Configurações
O A-Parser contém os seguintes grupos de configurações:
- Global Settings - configurações principais do programa: idioma, senha, parâmetros de atualização, número de tarefas ativas
- Config Presets - configurações de threads e métodos de desduplicação para tarefas
- Parser Presets - possibilidade de configurar cada scraper individualmente
- Configurações de verificação de proxy - número de threads e todas as configurações para o proxychecker
- Advanced Settings - configurações opcionais para usuários avançados
- Task presets - salvamento de tarefas para uso posterior
Todas as configurações (exceto as gerais e adicionais) são salvas nos chamados presets - conjuntos de configurações pré-salvas, por exemplo:
- Diferentes predefinições de configurações para o scraper
 SE::Google - uma para extração de dados de links com profundidade máxima de 10 páginas, outra para avaliação de concorrência por consulta, profundidade de extração de dados de 1 página
SE::Google - uma para extração de dados de links com profundidade máxima de 10 páginas, outra para avaliação de concorrência por consulta, profundidade de extração de dados de 1 página - Diferentes presets de configurações do proxychecker - separados para proxies HTTP e SOCKS
Para todas as configurações existe um preset padrão (default), ele não pode ser alterado; todas as alterações devem ser salvas em presets com novos nomes.
Configurações gerais
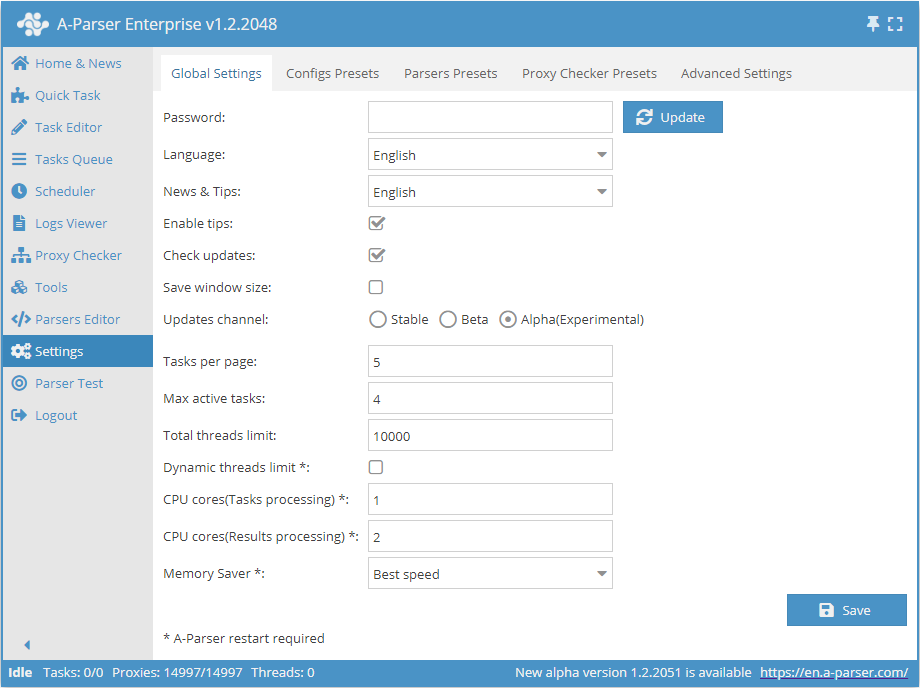
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Password | Sem senha | Definir uma senha para entrar no A-Parser |
| Language | English | Idioma da interface |
| News & Tips | English | Idioma das notícias e dicas |
| Enable tips | ☑ | Define se as dicas devem ser exibidas |
| Check updates | ☑ | Define se deve exibir informações sobre a disponibilidade de uma nova atualização na Barra de status |
| Save window size | ☐ | Define se deve salvar o tamanho da janela |
| Updates channel | Stable | Escolha do canal de atualizações (Estável, Beta, Alfa) |
| Tasks per page | 5 | Número de tarefas por página na Fila de tarefas |
| Max active tasks | 1 | Número máximo de tarefas ativas |
| Total threads limit | 10000 | Limite global de threads no A-Parser. A tarefa não será iniciada se o limite global de threads for menor que o número de threads na tarefa |
| Dynamic thread limit | ☐ | Define se deve usar o Limite dinâmico de threads |
| CPU cores (task processing) | 2 | Suporte para processamento de tarefas em diferentes núcleos do processador (apenas para licença Enterprise). Detalhado abaixo |
| CPU cores (result processing) | 4 | Vários núcleos são usados apenas na filtragem, Construtor de resultados, Parse custom result (todos os tipos de licença) |
| Memory Saver | Best speed | Permite definir quanta memória o scraper pode usar (Best speed / Medium memory usage / Save max memory). Saiba mais... |
Núcleos de CPU (processamento de tarefas)
Suporte para processamento de tarefas em diferentes núcleos do processador, esta funcionalidade está disponível apenas para licença Enterprise
Esta opção acelera (multiplicadamente) o processamento de várias tarefas na fila (Settings -> Max active tasks), mas não acelera a execução de uma única tarefa
Também foi implementada a distribuição inteligente de tarefas pelos núcleos de trabalho com base na carga de CPU de cada processo O número de núcleos de processador utilizados é definido nas configurações, por padrão - 2, máximo - 32
Assim como no caso das threads, a escolha do número de núcleos deve ser feita de forma experimental; valores razoáveis seriam 2-3 núcleos para processadores de 4 núcleos, 4-6 para processadores de oito núcleos, etc. Vale considerar que, com um grande número de núcleos e alta carga, pode ocorrer 100% de uso do processo de controle principal (aparser/aparser.exe), onde o aumento adicional de processos para processamento de tarefas causará apenas lentidão geral ou instabilidade. Também deve-se considerar que cada processo de processamento de tarefas pode criar uma carga adicional de até 300% (ou seja, carregar 100% simultaneamente em 3 núcleos), esta característica está ligada ao processamento multithread de coleta de lixo no motor JavaScript v8
Configurações de threads
O funcionamento do A-Parser é baseado no princípio de processamento de dados em múltiplas threads. O scraper executa tarefas paralelamente em threads separadas, cujo número pode variar de forma flexível dependendo da configuração do servidor.
Descrição do funcionamento das threads
Vamos entender o que são threads na prática. Suponha que você precise elaborar um relatório de três meses.
Opção 1
Você pode elaborar o relatório primeiro para o 1º mês, depois para o 2º e depois para o 3º. Este é um exemplo de trabalho em thread única. As tarefas são resolvidas uma por uma.
Opção 2
Contratar três contadores que elaborarão os relatórios, cada um para um mês. E então, ao receber os resultados dos três, fazer o relatório geral. Este é um exemplo de processamento em múltiplas threads. As tarefas são resolvidas simultaneamente.
Como visto nestes exemplos, o processamento em múltiplas threads permite realizar a tarefa mais rapidamente, mas ao mesmo tempo exige mais recursos (precisamos de 3 contadores em vez de 1). A multithreading funciona de forma análoga no A-Parser. Suponha que você precise extrair dados de vários links:
- com uma thread, o aplicativo fará a extração de cada site um por um
- ao trabalhar em várias threads, cada uma processará seu link e, ao terminar, passará para o próximo não processado na lista
Desta forma, na segunda opção, toda a tarefa será concluída significativamente mais rápido, mas requer mais recursos do servidor, por isso recomenda-se observar os Requisitos do sistema
Configuração de threads
A configuração de threads no A-Parser é feita separadamente para cada tarefa, dependendo dos parâmetros necessários para sua execução. Por padrão, estão disponíveis 2 configurações de threads: para 20 e 100 threads, para default e 100 Threads, respectivamente.
Para acessar as configurações da config selecionada, clique no ícone do lápis ![]() , após o qual suas configurações serão abertas.
, após o qual suas configurações serão abertas. 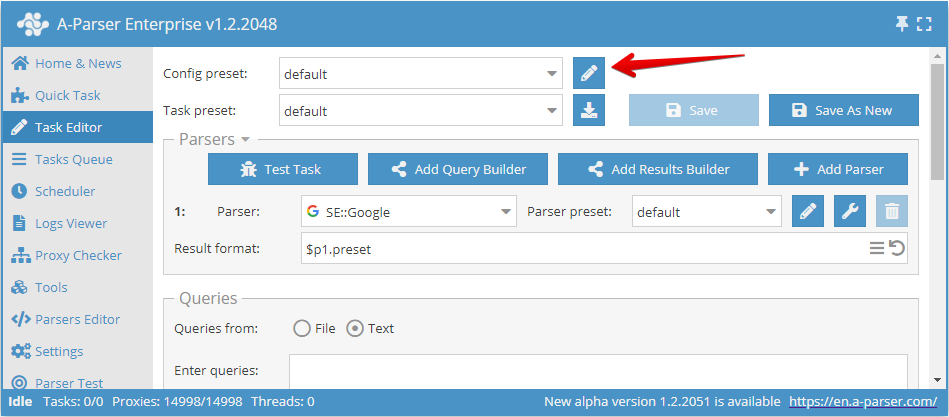
Também é possível acessar as configurações de threads através do item de menu: Settings -> Config Presets
Aqui podemos:
- criar uma nova config com suas próprias configurações e salvá-la com seu próprio nome (botão Adicionar novo)
- fazer alterações em uma config existente, selecionando-a na lista suspensa (botão Salvar)
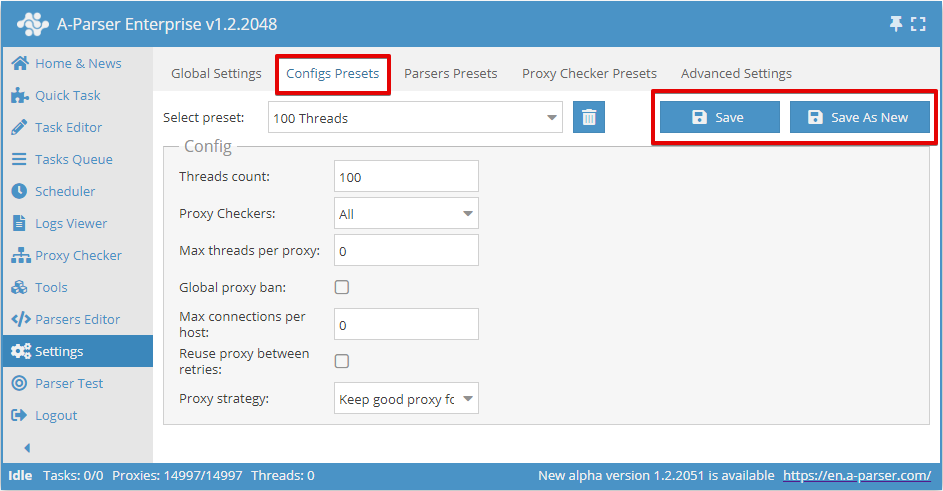
Número de threads (Threads count)
Este parâmetro define o número de threads em que a tarefa iniciada com esta config funcionará. O número de threads pode ser qualquer um, mas é necessário considerar as capacidades do seu servidor, bem como o limite do plano de proxy, se tal limite existir. Por exemplo, para nossos proxies, você pode especificar no máximo o plano selecionado.
Também é importante lembrar que o número total de threads no scraper é igual à soma das tarefas em execução e dos proxycheckers ativos com verificação de proxy. Por exemplo, se uma tarefa de 20 threads e duas tarefas de 100 threads cada estiverem em execução, e também um proxychecker com verificação de proxy em 15 threads estiver funcionando, o scraper usará no total 20+100+100+15=235 threads. Se o plano de proxy for para 200 threads, haverá muitas requisições falhas. Para evitá-las, é necessário reduzir o número de threads utilizadas. Por exemplo, desativar a verificação de proxy (se não for necessária, isso economizará 15 threads) e reduzir o número de threads em alguma tarefa em mais 20 threads. Assim, para uma das tarefas em execução, deve-se criar uma config de 80 threads e deixar as outras como estão.
Proxycheckers (Proxy Checkers)
Este parâmetro permite a escolha de um proxychecker com configurações específicas. Aqui você pode selecionar o parâmetro All, que significa o uso de todos os proxycheckers em funcionamento, ou apenas aqueles que devem ser usados na tarefa (é possível selecionar vários itens)
Esta configuração permite iniciar a tarefa apenas com os proxycheckers necessários. O processo de configuração do proxychecker é abordado aqui
Máximo de threads por proxy (Max threads per proxy)
Aqui é definido o número máximo de threads em que o mesmo proxy será usado simultaneamente. Permite definir diferentes parâmetros, por exemplo, o funcionamento de 1 thread = 1 proxy.
Por padrão, este parâmetro é 0, o que desativa esta função. Na maioria dos casos, isso é suficiente. Mas se for necessário limitar a carga em cada proxy, faz sentido alterar o valor.
Banimento global de proxy (Global proxy ban)
Todas as tarefas iniciadas com esta opção compartilham uma base comum de banimento de proxy. A característica deste parâmetro é que a lista de proxies banidos para cada scraper é comum a todas as tarefas em execução.
Por exemplo, um proxy banido no SE::Google na tarefa 1 também estará banido para o SE::Google na tarefa 2, mas poderá funcionar livremente no  SE::Yandex em ambas as tarefas
SE::Yandex em ambas as tarefas
Máximo de conexões por host (Max connections per host)
Este parâmetro indica o número máximo de conexões por host, destinado a reduzir a carga no site durante a extração de informações. Essencialmente, definir este parâmetro permite controlar o número de requisições em um dado momento para cada domínio específico. A ativação deste parâmetro aplica-se à tarefa; se várias tarefas forem iniciadas simultaneamente com a mesma config de threads, o limite será contado para todas as tarefas.
Por padrão, este parâmetro tem o valor 0, ou seja, está desativado.
Reutilização de proxy entre tentativas (Reuse proxy between retries)
Esta configuração desativa a verificação de unicidade de proxy para cada tentativa, e o banimento de proxy também não funcionará. Isso, por sua vez, significa a possibilidade de usar 1 proxy para todas as tentativas.
Recomenda-se ativar este parâmetro, por exemplo, nos casos em que se planeja usar 1 proxy que altera o IP de saída a cada conexão.
Estratégia de uso de proxy (Proxy strategy)
Permite gerenciar a estratégia de escolha de proxy ao usar sessões: manter o proxy de uma requisição bem-sucedida para a próxima requisição ou sempre usar um proxy aleatório.
Recomendações
Neste artigo foram abordadas todas as configurações que permitem gerenciar as threads. Vale notar que, ao configurar a config de threads, não é obrigatório definir todos os parâmetros mencionados no artigo; basta definir apenas aqueles que garantirão a obtenção do resultado correto. Geralmente, basta alterar apenas o Threads count, as outras configurações podem ser deixadas no padrão.
Configurações de scrapers
Cada scraper possui diversas configurações e permite salvar diferentes conjuntos de configurações em predefinições. O sistema de predefinições permite usar o mesmo scraper com diferentes configurações dependendo da situação, vejamos o exemplo do scraper SE::Google:
Preset 1: "Extração do número máximo de links"
- Número de páginas (Pages count):
10
Desta forma, o scraper coletará o número máximo de links, percorrendo todas as páginas dos resultados de busca.
Preset 2: "Extração de concorrência por consulta"
- Número de páginas (Pages count):
1 - Formato do resultado (Results format):
$query: $totalcount\n
Neste caso, obtemos o número de resultados da busca por consulta (concorrência da consulta) e, para maior velocidade, basta extrair apenas a primeira página.
Criação de presets
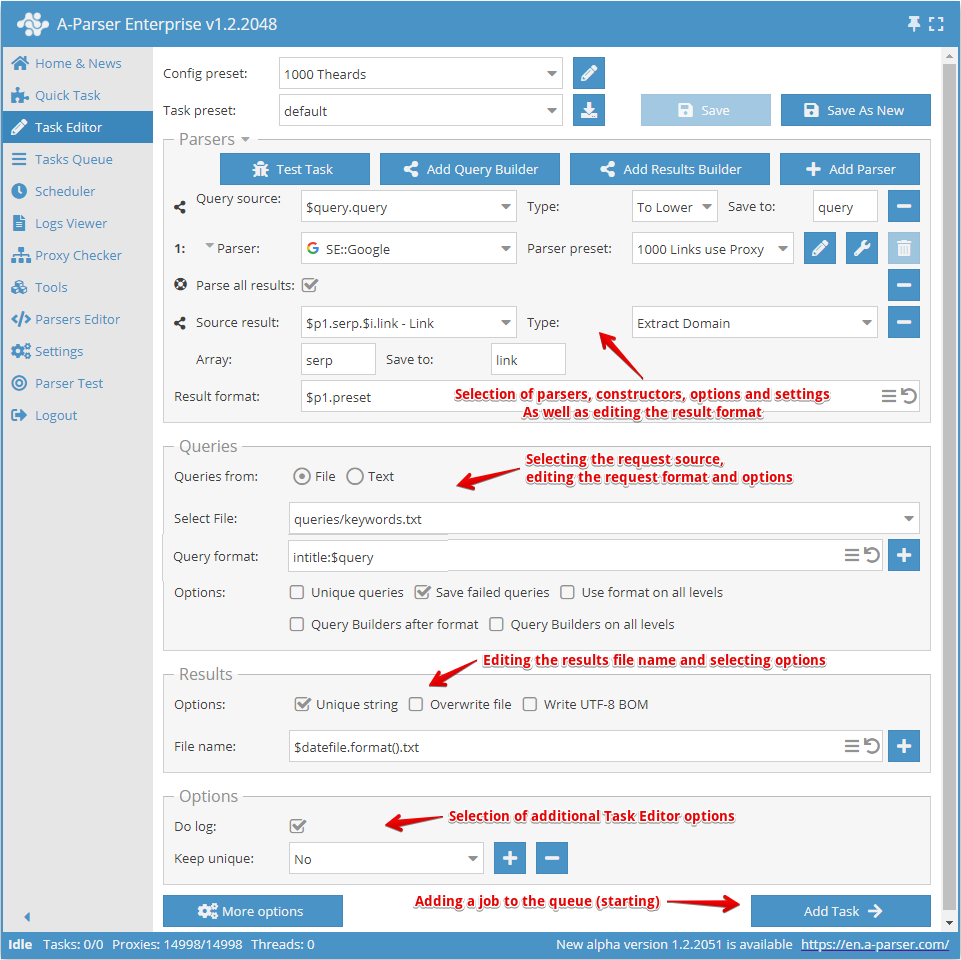
A criação de um preset começa com a escolha do scraper/scrapers e a definição do resultado que se deseja obter.
Em seguida, é necessário entender quais serão os dados de entrada para o scraper selecionado; na captura de tela acima, o scraper SE::Google está selecionado, e seus dados de entrada são quaisquer strings, como se você estivesse pesquisando algo no navegador. Você pode selecionar um arquivo de consultas ou inserir as consultas no campo de texto.
Agora é necessário redefinir as configurações (escolher opções) para o scraper, adicionar desduplicação. Pode-se usar o construtor de consultas se for necessário processar consultas. Ou usar o construtor de resultados se for necessário processar os resultados de alguma forma.
Em seguida, deve-se prestar atenção à edição do nome do arquivo de resultados e, se necessário, alterá-lo conforme sua preferência.
O último ponto é a escolha de opções adicionais, especialmente a opção Do log (Manter log). Muito útil se você quiser descobrir o motivo de um erro de extração de dados.
Após tudo isso, é necessário salvar o preset e adicioná-lo à fila de tarefas.
Redefinição de configurações
Override preset - redefinição rápida de configurações para o scraper, esta opção pode ser adicionada diretamente no Editor de tarefas. Com um clique, é possível adicionar vários parâmetros. Na lista de configurações, os valores padrão são indicados e, se a opção estiver em negrito, significa que já foi redefinida no preset.
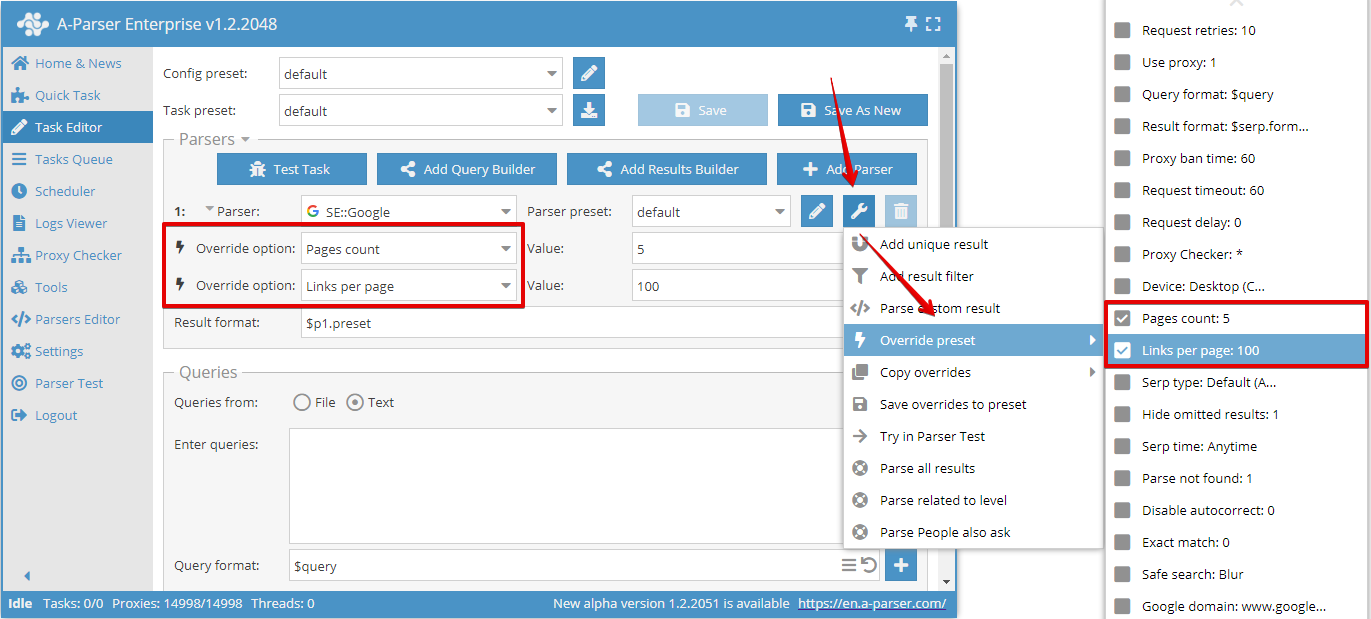
Neste exemplo, a opção Pages count (Número de páginas) foi redefinida para 5.
Na tarefa, pode-se usar um número ilimitado de opções Override preset, mas se houver muitas alterações, é mais conveniente criar um novo preset e salvar todas as alterações nele.
Também é possível salvar as redefinições facilmente usando a função Save overrides to preset (Salvar redefinições). Elas serão salvas como um preset separado para o scraper selecionado.
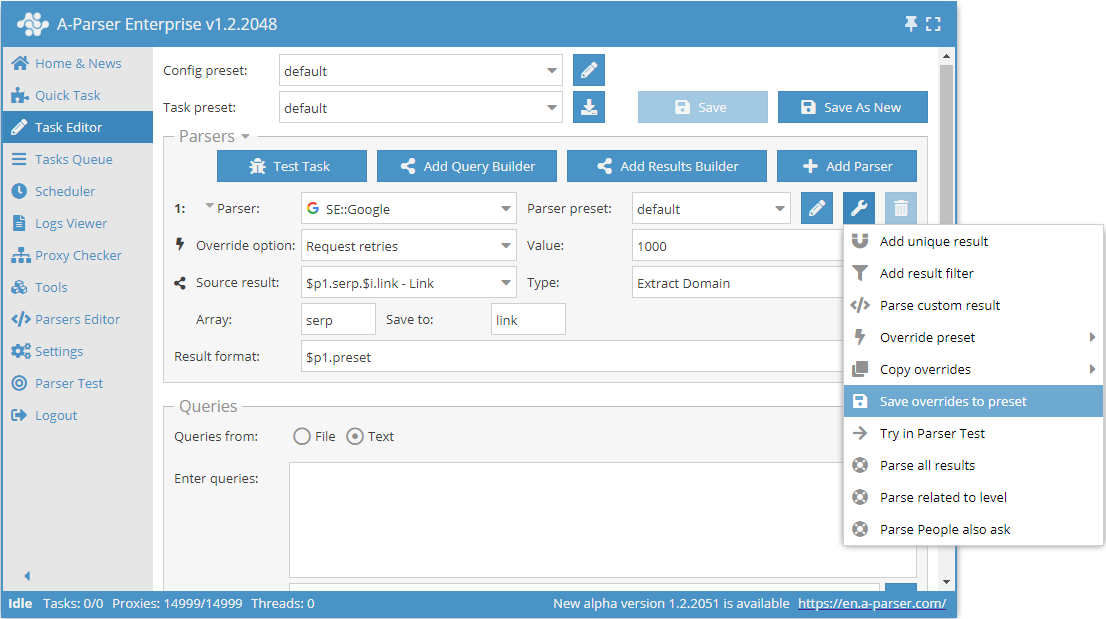
Depois disso, no futuro, bastará selecionar este preset salvo na lista e usá-lo.
Configurações comuns para todos os scrapers
Cada scraper tem seu próprio conjunto de configurações; informações sobre as configurações de cada scraper podem ser encontradas na seção correspondente
Nesta tabela, apresentamos as configurações comuns para todos os scrapers
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Request retries | 10 | Número de tentativas para cada requisição; se a requisição não puder ser concluída no número de tentativas especificado, ela será considerada falha e ignorada |
| Use proxy | ☑ | Define se deve usar proxy |
| Query format | $query | Formato da consulta |
| Result format | Cada scraper tem seu próprio valor | Formato de saída do resultado |
| Proxy ban time | Cada scraper tem seu próprio valor | Tempo de banimento do proxy em segundos |
| Request timeout | 60 | Tempo máximo de espera da requisição em segundos |
| Request delay | 0 | Atraso entre requisições em segundos; pode-se definir um valor aleatório em um intervalo, por exemplo 10,30 - atraso de 10 a 30 segundos |
| Proxy Checker | All | Proxies de quais checkers devem ser usados (escolha entre todos ou enumeração de específicos) |
Comuns para todos os scrapers que funcionam via protocolo HTTP
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Max body size | Cada scraper tem seu próprio valor | Tamanho máximo da página de resultados em bytes |
| Use gzip | ☑ | Define se deve usar compressão do tráfego transmitido |
| Extra query string | Permite especificar parâmetros adicionais na string de consulta |
As configurações padrão para cada scraper podem variar. Elas são armazenadas no preset default nas configurações de cada scraper.
Configurações de proxycheckers
Saiba mais sobre a Configuração de proxycheckers
Configurações adicionais
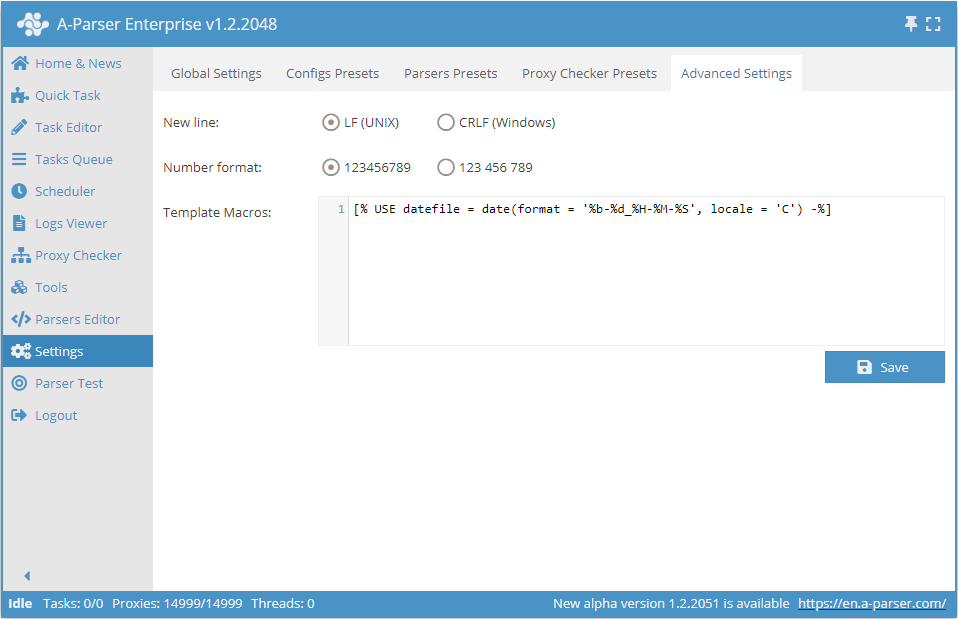
- Quebra de linha permite escolher entre a variante Unix e Windows de final de linha ao salvar resultados em arquivo
- Formato de números - define como exibir números na interface do A-Parser
- Macros de modelos