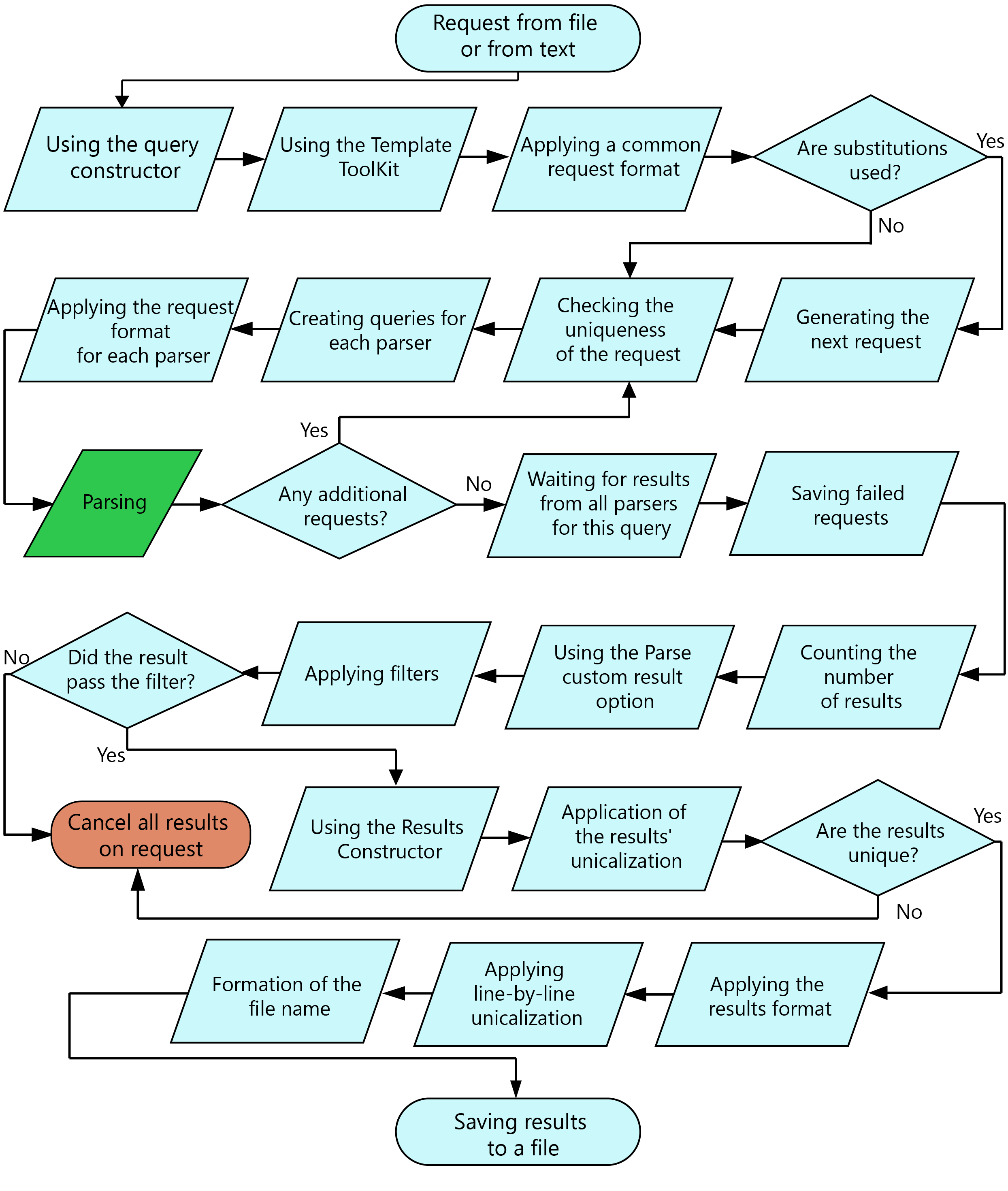
Ordning för bearbetning av frågor
I A-Parser finns det många funktioner och möjligheter. Detta diagram visar ordningen för bearbetning av en förfrågan, från att den läses från en fil (eller text) till att slutresultatet sparas i en fil.
Schematisk ordning för bearbetning av förfrågan
Anmärkningar
- Vid filtrering och dubblettkontroll av resultat avbryts förfrågan och dess resultat i sin helhet om ett enkelt resultat används för jämförelse; om en array används i jämförelsen tas element bort från den arrayen.
- Många steg i diagrammet är valfria och beror på de inställningar som angetts i Task Editor.
- Ytterligare förfrågningar kan uppstå när alternativen Parse all result och Parse to level används. Alla ytterligare förfrågningar har nästa nivå i förhållande till den förfrågan som de skapades ifrån. Nivåräkningen börjar på noll, vilket innebär att de ursprungliga förfrågningarna från filen eller texten alltid har nivå 0. Förfrågningar efter tillämpning av substitutioner har också nivå 0.
Misslyckade förfrågningar
En förfrågan anses vara misslyckad och hoppas över om den inte kunde utföras inom det angivna antalet försök.
Hur avgör man varför en förfrågan misslyckades? Aktivera loggning eller kör ett Task Test. Alla fel loggas. Genom att studera loggen kan du förstå vad som gick fel.
Exempel på en misslyckad förfrågan. Loggarna antyder att förfrågan inte kunde utföras på grund av captcha, och försöken tog slut. I detta fall kan det hjälpa att ansluta en tjänst för captcha-lösning eller öka antalet försök (endast om du skrapar med proxy, annars är det meningslöst att öka antalet försök).
Hur ökar man antalet försök? Du behöver skriva över inställningen Request retries och ange ett högre värde.