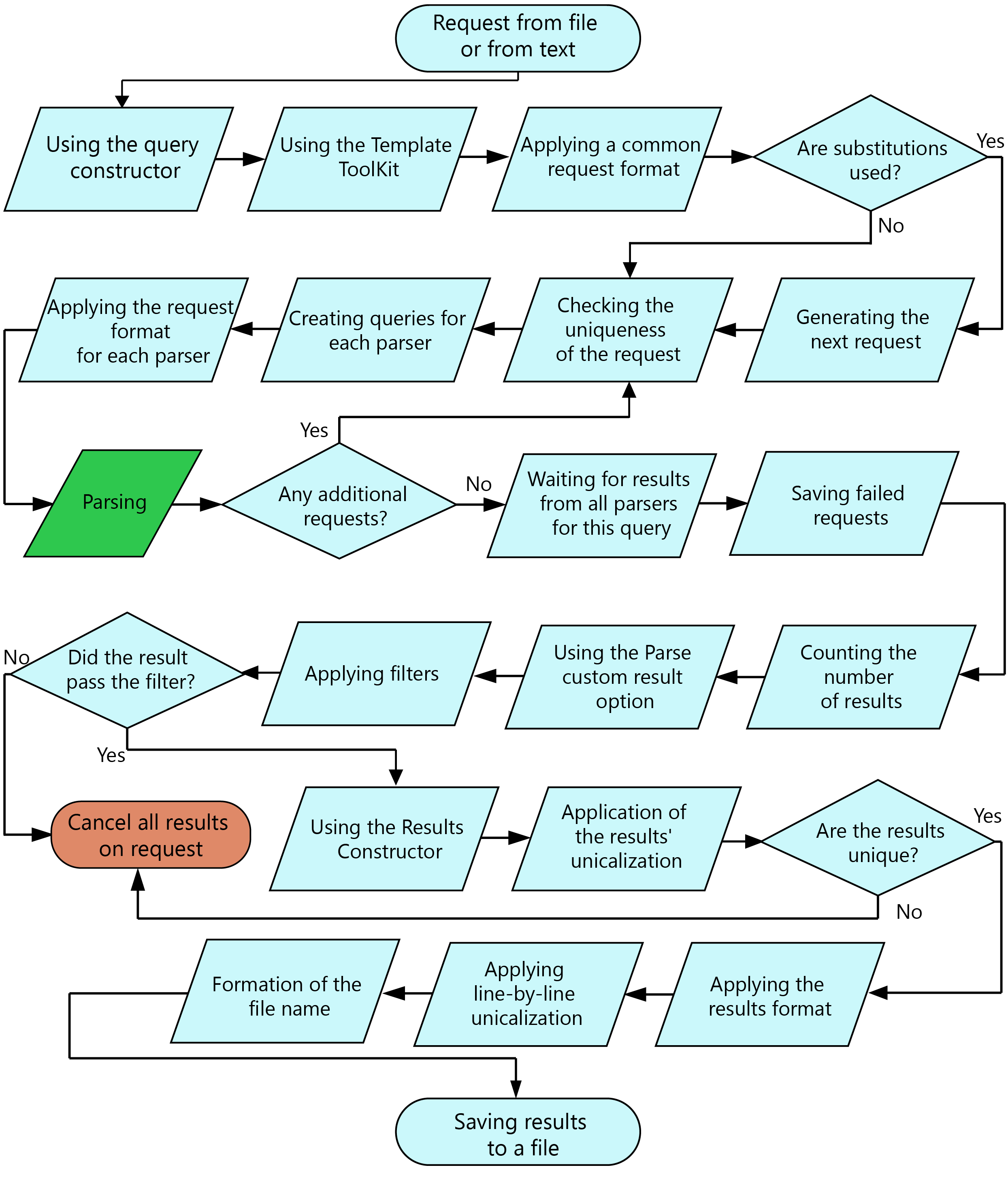
Orden de procesamiento de consultas
En A-Parser existe una multitud de funciones y posibilidades; este diagrama presenta el orden de procesamiento de una consulta desde su lectura de un archivo (o texto) hasta el guardado del resultado final en un archivo.
Esquema del orden de procesamiento de consultas
Notas
- Al filtrar y aplicar la unicidad de los resultados, la consulta y sus resultados se cancelan por completo si se utiliza un resultado simple como comparación; si se utiliza un array en la comparación, se eliminan los elementos de dicho array.
- Muchos pasos en el diagrama son opcionales y dependen de la configuración indicada en el Editor de tareas.
- Pueden aparecer consultas adicionales al utilizar las opciones Parse all result y Parse to level. Todas las consultas adicionales tienen el siguiente nivel con respecto a la consulta a partir de la cual se crearon; el conteo de niveles comienza desde cero, es decir, las consultas originales del archivo o texto siempre tienen el nivel 0. Las consultas tras aplicar sustituciones también tienen el nivel 0.
Consultas fallidas
Una consulta se considera fallida y se omite si no se pudo ejecutar en el número de intentos especificado.
¿Cómo determinar por qué una consulta falló? Active el registro de log o ejecute una Prueba de tarea. Todos los errores se registran en el log. Al estudiar el log, podrá comprender qué salió mal.
Ejemplo de una consulta fallida. Los logs sugieren que la consulta no se pudo ejecutar debido a un captcha y los intentos se agotaron. En este caso, puede ayudar conectar un servicio de resolución de captchas o aumentar el número de intentos (solo si está realizando la extracción de datos con proxies; de lo contrario, aumentar los intentos es inútil).
¿Cómo aumentar el número de intentos? Debe redefinir la opción Request retries y establecer un valor mayor.