HTML::TextExtractor - Парсинг контента (текста) с сайта
Обзор парсера
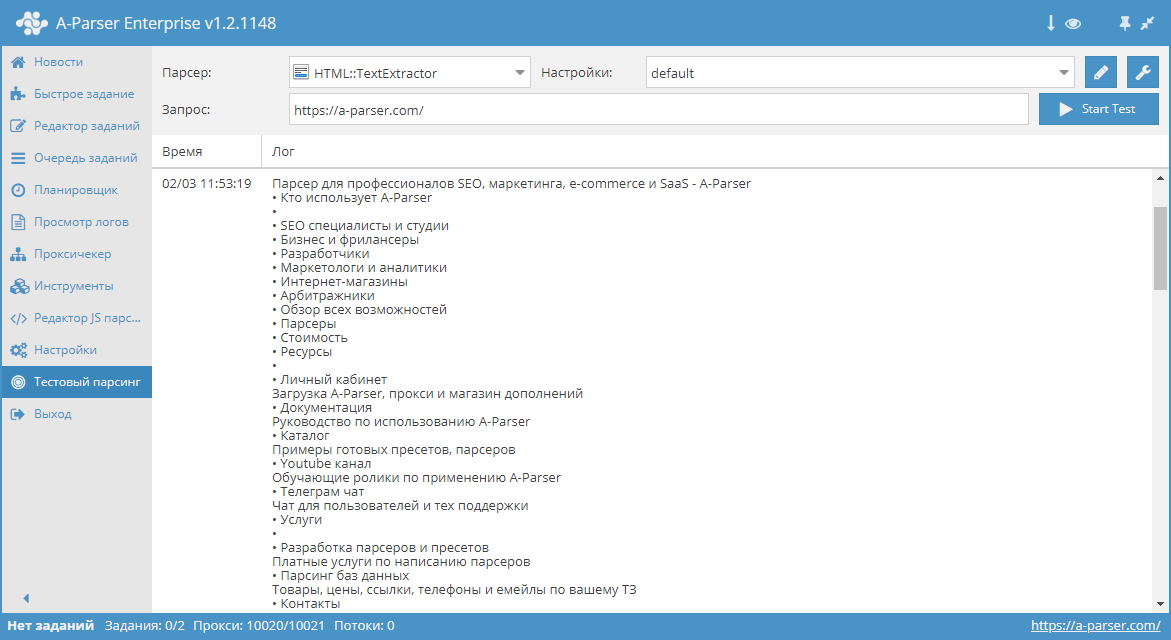
 HTML::TextExtractor парсит текстовые блоки с указанной страницы. Данный парсер контента поддерживает многостраничный парсинг (переход по страницам). Имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга контента со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 2000 запросов в минуту – это 120 000 ссылок за час.
HTML::TextExtractor парсит текстовые блоки с указанной страницы. Данный парсер контента поддерживает многостраничный парсинг (переход по страницам). Имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга контента со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 2000 запросов в минуту – это 120 000 ссылок за час.Кейсы по применению парсера
Парсинг текста через Chrome на примере lingualeo.com
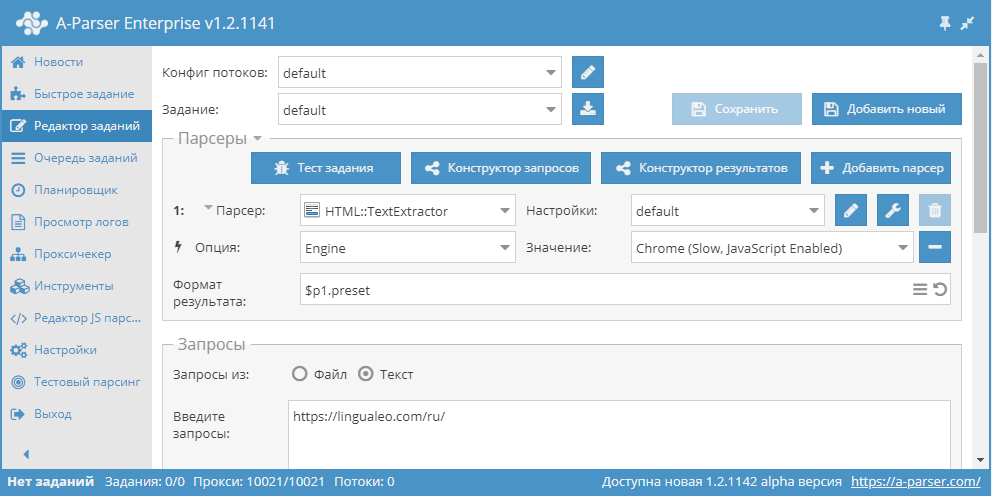
- Добавить опцию Engine, в списке выбрать движок
Chrome (Slow, JavaScript Enabled). - В качестве запроса указать ссылку на сайт, с которого требуется спарсить текст.
Данная опция может быть полезна в случаях, когда сайт подгружает основной текст скриптами по ходу загрузки страницы и при использовании HTTP (Fast, JavaScript Disabled) результат отсутствует или оказывается неполным.
Скачать пример
Как импортировать пример в А-Парсер
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Парсинг текста с переходом по страницам на примере новостей
Результаты сохраняются в директории aparser/results/example/textextractor в отдельный файл для каждого запроса. В качестве имени указывается порядковый номер запроса.
- Добавить опцию Check next page, в качестве регулярки указать
(forum\/news\/page-\d+)"[^>]+>Вперёд. - Добавить опцию Page as new query.
- Изменить Имя файла на
example/textextractor/${query.num}.txt. - В качестве запроса указать ссылку на первую страницу с новостями A-Parser:
https://a-parser.com/forum/news/.
Скачать пример
Как импортировать пример в А-Парсер
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Собираемые данные
- Парсит текстовые блоки с указанной страницы
- Массив со всеми собранными страницами (используется при работе опции Use Pages)
Возможности
- Многостраничный парсинг текста (переход по страницам)
- Автоматическая очистка текста от HTML тегов
- Возможность задать минимальную длину текстового блока
- Опциональное удаление ссылочных анкоров из текста
- Поддерживает сжатия gzip/deflate/brotli
- Определение и преобразование кодировок сайтов в UTF-8
- Обход защиты CloudFlare
- Выбор движка (HTTP или Chrome)
Варианты использования
- Парсинг текстового контента с любых сайтов
Запросы
В качестве запросов необходимо указывать ссылки на страницы, с которых необходимо спарсить текстовые блоки, например:
https://a-parser.com/
Варианты вывода результатов
A-Parser поддерживает гибкое форматирование результатов благодаря встроенному шаблонизатору Template Toolkit, что позволяет ему выводить результаты в произвольной форме, а также в структуированной, например CSV или JSON
Вывод по умолчанию
Формат результата:
$texts.format('$text\n')
Пример результата:
Здравствуйте, Супер Команда Высочайших Профессионалов своего Дела! Спасибо за возможность изучения Испанского, Турецкого и Португальского языка! Желаю Вам дальнейшего расширения Ваших Возможностей! Вдохновения и Творчества! И просьба добавить Возможность изучения Немецкого и Французского языка!”
Использую лингвалео уже многие годы, первый раз начал заниматься еще когда приложения не было совсем, был только сайт) Спасибо разработчикам, продолжайте в том же духе, с креативом и с большой любовью к делу)
Технический английский для IT: словари, учебники, журналы
Изучай языки онлайн Изучай английский онлайн Изучай вьетнамский онлайн Изучай греческий онлайн Изучай индонезийский онлайн Изучай испанский онлайн Изучай итальянский онлайн Изучай китайский онлайн Изучай корейский онлайн Изучай немецкий онлайн Изучай нидерландский онлайн Изучай польский онлайн Изучай португальский онлайн Изучай сербский онлайн Изучай турецкий онлайн Изучай украинский онлайн Изучай французский онлайн Изучай хинди онлайн Изучай чешский онлайн Изучай японский онлайн
Возможные настройки
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Min block length | 50 | Минимальная длинна текстового блока в символах. |
| Skip anchor text | ☐ | Пропускать ли анкоры в тексте. |
| Ignore tags list | Опция для указания тегов, которые нужно игнорировать. Пример указания: div,span,p | |
| Good status | All | Выбор какой ответ с сервера будет считается успешным. Если при парсинге будет другой ответ от сервера, то запрос будет повторен с другим прокси. |
| Good code RegEx | Возможность указать регулярное выражения для проверки кода ответа. | |
| Method | GET | Метод запроса. |
| POST body | Контент для передачи на сервер при использовании метода POST. Поддерживает переменные $query – URL запроса, $query.orig – исходный запрос и $pagenum - номер страницы при использовании опции Use Pages. | |
| Cookies | Возможность указать cookies для запроса. | |
| User agent | `_Автоматически подставляется user-agent актуальной версии Chrome_ | Заголовок User-Agent при запросе страниц. |
| Additional headers | Возможность указать произвольные заголовки запроса с поддержкой возможностей шаблонизатора и использованием переменных из конструктора запросов. | |
| Read only headers | ☐ | Читать только заголовки. В некоторых случаях позволяет экономить трафик, если нет необходимости обрабатывать контент. |
| Detect charset on content | ☐ | Распознавать кодировку на основе содержимого страницы. |
| Emulate browser headers | ☐ | Эмулировать заголовки браузера. |
| Max redirects count | 7 | Максимальное кол-во редиректов, по которым будет переходить парсер. |
| Max cookies count | 16 | Максимальное число cookies для сохранения. |
| Bypass CloudFlare | ☑ | Автоматический обход проверки CloudFlare. |
| Follow common redirects | ☑ | Позволяет делать редиректы http <-> https и www.domain <-> domain в пределах одного домена в обход лимита Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Позволяет выбрать движок HTTP (быстрее, без JavaScript) или Chrome (медленнее, JavaScript включен). |
| Chrome Headless | ☐ | Если опция включена, браузер не будет отображаться. |
| Chrome DevTools | ☑ | Позволяет использовать инструменты для отладки Chromium. |
| Chrome Log Proxy connections | ☑ | Если опция включена, в лог будет выводиться информация по подключениям chrome. |
| Chrome Wait Until | networkidle2 | Определяет, когда страница считается загруженной. Подробнее о значениях. |
| Use HTTP/2 transport | ☐ | Определяет, использовать ли HTTP/2 вместо HTTP/1.1. Например, Google и Majestic сразу банят, если использовать HTTP/1.1. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Обход CF через Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Макс. кол-во страниц при обходе CF через Chrome. |