Usuwanie duplikatów wyników
Usuwanie duplikatów, deduplikacja, usuwanie powtórek - wszystko to oznacza, że nie potrzebujemy powtarzających się wyników. W A-Parser istnieją 2 metody usuwania duplikatów, omówmy szczegółowo każdą z nich.
Usuwanie duplikatów wyników według wiersza
Ta metoda działa po sformatowaniu wyniku, bezpośrednio przed zapisaniem wyniku do pliku każdy wiersz jest sprawdzany pod kątem unikalności i w pliku zapisywane są tylko nowe unikalne wiersze.
Zobacz także: Kolejność przetwarzania zapytań
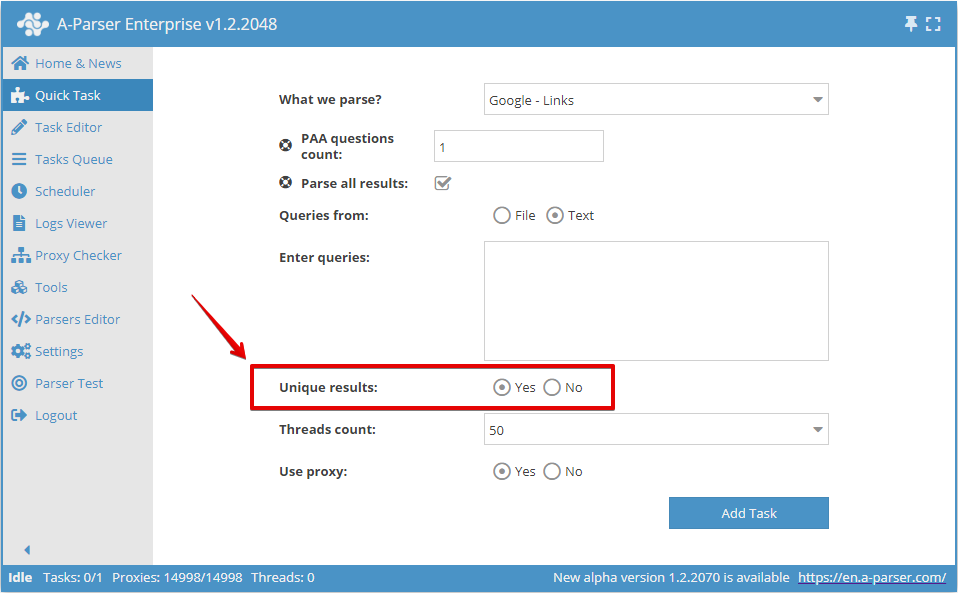
Włączyć unikalność według wiersza można w Szybkim zadaniu:
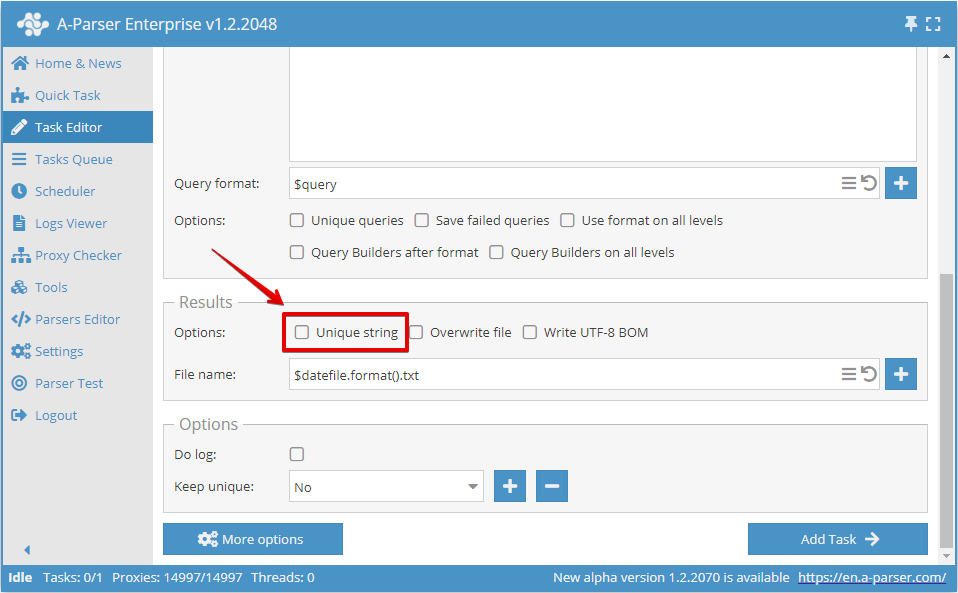
Lub w Edytorze zadań:
Usuwanie duplikatów według dowolnego wyniku
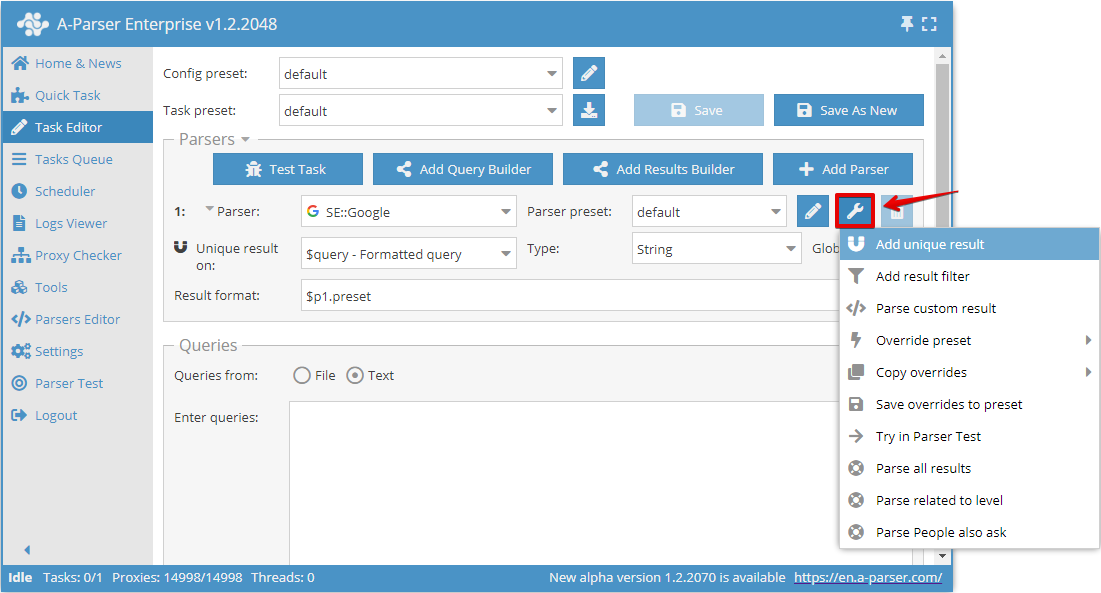
Usuwanie duplikatów według dowolnego wyniku pozwala na usuwanie duplikatów bezpośrednio na wybranym wyniku z konkretnego scrapera. Można dodać ten typ usuwania duplikatów w Edytorze zadań, klikając ikonę narzędzia po prawej stronie scrapera i wybierając Add unique result (Dodaj usuwanie duplikatów):
Teraz można wybrać, na którym wyniku przeprowadzić usuwanie duplikatów oraz typ usuwania duplikatów:
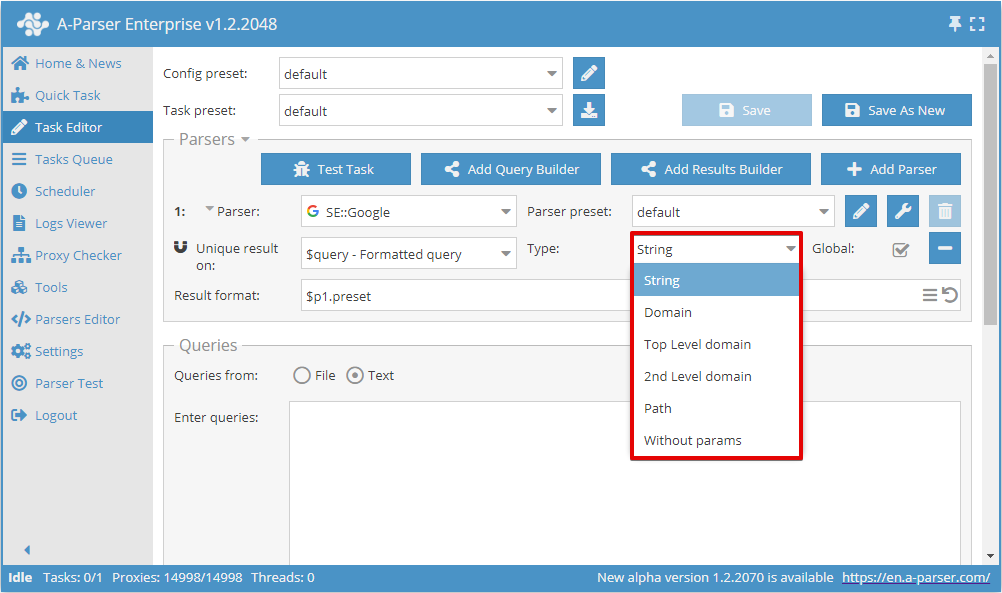
Przełącznik Global (Globalnie) jest używany, gdy wybrano 2 lub więcej scrapery; określa on, czy stosować wspólne usuwanie duplikatów, czy oddzielnie dla każdego scrapera.
Typy usuwania duplikatów
| Parametr | Opis |
|---|---|
| String | Usuwanie duplikatów według wiersza (porównywany jest cały wiersz wyniku) |
| Domain | Usuwanie duplikatów według domeny (porównywana jest cała domena, np. www.domain.com i domain.com to różne domeny) |
| Top Level domain | Usuwanie duplikatów według głównej domeny z uwzględnieniem domen regionalnych, komercyjnych, edukacyjnych i innych (np. domain.co.uk i domain2.co.uk to różne domeny, a sub1.domain.com i sub2.domain.com - takie same) |
| Domena 2-go poziomu | Usuwanie duplikatów według domeny drugiego poziomu (porównywane są domeny drugiego poziomu, np. www.domain.com, domain.com i user.subdomain.domain.com to ta sama domena) |
| Path | Usuwanie duplikatów według ścieżki (porównywane są części linku do pliku, np. http://domain.com/path1/file.php i http://domain.com/path1/file2.php - takie same części linku do pliku) |
| Without params | Usuwanie duplikatów według linku bez parametrów (porównywane są linki bez parametrów, np. http://domain.com/file.php?page=1 i http://domain.com/file.php?page=2 - takie same linki) |
Usuwanie duplikatów zapytań
Usuwanie duplikatów zapytań wysyła bezpośrednio do scrapowania tylko unikalne zapytania, które nie zostały wcześniej przescrapowane w bieżącym zadaniu. Główne przypadki użycia:
- Jeśli w zapytaniach źródłowych są duplikaty i niepożądane jest ich scrapowanie (podwójna praca)
- Przy użyciu opcji Parse to level (Parsuj do poziomu) konieczne jest używanie wyłącznie unikalnych zapytań, aby zapobiec rozrastaniu się i zapętlaniu zapytań (na przykład przy użyciu scrapera
 HTML::LinkExtractor)
HTML::LinkExtractor)
We wszystkich innych przypadkach niepotrzebne użycie usuwania duplikatów zapytań jedynie spowolni ogólną pracę scrapera
Zapisywanie stanu usuwania duplikatów między zadaniami
Istnieje możliwość zapisywania bazy usuwania duplikatów do wykorzystania w przyszłych zadaniach, co pozwala w nowych zadaniach zapisywać tylko nowe unikalne wyniki (na przykład linki podczas scrapowania SERP w  SE::Google)
SE::Google)
Aby zapisać bazę usuwania duplikatów, należy przy dodawaniu pierwszego zadania utworzyć nową nazwę bazy:
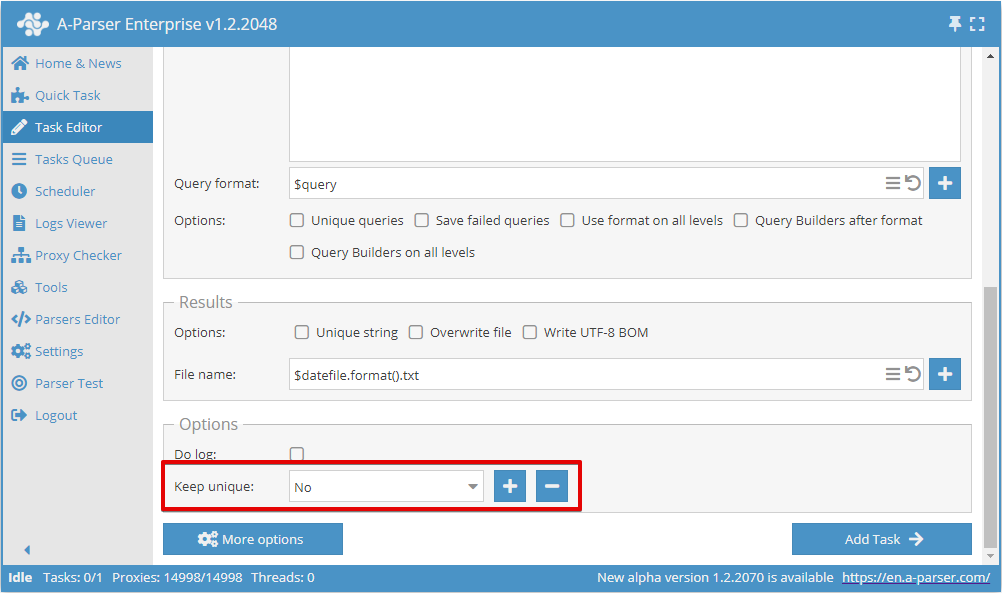
Dla wszystkich kolejnych zadań należy wybierać wcześniej utworzoną nazwę bazy, dzięki czemu zapisywane będą tylko nowe unikalne wyniki, niezależnie od tego, czy wyniki są zapisywane do tego samego pliku co w pierwszym zadaniu, czy do nowego pliku.