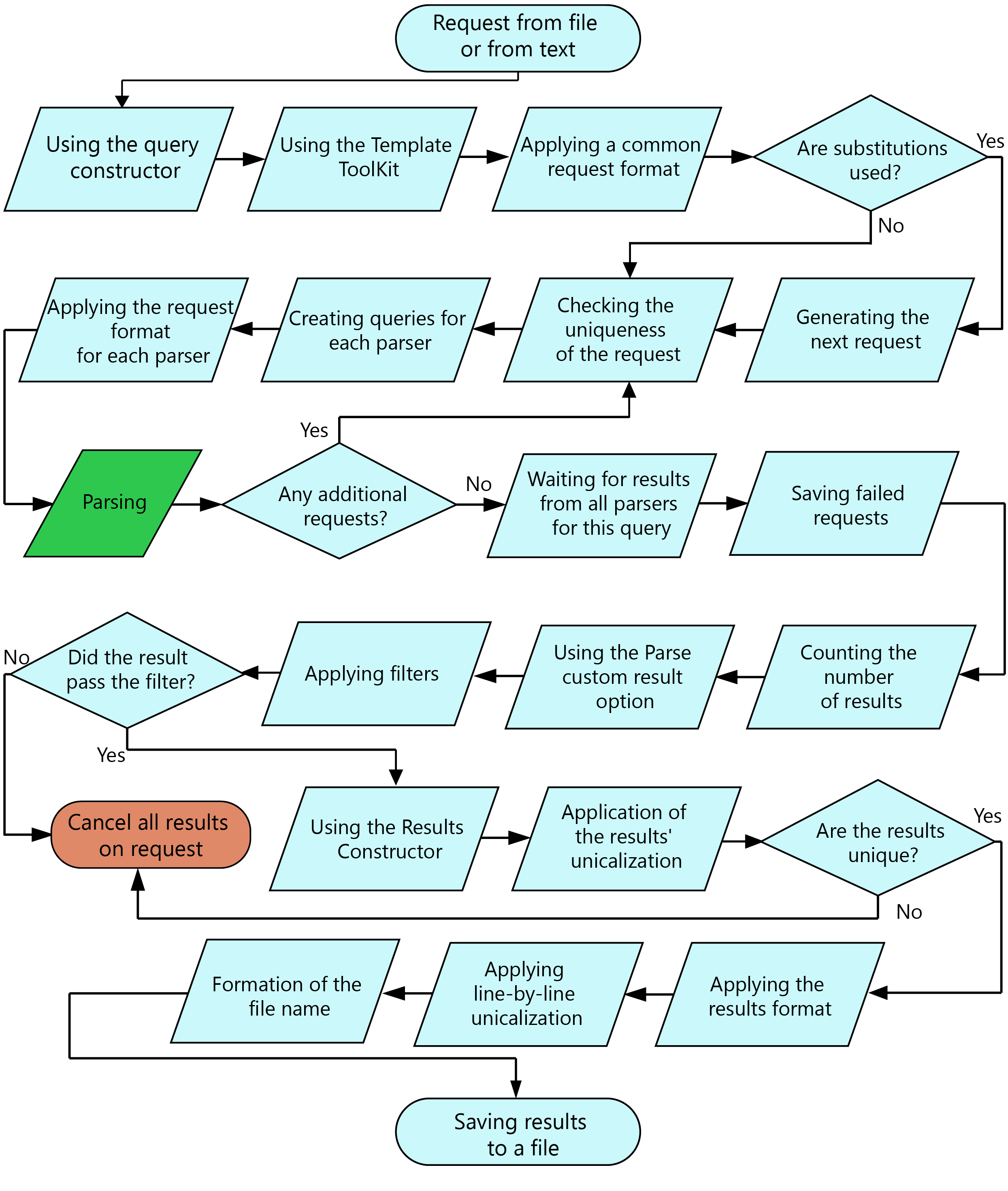
クエリ処理の順序
A-Parserには多くの機能と可能性があります。この図は、ファイル(またはテキスト)からのクエリの読み込みから、最終結果のファイルへの保存までの処理順序を示しています。
クエリ処理順序の概要
注記
- 結果のフィルタリングと重複排除において、比較対象としてシンプル結果が使用されている場合はクエリとその結果全体がキャンセルされます。比較に配列が使用されている場合は、その配列から要素が削除されます。
- 図の多くのステップはオプションであり、タスクエディタで指定された設定に依存します。
- Parse all resultおよびParse to levelオプションを使用すると、追加のクエリが発生する場合があります。すべての追加クエリは、その元となったクエリに対して次のレベルを持ちます。レベルのカウントは0から始まります。つまり、ファイルやテキストからの元のクエリは常にレベル0です。クエリの置換(Query substitutions)適用後のクエリもレベル0となります。
失敗したクエリ
指定された試行回数内に実行できなかったクエリは、失敗とみなされスキップされます。
注記
なぜクエリが失敗したのかを特定するには? ログの記録を有効にするか、タスクテストを実行してください。すべてのエラーはログに記録されます。ログを確認することで、何が問題だったのかを理解できます。
失敗したクエリの例です。ログは、キャプチャのためにクエリが実行できず、試行回数が終了したことを示しています。この場合、キャプチャ解決サービスの接続や、試行回数の増加が有効な場合があります(プロキシを使用してスクレイピングしている場合のみ。そうでない場合、試行回数を増やしても意味がありません)。
試行回数を増やすには? Request retries オプションをオーバーライドして、より大きな値を設定する必要があります。