HTML::LinkExtractor - Парсер внешних и внутренних ссылок с указанного сайта
Обзор парсера
 HTML::LinkExtractor – парсер внешних и внутренних ссылок с указанного сайта. Поддерживает многостраничный парсинг и переход по внутренним страницам сайта до указанной глубины, что позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки. Имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга почт со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 2000 запросов в минуту – это 120 000 ссылок за час.
HTML::LinkExtractor – парсер внешних и внутренних ссылок с указанного сайта. Поддерживает многостраничный парсинг и переход по внутренним страницам сайта до указанной глубины, что позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки. Имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга почт со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 2000 запросов в минуту – это 120 000 ссылок за час.Кейсы по применению парсера
Сбор всех внешних ссылок с сайта
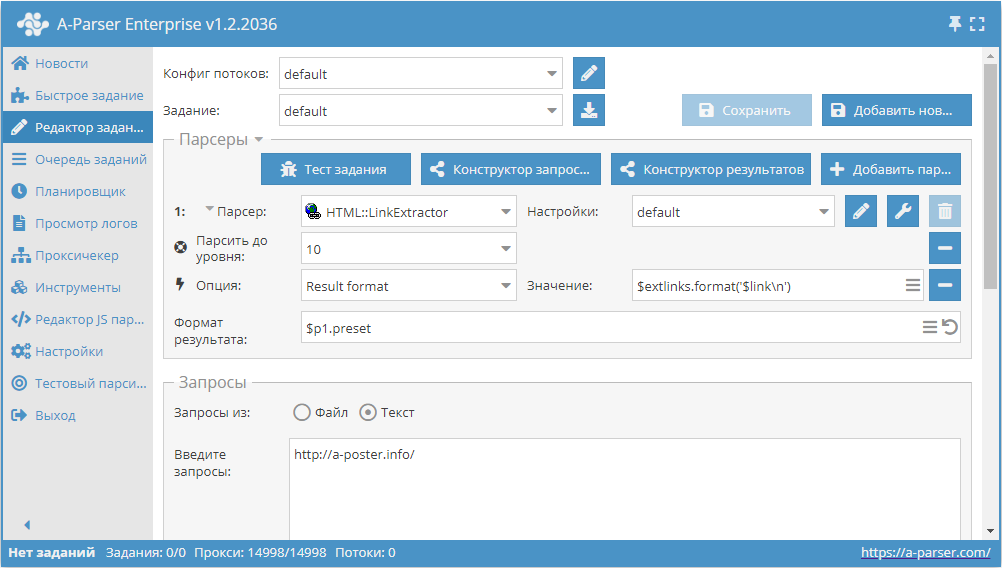
- Добавить опцию Парсить до уровня, в списке выбрать значение
10(переход по соседним страницам до 10-ого уровня). - Добавить опцию Result format, в качестве значения указать
$extlinks.format('$link\n')(вывод внешних ссылок). - В разделе Запросы поставить галочку на опцию
Уникальные запросы. - В разделе Результаты поставить галочку на опцию
Уник по строке. - В качестве запроса указать ссылку на сайт, с которого требуется спарсить внешние ссылки.
Скачать пример
Как импортировать пример в А-Парсер
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
подсказка
Сбор всех внутренних ссылок с сайта
Аналогично первому кейсу, но в шаге 2 в качестве значения нужно указать $intlinks.format('$link\n') (вывод внутренних ссылок).
Скачать пример
Как импортировать пример в А-Парсер
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
Переход только по ссылкам, в которых отсутствует слово forum
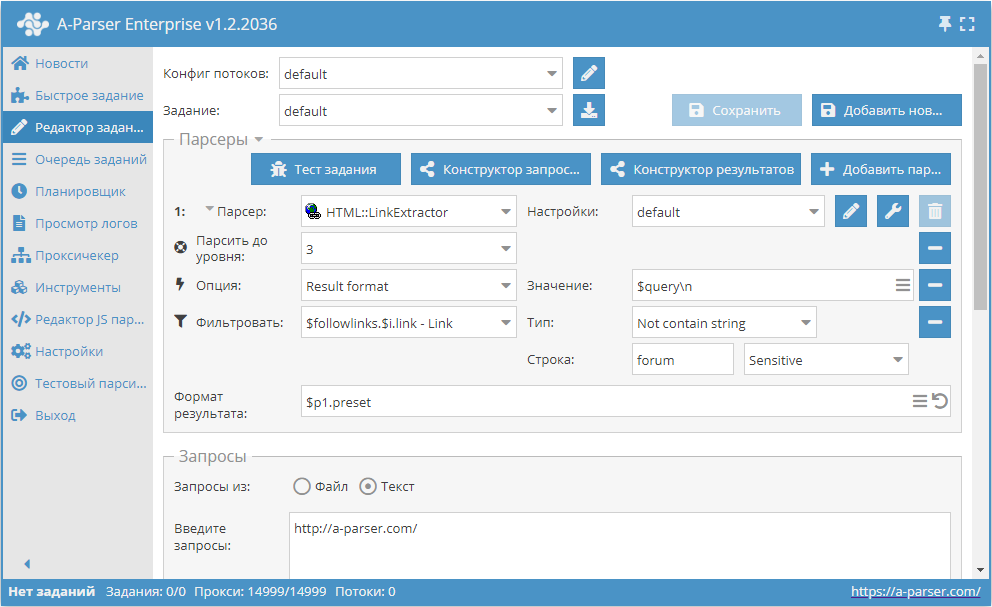
- Добавить опцию Парсить до уровня, в списке выбрать значение
3(переход по соседним страницам до 3-ого уровня). - Добавить опцию Result format, в качестве значения указать
$query. - Добавить фильтр. Фильтровать по
$followlinks.$i.link - Link, тип выбратьНе содержит строку, в качестве самой строки указатьforum. - В разделе Запросы поставить галочку на опцию
Уникальные запросы. - В разделе Результаты поставить галочку на опцию
Уник по строке. - В качестве запроса указать ссылку на сайт, с которого требуется спарсить ссылки.
Скачать пример
Как импортировать пример в А-Парсер
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
подсказка
Собираемые данные
- Количество внешних ссылок
- Количество внутренних ссылок
- Внешние ссылки:
- сами ссылки
- анкоры
- очищенные от HTML тегов анкоры
- параметр nofollow
- тег
<a>полностью
- Внутренние ссылки:
- сами ссылки
- анкоры
- очищенные от HTML тегов анкоры
- параметр nofollow
- тег
<a>полностью
- Массив со всеми собранными страницами (используется при работе опции Use Pages)
Возможности
- Многостраничный парсинг (переход по страницам)
- Переход по внутренним страницам сайта до указанной глубины (опция Parse to level) – позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки
- Лимит переходов по страницам (опция Follow links limit)
- Автоматически очищает анкор от HTML тегов
- Определение nofollow для каждой ссылки
- Возможность указать считать сабдомены как внутренние страницы сайта
- Поддерживает сжатия gzip/deflate/brotli
- Определение и преобразование кодировок сайтов в UTF-8
- Обход защиты CloudFlare
- Выбор движка (HTTP или Chrome)
Варианты использования
- Получение полной карты сайта (сохранение всех внутренних ссылок)
- Получение всех внешних ссылок с сайта
- Проверка обратной ссылки на свой сайт
Запросы
В качестве запросов необходимо указывать ссылки на страницы, с которых необходимо собрать ссылки, или точку входа (например, главную страницу сайта), в случаях, когда используется опция Parse to level:
https://lenta.ru/
https://a-parser.com/wiki/index/
Варианты вывода результатов
A-Parser поддерживает гибкое форматирование результатов благодаря встроенному шаблонизатору Template Toolkit, что позволяет ему выводить результаты в произвольной форме, а также в структуированной, например CSV или JSON
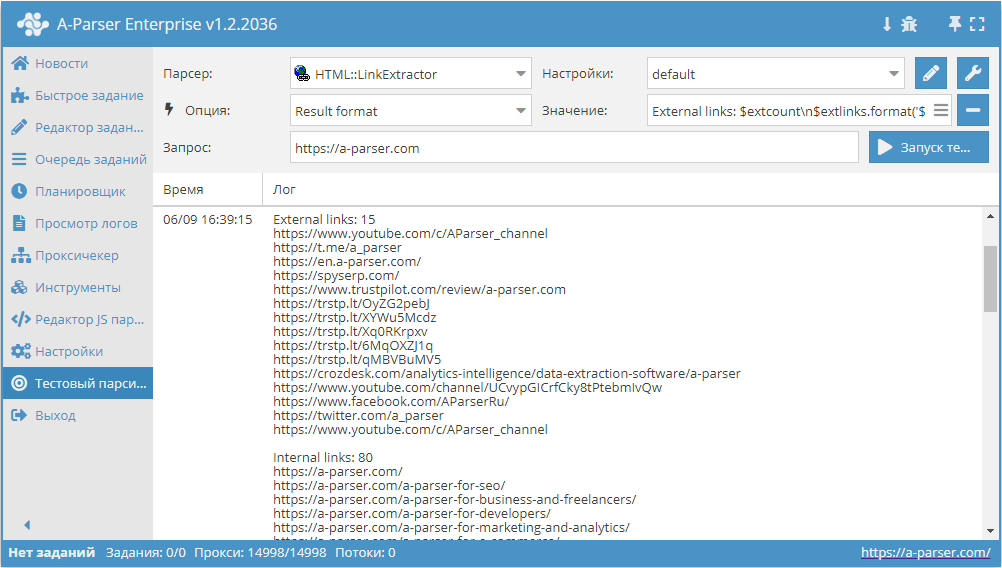
Вывод внешних и внутренних ссылок с их количеством
Формат результата:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
Пример результата:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
Возможные настройки
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Good status | All | Выбор какой ответ с сервера будет считается успешным. Если при парсинге будет другой ответ от сервера, то запрос будет повторен с другим прокси |
| Good code RegEx | Возможность указать регулярное выражения для проверки кода ответа | |
| Ban Proxy Code RegEx | Возможность банить прокси на время(Proxy ban time) на основе кода ответа сервера | |
| Method | GET | Метод запроса |
| POST body | Контент для передачи на сервер при использовании метода POST. Поддерживает переменные $query – URL запроса, $query.orig – исходный запрос и $pagenum - номер страницы при использовании опции Use Pages. | |
| Cookies | Возможность указать cookies для запроса. | |
| User agent | _Автоматически подставляется user-agent актуальной версии Chrome_ | Заголовок User-Agent при запросе страниц |
| Additional headers | Возможность указать произвольные заголовки запроса с поддержкой возможностей шаблонизатора и использованием переменных из конструктора запросов | |
| Read only headers | ☐ | Читать только заголовки. В некоторых случаях позволяет экономить трафик, если нет необходимости обрабатывать контент |
| Detect charset on content | ☐ | Распознавать кодировку на основе содержимого страницы |
| Emulate browser headers | ☐ | Эмулировать заголовки браузера |
| Max redirects count | 0 | Максимальное кол-во редиректов, по которым будет переходить парсер |
| Follow common redirects | ☑ | Позволяет делать редиректы http <-> https и www.domain <-> domain в пределах одного домена в обход лимита Max redirects count |
| Max cookies count | 16 | Максимальное число cookies для сохранения |
| Engine | HTTP (Fast, JavaScript Disabled) | Позволяет выбрать движок HTTP (быстрее, без JavaScript) или Chrome (медленнее, JavaScript включен) |
| Chrome Headless | ☐ | Если опция включена, браузер не будет отображаться |
| Chrome DevTools | ☑ | Позволяет использовать инструменты для отладки Chromium |
| Chrome Log Proxy connections | ☑ | Если опция включена, в лог будет выводиться информация по подключениям chrome |
| Chrome Wait Until | networkidle2 | Определяет, когда страница считается загруженной. Подробнее о значениях. |
| Use HTTP/2 transport | ☐ | Определяет, использовать ли HTTP/2 вместо HTTP/1.1. Например, Google и Majestic сразу банят, если использовать HTTP/1.1. |
| Don't verify TLS certs | ☐ | Отключение валидации TLS сертификатов |
| Randomize TLS Fingerprint | ☐ | Данная опция позволяет обходить бан сайтов по TLS отпечатку |
| Bypass CloudFlare | ☑ | Автоматический обход проверки CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Обход CF через Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Макс. кол-во страниц при обходе CF через Chrome |
| Subdomains are internal | ☐ | Считать ли поддомены как внутренние ссылки |
| Follow links | Internal only | По каким ссылкам переходить |
| Follow links limit | 0 | Лимит Follow links, применяется к каждому уникальному домену |
| Skip comment blocks | ☐ | Пропускать ли блоки комментариев |