Zapytania HTTP (+obsługa plików cookie, proxy, sesji)
Metody klasy bazowej
Aby zebrać dane ze strony internetowej, należy wykonać zapytanie HTTP. W JavaScript API v2 A-Parsera zaimplementowano łatwą w
użyciu metodę wykonywania zapytań HTTP, która w odpowiedzi zwraca obiekt JSON w zależności od wskazanych
argumentów metody. Dalej dowiesz się: jak wykonywane jest zapytanie HTTP, jakie argumenty i opcje posiada metoda, jakie są wyniki
określonych opcji, jak określić warunek powodzenia zapytania HTTP i inne.
Opisano również metody pozwalające łatwo manipulować plikami cookie, proxy i sesją w tworzonym scraperze. Po pomyślnym wykonaniu zapytania HTTP lub przed jego wykonaniem, możesz ustawić/zmienić dane proxy/cookie/sesji dla wykonywania zapytań HTTP lub zapisać je do wykonania przez inny wątek za pomocą Menedżera sesji.
Metody te są dziedziczone z BaseParser i stanowią podstawę do tworzenia własnych scraperów
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Otrzymywanie odpowiedzi HTTP na zapytanie, jako argumenty podaje się:
method- metoda zapytania (GET, POST...)url- link do zapytaniaqueryParams- hash z parametrami get lub hash z ciałem zapytania postopts- hash z opcjami zapytania
opts.check_content
check_content: [ warunek1, warunek2, ...] - tablica warunków do sprawdzenia otrzymanej treści, jeśli sprawdzenie nie
powiedzie się, zapytanie zostanie powtórzone z innym proxy.
Możliwości:
- użycie ciągów znaków jako warunków (wyszukiwanie wystąpienia ciągu)
- użycie wyrażeń regularnych jako warunków
- użycie własnych funkcji sprawdzających, do których przekazywane są dane i nagłówki odpowiedzi
- można zdefiniować kilka różnych typów warunków naraz
- dla negacji logicznej umieść warunek w tablicy, tj.
check_content: ['xxxx', [/yyyy/]]oznacza, że zapytanie zostanie uznane za pomyślne, jeśli w otrzymanych danych znajduje się podciągxxxx, a jednocześnie wyrażenie regularne/yyyy/nie znajduje dopasowań na stronie
Dla pomyślnego zapytania muszą zostać zaliczone wszystkie sprawdzenia wskazane w tablicy
Przykład (w komentarzach wskazano, co jest potrzebne, aby zapytanie zostało uznane za pomyślne):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // na otrzymanej stronie powinno zadziałać to wyrażenie regularne
['XXXX'], // na otrzymanej stronie nie powinno być tego podciągu
'</html>', // na otrzymanej stronie powinien być taki podciąg
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // ta funkcja powinna zwrócić true
]
});
opts.decode
decode: 'auto-html' - automatyczne wykrywanie kodowania i konwersja na utf8
Możliwe wartości:
auto-html- na podstawie nagłówków, tagów meta i zawartości strony (optymalna zalecana opcja)utf8- wskazuje, że dokument jest w kodowaniu utf8<encoding>- dowolne inne kodowanie
opts.headers
headers: { ... } - hash z nagłówkami, nazwa nagłówka jest podawana małymi literami, można podać m.in. cookie.
Przykład:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - pozwala nadpisać kolejność sortowania nagłówków
opts.onlyheaders
onlyheaders: 0 - określa odczyt data, jeśli włączone (1), pobiera tylko nagłówki
opts.recurse
recurse: N - maksymalna liczba przekierowań, domyślnie 7, użyj 0, aby wyłączyć podążanie za
przekierowaniami
opts.proxyretries
proxyretries: N - liczba prób wykonania zapytania, domyślnie pobierana z ustawień scrapera
opts.parsecodes
parsecodes: { ... } - lista kodów odpowiedzi HTTP, które scraper uzna za udane, domyślnie pobierana z
ustawień scrapera. Jeśli podasz '*': 1, wszystkie odpowiedzi będą uznawane za udane.
Przykład:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - limit czasu odpowiedzi w sekundach, domyślnie pobierany z ustawień scrapera
opts.do_gzip
do_gzip: 1 - określa, czy używać kompresji (gzip/deflate/br), domyślnie włączone (1), aby wyłączyć
należy ustawić wartość 0
opts.max_size
max_size: N - maksymalny rozmiar odpowiedzi w bajtach, domyślnie pobierany z ustawień scrapera
opts.cookie_jar
cookie_jar: { ... } - hash z plikami cookie. Przykład hasha:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - wskazuje numer bieżącej próby, przy użyciu tego parametru wbudowany mechanizm obsługi prób dla
danego zapytania jest ignorowany
opts.browser
browser: 1 - automatyczna emulacja nagłówków przeglądarki (1 - włączone, 0 - wyłączone)
opts.use_proxy
use_proxy: 1 - nadpisuje użycie proxy dla pojedynczego zapytania wewnątrz JS scrapera nad parametrem globalnym
Use proxy (1 - włączone, 0 - wyłączone)
opts.noextraquery
noextraquery: 0 - wyłącza dodawanie Extra query string do adresu URL zapytania (1 - włączone, 0 - wyłączone)
opts.save_to_file
save_to_file: file - pozwala pobrać plik bezpośrednio na dysk, z pominięciem zapisu w pamięci. Zamiast file podaje się nazwę i
ścieżkę, pod jaką zapisać plik. Przy użyciu tej opcji ignorowane jest wszystko, co związane z data (sprawdzanie treści
w opts.check_content nie zostanie wykonane, response.data będzie puste itd.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - automatyczne obejście ochrony JavaScript CloudFlare przy użyciu przeglądarki Chrome (1 - włączone, 0 -
wyłączone)
Kontrola Chrome Headless w tym przypadku odbywa się poprzez ustawienia scrapera bypassCloudFlareChromeMaxPages
i bypassCloudFlareChromeHeadless, które należy podać w static defaultConf i static editableConf:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - pozwala przechodzić po przekierowaniach zadeklarowanych przez tag meta HTML:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - pozwala zdefiniować funkcję filtrowania przechodzenia po przekierowaniach, jeśli funkcja
zwraca 1, scraper przejdzie po przekierowaniu (uwzględniając parametr opts.recurse), przy zwróceniu 0 przechodzenie po
przekierowaniach zostanie przerwane:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - określa, czy przechodzić po standardowych przekierowaniach (na przykład http -> https
i/lub www.domain.com -> domain.com), jeśli podasz 1, scraper będzie przechodził po standardowych przekierowaniach bez uwzględnienia
parametru opts.recurse
opts.http2
opts.http2: 0 - określa, czy używać protokołu HTTP/2 podczas wykonywania zapytań, domyślnie
używany jest HTTP/1.1
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - ta opcja pozwala omijać blokady stron po odcisku palca TLS (1 - włączone, 0 -
wyłączone)
opts.tlsOpts
tlsOpts: { ... } – pozwala
przekazywać ustawienia dla
połączeń https
await this.cookies.*
Praca z plikami cookie dla bieżącego zapytania
.getAll()
Pobieranie tablicy plików cookie
await this.cookies.getAll();
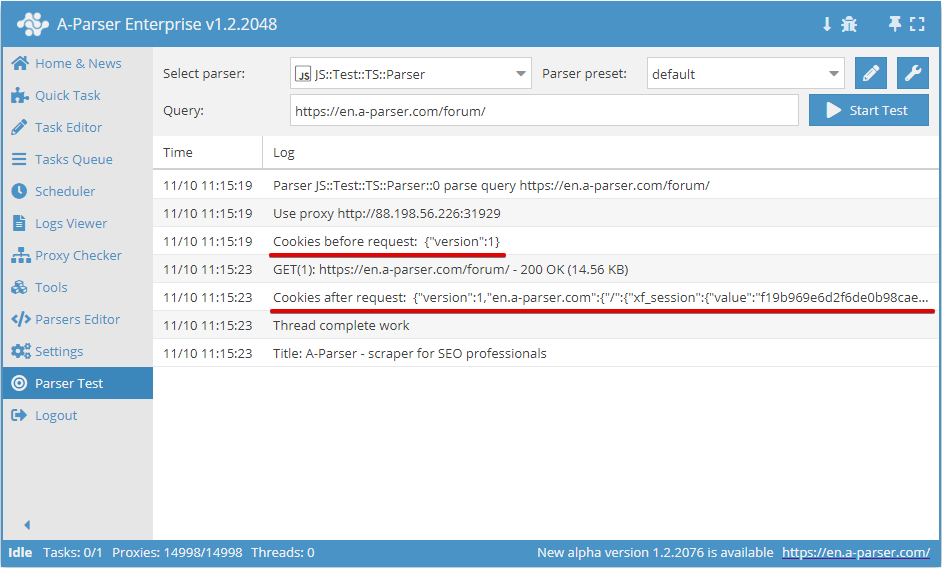
.setAll(cookie_jar)
Ustawianie plików cookie, jako argument musi zostać przekazany hash z plikami cookie
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
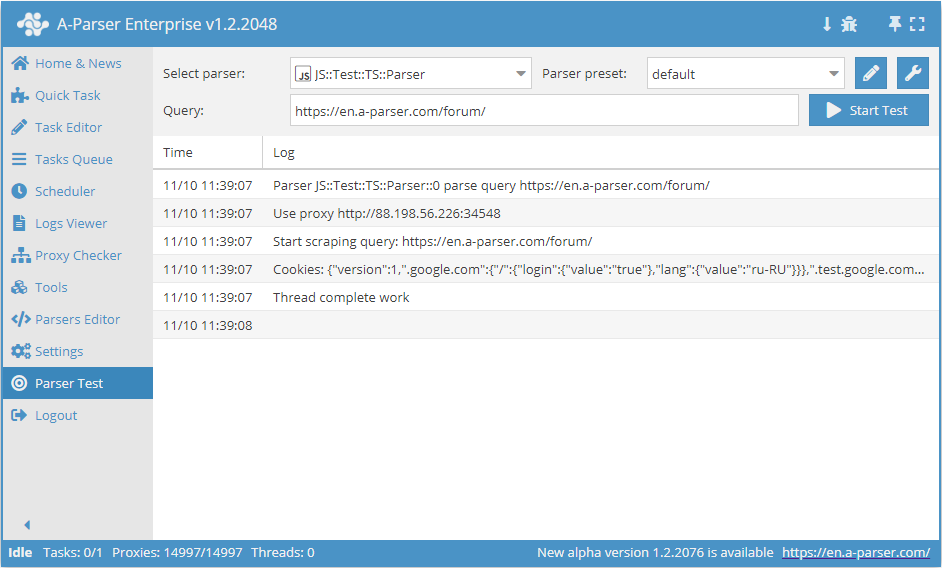
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - ustawianie pojedynczego pliku cookie.
Zakres widoczności pliku cookie zależy bezpośrednio od formatu podanej domeny, dlatego w host uwzględniana jest obecność kropki przed hostem:
- jeśli kropka jest podana (
this.cookies.set('.domain.com', ...)), to cookie będzie używane dla wszystkich subdomen (np. a.domain.com, b.a.domain.com) - jeśli host jest podany bez kropki z przodu (
this.cookies.set('site.com', ...)), to cookie będzie używane ściśle dla podanego hosta (host-only cookie) i nie jest przekazywane do subdomen
Ta różnica jest krytycznie ważna, ponieważ jednoczesne istnienie plików cookie z kropką i bez może prowadzić do ich duplikowania i nieprzewidywalnego działania strony. Dla poprawnej emulacji zawsze sprawdzaj, jak dokładnie docelowa strona ustawia pliki cookie (z atrybutem Domain lub bez) i używaj odpowiedniego formatu.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
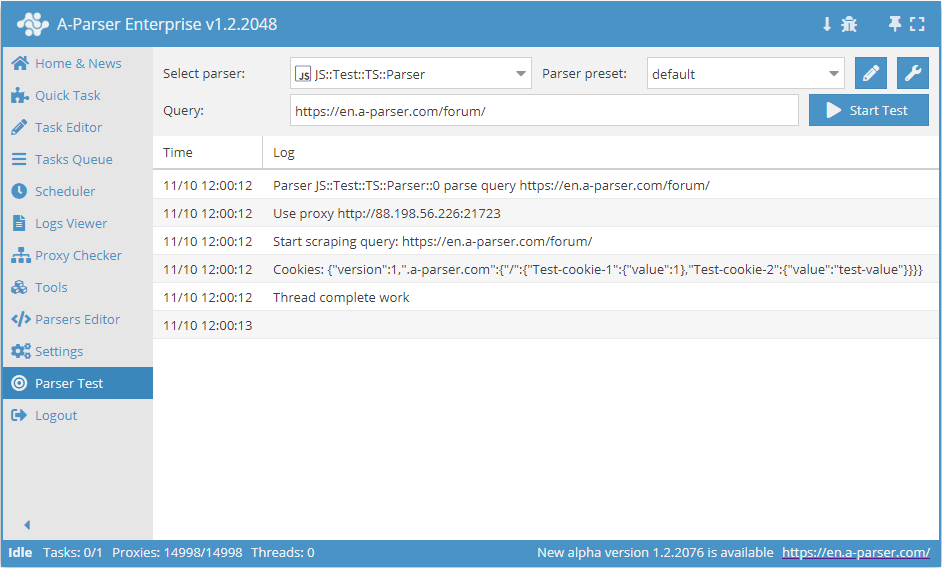
await this.proxy.*
Praca z proxy
.next()
Zmień proxy na następne, stare proxy nie będzie już używane dla bieżącego zapytania
.ban()
Zmień i zablokuj proxy (należy używać, gdy serwis blokuje pracę po IP), proxy zostanie zablokowane na czas
wskazany w ustawieniach scrapera (proxybannedcleanup)
.get()
Pobierz bieżące proxy (ostatnie proxy, z którym zostało wykonane zapytanie)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - ustaw proxy dla następnego zapytania. Parametr noChange jest opcjonalny, jeśli ustawiono true, proxy nie będzie zmieniane między próbami. Domyślnie noChange = false
await this.sessionManager.*
Metody do pracy z sesjami. Każda sesja obowiązkowo przechowuje użyte proxy i pliki cookie. Można również dodatkowo zapisywać dowolne dane.
Aby korzystać z sesji w JS scraperze, najpierw obowiązkowo należy zainicjować Menedżera sesji. Robi się to za pomocą metody await this.sessionManagerinit() w init()
.init(opts?)
Inicjalizacja Menedżera sesji. Jako argument można przekazać obiekt (opts) z dodatkowymi parametrami (wszystkie parametry są opcjonalne):
name- pozwala nadpisać nazwę scrapera, do którego należą sesje, domyślnie równa nazwie scrapera, w którym następuje inicjalizacjawaitForSession- nakazuje scraperowi czekać na sesję, dopóki się nie pojawi (jest to istotne tylko wtedy, gdy pracuje kilka zadań, np. jedno generuje sesje, drugie ich używa), tj..get()i.reset()będą zawsze czekać na sesjędomain- nakazuje szukać sesji wśród wszystkich zapisanych dla tego scrapera (jeśli wartość nie jest podana) lub tylko dla konkretnej domeny (należy podać domenę z kropką z przodu, np..site.com)sessionsKey- pozwala ręcznie ustawić nazwę magazynu sesji, jeśli nie jest podana, nazwa jest tworzona automatycznie na podstawiename(lub nazwy scrapera, jeślinamenie jest podany), domeny i proxycheckeraexpire- ustawia czas życia sesji w minutach, domyślnie nieograniczony
Przykład użycia:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Pobieranie nowej sesji, należy wywołać przed wykonaniem zapytania (przed pierwszą próbą). Zwraca obiekt z dowolnymi danymi zapisanymi w sesji. Jako argument można przekazać obiekt (opts) z dodatkowymi parametrami (wszystkie parametry są opcjonalne):
waitTimeout- możliwość określenia, ile minut czekać na pojawienie się sesji, działa niezależnie od parametruwaitForSessionw.init()(ignoruje go), po upływie zostanie użyta pusta sesjatag- pobieranie sesji z określonym tagiem, można użyć np. nazwy domeny do powiązania sesji z domenami, z których zostały pobrane
Przykład użycia:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Czyszczenie plików cookie i pobieranie nowej sesji. Należy użyć, jeśli z bieżącą sesją zapytanie nie powiodło się. Zwraca obiekt z dowolnymi danymi zapisanymi w sesji. Jako argument można przekazać obiekt (opts) z dodatkowymi parametrami (wszystkie parametry są opcjonalne):
waitTimeout- możliwość określenia, ile minut czekać na pojawienie się sesji, działa niezależnie od parametruwaitForSessionw.init()(ignoruje go), po upływie zostanie użyta pusta sesjatag- pobieranie sesji z określonym tagiem, można użyć np. nazwy domeny do powiązania sesji z domenami, z których zostały pobrane
Przykład użycia:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Zapisywanie udanej sesji z możliwością zapisywania dowolnych danych w sesji. Obsługuje 2 opcjonalne argumenty:
sessionOpts- dowolne dane do przechowywania w sesji, może to być liczba, ciąg znaków, tablica lub obiektsaveOpts- obiekt z parametrami zapisywania sesji:multiply- opcjonalny parametr, pozwala powielić sesję, jako wartość należy podać liczbętag- opcjonalny parametr, ustawia tag dla zapisywanej sesji, można użyć np. nazwy domeny do powiązania sesji z domenami, z których zostały pobrane
Przykład użycia:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Zwraca liczbę sesji dla bieżącego Menedżera sesji
Przykład użycia:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Usuwa wszystkie sesje o podanym id. Zwraca liczbę usuniętych sesji. Id bieżącej sesji znajduje się w zmiennej this.sessionId
Przykład użycia:
const removedCount = await this.sessionManager.removeById(this.sessionId);
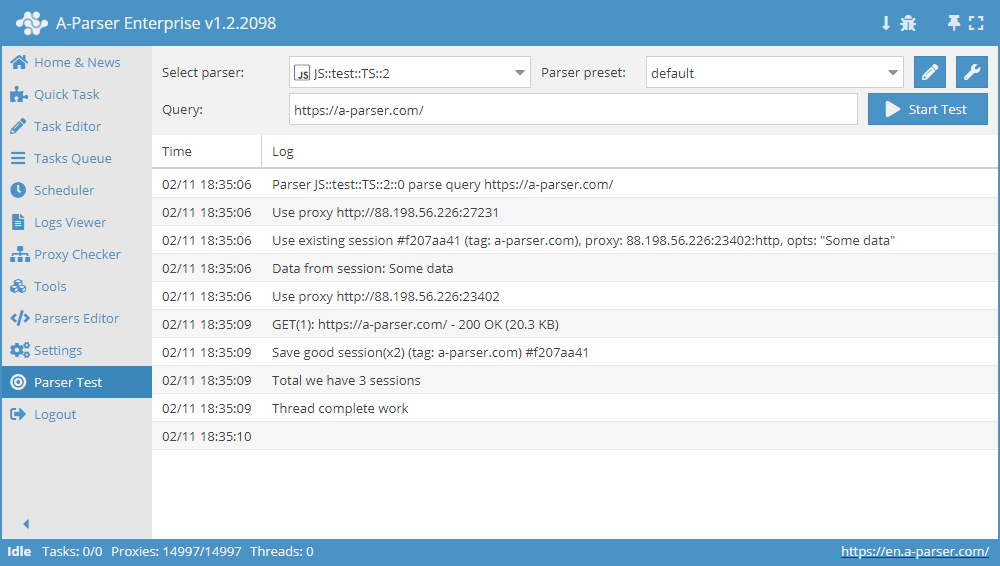
Kompleksowy przykład użycia Menedżera sesji
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Metody zapytań await this.request
Metoda GET
Przekazać parametry zapytania można bezpośrednio w ciągu zapytania https://a-parser.com/users/?type=staff:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
Lub jako obiekt w queryParams, gdzie key: value odpowiada param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
Metoda POST
Jeśli używana jest metoda POST, ciało zapytania można przekazać na dwa sposoby:
Wymienić nazwy zmiennych i ich wartości w
queryParams, na przykład:{
"key": set.query,
"id": 1234,
"type": "text"
}Wymienić je w
opts.body, na przykład:body: 'key=' + set.query + '&id=1234&type=text'
Jeśli ciało zapytania jest przekazywane jako obiekt, zostaje ono automatycznie przekonwertowane na formę form-urlencoded, również jeśli podano body i nie
podano nagłówka content-type, zostanie automatycznie przypisany content-type: application/x-www-form-urlencoded:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Jeśli ciało zapytania POST jest ciągiem znaków lub buforem, jest ono przekazywane w takiej formie:
// zapytanie z ciągiem znaków
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// zapytanie z buforem
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Wysyłanie plików
Wysyłanie pliku zapytaniem POST z użyciem modułu form-data:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Przykład wysyłania pliku w zapytaniu POST z typem zawartości multipart/form-data:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});