Användning av reguljära uttryck
Allmän information
I A-Parser används Perl/JavaScript-kompatibla reguljära uttryck som kan användas:
- Vid dataskrapning av godtycklig information från vilka webbplatser som helst
- I frågebyggaren för att extrahera eller ersätta delar av en fråga
- I resultatbyggaren för att transformera alla typer av resultat
- Vid användning av filter
- I konstruktorn för reguljära uttryck
- Vid kontroll av tillgänglighet för nästa sida i scrapern
 Net::HTTP
Net::HTTP
Detaljerad dokumentation om reguljära uttryck finns i följande källor:
- Reguljära uttryck på Wikipedia
- Universell encyklopedi för reguljära uttryck av PCRE-standard
- Tråden Vi delar med oss av regex på forumet
I A-Parser finns möjligheten att bearbeta valfritt resultat med hjälp av ett reguljärt uttryck, för detta används alternativet Parse custom results (Använd regex):
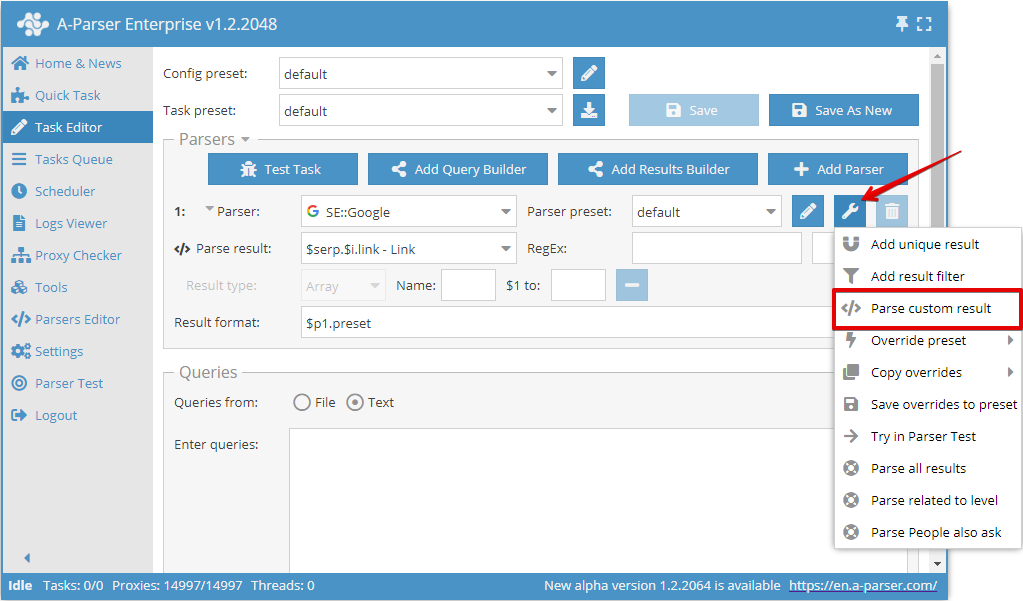
Användning och flaggor
- Reguljära uttryck skrivs utan avgränsare
// - Följande flaggor stöds:
- i - sökning utan skiftlägeskänslighet
- s - punkt inkluderar alla tecken, inklusive radbrytningar
- g - global sökning eller ersättning
Dessutom kan en flagga anges direkt i regexen, till exempel sökning efter ordet test i varje rad i hela texten (eller sidans kod, beroende på vad regexen tillämpas på) med flaggan m (multi line - symbolerna ^ och $ fungerar som början respektive slut på raden):
(?m)^(.+?test.+?)$
Extrahering av godtycklig information
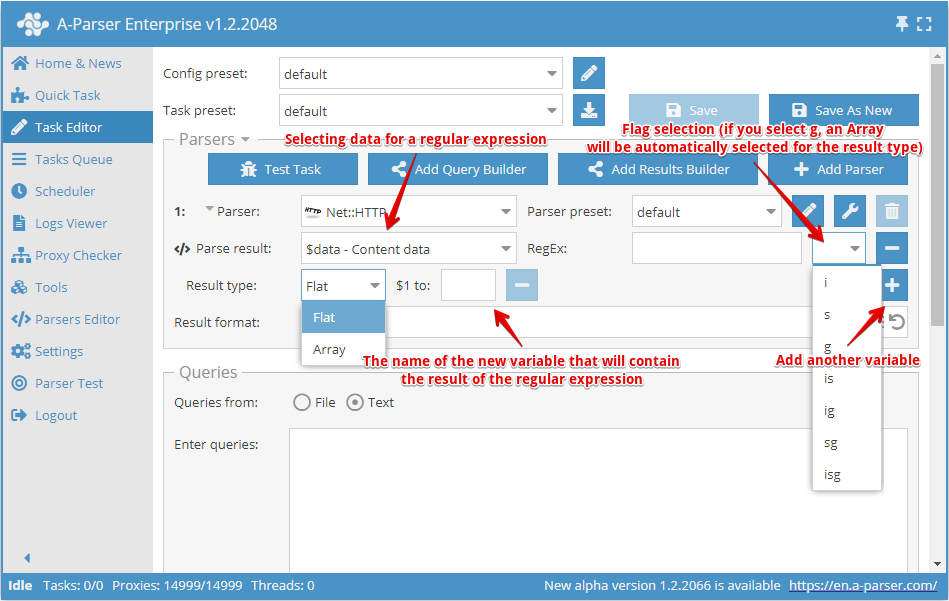
Med hjälp av alternativet Parse custom results (Använd regex) eller Resultatbyggaren är det möjligt att använda reguljära uttryck för att extrahera godtycklig information från resultat av dataskrapning, till exempel från källkoden på HTML-sidor eller från redan förberedda resultat
- Som Parse result (Tillämpa på) väljs resultatet från scrapern, detta kan vara ett enkelt resultat eller en array
- Det reguljära uttrycket anges utan avgränsare, därefter finns möjlighet att ange en flagga
- I Result type (Resultattyp) anges typen för resultatet -
Flat(enkelt resultat) ellerArray(array). Om en array valts som källresultat eller flaggan g i det reguljära uttrycket används, kommer resultatet alltid att sparas i en array. I fältet Name (Namn) anges arrayens namn - Varje fångstgrupp i det reguljära uttrycket kan sparas som ett separat element, elementets namn skrivs i motsvarande fält $1 to, $2 to... - där siffran anger numret på fångstgruppen
- I fältet RegEx (Regex) kan man använda mallmotorn, vilket gör det möjligt att använda frågan som en del av det reguljära uttrycket
De nyskapade resultaten kan användas vid formatering av resultat, i resultatbyggaren, i filtrering och dubblettkontroll av resultat eller i nästa alternativ Parse custom results (Använd regex).
Detta alternativ liknar resultatbyggaren när RegEx Match används
Exempel på dataskrapning av bildlänkar från HTML-källkod
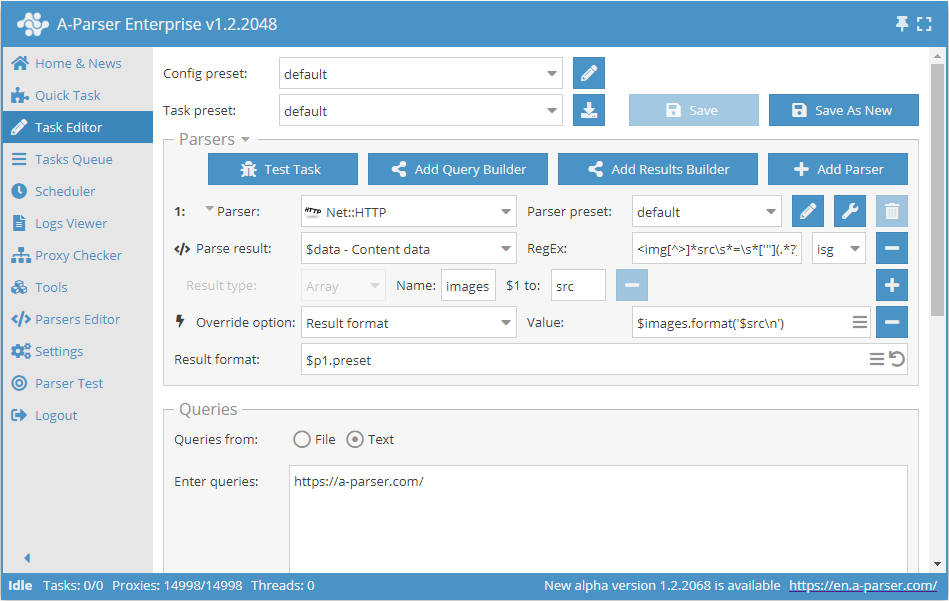
För att lösa denna uppgift använder vi scrapern Net::HTTP för att hämta sidans källkod.
På $data (nedladdad sida) tillämpar vi ett reguljärt uttryck med flaggorna isg, resultatet sparas i elementen src i arrayen images.
I resultatformatet anger vi att alla src-element ska skrivas ut med radbrytning.
Som ett resultat av dataskrapningen för frågan http://a-parser.com/ får vi följande lista i resultatfilen:
/img/lang/en.png
/img/lang/ru.png
img/[email protected]
https://files.a-parser.com/img/site/tour_ru/V1qpV.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_1_all_parsers_list.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_1_quick_task.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_2_task_editor_easy.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_3_task_editor_analyze_domains.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_4_task_editor_parse_emails.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_5_queue_fast_google.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_6_queue_spyserp.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_7_javascript_parser.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_8_scheduler.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_9_settings.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_10_proxies.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_11_templates.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_12_task_tester.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_13_parser_test.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_14_api.png
https://files.a-parser.com/img/site/tour_ru/tour_ru_15_resources.png
data/avatars/s/0/12.jpg?1507557563
data/avatars/s/0/12.jpg?1507557563
data/avatars/s/13/13392.jpg?1570706020
data/avatars/s/16/16560.jpg?1586782475
data/avatars/s/1/1240.jpg?1537376153
styles/uix/xenforo/avatars/avatar_s.png
data/avatars/s/0/371.jpg?1412969226
styles/uix/xenforo/avatars/avatar_s.png
//mc.yandex.ru/watch/26891250
Ladda ner exempel
Hur man importerar ett exempel i A-Parser
eJxtVN9v2jAQ/l8sJArqYH3YS7Stokhomxgwmj5BJlnkyLz612yHFUX533d2Egfa
vYDv7rvvvvNdXBFH7bPdGLDgLEl2FdHhTBKSw5GW3JFboqmxYHx4R1bgkuRLmm7Q
HxEVcWcNmHMorVNiC7ZJNM0BuaijwS7gBc2PTBS7n5+zsTWH/d6OP/mf3XBPspvJ
+H4UTh08bZiZLSJh66LG0DM6w/+KigATtAAbkV4zwSIkq3uR6gTGsBwQxXK0j8oI
6kwn+kR56WGDhmvShG+GgyBWDkekzrJYYBGiHq7vJu3dxeAjPUGqfAnGoXcv0Gr1
DvBmwEe7MqOJe/EMNM+ZY0pS3lTwnfRVnyT7E0RKhVg8GgZ2YZRAl4NA4J3nTt2O
DIJNkKIMuT+aHJIcKbdwSyxKXVAUkr+OMAeGOmXW2utBf0WUnHG+hBPwHhb4H0rG
c1yV2RGTvraJ/4es33DUsb3LUjisvwY1RJZgPay/91m5WqqiuwzOBHNo27kqpR/M
e3Q+A+h4ZysPE8pALNMyt9Xxa9Ag/Wb0I5vp3nXVxtVYrp0HJY+sWLfb1iFLmeIn
t5ZzJTQH35csOcexWNj26zGz7Ri80Qt8nTwPJa4+VqcUt98eG6naMFy/D16gwJu8
rNpSHijnT9vlZYT0K4XGL+e0TaZT+q55BiYHJabEJzooFK4UtlVn8ZGIT0l18VQk
VY1j+m03Dcb35BHow8uxOAOS3NX/AFJvlP8=
Regex-konstruktor
Från och med version 1.2.78 har en Regex-konstruktor lagts till.
Du hittar den under fliken Tools -> Regex Builder. Det går även att skicka den erhållna sidkoden direkt från Test-dataskrapning. För att göra detta måste debug-läge aktiveras och man klickar på länken Go to RegEx Builder.
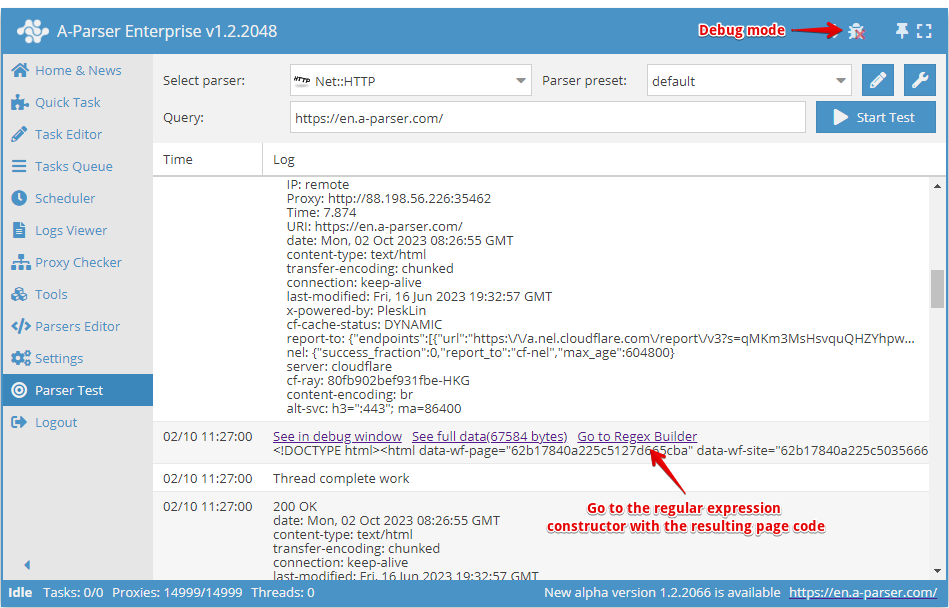
I konstruktorn finns möjlighet att välja programmeringsspråk som de erhållna reguljära uttrycken ska användas i.
För att arbeta med konstruktorn behöver man klistra in källtexten i fältet till vänster (eller så klistras den in automatiskt från Test-dataskrapning vid övergång via Go to Regex Builder). Till höger ställer vi in parametrarna för det framtida reguljära uttrycket.
För att skapa ett enkelt reguljärt uttryck (till exempel för att hämta en titel) räcker det att ange de önskade elementen för det reguljära uttrycket.
- I fältet Before group (Före grupp) skriver vi in de tecken som finns före den information vi behöver
- I fältet After group (Efter grupp) skriver vi in de tecken som finns efter den önskade datan
- I fältet Grupp börjar med anger vi de tecken som den sökta strängen ska börja med
- I fältet Group ends with (Grupp slutar med) anger vi de tecken som ska vara i slutet av den sökta strängen
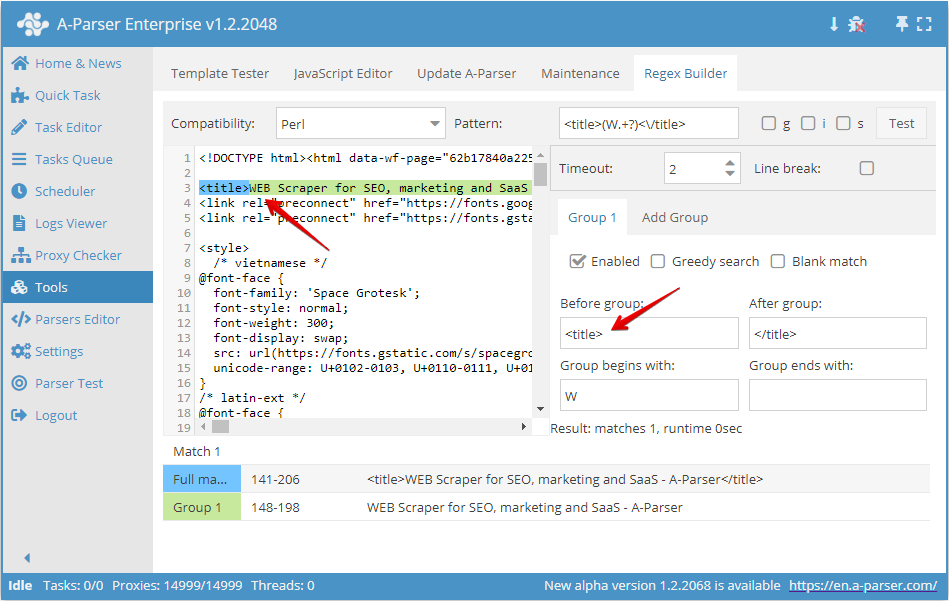
Som framgår av skärmbilden ovan sätter vi ihop ett reguljärt uttryck som kommer att välja webbplatsens titel. Före gruppen sätter vi <title> och efter gruppen </title>, och för exempel anger vi att den sökta strängen börjar med bokstaven W.
För fullständig testning av det erhållna reguljära uttrycket finns möjlighet att aktivera önskade flaggor: g, s och i.
Man kan även skapa mer komplexa reguljära uttryck med 2 eller fler grupper.
Som exempel försöker vi skapa ett reguljärt uttryck för att samla alla länkar och ankartexter i listan <li>. För detta behöver vi aktivera flaggan g och lägga till ytterligare en sökgrupp, eftersom den första gruppen kommer att innehålla länkar och den andra ankartexter.
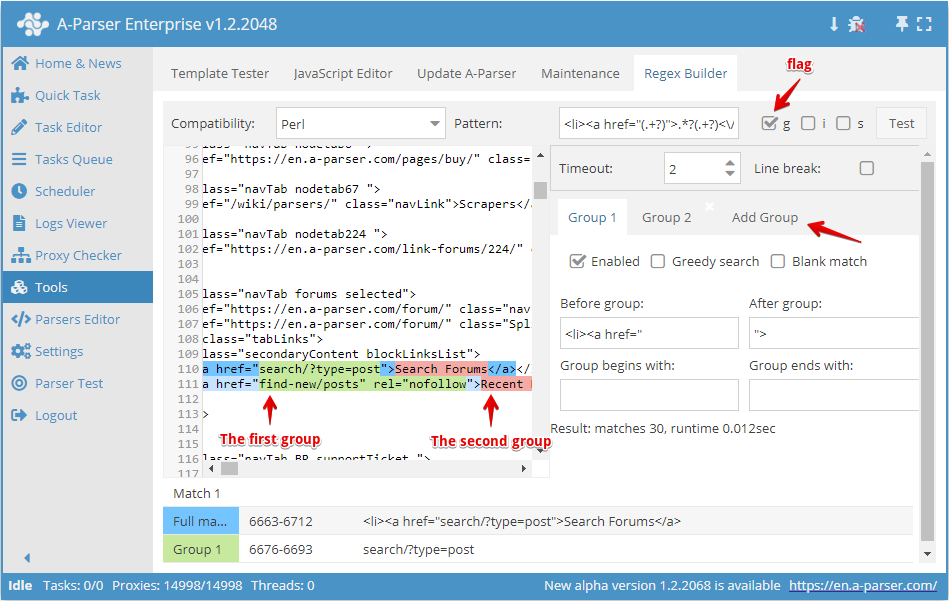
Efter att ha angett önskade parametrar för båda grupperna får vi det reguljära uttrycket:
<li><a href="(.+?)">(.+?)<\/a
För att kontrollera det reguljära uttrycket, tryck på knappen Test:
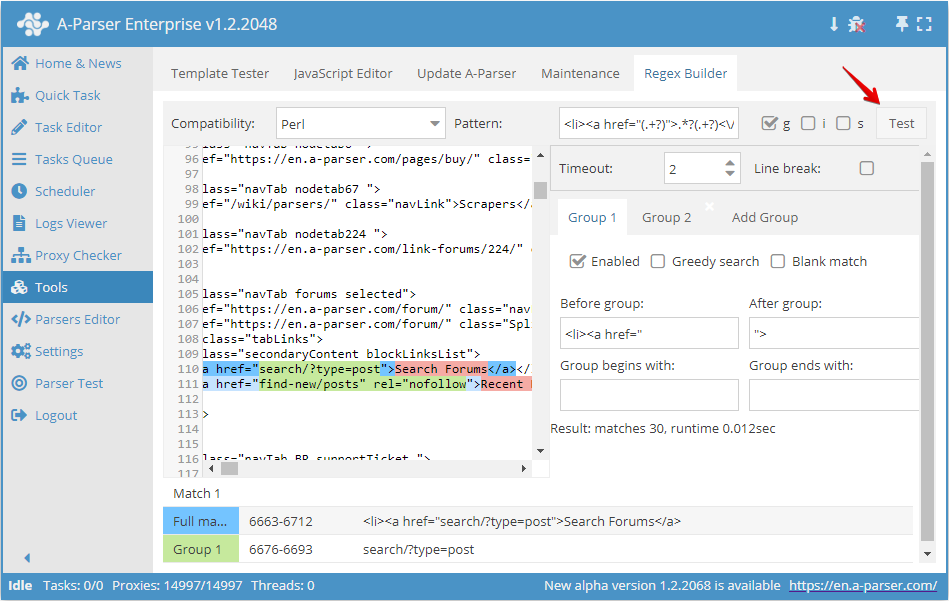
Efter att det reguljära uttrycket har körts visas resultatet av dess arbete längst ner: hela strängen och de fångade grupperna. Vid dubbelklick på valfritt element i resultattabellen scrollas källtexten till platsen för den aktuella matchningen.
Användbara länkar
🔗 Reguljära uttryck för nybörjare
Mitt namn är Vitalij Kotov och jag vet lite om reguljära uttryck. Här kommer jag att berätta om grunderna för att arbeta med dem...
🔗 Reguljära uttryck (regexp) — grunder
Reguljära uttryck är en mekanism för att söka och ersätta text. I en sträng, en fil, flera filer...
🔗 ⏩Vi skrapar en katalog för industriell utrustning
Exempel på användning av regex vid dataskrapning av en katalog för industriell utrustning
🔗 ⏩Dataskrapning av resursen Booking.com
Exempel på användning av regex vid dataskrapning av resursen Booking.com
🔗 ⏩Sökning efter kontaktsidor
Exempel på användning av regex vid dataskrapning av kontaktsidor