HTML::EmailExtractor - Парсинг email адресов со страниц сайтов
Обзор парсера
 HTML::EmailExtractor собирает адреса электронной почты с указанных страниц. Поддерживает переход по внутренним страницам сайта до указанной глубины, что позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки. Email парсер имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга почт со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 250 запросов в минуту – это 15 000 ссылок за час.
HTML::EmailExtractor собирает адреса электронной почты с указанных страниц. Поддерживает переход по внутренним страницам сайта до указанной глубины, что позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки. Email парсер имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга почт со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 250 запросов в минуту – это 15 000 ссылок за час.Кейсы по применению парсера
Парсинг почт с сайта с прохождением страниц вглубь до указанного лимита
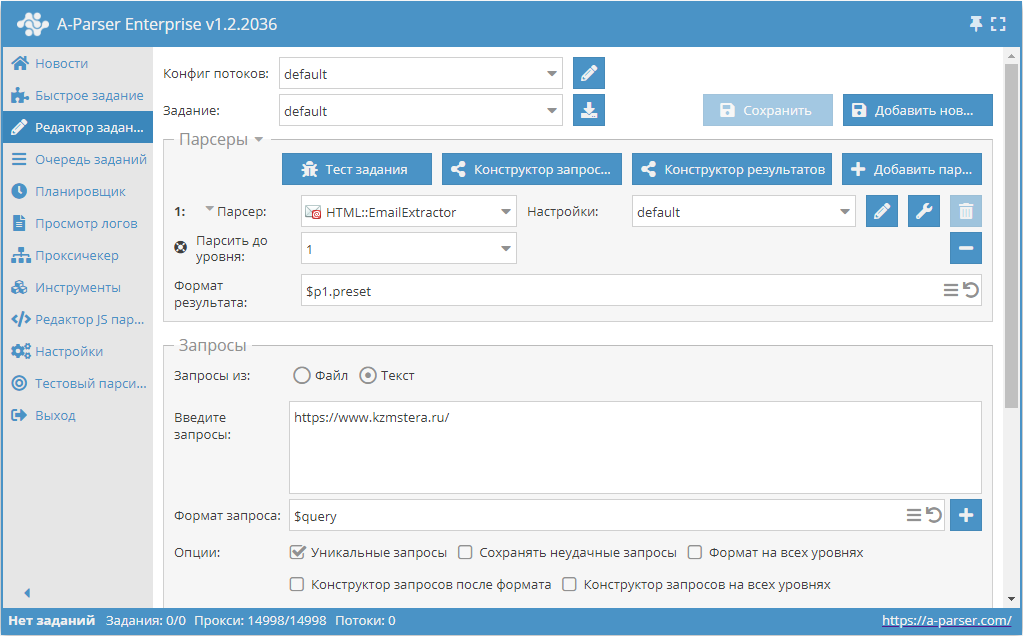
- Добавить опцию Парсить до уровня, в списке выбрать необходимое значение (лимит).
- В разделе Запросы поставить галочку на опцию
Уникальные запросы. - В разделе Результаты поставить галочку на опцию
Уник по строке. - В качестве запроса указать ссылку на сайт, с которого требуется спарсить почты.
Скачать пример
Как импортировать пример в А-Парсер
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
подсказка
Парсинг почт по базе сайтов с прохождением каждого сайта на глубину до указанного лимита
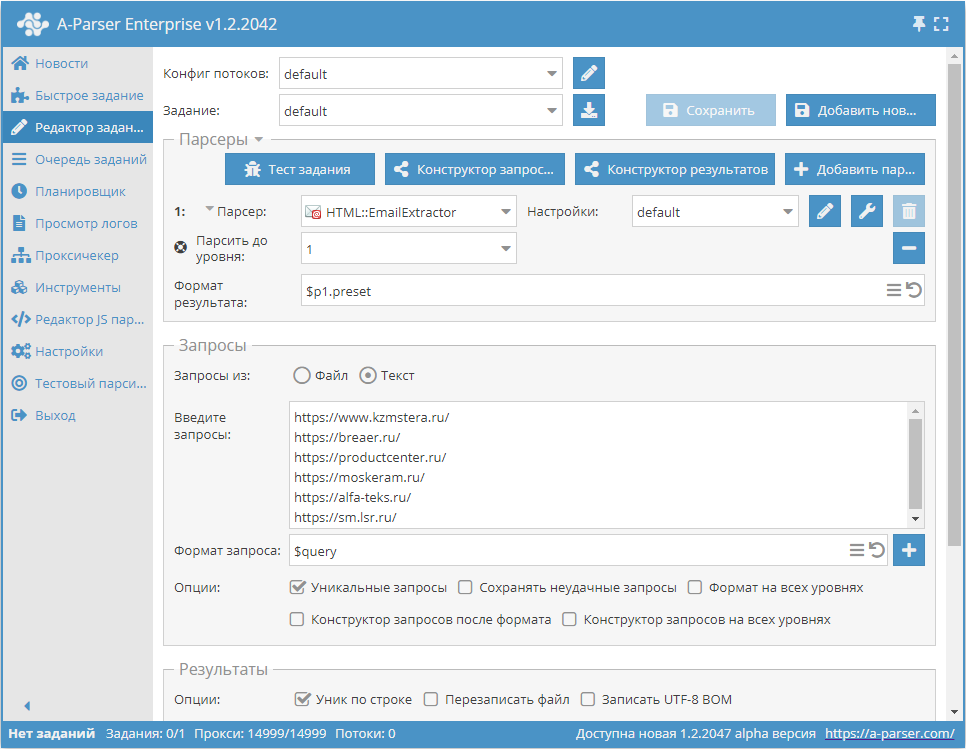
- Добавить опцию Парсить до уровня, в списке выбрать необходимое значение (лимит).
- В разделе Запросы поставить галочку на опцию
Уникальные запросы. - В разделе Результаты поставить галочку на опцию
Уник по строке. - В качестве запроса указать ссылки на сайты, с которых требуется спарсить почты, или в Запросы из указать
Файли загрузить файл запросов с базой сайтов.
Скачать пример
Как импортировать пример в А-Парсер
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
подсказка
Парсинг почт по базе ссылок
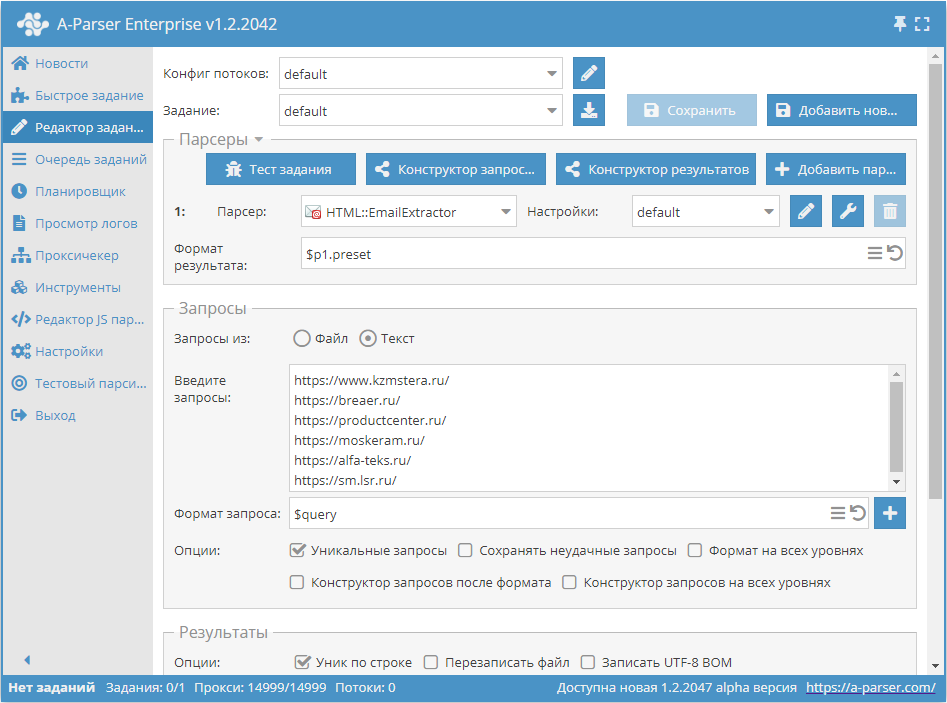
- В разделе Запросы поставить галочку на опцию
Уникальные запросы. - В разделе Результаты поставить галочку на опцию
Уник по строке. - В качестве запроса указать ссылки, с которых требуется спарсить почты, или в Запросы из указать
Файли загрузить файл запросов с базой ссылок.
Скачать пример
Как импортировать пример в А-Парсер
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
подсказка
Собираемые данные
- Адреса электронной почты
- Общее кол-во адресов на странице
- Массив со всеми собранными страницами (используется при работе опции Use Pages)
Возможности
- Многостраничный парсинг (переход по страницам)
- Переход по внутренним страницам сайта до указанной глубины (опция Parse to level) – позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки
- Определение follow links для ссылок
- Лимит переходов по страницам (опция Follow links limit)
- Возможность указать считать сабдомены как внутренние страницы сайта
- Поддерживает сжатия gzip/deflate/brotli
- Определение и преобразование кодировок сайтов в UTF-8
- Обход защиты CloudFlare
- Выбор движка (HTTP или Chrome)
- Поддержка всего функционала
 HTML::LinkExtractor
HTML::LinkExtractor
Варианты использования
- Парсинг email адресов
- Вывод кол-ва e-mail адресов
Запросы
В качестве запросов необходимо указывать ссылки на страницы, например:
https://a-parser.com/pages/support/
Варианты вывода результатов
A-Parser поддерживает гибкое форматирование результатов благодаря встроенному шаблонизатору Template Toolkit, что позволяет ему выводить результаты в произвольной форме, а также в структуированной, например CSV или JSON
Вывод кол-ва email адресов
Формат результата:
$mailcount
Пример результата:
4
Возможные настройки
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Good status | All | Выбор какой ответ с сервера будет считается успешным. Если при парсинге будет другой ответ от сервера, то запрос будет повторен с другим прокси |
| Good code RegEx | Возможность указать регулярное выражения для проверки кода ответа | |
| Ban Proxy Code RegEx | Возможность банить прокси на время (Proxy ban time) на основе кода ответа сервера | |
| Method | GET | Метод запроса |
| POST body | Контент для передачи на сервер при использовании метода POST. Поддерживает переменные $query – URL запроса, $query.orig – исходный запрос и $pagenum - номер страницы при использовании опции Use Pages. | |
| Cookies | Возможность указать cookies для запроса. | |
| User agent | _Автоматически подставляется user-agent актуальной версии Chrome_ | Заголовок User-Agent при запросе страниц |
| Additional headers | Возможность указать произвольные заголовки запроса с поддержкой возможностей шаблонизатора и использованием переменных из конструктора запросов | |
| Read only headers | ☐ | Читать только заголовки. В некоторых случаях позволяет экономить трафик, если нет необходимости обрабатывать контент |
| Detect charset on content | ☐ | Распознавать кодировку на основе содержимого страницы |
| Emulate browser headers | ☐ | Эмулировать заголовки браузера |
| Max redirects count | 0 | Максимальное кол-во редиректов, по которым будет переходить парсер |
| Follow common redirects | ☑ | Позволяет делать редиректы http <-> https и www.domain <-> domain в пределах одного домена в обход лимита Max redirects count |
| Max cookies count | 16 | Максимальное число cookies для сохранения |
| Engine | HTTP (Fast, JavaScript Disabled) | Позволяет выбрать движок HTTP (быстрее, без JavaScript) или Chrome (медленнее, JavaScript включен) |
| Chrome Headless | ☐ | Если опция включена, браузер не будет отображаться |
| Chrome DevTools | ☑ | Позволяет использовать инструменты для отладки Chromium |
| Chrome Log Proxy connections | ☑ | Если опция включена, в лог будет выводиться информация по подключениям chrome |
| Chrome Wait Until | networkidle2 | Определяет, когда страница считается загруженной. Подробнее о значениях. |
| Use HTTP/2 transport | ☐ | Определяет, использовать ли HTTP/2 вместо HTTP/1.1. Например, Google и Majestic сразу банят, если использовать HTTP/1.1. |
| Don't verify TLS certs | ☐ | Отключение валидации TLS сертификатов |
| Randomize TLS Fingerprint | ☐ | Данная опция позволяет обходить бан сайтов по TLS отпечатку |
| Bypass CloudFlare | ☑ | Автоматический обход проверки CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Обход CF через Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Макс. кол-во страниц при обходе CF через Chrome |
| Subdomains are internal | ☐ | Считать ли поддомены как внутренние ссылки |
| Follow links | Internal only | По каким ссылкам переходить |
| Follow links limit | 0 | Лимит Follow links, применяется к каждому уникальному домену |
| Skip comment blocks | ☐ | Пропускать ли блоки комментариев |
| Search Cloudflare protected e-mails | ☑ | Парсить ли Cloudflare protected e-mails. |
| Skip non-HTML blocks | ☑ | Не собирать почтовые адреса в тегах (script, style, comment и т.д.). |
| Skip meta tags | ☐ | Не собирать почтовые адреса в meta тегах |
| Search URL encoded e-mails | ☐ | Сбор URL encoded почт |