Kolejność przetwarzania zapytań
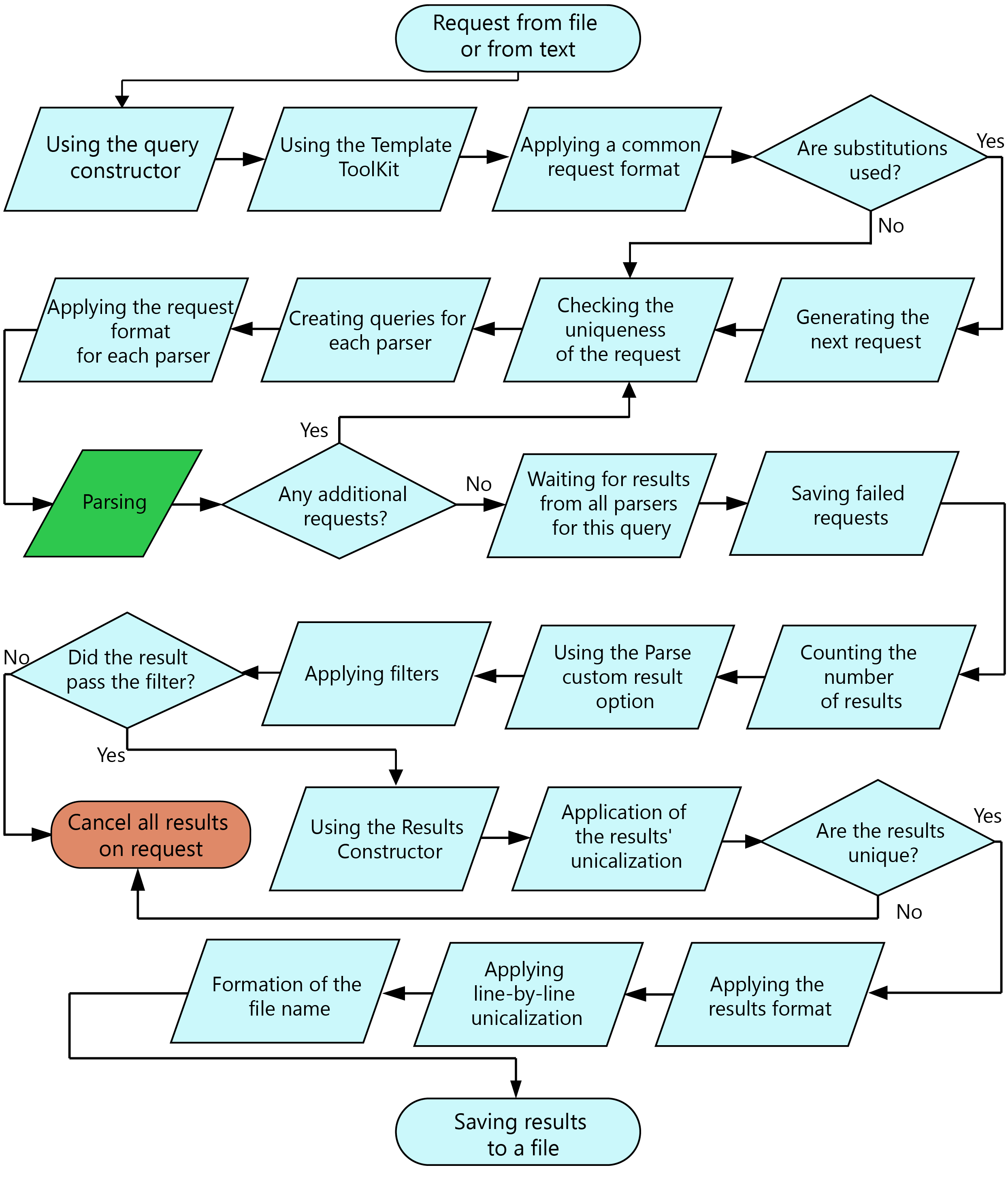
W A-Parser istnieje wiele funkcji i możliwości, na poniższym schemacie przedstawiono kolejność przetwarzania zapytania od jego odczytu z pliku (lub tekstu) do zapisania końcowego wyniku do pliku
Schemat kolejności przetwarzania zapytania
Uwagi
- Podczas filtrowania i usuwania duplikatów wyników zapytanie i jego wyniki są odrzucane w całości, jeśli jako porównanie wykorzystywany jest prosty wynik, jeśli w porównaniu wykorzystywana jest tablica, usuwane są elementy z tej tablicy
- Wiele kroków na schemacie jest opcjonalnych i zależy od ustawień określonych w Edytorze zadań
- Dodatkowe zapytania mogą pojawiać się przy użyciu opcji Parse all result oraz Parse to level. Wszystkie dodatkowe zapytania mają kolejny poziom w stosunku do zapytania, z którego zostały utworzone, odliczanie poziomów zaczyna się od zera, tzn. pierwotne zapytania z pliku lub tekstu zawsze mają poziom 0. Zapytania po zastosowaniu podstawień również mają poziom 0
Nieudane zapytania
Zapytanie jest uważane za nieudane i zostaje pominięte, jeśli nie udało się go wykonać w określonej liczbie prób.
Jak określić, dlaczego zapytanie jest nieudane? Włącz prowadzenie logu lub uruchom Test zadania. Wszystkie błędy są logowane. Analizując log, będziesz mógł zrozumieć, co poszło nie tak.
Przykład nieudanego zapytania. Logi podpowiadają, że zapytania nie udało się wykonać z powodu captcha, a próby się skończyły. W takim przypadku może pomóc podłączenie serwisu rozwiązywania lub zwiększenie liczby prób (tylko jeśli scrapujesz z proxy, w innym przypadku zwiększanie prób jest bezcelowe).
Jak zwiększyć liczbę prób? Należy nadpisać opcję Request retries i ustawić większą wartość.