Net::HTTP - Uniwersalny bazowy scraper z obsługą wielostronicowego scrapowania i omijaniem CloudFlare
Przegląd scrapera
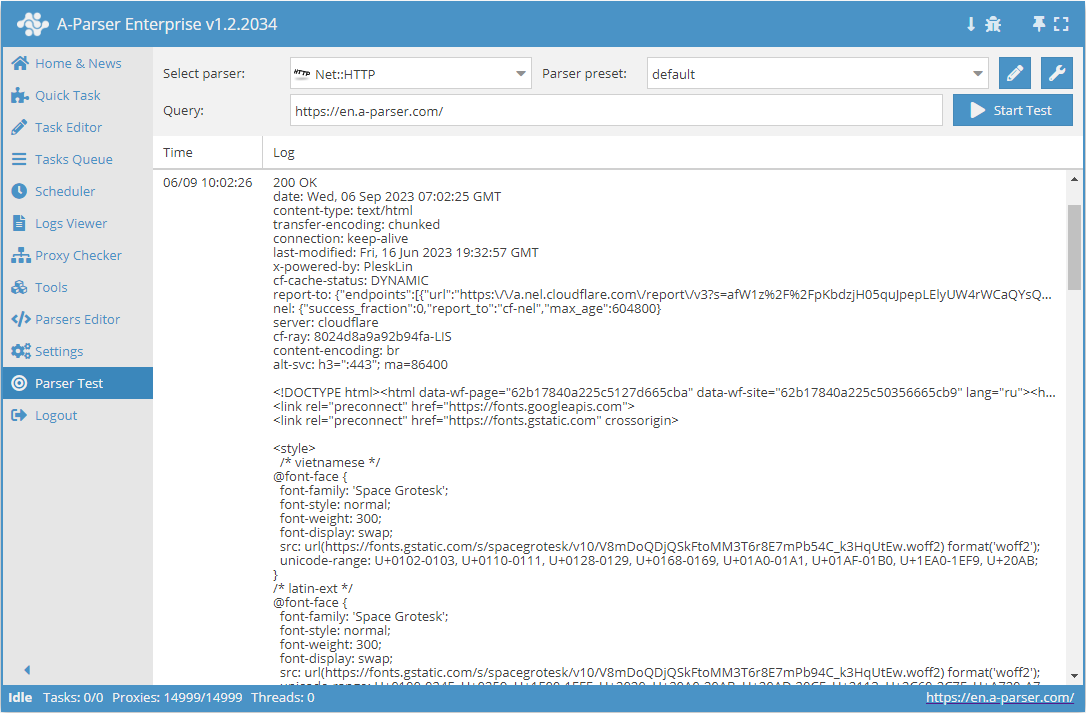
 Net::HTTP – to uniwersalny scraper, który pozwala rozwiązywać większość niestandardowych zadań. Może być używany jako podstawa do scrapowania dowolnej treści z dowolnych witryn. Pozwala pobrać kod strony za pomocą linku, obsługuje scrapowanie wielostronicowe (przechodzenie po stronach), automatyczną pracę z proxy, pozwala na sprawdzenie pomyślnej odpowiedzi według kodu lub zawartości strony.
Net::HTTP – to uniwersalny scraper, który pozwala rozwiązywać większość niestandardowych zadań. Może być używany jako podstawa do scrapowania dowolnej treści z dowolnych witryn. Pozwala pobrać kod strony za pomocą linku, obsługuje scrapowanie wielostronicowe (przechodzenie po stronach), automatyczną pracę z proxy, pozwala na sprawdzenie pomyślnej odpowiedzi według kodu lub zawartości strony.Przypadki użycia scrapera
🔗 Aukcja domen REG.RU
Scrapowanie aukcji zwalnianych domen z możliwością filtrowania
🔗 Dane certyfikatu SSL
Scrapowanie danych certyfikatu SSL domen z serwisu leaderssl.ru
🔗 Scrapowanie serwisu Booking.com
Pobieranie wyników wyszukiwania mieszkań i hoteli w serwisie
🔗 Zbieranie charakterystyk produktu
Przykład scrapowania nieznanej liczby charakterystyk produktu
🔗 Scrapowanie bazy filmów z IMDB
Pobiera dane o każdym filmie i zapisuje je do wyniku
🔗 Sprawdzanie obecności HTTPS
Preset sprawdza obecność HTTPS na stronie
Gromadzone dane
- Treść
- Kod odpowiedzi serwera
- Opis odpowiedzi serwera
- Nagłówki odpowiedzi serwera
- Proxy użyte podczas zapytania
- Tablica ze wszystkimi zebranymi stronami (używana przy włączonej opcji Use Pages)
Funkcje
- Scrapowanie wielostronicowe (przechodzenie po stronach)
- Automatyczna obsługa proxy
- Sprawdzanie poprawnej odpowiedzi na podstawie kodu lub zawartości strony
- Obsługa kompresji gzip/deflate/brotli
- Wykrywanie i konwersja kodowania stron na UTF-8
- Omijanie ochrony CloudFlare
- Wybór silnika (HTTP lub Chrome)
- Opcja Check content – wykonuje określone wyrażenie regularne na pobranej stronie. Jeśli wyrażenie nie zostanie dopasowane, strona zostanie załadowana ponownie z innego proxy.
- Opcja Use Pages – pozwala na przejrzenie określonej liczby stron z zadanym krokiem. Zmienna
$pagenumzawiera bieżący numer strony podczas iteracji. - Opcja Check next page – należy podać wyrażenie regularne, które wyodrębni link do następnej strony (zazwyczaj przycisk "Dalej"), jeśli istnieje. Przejście między stronami odbywa się w ramach określonego limitu (0 - bez ograniczeń).
- Opcja Page as new query – przejście do następnej strony odbywa się w nowym zapytaniu. Pozwala to usunąć ograniczenie liczby stron do przejścia.
Warianty użycia
- Pobieranie treści
- Pobieranie obrazów
- Sprawdzanie kodu odpowiedzi serwera
- Sprawdzanie obecności HTTPS
- Sprawdzanie obecności przekierowań
- Wyświetlanie listy adresów URL przekierowań
- Pobieranie rozmiaru strony
- Zbieranie meta-tagów
- Wyodrębnianie danych z kodu źródłowego strony i/lub nagłówków
Zapytania
Jako zapytania należy podawać linki do stron, na przykład:
http://lenta.ru/
http://a-parser.com/pages/reviews/
Przykłady formatowania wyników
A-Parser obsługuje elastyczne formatowanie wyników dzięki wbudowanemu silnikowi szablonów Template Toolkit, co pozwala na wyprowadzanie wyników w dowolnej formie, a także w formie strukturalnej, np. CSV lub JSON
Wyświetlanie treści
Format wyniku:
$data
Przykład wyniku:
<!DOCTYPE html><html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<!-- Google Tag Manager -->
<!-- End Google Tag Manager -->
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<base href="https://a-parser.com/" />
<title>A-Parser - scraper dla profesjonalistów SEO</title>
<noscript><style>.JsOnly, .jsOnly { display: none !important; }</style></noscript>
<link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" />
Kod odpowiedzi serwera
Format wyniku:
$code
Przykład wyniku:
200
Format wyniku [% response.Redirects.0.Status || code %] pozwala wyświetlić status 301, jeśli w zapytaniu występują przekierowania.
Pobieranie danych o zapytaniu
Zmienna $response pomaga uzyskać informacje o zapytaniu i odpowiedzi serwera
Format wyniku:
$response.json\n
Przykład wyniku:
{
"Time": 3.414,
"connection": "keep-alive",
"Decode": "Decode from utf-8(meta charset)",
"cache-control": "max-age=3600,public",
"last-modified": "Tue, 18 May 2021 12:42:56 GMT",
"transfer-encoding": "chunked",
"date": "Thu, 27 May 2021 14:18:42 GMT",
"Status": 200,
"content-encoding": "gzip",
"Body-Length-Decoded": 1507378,
"Reason": "OK",
"Proxy": "http://51.255.55.144:25302",
"content-type": "text/html",
"Redirects": [],
"server": "nginx",
"Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n",
"URI": "https://a-parser.com/",
"HTTPVersion": "1.1",
"Body-Length": 299312,
"Decode-Mode": "auto-html",
"etag": "W/\"60a3b650-170032\"",
"Decode-Time": 0.003,
"IP": "remote",
"expires": "Thu, 27 May 2021 15:18:42 GMT"
}
Pobieranie przekierowań
Zapytanie:
https://google.it
Format wyniku:
$response.Redirects.0.URI -> $response.URI
Przykład wyniku:
https://google.it/ -> https://www.google.it/
JSON z przekierowaniami
Format wyniku:
$response.Redirects.json
Przykład wyniku:
[{"x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n"}]
Wyświetlanie statusu odpowiedzi serwera
Format wyniku:
$reason
Przykład wyniku:
OK
Czas odpowiedzi serwera
Format wyniku:
$response.Time
Przykład wyniku:
1.457
Pobieranie rozmiaru strony
Jako przykład rozmiar przedstawiono w trzech różnych wariantach.
Format wyniku:
[% "data-length: " _ data.length _ "\n";
"Body-Length: " _ response.${'Body-Length'} _ "\n";
"Body-Length-Decoded: " _ response.${'Body-Length-Decoded'} _ "\n" %]
Przykład wyniku:
data-length: 70257
Body-Length: 23167
Body-Length-Decoded: 75868
Przetwarzanie wyników
A-Parser pozwala przetwarzać wyniki bezpośrednio podczas scrapowania, w tej sekcji przedstawiliśmy najpopularniejsze przypadki dla scrapera Net::HTTP
Wyświetlanie nagłówków H1-H6
Dodać wyrażenie regularne (opcja Parse custom results (Użyj wyrażenia regularnego)) <(h\d+)[^>]+>(.+?)<\/h\d+>, w polu "Parse result" wybrać $pages.$i.data - Page content, w polu obok wyrażenia regularnego wybrać modyfikatory sg. Jako typ wyniku zostanie automatycznie wybrana tablica. W polu "Name" wpisać headers, (dalej "następnie") w "$1 to" wpisać tag, kliknąć na

content. W ogólnym formacie wyniku wpisać wyjście $p1.headers.format('$tag - $content\n').Pobierz przykład
Jak zaimportować przykład do A-Parser
eJxtVNuO2jAQ/RVkIS2IW3loH6IVFYuK2ooSlmWfIJUsMgR3HTu1HboI8e+dcUIC
tE+Jj+ccn7nYJ+a4fbMLAxacZcH6xDL/zwI2BxcEX1erRWOrpYStEypp7Ie9/SfW
ZRk3Fgwx1nUg4jHseC4d656YO2aAMtvcOp0uwXqYmeInWKNEApYo3HEW0U4C70h4
bO03m7jTXv8cRZ1Rq9/53H7cbAYeHLEyblWI26SSLBFuDD8i6L9znhK2Bx6T2Uso
2cbEibvVyoFyLDpHUbU91SblVIJmNuyX5P7Og62HJhIbvUazZG426qFdK7/wA6w0
UndCQg1PcVWaaWK+QLsXxXbfvVNleBwLJ7TisjifXNaeXpX4nRNfaYzFXyPATo1O
EXLgBQg8XryvWdOvqbK55z4XHBbsuLTQZRatTjkaie93hAPDnTZhRn4QPzGtxlLO
4ACyDvP6T7mQVJ/xDknfSuL/Q8J/NM5VetdHHcD8MeihUvGrp/BHzYr1TCeXYkiR
CodrO9G5orZ9QPANIKtqNqewVBuojimVy9Nx/jNQMUbWLRtnNXSTxk1bbkGciZ1I
QkzAiBgukbla4SUL1USnmQTKS+VSYlssLOvxGNuyDbSoDd6TJ/4ItFXdNOa0lvb7
S2E1MwLH7yMZTLGS16eWklsu5etydr1DRLylWai+GHPXPj8YbO9cZoPBgPeKm9/f
6nRA9weHOdE4ZpjqOarehepBOV29DsHpjK37ZRdFDOVJEYhhwSz2hQXD81+VjpX2
Zbieranie meta-tagów
Dodać wyrażenie regularne (opcja Parse custom results (Użyj wyrażenia regularnego)) (<meta[^>]+>), w polu "Parse result" wybrać $pages.$i.data - Page content, w polu obok wyrażenia regularnego wybrać modyfikator g. Jako typ wyniku zostanie automatycznie wybrana tablica. W polu "Name" wpisać meta, w "$1 to" wpisać item. W Formacie wyniku użyć $p1.meta.format('$item\n').
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB
bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj
3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm
Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z
Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL
SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9
iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK
zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY
rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF
Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY
i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1
gDE=
Warianty przechodzenia przez paginację
Użycie Use pages
Use pages. Funkcja ta pozwala przechodzić przez paginację, podając z góry znaną liczbę stron.
Jako przykład weźmy jedną z kategorii na stronie katalogu produktów https://www.proball.ru/catalog/myachi/. Na górze i na dole widzimy panel paginacji. Po kliknięciu w ikony z numerami stron można zobaczyć w pasku przeglądarki, jak przekazywany jest parametr z numerem strony na końcu zapytania:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
Use pages to rodzaj licznika, który faktycznie podstawia do zmiennej $pagenum kolejne numery, zwiększając je o wartość, którą podamy
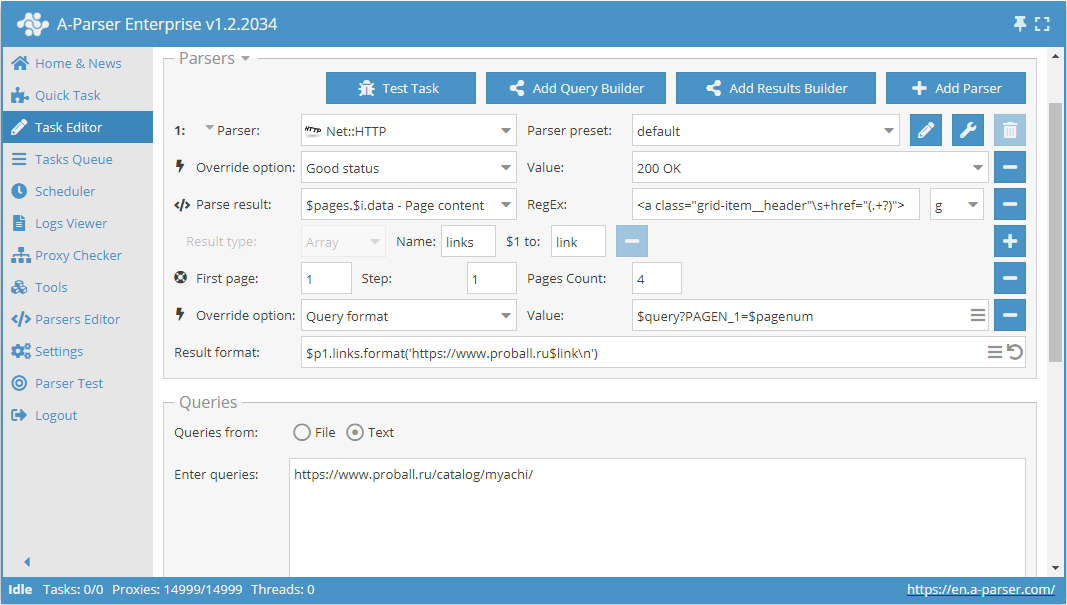
Jak widać na zrzucie ekranu, w formacie zapytania scrapera w odpowiednim miejscu używana jest zmienna $pagenum.
Funkcja Use pages przeiteruje i podstawi do zapytania wszystkie wartości, faktycznie będziemy otrzymywać linki do zapytania
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum
gdzie zamiast zmiennej $pagenum zostanie podstawiony numer strony, zaczynając od 1 do 4 z krokiem 1.
W ten sposób uzyskuje się przejście przez strony z danego zakresu. Na tym polega ograniczenie tej metody - trzeba z góry znać liczbę stron znajdujących się w paginacji. Oczywiście przy jednoczesnym scrapowaniu kilku kategorii liczba stron wszędzie będzie inna i jako wyjście możemy po prostu podać większą liczbę przewidywanych stron. Nie jest to jednak do końca poprawne, dlatego istnieje bardziej optymalne rozwiązanie, o którym mowa poniżej
Pobierz przykład
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2
pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn
PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0
9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+
1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh
9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob
jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4
YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5
QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u
kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp
sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9
P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8
z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M
vOJ4VZ5BGJXHUBcgGBZ/AXULzRU=
Użycie Check next page
Check next page to kolejna funkcja pozwalająca zorganizować przejście przez paginację. Specyfika jej użycia polega na tym, że aby przejść do następnej strony, należy użyć wyrażenia regularnego, które zwróci link do następnej strony. Jest to wygodniejszy i najczęściej stosowany sposób. Jednak nie uda się go zastosować dla https://www.proball.ru/catalog/myachi/, ponieważ w kodzie nie ma linków do następnych stron. Linki są tam generowane przez skrypt. Dlatego jako przykład weźmy stronę http://www.imdb.com/search/name?gender=female. Tutaj paginacja występuje zarówno na początku, jak i na końcu listy. Po przeanalizowaniu kodu źródłowego można zauważyć obecność linku pozwalającego przejść do następnej strony:
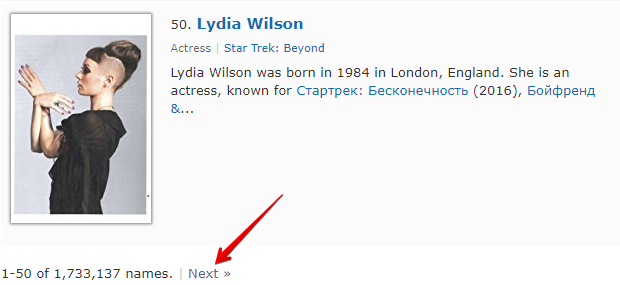
- w polu Next page RegEx wpiszemy wyrażenie regularne
- w polu Limit podamy liczbę stron, które należy przejść
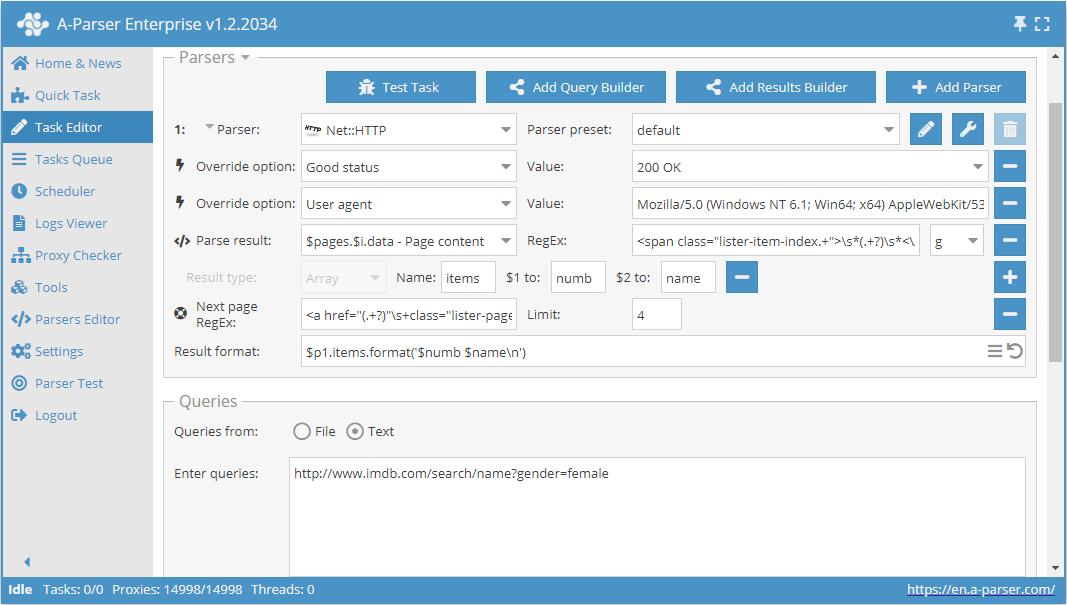
W przykładzie podano 4. Podając limit, określamy, ile stron scraper ma przejść. W naszym przypadku zostanie przejrzanych 5 stron, ponieważ odliczanie zaczyna się od 0. Jeśli podamy limit 0, scraper będzie pracował do momentu, aż przejdzie wszystkie strony, niezależnie od ich liczby. Jest to bardzo wygodne, gdy trzeba zebrać wszystkie wyniki ze wszystkich stron
Pobierz przykład
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS
sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr
gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp
ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I
22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY
FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI
HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu
NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O
MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7
exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x
+JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L
itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy
KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18
bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq
iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU
tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY
11r9ASIaBUM=
Jak wspomniano wyżej, istnieje możliwość dynamicznego ograniczania liczby stron w Use pages. W tym celu należy wspólnie użyć Use pages i Check next page. Uzupełnijmy przykład rozważany przy opisie Use pages i dodajmy do niego funkcję Check next page:
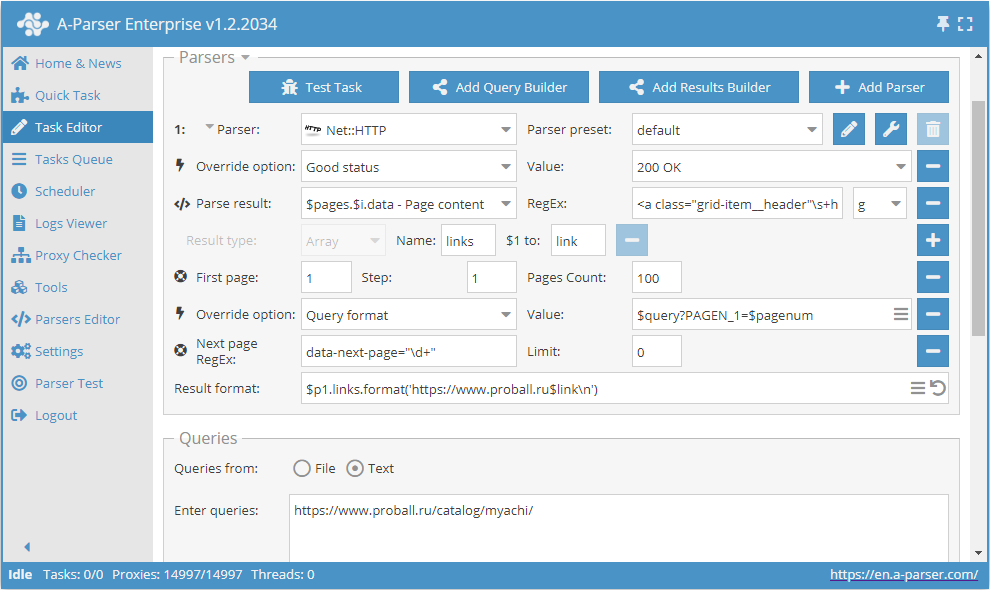
Te dwie funkcje w parze działają następująco: Use pages zapewnia przejście przez strony, a Check next page sprawdza, czy istnieje następna. Gdy tylko Check next page nie znajdzie następnej strony, scrapowanie tej kategorii zostanie zatrzymane, nie czekając na przejście przez całą liczbę podaną w Use pages. Łącząc te funkcje, zwiększamy efektywność pracy scrapera, oszczędzając czas i zasoby
Pobierz przykład
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF
XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG
eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY
LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve
u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals
SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8
Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g
45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa
eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS
mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x
GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ
NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ
EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0
0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g
KP8Byg3yDQ==
Użycie makr podstawień
Makra podstawień pozwalają na realizację sekwencyjnego podstawiania wartości z określonego zakresu
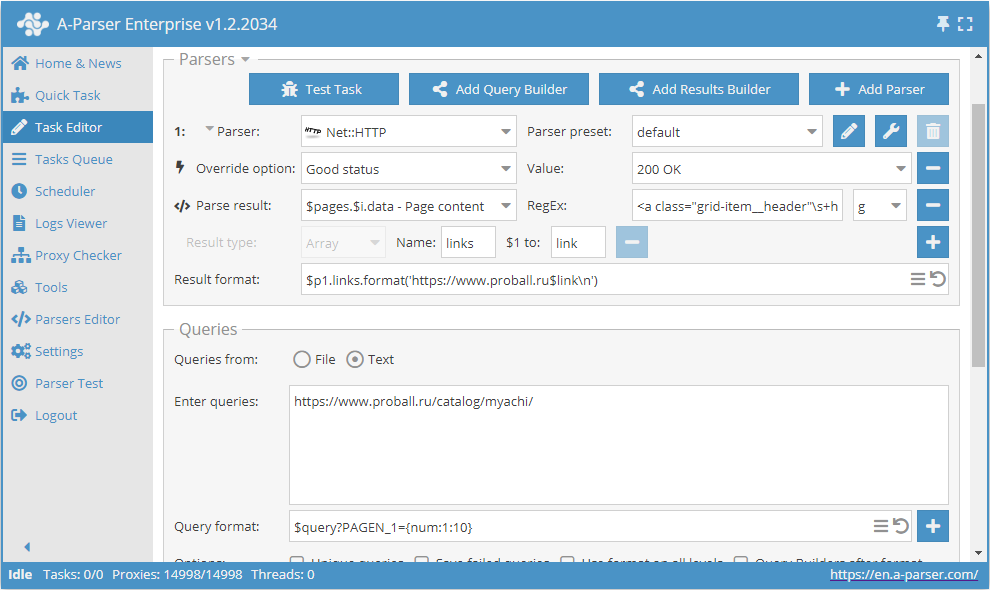
Ten preset będzie działał w następujący sposób. Podając w formacie zapytania szablon:
$query?PAGEN_1={num:1:10}
dodajemy podstawianie wartości od 1 before 10 (zakres można podać dowolny) do samego zapytania. W ten sposób otrzymujemy zapytania zapewniające przejście przez żądaną liczbę stron, typu:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
https://www.proball.ru/catalog/myachi/?PAGEN_1=2
...
https://www.proball.ru/catalog/myachi/?PAGEN_1=10
Użycie makr podstawień do przechodzenia przez paginację jest podobne do funkcji Use pages i ma takie same ograniczenia, czyli trzeba podać konkretny zakres wartości. Zaletą tej metody jest to, że przez makra podstawień można podstawiać różne wartości, zarówno liczbowe, jak i tekstowe, na przykład słowa lub wyrażenia. W ten sposób możemy bardziej elastycznie wstawiać potrzebne części do zapytań lub tworzyć same zapytania z części, które będą znajdować się w różnych plikach, jeśli wymaga tego zadanie
Pobierz przykład
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a
AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix
JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi
Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6
OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ
IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC
4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv
nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk
vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke
AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa
F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q
MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU
1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg==
Użycie Page as query
Aby zmniejszyć zużycie pamięci, logikę można zdefiniować za pomocą opcji Page as query. Po jej aktywacji funkcje Check next page i Use pages będą każdą kolejną stronę podstawiać do zapytań jako osobne, samodzielne zapytanie, nie gromadząc tym samym ich treści w pamięci. Page as query pozwala również określić, czy zwiększać poziom zapytania Increase (podobnie jak działanie narzędzia tools.query.add), czy nie Keep
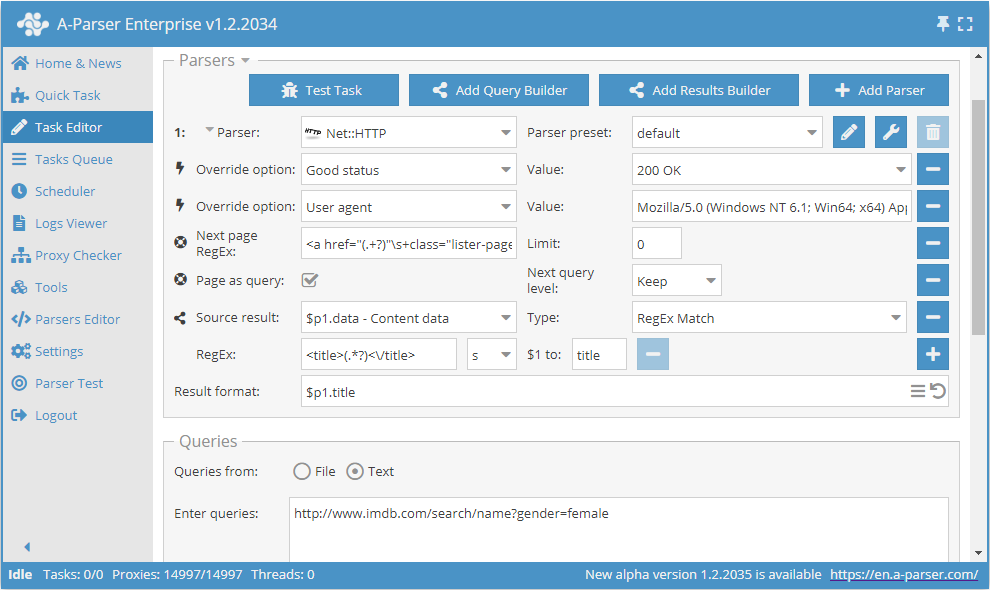
Pobierz przykład
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM
tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA
DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z
ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv
dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i
pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr
mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa
VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1
Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl
CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa
lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0
ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn
5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob
7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD
yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj
geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8=
Możliwe ustawienia
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Good status | All | Wybór, która odpowiedź z serwera będzie uznana za udaną. Jeśli podczas scrapowania wystąpi inna odpowiedź z serwera, zapytanie zostanie powtórzone z innym proxy |
| Good code RegEx | Możliwość podania wyrażenia regularnego do sprawdzenia kodu odpowiedzi | |
| Ban Proxy Code RegEx | Możliwość banowania proxy na czas (Proxy ban time) na podstawie kodu odpowiedzi serwera | |
| Method | GET | Metoda zapytania |
| POST body | Treść do przesłania na serwer przy użyciu metody POST. Obsługuje zmienne $query – URL zapytania, $query.orig – zapytanie źródłowe oraz $pagenum - numer strony przy użyciu opcji Use Pages. | |
| Cookies | Możliwość podania cookies dla zapytania. | |
| User agent | _Automatycznie podstawiany jest user-agent aktualnej wersji Chrome_ | Nagłówek User-Agent przy zapytaniu o strony |
| Additional headers | Możliwość podania dowolnych nagłówków zapytania z obsługą funkcji silnika szablonów i użyciem zmiennych z konstruktora zapytań | |
| Read only headers | ☐ | Czytaj tylko nagłówki. W niektórych przypadkach pozwala zaoszczędzić transfer, jeśli nie ma potrzeby przetwarzania treści |
| Detect charset on content | ☐ | Rozpoznawaj kodowanie na podstawie zawartości strony |
| Emulate browser headers | ☑ | Emuluj nagłówki przeglądarki |
| Max redirects count | 7 | Maksymalna liczba przekierowań, przez które przejdzie scraper |
| Follow common redirects | ☑ | Pozwala na przekierowania http <-> https i www.domain <-> domain w obrębie jednej domeny z pominięciem limitu Max redirects count |
| Max cookies count | 16 | Maksymalna liczba cookies do zapisania |
| Engine | HTTP (Fast, JavaScript Disabled) | Pozwala wybrać silnik HTTP (szybszy, bez JavaScript) lub Chrome (wolniejszy, JavaScript włączony) |
| Chrome Headless | ☐ | Jeśli opcja jest włączona, przeglądarka nie będzie wyświetlana |
| Chrome DevTools | ☐ | Pozwala używać narzędzi do debugowania Chromium |
| Chrome Log Proxy connections | ☐ | Jeśli opcja jest włączona, w logu będą wyświetlane informacje o połączeniach chrome |
| Chrome Wait Until | networkidle2 | Określa, kiedy strona jest uznawana za załadowaną. Więcej o wartościach. |
| Use HTTP/2 transport | ☐ | Określa, czy używać HTTP/2 zamiast HTTP/1.1. Niektóre strony od razu banują przy użyciu HTTP/1.1, a inne wręcz przeciwnie, nie działają przez HTTP/2. |
| Try use HTTP/1.1 for Protocol error | ☑ | Nakazuje scraperowi powtórzyć zapytanie z HTTP/1.1, jeśli włączony był HTTP/2 i wystąpił błąd protokołu (tj. jeśli strona nie działa przez HTTP/2) |
| Don't verify TLS certs | ☐ | Wyłączenie walidacji certyfikatów TLS |
| Randomize TLS Fingerprint | ☐ | Ta opcja pozwala omijać bany stron na podstawie odcisku palca TLS |
| Bypass CloudFlare with Chrome | ☐ | Automatyczne omijanie weryfikacji CloudFlare |
| Bypass CloudFlare with Chrome Max Pages | 20 | Maks. liczba stron przy omijaniu CF przez Chrome |
| Bypass CloudFlare with Chrome Headless | ☑ | Jeśli opcja jest włączona, przeglądarka nie będzie wyświetlana podczas omijania CF przez Chrome |