condições simultaneamente
- para negação lógica, coloque a condição em um array, ou seja,
check_content: ['xxxx', [/yyyy/]]significa que a requisição será considerada bem-sucedida se os dados recebidos contiverem a substringxxxxe, ao mesmo tempo, a expressão regular/yyyy/não encontrar correspondências na página
Para uma requisição bem-sucedida, todas as verificações especificadas no array devem passar
Exemplo (os comentários indicam o que é necessário para que a requisição seja considerada bem-sucedida):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // esta expressão regular deve ser acionada na página recebida
['XXXX'], // esta substring não deve estar presente na página recebida
'</html>', // esta substring deve estar presente na página recebida
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // esta função deve retornar true
]
});
opts.decode
decode: 'auto-html' - detecção automática de codificação e conversão para utf8
Valores possíveis:
auto-html- baseado em cabeçalhos, tags meta e no conteúdo da página (opção recomendada ideal)utf8- indica que o documento está na codificação utf8<encoding>- qualquer outra codificação
opts.headers
headers: { ... } - hash com cabeçalhos, o nome do cabeçalho é definido em letras minúsculas, pode-se incluir inclusive cookie.
Exemplo:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - permite redefinir a ordem de classificação dos cabeçalhos
opts.onlyheaders
onlyheaders: 0 - define a leitura de data; se ativado (1), recebe apenas os cabeçalhos
opts.recurse
recurse: N - número máximo de redirecionamentos; o padrão é 7, use 0 para desativar o seguimento de
redirecionamentos
opts.proxyretries
proxyretries: N - número de tentativas de execução da requisição; por padrão, é obtido das configurações do scraper
opts.parsecodes
parsecodes: { ... } - lista de códigos de resposta HTTP que o scraper considerará bem-sucedidos; por padrão, é obtido das
configurações do scraper. Se especificar '*': 1, todas as respostas serão consideradas bem-sucedidas.
Exemplo:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - tempo limite de resposta em segundos; por padrão, é obtido das configurações do scraper
opts.do_gzip
do_gzip: 1 - define se deve usar compressão (gzip/deflate/br); por padrão está ativado (1), para desativar
é necessário definir o valor como 0
opts.max_size
max_size: N - tamanho máximo da resposta em bytes; por padrão, é obtido das configurações do scraper
opts.cookie_jar
cookie_jar: { ... } - hash com cookies. Exemplo de hash:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - indica o número da tentativa atual; ao usar este parâmetro, o manipulador de tentativas integrado para
esta requisição é ignorado
opts.browser
browser: 1 - emulação automática de cabeçalhos de navegador (1 - ativado, 0 - desativado)
opts.use_proxy
use_proxy: 1 - substitui o uso de proxy para uma requisição individual dentro do scraper JS sobre o parâmetro global
Use proxy (1 - ativado, 0 - desativado)
opts.noextraquery
noextraquery: 0 - desativa a adição de Extra query string à URL da requisição (1 - ativado, 0 - desativado)
opts.save_to_file
save_to_file: file - permite baixar um arquivo diretamente para o disco, ignorando a gravação na memória. Em vez de file, especifica-se o nome e o
caminho sob o qual salvar o arquivo. Ao usar esta opção, tudo relacionado a data é ignorado (a verificação de conteúdo
em opts.check_content não será executada, response.data estará vazio, etc.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - contorno automático da proteção JavaScript do CloudFlare usando o navegador Chrome (1 - ativado, 0 -
desativado)
O controle do Chrome Headless neste caso é realizado pelas configurações do scraper bypassCloudFlareChromeMaxPages
e bypassCloudFlareChromeHeadless, que devem ser especificadas em static defaultConf e static editableConf:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - permite seguir redirecionamentos declarados via meta tag HTML:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - permite definir uma função de filtragem para seguir redirecionamentos; se a função
retornar 1, o scraper seguirá o redirecionamento (considerando o parâmetro opts.recurse); ao retornar 0, o seguimento de
redirecionamentos será interrompido:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - define se deve seguir redirecionamentos padrão (por exemplo http -> https
e/ou www.domain.com -> domain.com); se especificar 1, o scraper seguirá os redirecionamentos padrão sem considerar o
parâmetro opts.recurse
opts.http2
opts.http2: 0 - define se deve usar o protocolo HTTP/2 ao realizar requisições; por padrão
é usado HTTP/1.1
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - esta opção permite contornar o banimento de sites por impressão digital TLS (1 - ativado, 0 -
desativado)
opts.tlsOpts
tlsOpts: { ... } – permite
passar configurações para
conexões https
await this.cookies.*
Trabalho com cookies para a requisição atual
.getAll()
Obtenção de um array de cookies
await this.cookies.getAll();
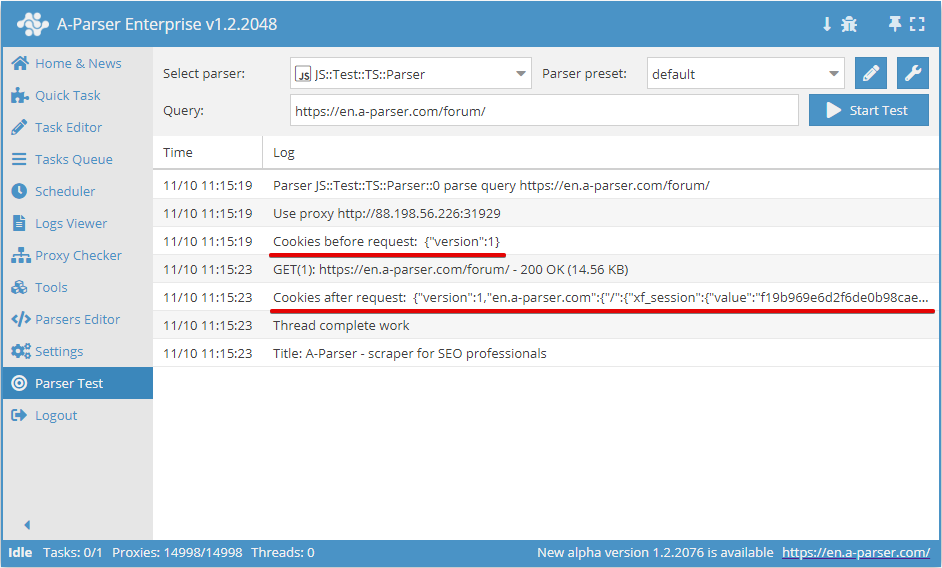
.setAll(cookie_jar)
Definição de cookies; um hash com cookies deve ser passado como argumento
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
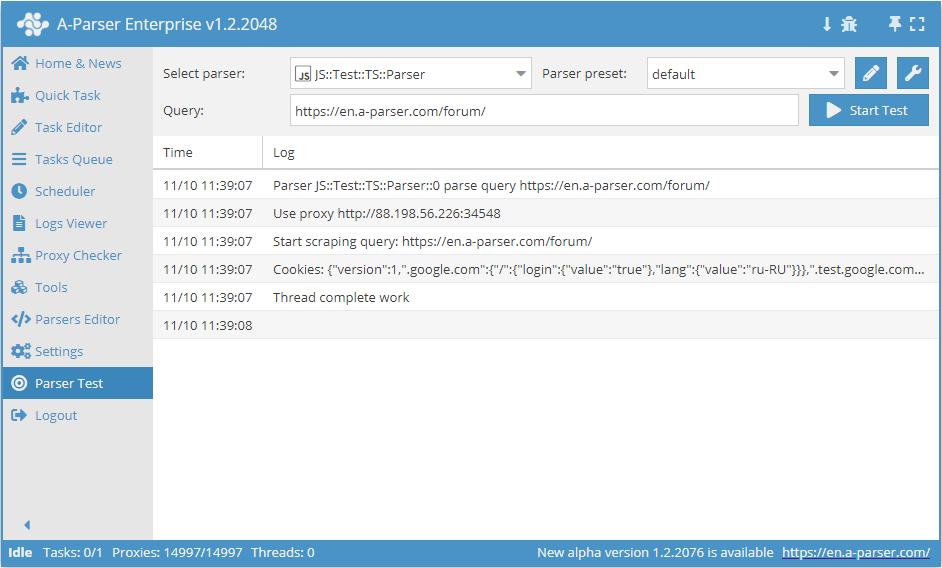
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - definição de um único cookie.
O escopo de visibilidade do cookie depende diretamente do formato do domínio especificado, portanto em host a presença de um ponto antes do host é levada em conta:
- se o ponto for especificado (
this.cookies.set('.domain.com', ...)), o cookie será usado para todos os subdomínios (por exemplo a.domain.com, b.a.domain.com) - se o host for especificado sem o ponto à frente (
this.cookies.set('site.com', ...)), o cookie será usado estritamente para o host especificado (host-only cookie) e não será passado para subdomínios
Esta diferença é criticamente importante, pois a existência simultânea de cookies com e sem ponto pode levar à sua duplicação e ao comportamento imprevisível do site. Para uma emulação correta, verifique sempre como exatamente o site de destino define os cookies (com o atributo Domain ou sem) e use o formato correspondente.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
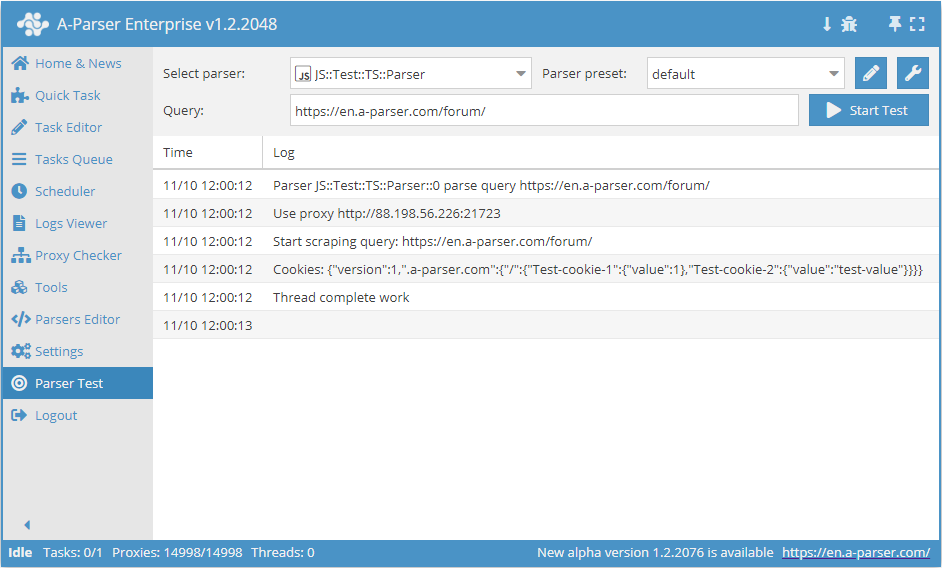
await this.proxy.*
Trabalho com proxy
.next()
Mudar o proxy para o próximo; o proxy antigo não será mais usado para a requisição atual
.ban()
Mudar e banir o proxy (necessário usar quando o serviço bloqueia o trabalho por IP); o proxy será banido pelo tempo
especificado nas configurações do scraper (proxybannedcleanup)
.get()
Obter o proxy atual (o último proxy com o qual a requisição foi feita)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - definir o proxy para a próxima requisição. O parâmetro noChange é opcional; se definido como true, o proxy não mudará entre as tentativas. Por padrão noChange = false
await this.sessionManager.*
Métodos para trabalhar com sessões. Cada sessão armazena obrigatoriamente o proxy e os cookies utilizados. Também é possível salvar adicionalmente dados arbitrários.
Para usar sessões no scraper JS, primeiro é obrigatório inicializar o Gerenciador de sessões. Isso é feito usando o método await this.sessionManagerinit() em init()
.init(opts?)
Inicialização do Gerenciador de sessões. Como argumento, pode-se passar um objeto (opts) com parâmetros adicionais (todos os parâmetros são opcionais):
name- permite redefinir o nome do scraper ao qual as sessões pertencem; por padrão é igual ao nome do scraper no qual a inicialização ocorrewaitForSession- instrui o scraper a esperar por uma sessão até que ela apareça (isso é relevante apenas quando várias tarefas estão em execução, por exemplo, uma gera sessões e a segunda as utiliza), ou seja,.get()e.reset()sempre esperarão por uma sessãodomain- instrui a procurar sessões entre todas as salvas para este scraper (se o valor não for definido), ou apenas para um domínio específico (é necessário especificar o domínio com um ponto à frente, por exemplo.site.com)sessionsKey- permite definir manualmente o nome do armazenamento de sessões; se não for definido, o nome é formado automaticamente com base emname(ou no nome do scraper, senamenão for definido), domínio e proxycheckerexpire- define o tempo de vida da sessão em minutos; por padrão é ilimitado
Exemplo de uso:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Obtenção de uma nova sessão; deve ser chamado antes de realizar a requisição (antes da primeira tentativa). Retorna um objeto com dados arbitrários salvos na sessão. Como argumento, pode-se passar um objeto (opts) com parâmetros adicionais (todos os parâmetros são opcionais):
waitTimeout- possibilidade de especificar quantos minutos esperar pelo aparecimento da sessão; funciona independentemente do parâmetrowaitForSessionem.init()(ignora-o); após o tempo limite, uma sessão vazia será usadatag- obtenção de uma sessão com uma tag específica; pode-se usar, por exemplo, o nome do domínio para vincular sessões aos domínios dos quais foram obtidas
Exemplo de uso:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Limpeza de cookies e obtenção de uma nova sessão. Deve ser usado se a requisição com a sessão atual não foi bem-sucedida. Retorna um objeto com dados arbitrários salvos na sessão. Como argumento, pode-se passar um objeto (opts) com parâmetros adicionais (todos os parâmetros são opcionais):
waitTimeout- possibilidade de especificar quantos minutos esperar pelo aparecimento da sessão; funciona independentemente do parâmetrowaitForSessionem.init()(ignora-o); após o tempo limite, uma sessão vazia será usadatag- obtenção de uma sessão com uma tag específica; pode-se usar, por exemplo, o nome do domínio para vincular sessões aos domínios dos quais foram obtidas
Exemplo de uso:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Salvamento de uma sessão bem-sucedida com a possibilidade de salvar dados arbitrários na sessão. Suporta 2 argumentos opcionais:
sessionOpts- dados arbitrários para armazenamento na sessão; pode ser um número, string, array ou objetosaveOpts- objeto com parâmetros de salvamento da sessão:multiply- parâmetro opcional; permite multiplicar a sessão; deve-se especificar um número como valortag- parâmetro opcional; define uma tag para a sessão salva; pode-se usar, por exemplo, o nome do domínio para vincular sessões aos domínios dos quais foram obtidas
Exemplo de uso:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Retorna a quantidade de sessões para o Gerenciador de sessões atual
Exemplo de uso:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Remove todas as sessões com um determinado id. Retorna a quantidade de sessões removidas. O Id da sessão atual está contido na variável this.sessionId
Exemplo de uso:
const removedCount = await this.sessionManager.removeById(this.sessionId);
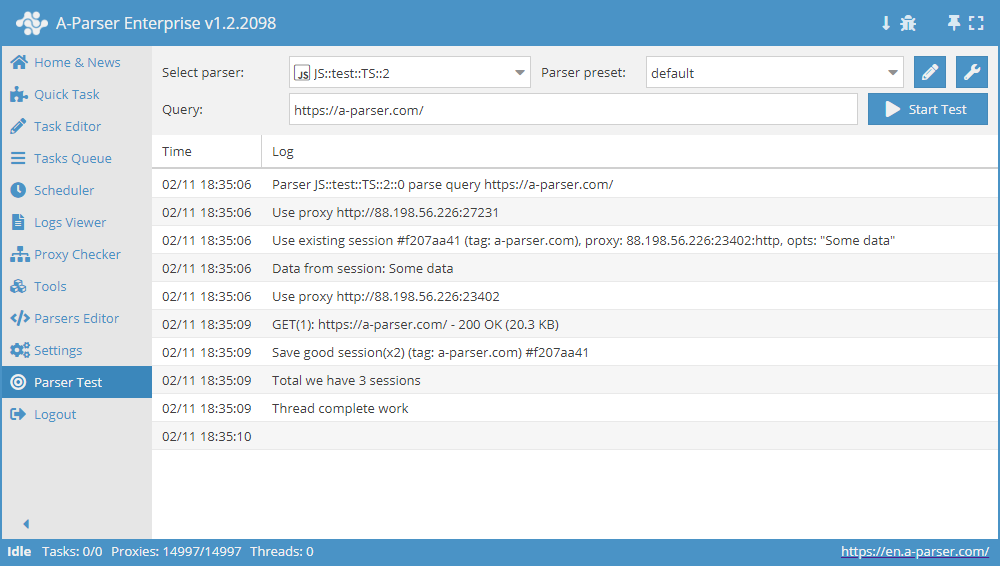
Exemplo complexo de uso do Gerenciador de sessões
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Métodos de requisição await this.request
Método GET
Passar os parâmetros da requisição diretamente na string da requisição https://a-parser.com/users/?type=staff:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
Ou como um objeto em queryParams, onde key: value é igual a param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
Método POST
Se o método POST for usado, o corpo da requisição pode ser passado de duas maneiras:
Listar os nomes das variáveis e seus valores em
queryParams, por exemplo:{
"key": set.query,
"id": 1234,
"type": "text"
}Listá-los em
opts.body, por exemplo:body: 'key=' + set.query + '&id=1234&type=text'
Se o corpo da requisição for passado como um objeto, ele é automaticamente convertido para o formato form-urlencoded; da mesma forma, se body for especificado e o cabeçalho content-type não for
especificado, será atribuído automaticamente content-type: application/x-www-form-urlencoded:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Se o corpo da requisição POST for uma string ou buffer, ele será passado como tal:
// requisição com string
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// requisição com buffer
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Upload de arquivos
Envio de arquivo por requisição POST usando o módulo form-data:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Exemplo de envio de arquivo em uma requisição POST com o tipo de conteúdo multipart/form-data:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});