Używanie wyrażeń regularnych
Informacje ogólne
W A-Parser stosowane są wyrażenia regularne kompatybilne z Perl/JavaScript, które można wykorzystać:
- Podczas scrapowania dowolnych informacji z dowolnych stron
- W kreatorze zapytań do wyodrębniania lub zamiany części zapytania
- W kreatorze wyników do przekształcania dowolnych wyników
- Przy użyciu filtrów
- W kreatorze wyrażeń regularnych
- Podczas sprawdzania dostępności następnej strony w scraperze
 Net::HTTP
Net::HTTP
Szczegółową dokumentację dotyczącą wyrażeń regularnych można znaleźć w następujących źródłach:
- Wyrażenia regularne na Wikipedii
- Uniwersalna encyklopedia wyrażeń regularnych standardu PCRE
- Temat Dzielimy się regexami na forum
W A-Parser istnieje możliwość przetwarzania dowolnego wyniku za pomocą wyrażenia regularnego, w tym celu używana jest opcja Parse custom results (Użyj regexa):
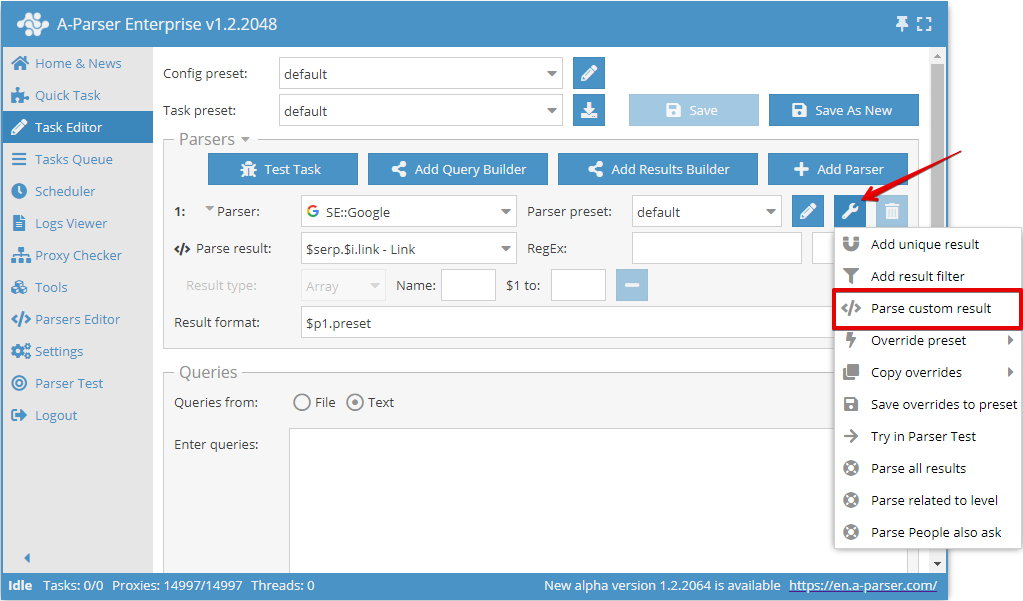
Cechy użytkowania i flagi
- Wyrażenia regularne zapisuje się bez ograniczników
// - Obsługiwane są następujące flagi:
- i - wyszukiwanie bez uwzględniania wielkości liter
- s - kropka obejmuje wszystkie znaki, w tym znaki nowej linii
- g - wyszukiwanie globalne lub zamiana
Dodatkowo można podać flagę w samym regexie, na przykład wyszukiwanie słowa test w każdej linii całego tekstu (lub kodu strony, zależnie od tego, do czego stosuje się regex) z użyciem flagi m (multi line - symbole ^ i $ działają odpowiednio jako początek i koniec wiersza):
(?m)^(.+?test.+?)$
Wyodrębnianie dowolnych informacji
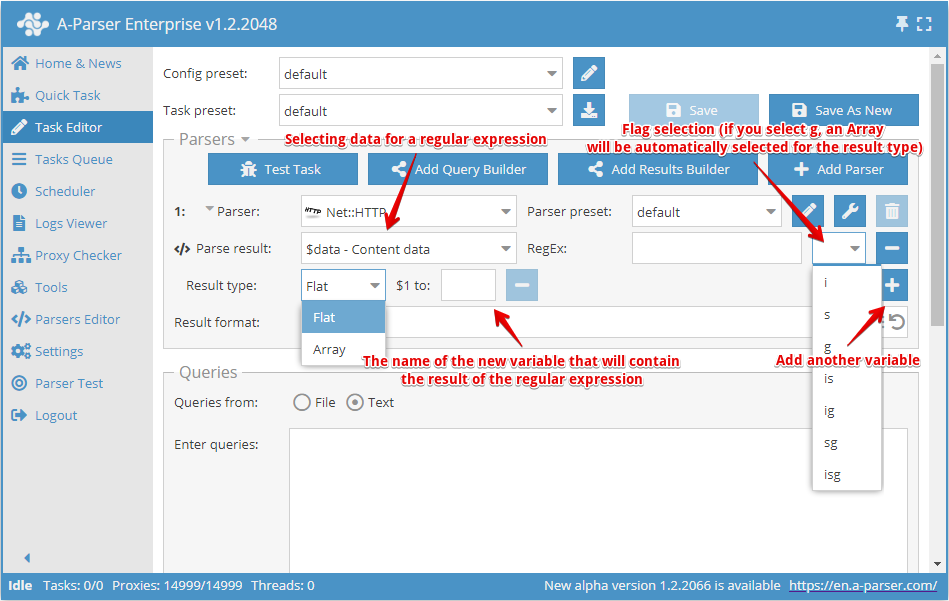
Za pomocą opcji Parse custom results (Użyj regexa) lub Konstruktora wyników możliwe jest użycie wyrażeń regularnych do wyodrębniania dowolnych informacji z wyników scrapowania, na przykład z kodu źródłowego stron HTML lub z już przygotowanych wyników
- Jako Parse result (Zastosuj do) wybierany jest wynik ze scrapera, może to być prosty wynik lub tablica
- Wyrażenie regularne podaje się bez ograniczników, następnie istnieje możliwość wskazania flagi
- W Result type (Typie wyniku) określa się typ wyniku -
Flat(prosty wynik) lubArray(tablica). Jeśli jako wynik źródłowy wybrano tablicę albo użyto flagi g wyrażenia regularnego, wynik zawsze będzie zapisywany do tablicy. W polu Name (Nazwa) wpisuje się nazwę tablicy - Każdy nawias przechwytujący wyrażenia regularnego może zostać zapisany jako oddzielny element, nazwa elementu jest wpisywana w odpowiednie pole $1 to, $2 to... - gdzie cyfra oznacza numer nawiasu przechwytującego
- W polu RegEx (Regex) można używać silnika szablonów, co pozwala na użycie zapytania jako części wyrażenia regularnego
Utworzone nowe wyniki można wykorzystać przy formatowaniu wyników, w konstruktorze wyników, w filtrowaniu i usuwaniu duplikatów wyników lub w kolejnej opcji Parse custom results (Użyj regexa).
Ta opcja jest podobna do konstruktora wyników przy użyciu RegEx Match
Przykład scrapowania linków do obrazków z kodu źródłowego HTML
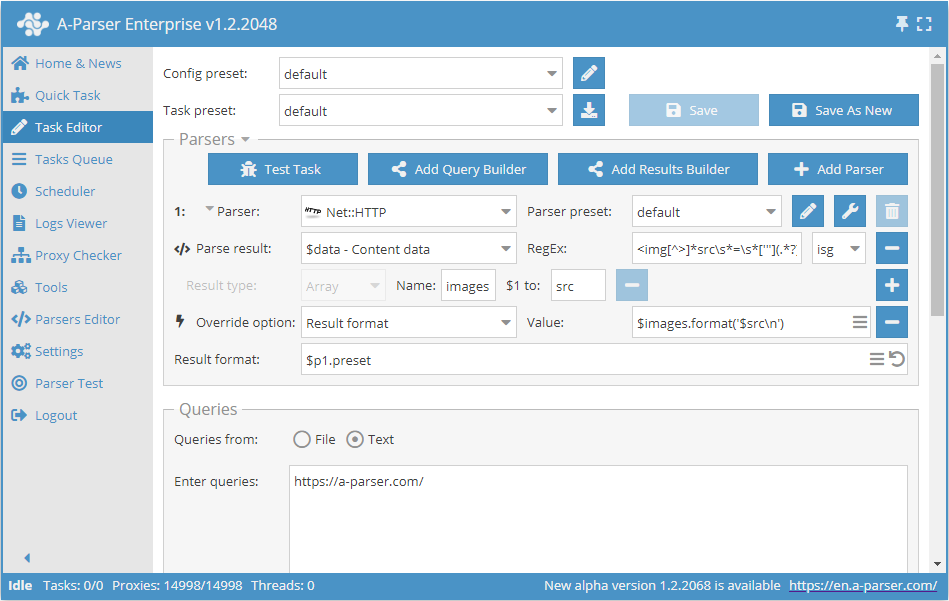
Aby rozwiązać to zadanie, używamy scrapera Net::HTTP do pobrania kodu źródłowego strony.
Stosujemy do $data (pobrana strona) wyrażenie regularne z flagami isg, a wynik zapisujemy do elementów src tablicy images.
W formacie wyniku wskazujemy wyświetlanie wszystkich elementów src przez znak nowej linii.
W wyniku scrapowania dla zapytania http://a-parser.com/ w pliku wynikowym otrzymamy następującą listę:
/img/lang/en.png
/img/lang/ru.png
img/[email protected]
https://files.a-parser.com/img/site/tour_ru/V1qpV.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_1_all_parsers_list.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_1_quick_task.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_2_task_editor_easy.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_3_task_editor_analyze_domains.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_4_task_editor_parse_emails.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_5_queue_fast_google.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_6_queue_spyserp.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_7_javascript_parser.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_8_scheduler.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_9_settings.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_10_proxies.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_11_templates.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_12_task_tester.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_13_parser_test.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_14_api.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_15_resources.png
data/avatars/s/0/12.jpg?1507557563
data/avatars/s/0/12.jpg?1507557563
data/avatars/s/13/13392.jpg?1570706020
data/avatars/s/16/16560.jpg?1586782475
data/avatars/s/1/1240.jpg?1537376153
styles/uix/xenforo/avatars/avatar_s.png
data/avatars/s/0/371.jpg?1412969226
styles/uix/xenforo/avatars/avatar_s.png
//mc.yandex.ru/watch/26891250
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJxtVN9v2jAQ/l8sJArqYH3YS7Stokhomxgwmj5BJlnkyLz612yHFUX533d2Egfa
vYDv7rvvvvNdXBFH7bPdGLDgLEl2FdHhTBKSw5GW3JFboqmxYHx4R1bgkuRLmm7Q
HxEVcWcNmHMorVNiC7ZJNM0BuaijwS7gBc2PTBS7n5+zsTWH/d6OP/mf3XBPspvJ
+H4UTh08bZiZLSJh66LG0DM6w/+KigATtAAbkV4zwSIkq3uR6gTGsBwQxXK0j8oI
6kwn+kR56WGDhmvShG+GgyBWDkekzrJYYBGiHq7vJu3dxeAjPUGqfAnGoXcv0Gr1
DvBmwEe7MqOJe/EMNM+ZY0pS3lTwnfRVnyT7E0RKhVg8GgZ2YZRAl4NA4J3nTt2O
DIJNkKIMuT+aHJIcKbdwSyxKXVAUkr+OMAeGOmXW2utBf0WUnHG+hBPwHhb4H0rG
c1yV2RGTvraJ/4es33DUsb3LUjisvwY1RJZgPay/91m5WqqiuwzOBHNo27kqpR/M
e3Q+A+h4ZysPE8pALNMyt9Xxa9Ag/Wb0I5vp3nXVxtVYrp0HJY+sWLfb1iFLmeIn
t5ZzJTQH35csOcexWNj26zGz7Ri80Qt8nTwPJa4+VqcUt98eG6naMFy/D16gwJu8
rNpSHijnT9vlZYT0K4XGL+e0TaZT+q55BiYHJabEJzooFK4UtlVn8ZGIT0l18VQk
VY1j+m03Dcb35BHow8uxOAOS3NX/AFJvlP8=
Konstruktor wyrażeń regularnych
Począwszy od wersji 1.2.78 dodano Konstruktor wyrażeń regularnych.
Można go znaleźć w zakładce Tools -> Regex Builder. Można również wysyłać otrzymany kod stron bezpośrednio w Scrapowaniu testowym. W tym celu należy włączyć tryb debug i kliknąć link Go to RegEx Builder.
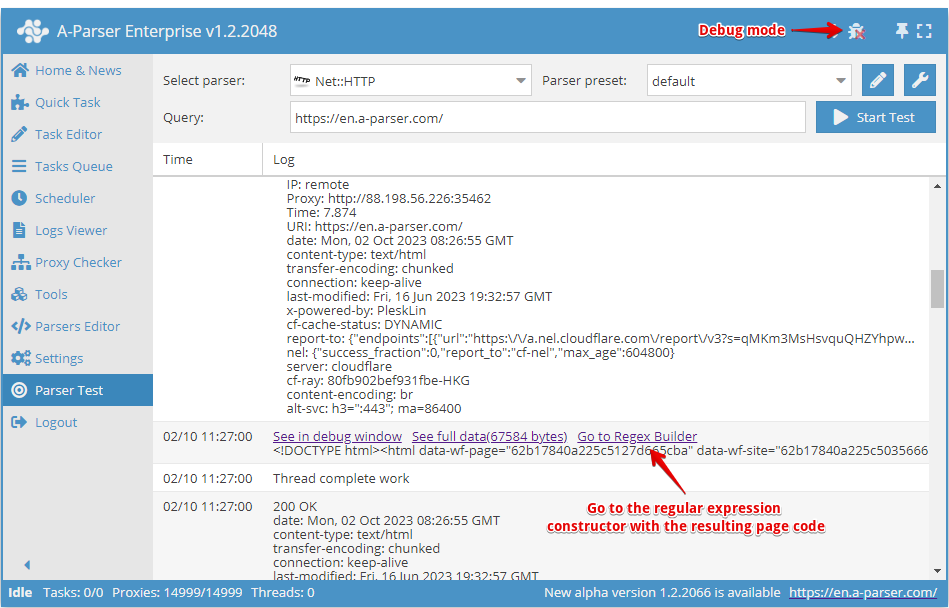
W konstruktorze istnieje możliwość wyboru języka programowania, w którym będą używane uzyskane wyrażenia regularne.
Aby pracować z konstruktorem, należy w pole po lewej stronie wkleić tekst źródłowy (lub zostanie on wklejony automatycznie ze Scrapowania testowego po przejściu przez Go to Regex Builder). Po prawej stronie konfigurujemy parametry przyszłego wyrażenia regularnego.
Do stworzenia prostego wyrażenia regularnego (na przykład w celu pobrania tytułu) wystarczy wskazać potrzebne elementy wyrażenia regularnego.
- W polu Before group (Przed grupą) wpisujemy znaki, które znajdują się przed informacją, której potrzebujemy
- W polu After group (Po grupie) wpisujemy znaki, które znajdują się po potrzebnych danych
- W polu Grupa zaczyna się od wskazujemy znaki, od których powinien zaczynać się szukany ciąg
- W polu Group ends with (Grupa kończy się na) wskazujemy znaki, które powinny znajdować się na końcu szukanego ciągu
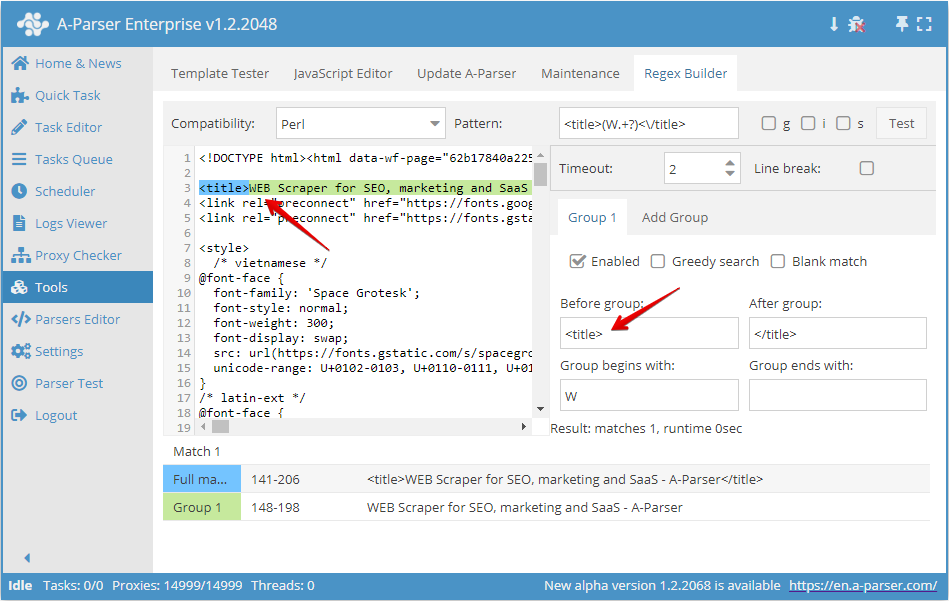
Jak widać na zrzucie ekranu powyżej, tworzymy wyrażenie regularne, które będzie wybierać tytuł strony. Przed grupą umieścimy <title>, a po grupie </title>, a także dla przykładu wskażemy, że szukany ciąg zaczyna się na literę W.
Do pełnego przetestowania uzyskanego wyrażenia regularnego istnieje możliwość włączenia potrzebnych flag: g, s i i.
Można również tworzyć bardziej złożone wyrażenia regularne, w których występują 2 lub więcej grup.
Dla przykładu spróbujemy zbudować wyrażenie regularne do zebrania wszystkich linków i anchorów na liście <li>. W tym celu musimy włączyć flagę g i dodać jeszcze jedną grupę wyszukiwania, ponieważ w pierwszej grupie będą linki, a w drugiej anchory.
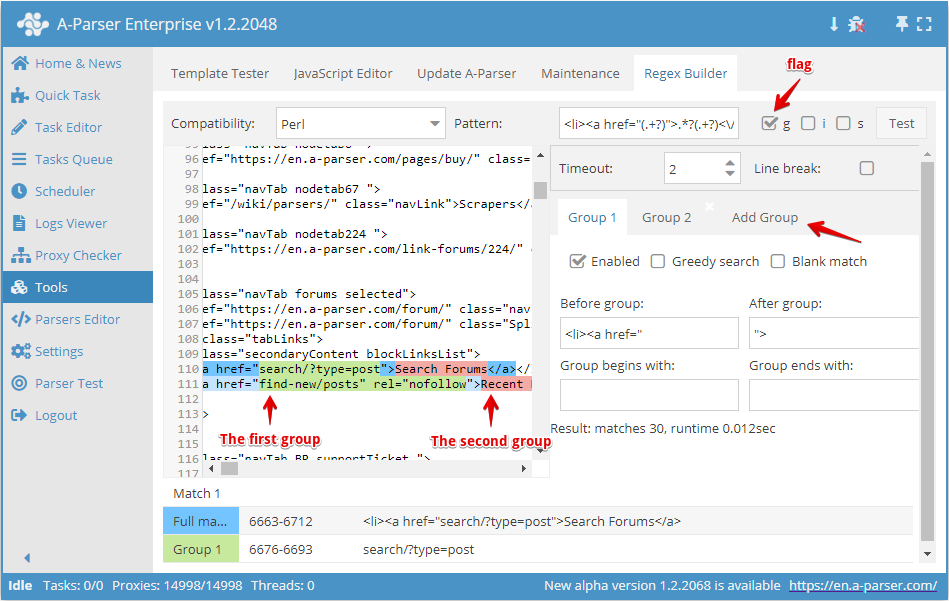
Po ustawieniu odpowiednich parametrów dla obu grup otrzymujemy wyrażenie regularne:
<li><a href="(.+?)">(.+?)<\/a
Aby sprawdzić wyrażenie regularne, naciśnij przycisk Test:
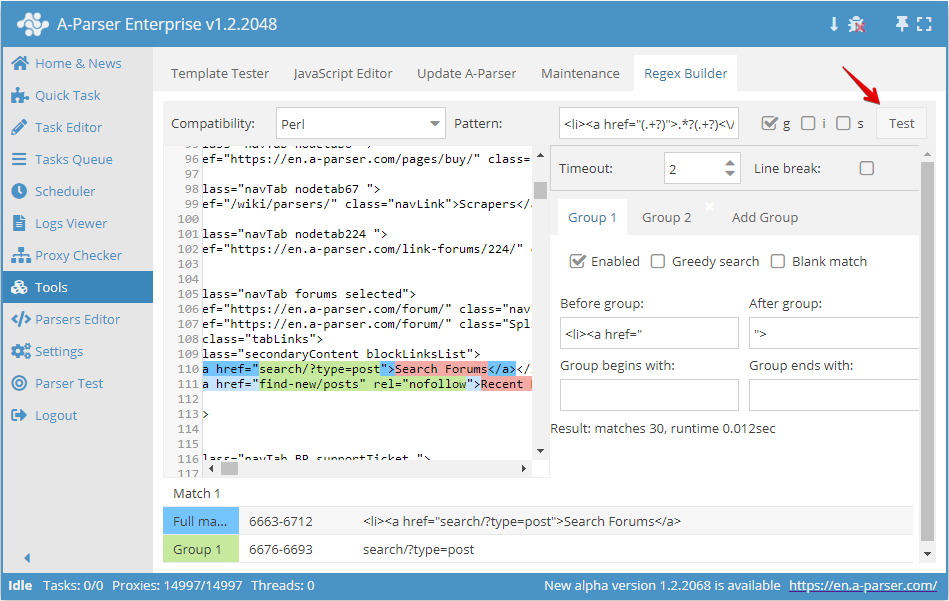
Po wykonaniu wyrażenia regularnego na dole wyświetlany jest wynik jego działania: pełny ciąg i przechwycone grupy. Po dwukrotnym kliknięciu na dowolny element w tabeli wyników, tekst początkowy przewija się do miejsca znalezienia danego dopasowania.
Przydatne linki
🔗 Wyrażenia regularne dla najmłodszych
Nazywam się Vitaliy Kotov i wiem nieco o wyrażeniach regularnych. Poniżej opowiem o podstawach pracy z nimi...
🔗 Wyrażenia regularne (regexp) — podstawy
Wyrażenia regularne to mechanizm do wyszukiwania i zamiany tekstu. W ciągu, pliku, wielu plikach...
🔗 ⏩Scrapujemy katalog urządzeń przemysłowych
Przykład użycia regexów w scrapowaniu katalogu urządzeń przemysłowych
🔗 ⏩Scrapowanie zasobu Booking.com
Przykład użycia regexów w scrapowaniu zasobu Booking.com
🔗 ⏩Wyszukiwanie stron kontaktowych
Przykład użycia regexów w scrapowaniu stron kontaktowych