結果重複排除
重複排除、デデプリケーション、重複の削除、リピートの削除 - これらはすべて、重複する結果が必要ないことを意味します。 A-Parser には2つの重複排除方法があります。それぞれについて詳しく説明します。
行ごとの結果重複排除
このメソッドは、結果のフォーマット後に動作します。結果がファイルに書き込まれる直前に、各行の一意性がチェックされ、新しい一意の行のみがファイルに書き込まれます。
参照: クエリの処理順序
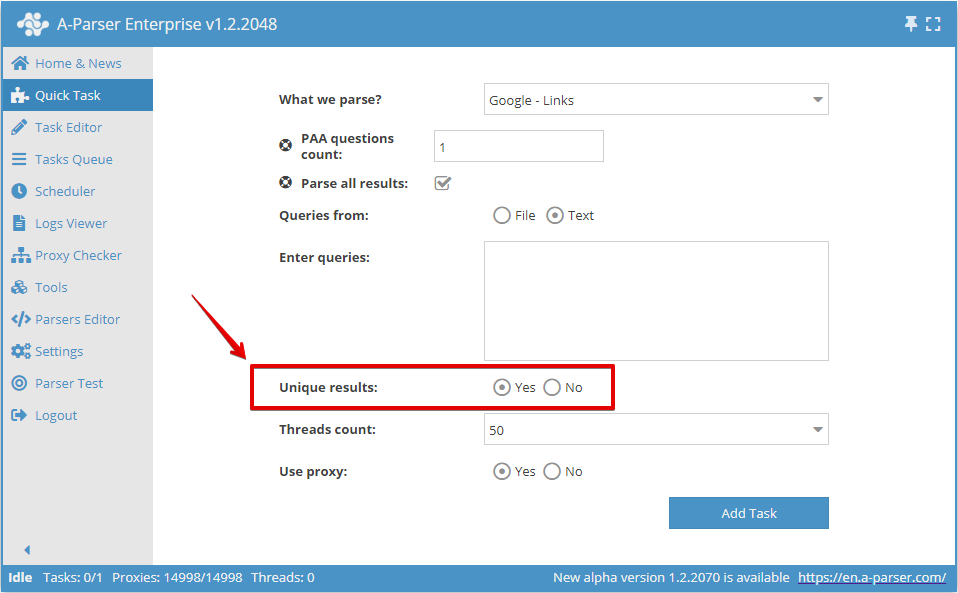
行ごとの重複排除は、クイックタスクで有効にできます:
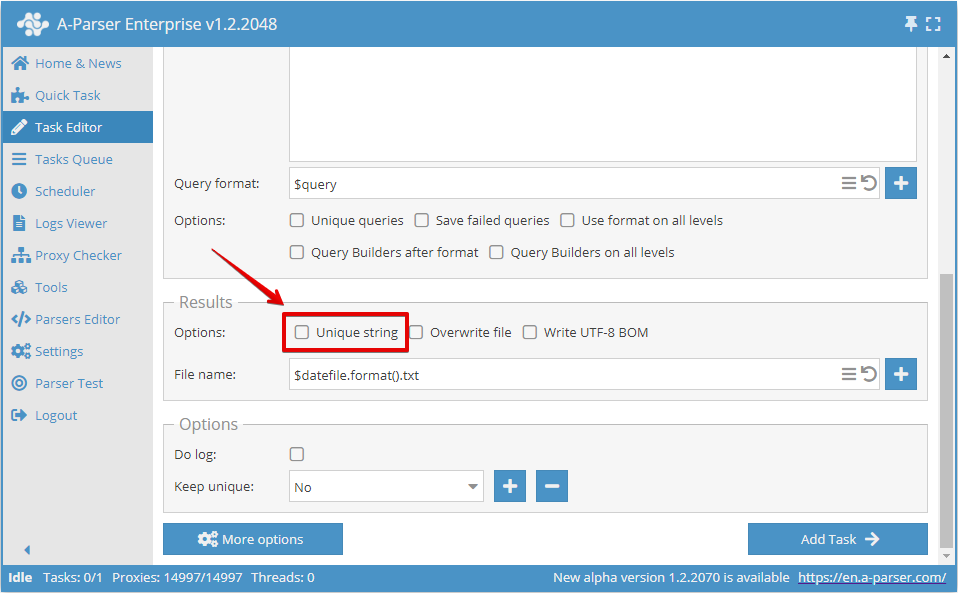
または、タスクエディタで設定します:
任意の結果による重複排除
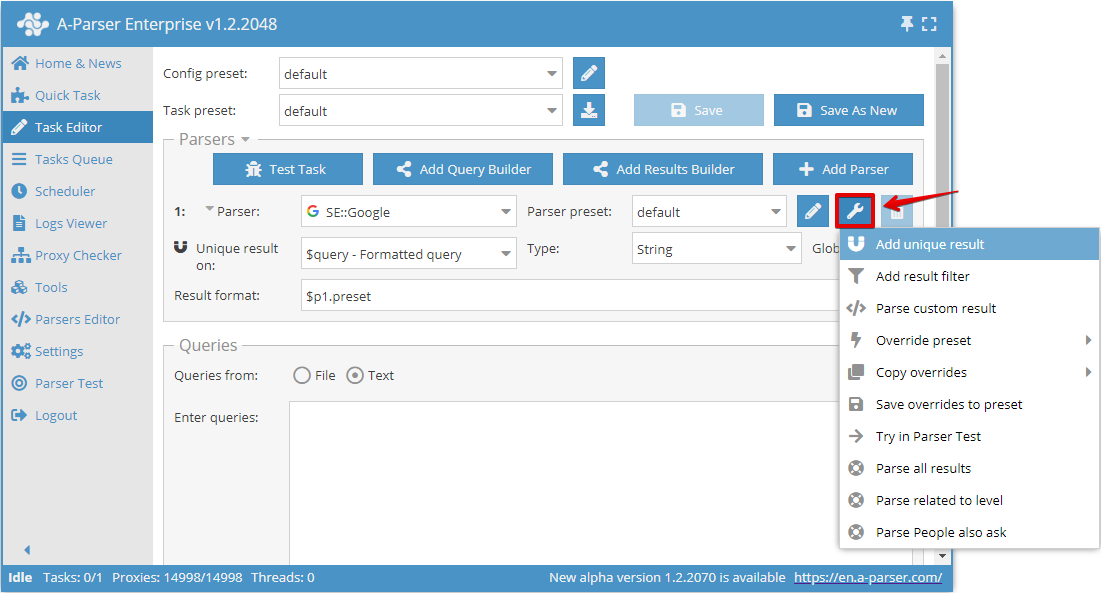
任意の結果による重複排除では、特定のスクレイパーから選択した結果に対して直接重複排除を行うことができます。この重複排除タイプを追加するには、タスクエディタでスクレイパーの右側にあるツールアイコンをクリックし、Add unique result (重複排除を追加)を選択します:
これで、どの結果に対して重複排除を行うかと、重複排除タイプを選択できます:
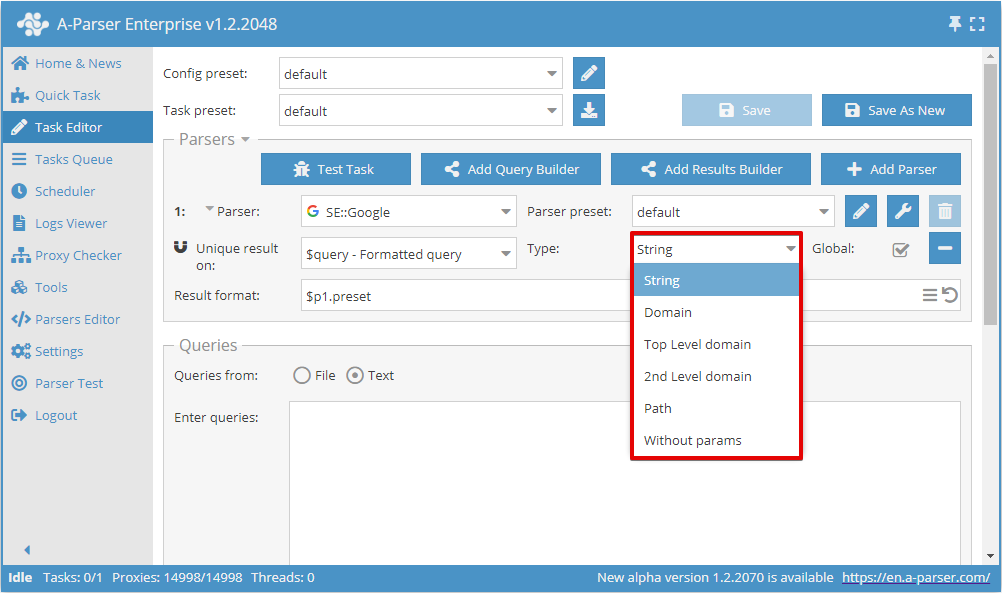
Global (グローバル)スイッチは、2つ以上のスクレイパーが選択されている場合に使用されます。これは、共通の重複排除を行うか、各スクレイパーごとに個別に行うかを決定します。
重複排除タイプ
| パラメーター | 説明 |
|---|---|
| String | 行ごとの重複排除(結果の行全体が比較されます) |
| Domain | ドメインによる重複排除(ドメイン全体が比較されます。例えば、www.domain.com と domain.com は異なるドメインとして扱われます) |
| Top Level domain | 地域、商用、教育などのドメインを考慮したメインドメインによる重複排除(例えば、domain.co.uk と domain2.co.uk は異なるドメインですが、sub1.domain.com と sub2.domain.com は同じドメインとして扱われます) |
| 第2レベルドメイン | 第2レベルドメインによる重複排除(第2レベルドメインが比較されます。例えば、www.domain.com、domain.com、user.subdomain.domain.com はすべて同じドメインとして扱われます) |
| Path | パスによる重複排除(ファイルまでのリンク部分が比較されます。例えば、http://domain.com/path1/file.php と http://domain.com/path1/file2.php は、ファイルまでのリンク部分が同じとみなされます) |
| Without params | パラメータなしのリンクによる重複排除(パラメータを除いたリンクが比較されます。例えば、http://domain.com/file.php?page=1 と http://domain.com/file.php?page=2 は同じリンクとして扱われます) |
クエリ重複排除
クエリ重複排除は、現在のタスクでまだスクレイピングされていない一意のクエリのみを直接スクレイピングに送信します。主なユースケースは以下の通りです:
- 元のクエリに重複があり、それらをスクレイピングしたくない場合(二度手間の防止)
- Parse to level (指定レベルまでスクレイピング)オプションを使用する場合、クエリの増殖やループを防ぐために、一意のクエリのみを使用する必要があります(例:スクレイパー
 HTML::LinkExtractor を使用する場合)。
HTML::LinkExtractor を使用する場合)。
それ以外のケースで不要にクエリ重複排除を使用すると、スクレイパーの全体的な動作が遅くなるだけです。
タスク間での重複排除状態の保存
重複排除データベースを保存して将来のタスクで使用することができます。これにより、新しいタスクで新しい一意の結果のみを保存することが可能になります(例: SE::Google での検索結果スクレイピング時のリンクなど)。
SE::Google での検索結果スクレイピング時のリンクなど)。
重複排除データベースを保存するには、最初のタスクを追加する際に新しいデータベース名を作成する必要があります:
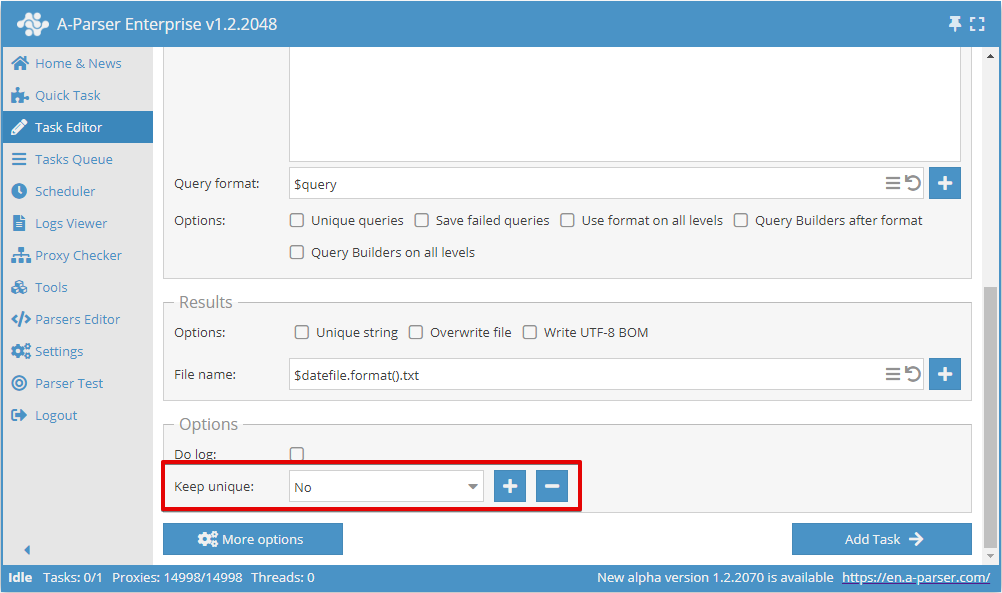
それ以降のすべてのタスクでは、以前に作成したデータベース名を選択する必要があります。これにより、結果が最初のタスクと同じファイルに書き込まれるか、新しいファイルに書き込まれるかに関係なく、新しい一意の結果のみが保存されます。