SE::Google - Scraper wyników wyszukiwania Google
Przegląd scrapera
Scraper wyników wyszukiwania Google jest jednym z najbardziej pożądanych, dzięki niemu będziesz mógł otrzymywać ogromne bazy linków, gotowych do dalszego wykorzystania. Możesz używać zapytań w takiej samej formie, w jakiej wpisujesz je w Google, wliczając w to operatory wyszukiwania (inurl, intitle itp.).
Scraper Google obsługuje automatyczne rozmnażanie zapytań, dzięki czemu możesz być pewien, że otrzymasz maksymalną liczbę wyników z wyszukiwarki. Ponadto A-Parser może automatycznie przechodzić po powiązanych zapytaniach na określoną głębokość. Dzięki wielowątkowej pracy A-Parser, prędkość przetwarzania zapytań może osiągać 3000-7000 zapytań na minutę, co średnio pozwala na uzyskanie do 500 000 linków na minutę.
Funkcjonalność A-Parser pozwala zapisywać ustawienia scrapowania do dalszego wykorzystania (presety), ustalać harmonogram scrapowania i wiele więcej. Możesz korzystać z automatycznego rozmnażania zapytań, podstawiania podzapytań z plików, generowania kombinacji alfanumerycznych i list w celu uzyskania maksymalnej możliwej liczby wyników.
Zapisywanie wyników jest możliwe w dowolnej formie i strukturze, której potrzebujesz, dzięki wbudowanemu potężnemu silnikowi szablonów Template Toolkit, który pozwala na stosowanie dodatkowej logiki do wyników i wyprowadzanie danych w różnych formatach, w tym JSON, SQL i CSV.
Przypadki użycia scrapera
🔗 Scrapowanie domen
Scrapowanie domen tematycznych według frazy kluczowej z Google i pobieranie różnych parametrów domen
🔗 Scrapowanie Google News
Ten preset scrapuje wiadomości Google według zapytania wyszukiwania i zbiera daty tych wiadomości
🔗 Sprawdzanie indeksacji
Preset sprawdza indeksację stron witryny w Google, przechodząc przez listę podanych linków
🔗 Ocena konkurencji
Preset określa konkurencję w wyszukiwarce Google według słów kluczowych
🔗 Scrapowanie wyników top 3
Preset zapisuje pierwsze trzy snippety z wyników wyszukiwania Google
🔗 Pytania i odpowiedzi
Scraper zbierający pytania i odpowiedzi z sekcji People Also Ask
Zbierane dane
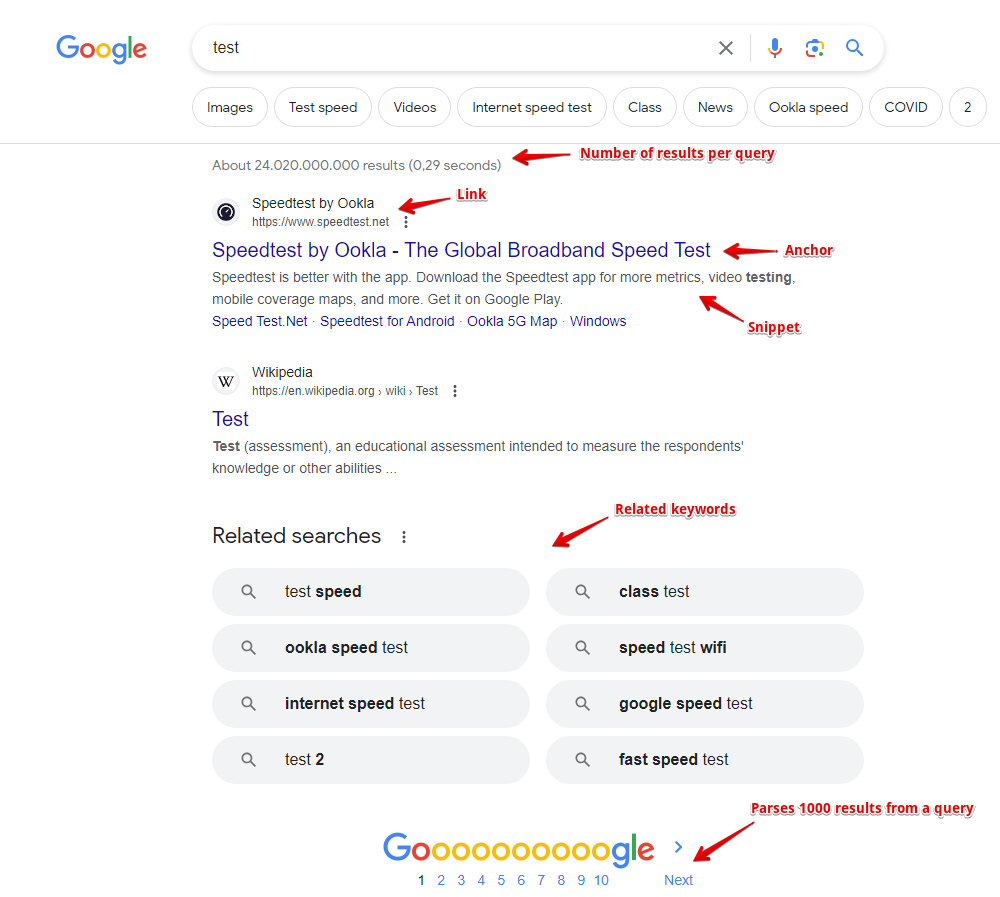
- Linki, anchory i snippety z wyników wyszukiwania, a także datę ze snippetu (jeśli jest dostępna)
- Zbierane są również informacje o flagach każdego wyniku, obecnie obsługiwane są flagi: Date, AMP, Image Preview, Video, Rich snippet, Featured snippet
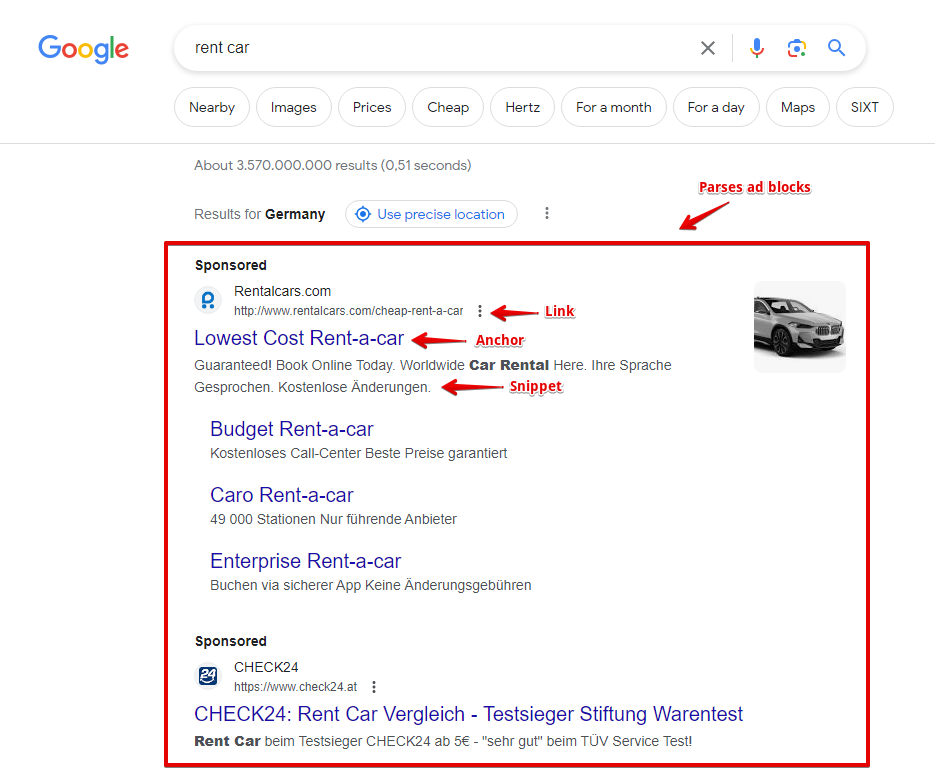
- Obecność i zawartość bloków reklamowych, a także ich pozycję na stronie
- Liczbę wyników dla zapytania (konkurencja)
- Listę powiązanych słów kluczowych (Related keywords)
- Obecność dodatkowych bloków na stronie: karuzela produktów, wideo itp.
- Scraper zbiera również takie dodatkowe dane:
- Obecność literówki w zapytaniu i poprawione zapytanie
- Lokalizację geograficzną określoną przez Google
- Obecność stron AMP
- Listę People also ask: pytania, odpowiedzi, linki do źródeł, ich anchory i linki do mediów (włączane osobną opcją Parse People also ask)
- Odpowiedź AI (AI overview), jej typ oraz listę źródeł
Możliwości
Scraper wyszukiwarki Google posiada wiele możliwości i ustawień:
- obsługa wszystkich operatorów wyszukiwania Google (site:, inurl: itp.)
- określenie rozmiaru wyników (10, 20, 30, 50 lub 100 wyników) oraz określenie liczby stron (od 1 do 10), przy maksymalnych ustawieniach Google podaje od 300 do 500 wyników na jedno zapytanie, dzięki rozmnażaniu zapytań A-Parser łatwo omija to ograniczenie
- możliwość automatycznego przechodzenia po powiązanych słowach kluczowych
- określenie języka i kraju wyników, możliwość wyboru lokalnej domeny Google, a także języka interfejsu wyników
- możliwość wskazania geolokalizacji, co pozwala na uzyskanie precyzyjnych lokalnych wyników dla dowolnego miejsca na świecie
- wybór między widokiem desktop a mobilnym
- możliwość wyboru typu wyników, oprócz głównych wyników organicznych scraper Google może zbierać wyniki wiadomości, książek lub wideo
- w razie potrzeby można podłączyć automatyczne rozpoznawanie ReCaptcha2 poprzez serwisy rozpoznawania lub przez XEvil/CapMonster
- obsługuje określenie czasu publikacji wyników (za cały czas lub za określony interwał od 24 godzin do roku)
- możliwość wyłączenia filtra Google ukrywającego podobne wyniki (filter=)
- możliwość określenia, czy scrapować wyniki, jeśli Google informuje, że dla danego zapytania nic nie znaleziono i proponuje wyniki dla podobnego zapytania
- możliwość ustawienia liczby People also ask, które scraper powinien zebrać, klikając w głąb każdego pytania
- możliwość zbierania tagów
Na bazie scrapera Google działają następujące scrapery:
 SE::Google::Position - określanie pozycji dowolnych witryn w wynikach wyszukiwania dla listy zapytań
SE::Google::Position - określanie pozycji dowolnych witryn w wynikach wyszukiwania dla listy zapytań SE::Google::Compromised - sprawdza domeny pod kątem bezpieczeństwa z punktu widzenia Google, potrafi identyfikować witryny zhakowane i phishingowe
SE::Google::Compromised - sprawdza domeny pod kątem bezpieczeństwa z punktu widzenia Google, potrafi identyfikować witryny zhakowane i phishingowe SE::Google::TrustCheck - sprawdza Trust (zaufanie) Google do witryny
SE::Google::TrustCheck - sprawdza Trust (zaufanie) Google do witryny
Warianty użycia
- Zbieranie baz linków - dla XRumer, AllSubmitter, GSA Ranker itp.
- Pełny zrzut SERP, zawierający linki, anchory, snippety, bloki reklamowe i inne informacje, pozwala na przeprowadzenie głębokiej analizy dla specjalistów SEO i marketerów
- Ocena konkurencji dla słów kluczowych
- Ocena konkurencji w wynikach PPC (reklamowych)
- Wyszukiwanie backlinków i wzmianek o stronach
- Sprawdzanie indeksacji stron
- Wyszukiwanie podatnych stron
- Wszelkie inne warianty zakładające pozyskiwanie wyników wyszukiwania dla nieograniczonej liczby zapytań
Zapytania
Jako zapytania należy podawać frazy wyszukiwania dokładnie tak samo, jak gdyby były wpisywane bezpośrednio w formularzu wyszukiwania Google, na przykład:
zakup auta
okna w warszawie
site:https://lenta.ru
inurl:guestbook
Podstawienia zapytań
Możesz używać wbudowanych makr do rozmnażania zapytań, na przykład chcemy uzyskać bardzo dużą bazę forów, podajmy kilka głównych zapytań w różnych językach:
forum
forum
foro
论坛
W formacie zapytań wskażemy generowanie znaków od a do zzzz, ta metoda pozwala na maksymalną rotację wyników wyszukiwania i uzyskiwanie wielu nowych unikalnych wyników:
$query {az:a:zzzz}
To makro utworzy 475254 dodatkowych zapytań dla każdego bazowego zapytania, co łącznie da 4 x 475254 = 1901016 zapytań wyszukiwania, liczba imponująca, ale nie stanowi to żadnego problemu dla A-Parser. Przy prędkości 2000 zapytań na minutę takie zadanie zostanie przetworzone w zaledwie 16 godzin.
Użycie operatorów
Możesz używać operatorów wyszukiwania w formacie zapytania, dzięki czemu zostaną one automatycznie dodane do każdego zapytania z Twojej listy:
inurl:$query
Warianty wyprowadzania wyników
A-Parser obsługuje elastyczne formatowanie wyników dzięki wbudowanemu silnikowi szablonów Template Toolkit, co pozwala mu na wyprowadzanie wyników w dowolnej formie, a także w formie strukturalnej, na przykład CSV lub JSON
Eksport listy linków
Format wyniku:
$serp.format('$link\n')
Przykład wyniku:
https://www.weforum.org/open-forum/
https://www.weforum.org/about/world-economic-forum/
https://www.merriam-webster.com/dictionary/forum
https://en.wikipedia.org/wiki/Forum
https://dictionary.cambridge.org/dictionary/english/forum
https://www.collinsdictionary.com/dictionary/english/forum
https://www.linkedin.com/company/world-economic-forum
https://docs.moodle.org/en/Forum_activity
https://wordpress.org/support/forums/
https://www.facebook.com/worldeconomicforum/
...
Linki + anchory + snippety z wyprowadzeniem pozycji
Format wyniku:
[% FOREACH item IN serp; loop.count _ ' - ' _ item.link _ ' - ' _ item.anchor _ ' - ' _ item.snippet _ "\n"; END %]
Przykład wyniku:
1 - https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC - Forum — Wikipedia - <em>Fórum</em> (łac. forum — arch. przedsionek grobowca; plac w tłoczni dla winogron podlegających obróbce; plac targowy, rynek miejski; ...
2 - https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC_(%D0%BC%D0%B5%D1%80%D0%BE%D0%BF%D1%80%D0%B8%D1%8F%D1%82%D0%B8%D0%B5) - Forum (wydarzenie) — Wikipedia - <em>Forum</em> — wydarzenie organizowane w celu określenia lub rozwiązania jakich-<wbr>kolwiek w wystarczającym stopniu globalnych problemów. Pojęcie to spotyka się w ...
3 - https://support.google.com/googleplay/community?hl=ru - Witamy na forum pomocy społeczności ... - Witamy na forum pomocy <em>forum</em> społeczności Google Play. Polecane wpisy. Zobacz wszystkie ciekawe wpisy · Potrzebujesz pomocy z grą?
4 - https://support.google.com/mail/community?hl=en - Gmail Community - Google Support - Welcome to the Gmail Help Community · Featured posts · Categories.
5 - https://www.weforum.org/ - The World Economic Forum - The World Economic Forum is an independent international organization committed to improving the state of the world by engaging business, political, academic ...
6 - https://www.kunena.org/ - Home - Kunena - To Speak! Next Generation Forum ... - Kunena! - To Speak! Next Generation Forum Component for Joomla.
7 - https://forum.adguard.com/index.php - AdGuard Forum - <em>Forum</em> beta testerów. Tutaj piszemy raporty o błędach wersji beta. Wątki: 355. Wiadomości: 11.6K. Subfora: Komentarze do wydań wersji beta ...
8 - https://www.sofiaforum.bg/ - Sofia Security Forum: Platforma do dyskusji ... - Sofia <em>Security Forum</em> / Sofia Security Forum.
9 - https://forum.keenetic.net/ - Forums - Keenetic Community - Keenetic fan club. A place to meet software developers, get the latest updates, and share experience.
10 - https://forum.euroaion.com/ - Perfect quality European private server of Aion - EuroAion.com - Perfect quality European private server of Aion!
...
Wyprowadzanie linków, anchorów i snippetów do tabeli CSV
Wbudowane narzędzie $tools.CSVLine pozwala na tworzenie poprawnych dokumentów tabelarycznych, gotowych do importu do Excela lub Google Sheets.
Ogólny format wyniku:
[% FOREACH i IN p1.serp; tools.CSVline(i.link, i.anchor, i.snippet); END %]
Nazwa pliku:
$datefile.format().csv
Tekst początkowy:
Link,Anchor,Snippet
Przykład wyniku:
Link,Anchor,Snippet
https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC,"Forum — Wikipedia",
https://en.wikipedia.org/wiki/Forum,"Forum - Wikipedia","<em>Forum</em> (plural forums or fora) may refer to: Contents. 1 Common uses; 2 Places. 2.1 Natural features; 2.2 Populated places. 3 Arts and entertainment; 4 Media."
https://www.weforum.org/,"The World Economic Forum","The World Economic <em>Forum</em> is an independent international organization committed to improving the state of the world by engaging business, political, academic ..."
https://support.google.com/webmasters/community?hl=ru,"Witamy na forum pomocy społeczności ...","Witamy na forum pomocy <em>forum</em> społeczności Centrum wyszukiwarki Google. Polecane wpisy. Zobacz wszystkie ciekawe wpisy · Odpowiedzi na ..."
https://support.google.com/chrome/community?hl=ru,"Witamy na forum pomocy społeczności ...","Witamy na forum pomocy <em>forum</em> społeczności Google Chrome. Polecane ..."
...
W Ogólnym formacie wyników stosowany jest silnik szablonów Template Toolkit do wyprowadzania tablicy $serp w pętli FOREACH.
W nazwie pliku wyników należy po prostu zmienić rozszerzenie pliku na csv.
Aby opcja "Prepend text" była dostępna w Edytorze zadań, należy aktywować "More options". W "Prepend text" wpisujemy nazwy kolumn oddzielone przecinkami, a drugą linię pozostawiamy pustą.
Wyprowadzanie bloków reklamowych
Format wyniku:
$ads.format('$link - $anchor - $snippet\n')
Przykład wyniku:
https://www.rentalcars.com/ - Rent a Car Worldwide - Best Prices Online Guaranteed - Secure Your <em>Car Hire</em> Today. The Best Price Guaranteed. Book at Over 53,000 Locations. Search, Compare and Save Using the World's Biggest Online <em>Car Rental</em> Service.
https://www.kayak.com/United-States-Car-Rentals.253.crc.html - United States from $9/day - Search for Rental Cars on Kayak - Find and Compare Great <em>Car</em> Deals in USA. Book with Confidence on KAYAK®!
https://www.discovercars.com/ - -70% Worldwide Car Rental - Rent Your Car in 5 Minutes - <em>Car rental</em> prices are rising, but if you act fast, you can get a good deal. Don’t stress! We...
https://www.economybookings.com/ - Rent a Car for Summer Holidays - Car Rentals for the Best Price - Theft protection and Third Party liability part of a great deal. Free Mileage included.
...
Zapisywanie powiązanych słów kluczowych
Format wyniku:
$related.format('$key\n')
Przykład wyniku:
test <b>speed</b>
<b>net speed</b> test
<b>google speed</b> test
<b>fast speed</b> test
<b>ping</b> test
<b>xfinity speed</b> test
<b>speed</b> test <b>mobile</b>
test <b>my</b>
...
Aby automatycznie usuwać tagi HTML w wyniku, należy użyć Konstruktora wyników, wybrać tablicę $related i zastosować Remove HTML tags.
Konkurencja słów kluczowych
Format wyniku:
$query - $totalcount\n
Przykład wyniku:
speed test mobile - 1080000000
test score - 4020000000
net speed test - 1210000000
fast speed test - 2150000000
speed test - 2500000000
test match - 4160000000
ping test - 425000000
google speed test - 1870000000
Wykrywanie słów kluczowych z błędami
Format wyniku:
$query - $misspell\n
Przykład wyniku:
spead test - 1
test match - 0
speed test - 0
temst match - 1
Sprawdzanie indeksacji linków
Format zapytania:
site:$query
Format wyniku:
$query.orig - $totalcount\n
Przykład wyniku:
https://a-parser.com/pages/buy - 2
https://a-parser.com/wiki/parsers - 4
https://a-parser.com/resources - 883
https://trjkjfkdf.bg.ky - none
https://a-parser.com/forum - 371
Aby sprawdzić indeksację linków, wstawiamy w Formacie zapytania odpowiedni operator: site:.
Format wyniku jest wyprowadzany w postaci "źródłowy url - liczba stron w indeksie".
W rezultacie otrzymujemy adres stron i ich liczbę w indeksie wyszukiwarki.
Jeśli strona nie istnieje w indeksie, wynikiem będzie: none.
Zapisywanie w formacie SQL
Format wyniku:
[% FOREACH serp; "INSERT INTO serp VALUES('" _ query _ "', '"; link _ "', '"; anchor _ "')\n"; END %]
Przykład wyniku:
INSERT INTO serp VALUES('test', 'https://www.speedtest.net/', 'Speedtest by Ookla - The Global Broadband Speed Test')
INSERT INTO serp VALUES('test', 'https://fast.com/', 'Fast.com: Internet Speed Test')
INSERT INTO serp VALUES('test', 'https://www.business-standard.com/article/sports/ind-vs-aus-live-score-4th-day-5-india-vs-australia-live-cricket-score-online-brisbane-weather-121011900103_1.html', 'IND vs AUS 4th Test highlights: India creates history, wins ...')
INSERT INTO serp VALUES('test', 'https://www.test.com/', 'Find online tests, practice test, and test creation software | Test ...')
INSERT INTO serp VALUES('test', 'https://www.espncricinfo.com/series/india-in-australia-2020-21-1223867/australia-vs-india-4th-test-1223872/match-report-4', 'Recent Match Report - Australia vs India 4th Test 2020 ...')
INSERT INTO serp VALUES('test', 'https://www.icc-cricket.com/world-test-championship/standings', 'World Test Championship (2019-2021) Points Table - Live ...')
INSERT INTO serp VALUES('test', 'https://www.icc-cricket.com/rankings/mens/team-rankings/test', 'ICC Test Match Team Rankings International Cricket Council')
INSERT INTO serp VALUES('test', 'https://projectstream.google.com/speedtest', 'Speedtest - Google')
INSERT INTO serp VALUES('test', 'https://www.google.com/search?hl=en&q=Software+Testing&stick=H4sIAAAAAAAAAONgecQ4g5Fb4OWPe8JSfYyT1py8xtjOyMUVnJFf7ppXkllSKaTCxQZlSXHxSHHo5-obmJul5GkwSHFxwXlKwUbuuy5NO8fmKMgABGJm_g5SmlpCXOyexT75yYk5ggpvuB68mfLeXkuYiyMksSI_Lz-3UtCBgcHhx__39kqcnEBND7aoddhrMTTtW3GIjYWDUYCBZxGrQHB-Wkl5YlGqQkhqcUlmXjoAS5B1P7EAAAA&sa=X&ved=2ahUKEwiW-rnmlajuAhWpAGMBHR-JAv4Q6RMwHXoECDQQBQ', '')
...
Zrzut wyników do JSON
Ogólny format wyniku:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.links = [];
FOREACH item IN p1.serp;
obj.links.push(item.link);
END;
obj.json %]
Tekst początkowy:
[
Tekst końcowy:
]
Przykład wyniku:
[{"totalcount":"6450000000","links":["https://www.speedtest.net/","https://fast.com/","https://projectstream.google.com/speedtest","https://www.test.com/","https://www.speakeasy.net/speedtest/","https://www.att.com/support/speedtest/","https://speedtest.xfinity.com/","https://developers.google.com/speed/pagespeed/insights/","https://www.espncricinfo.com/series/india-in-australia-2020-21-1223867/australia-vs-india-4th-test-1223872/match-report-4","https://nasional.tempo.co/read/1424570/listyo-sigit-temui-ahy-menjelang-fit-and-profer-test-calon-kapolri","https://www.google.com/search?hl=en&q=Test+Assessment&stick=H4sIAAAAAAAAAONgecRYyC3w8sc9YamMSWtOXmNM4uIKzsgvd80rySypFNLiYoOyFLj4pbj10_UNjQyzKsvyzDQYpHi5kAWUNIxkdl2ado5NTJABCMTKAhyUODmBLIVA-wX2WgxN-1YcYmPhYBRg4FnEyh-SWlyi4FhcnFpcnJuaVwIAwEAP9ogAAAA&sa=X&ved=2ahUKEwj17MzXmajuAhW8CWMBHRlzBP4Q6RMwDHoECBEQBQ"]}]
Aby opcje "Prepend text" i "Append text" były dostępne w Edytorze zadań, należy aktywować "More options".
Przetwarzanie wyników
A-Parser pozwala na przetwarzanie wyników bezpośrednio podczas scrapowania, w tej sekcji przedstawiliśmy najpopularniejsze przypadki dla scrapera Google
Usuwanie duplikatów linków
Dodaj usuwanie duplikatów i z listy rozwijanej wybierz $serp.$i.link - Link.
Pobierz przykład
Jak importować przykład do A-Parser
eJx9VE1v2zAM/SsFkcMGBEFy2MW3NFiKDVnTNekpyEGNaUOLLGmSnDUw/N9H+ktO
N/Rmko+PfCTlCoLwZ//k0GPwkBwqsM03JLD7miQPxuQK7zZSn/3di5a/S4QpWOE8
OoYfRigKpJiJUgWYVhCuFonEXNA5mXJQpmRbZ96uDoOT6Ml3Eapk2GI+n0P9QZrI
8WRKHWLO4gO44n4tOk4bZcxHKWUvhuRyy8kBSJMlByfDcdoh9i3cU8c6h977oMyr
UJAEV2J9PPYsfm1cIXh4E7uYdZMcgjtxwb2hYCZVrOzXZD2KgqtMUhGQo7OsIfr0
eRbemEGkqQzSaKHaCjz7WLVbTALaEJY+ebprZwpyBWwI2HntuzvApLGjyp9tDiSZ
UB6n4KnVtaBG0vcRGdCJYNzWcj/kr8DopVIbvKCKsIb/vpQqpUNZZpT0rUv8P2T7
D0c9yBuXokX/cdTDwNJY99sfMSs1G5OT8vS1WWYhA9l+1VxPAnNynhHtMLNHnllh
HA5lOuauOr0Ni5qvKq5saaPrRsbNWm6dJ6MzmW+7S+2Rpd7TA9zqlSmsQtalS6Vo
LR6f43ksfbcGNmKD75NXTQmW3r9DCMYo/33XtmqdpPP7wg0WNMlx1Y7yJJR6ed6M
IxBPqjknz7QnutPc0AWRivo4/BGG/0g1/i8kVU1r+eWfWhBrYAj5aBieZs6P+S/t
6pW4
Zobacz również: Usuwanie duplikatów wyników
Usuwanie duplikatów linków według domeny
Dodaj usuwanie duplikatów i z listy rozwijanej wybierz $serp.$i.link - Link. Wybierz typ usuwania duplikatów: Domain.
Pobierz przykład
Jak importować przykład do A-Parser
eJx9VE2P2jAQ/SvI4tBKaAWHXnJj6bJqRZftwp4QB0MmyMXxuLZDF0X89844IQ7b
am+ZmffefDq1CNIf/bMDD8GLbFMLG79FJlYPWfaIeNAwWChz9INXo35XMNidB1+x
lMqIkbDSeXBM3PTwFMihkJUOYlSLcLZAcngC51TOQZWTbR2+nR0Ep8CT7yR1xbDJ
eDwWlw9o8gB7rExInMkHcM2VW3BM6zHGPUoV26IgNc4lZxtBPVlyMFlsRy1i3cDz
a++N91HjTmqRBVfBZbu9qvg5ulLyGId2ctfOtAuu5AnWSMFC6ZTZz8l6kiVnGeYy
AEfviij06fNdeGMFmecqKDRSNxl49ilrsyLiGyQsffJ05w5LcgWIAuw8X6vbiGG0
U5c/G47ICqk9jISnUueSCsnfR1QAJwO6peV6yF8LNFOtF3ACnWBR/75SOqdDmRZE
+tYS/w9Z/qNx6drrp6JF/3FUQ6cSrfvlj8TKcYEHXtkuLrNUgWw/i9eTiTE5jwC2
m9kTz6xEB12aVrnNTq/EguGrSiub2uS6aeNmLbfOPZpCHZbtpV6RlVnTU1yaGZZW
A/dlKq1pLR5e0nlMfbsGNlKB78mzmIJbv75DERC1/75qSrVO0fl94QJLmmQ/ayu5
l1q/viz6EZFOKp6TZ9k93ekB6YKoi8u2+yN0f5S6/1/I6gut5Zd/bkDcA0PIR8Pw
NHN+zH8BRVyZDA==
Zobacz również: Usuwanie duplikatów wyników
Wyodrębnianie domen
Dodaj Result Builders (Konstruktor wyników) i z listy rozwijanej wybierz źródło: $p1.serp.$i.link - Link. Wybierz typ: Extract Domain.
Pobierz przykład
Jak importować przykład do A-Parser
eJx9VE1v2zAM/SuFkMMGBIFz2MW3NGuGDVnTNe0p6EGzaUOLLGqSnCUw8t9HKort
dkNv5scj+cgndyJIv/cPDjwEL/JdJ2z8FrnY3uX5F8Raw83dMThZhJvP2EhlxFRY
6Tw4BuxGeRQooZKtDmLaiXCyQGXwAM6pkoOqJNs6PJ4cBKfAk+8gdctp8yzLxPkd
mKyhwNaEATN/J10rs/cWHMNGiOz88jIVxJBm9Ct0jWSmEzufJdp9cCsP8IQUrFQk
dsWQdS8bbjkpZQCOzqpY6MPHWThyBVmWKig0Ul868JqGrs9G/Y6MDVIuffIiVg4b
cgWIBdh5uk63E5NoCyrRRuyPC0bkldQepsLTqCtJg5RvIyqAkwHdxvI85O8EmoXW
aziAHtJi/dtW6ZJuuqgI9DUB/5+y+afGuac3bkU3+eNohr5KtG433wdUiWusiXn5
k3hr1ahAtl/GQ+ciI+cewPY7u+edNeigb5Mqp+4kZAuGBTCcbGEH1ysar84ycnbC
Y+sK6rfLpjtBQrdxOLMXrJ6kOLi8if5JSOfkifwpPWBSoTgTpkBTqXqTRHrt3Jon
en0bs8TGauA9mVZrOrOHx0FuC5/OysZA+C14GVvwKq9PkGZA7b9tL9StUzTSJybc
0GXGXVPJQmr9/LgeR8Qg0ShPz2UL0n2NpEhiweTSz6D/iXTjX0LenenMv/zDJYk5
cAr5aBmebsjv+C86oZM/
Zobacz również: Konstruktor wyników
Usuwanie tagów z anchorów i snippetów
Dodaj Result Builders (Konstruktor wyników) i z listy rozwijanej wybierz źródło: $p1.serp.$i.anchor - Anchor. Wybierz typ: Remove HTML tags.
Dodaj ponownie Result Builders (Konstruktor wyników) i z listy rozwijanej wybierz źródło: $p1.serp.$i.snippet - Snippet. Wybierz typ: Remove HTML tags.
Pobierz przykład
Jak importować przykład do A-Parser
eJyVVD1v2zAQ/SsC4aEFBEMeumhzjLpp4cSp7UxGBlY6qawpkiUpN4bg/947mpaU
NAjQjby79+7rkR3z3B3cgwUH3rF83zETzixn2895/kXrWkKygUYfIbnd3a0Sz2uX
VFY3yVwVP7V1CVdlslXCGKJImeHWgSWy/YgDHSVUvJWepR3zJwOYAkmtFSU5RYl3
Y/XzyYK3AojpyGVLYbMsy9j5HRivodCt8gNm9k64FOrgDFiCjRDZ+ekpZdg91uiW
2jacpjAxs2kcSe/c8iPsNDorERq7YvB2zxtKOSm5B/JOq0D04ePUPxMDL0vhhVZc
XjLQmIasj0r8Dh0rjbF4pEEscdZo8hAIyHi6Vrdnk3BnSNEG7PcLhuUVlw5S5rDU
JcdCytce4cFyr+3aUD1o75hWcylXcAQ5hAX+m1bIEnc6rxD0NQLfDln/w3Hu2xun
wp38sVhDzxJuN+u7AVXqla6x8/IH9i1FIzze3SIsOmcZGg8App/ZPc2s0Rb6NJE5
ZkeRG1AkgGFlczOYXrTxYi0jY8ecbm2B+fZZumcodENbDS+BkX6i5mx4Mbe+keS2
lp/QGKM9SSdCSKZvMbrLe/ovyivmjJhCq0rU66j8azut2uFzX6uFbowEGr5qpUTt
ONgMGp67qBW6DFN8DV6EFLSf67vGMrR037aXeRorsKpPaSx8nDVSFlzKx81q7GGD
7oPmHdEW+JhqjTLHLqi5+MP0v1Y3/mfy7oza+eUeLkHUA4WgDYfhUBj0OfwFH/O5
UQ==
Konstruktor wyników można dodać tyle razy, ile jest potrzebne.
Zobacz również: Konstruktor wyników
Filtrowanie linków według występowania
Dodaj filtr i z listy rozwijanej wybierz: $serp.$i.link - Link. Wybierz typ: Contain string. Następnie w polu String (Ciąg) wpisz cechę filtrowania.
Pobierz przykład
Jak importować przykład do A-Parser
eJx9VE1v2kAQ/StoxSGVEIJDL74RVKpWNKSBnBCHDR5bG9Y72901DbL83zuzNrZJ
qtw8H+/Nm491JYL0J//owEPwItlXwsZvkYjttyT5jphrGK2UDuCUyUcvl5EP8UuZ
kVbmJCbCSufBMXo/AFEghUyWOohJJcLFAnHiGZxTKQdVSrZ1+HZxQIzgyXeWuuS0
+Ww2E/UnMJnDEUsTesz8k3TW6S04hg0QswEkix1SkLpnycleUE+WHLHJw6TN2DXp
RzRBKjOQPD1iQSbaoNCQ7cF4UR8OV0a/QldInuvYzqftkLvgVp5hh40O6N00d3iQ
BfOPUxmAo9MsEt19mYY3ZpBpqrim1E0F3kNf9dmoP1GfQcqlT570ypHWRASIBOy8
XNXtxTja3HEZsb8bjEgyqT1MhCepK0lC0vcRRfORAd0mzoD8lUCz0HoNZ9B9WuS/
L5VO6WgWGYF+tMD/p2w+cNRde8NStPS/jjR0LNG63/zqUSmuMafO05e42EIFsv0y
XlIiZuQ8AdhuZg88swIddGVa5rY6PRsLhi+sX9nC9q6bNm7Wcuuka8pUvmmv9ppZ
mh29zY1ZYmE1cF+m1JrW4uGpP4+Fb9fARi/wPXgZS3Dr1zcpAqL2P7eNVOsUnd9X
FljQJIdVW8qj1Pr5aT2MiP6k4jl5pj3SneZIF0Rd1Ifu79D9YqrhPyKpalrLq39s
krgHTiEfDcPHlzSv/wHtZp3U
Zobacz również: Filtry wyników
Możliwe ustawienia
Parametry regionalne
Google domain - używana domena Google, domyślnie google.com
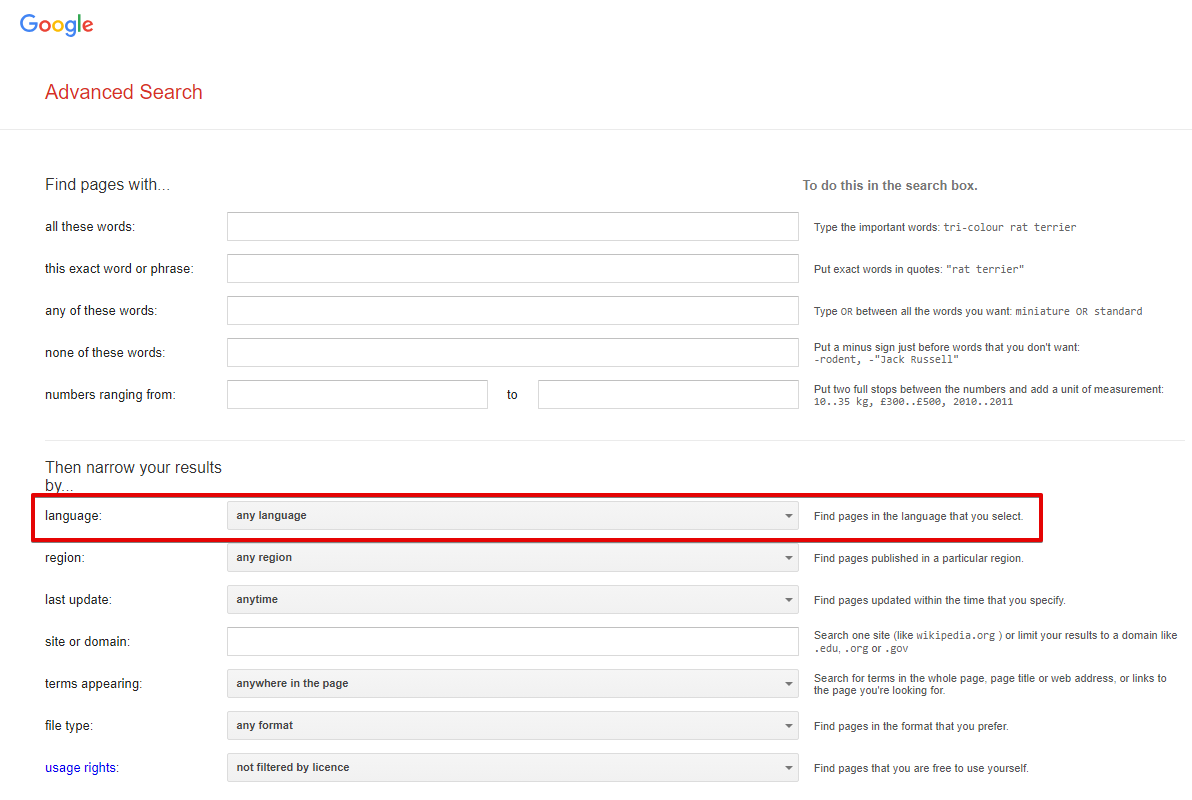
Results language - wyszukiwanie stron w wybranym języku, w przeglądarce odpowiada to opcji Wyszukiwanie zaawansowane -> Dodatkowe ustawienia -> Szukaj w (parametr url lr). Domyślnie nieustawione, co oznacza automatyczne wykrywanie na podstawie IP
Spoiler: Zrzut ekranu
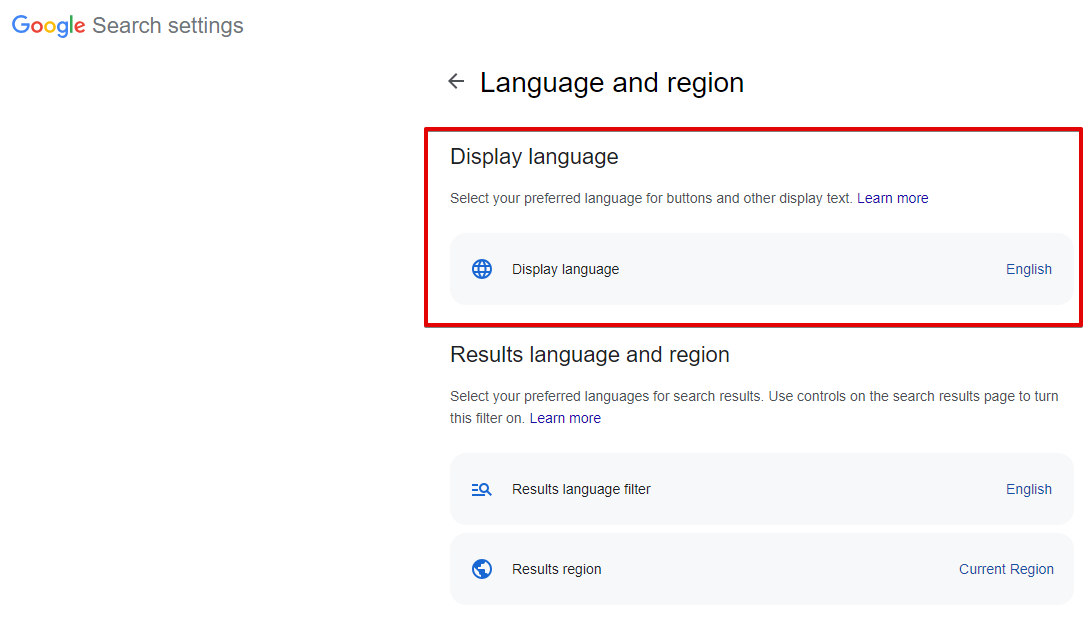
Interface language - język produktów Google, w przeglądarce to Języki -> Język interfejsu (parametr url hl). Domyślnie wybrany język angielski
Spoiler: Zrzut ekranu
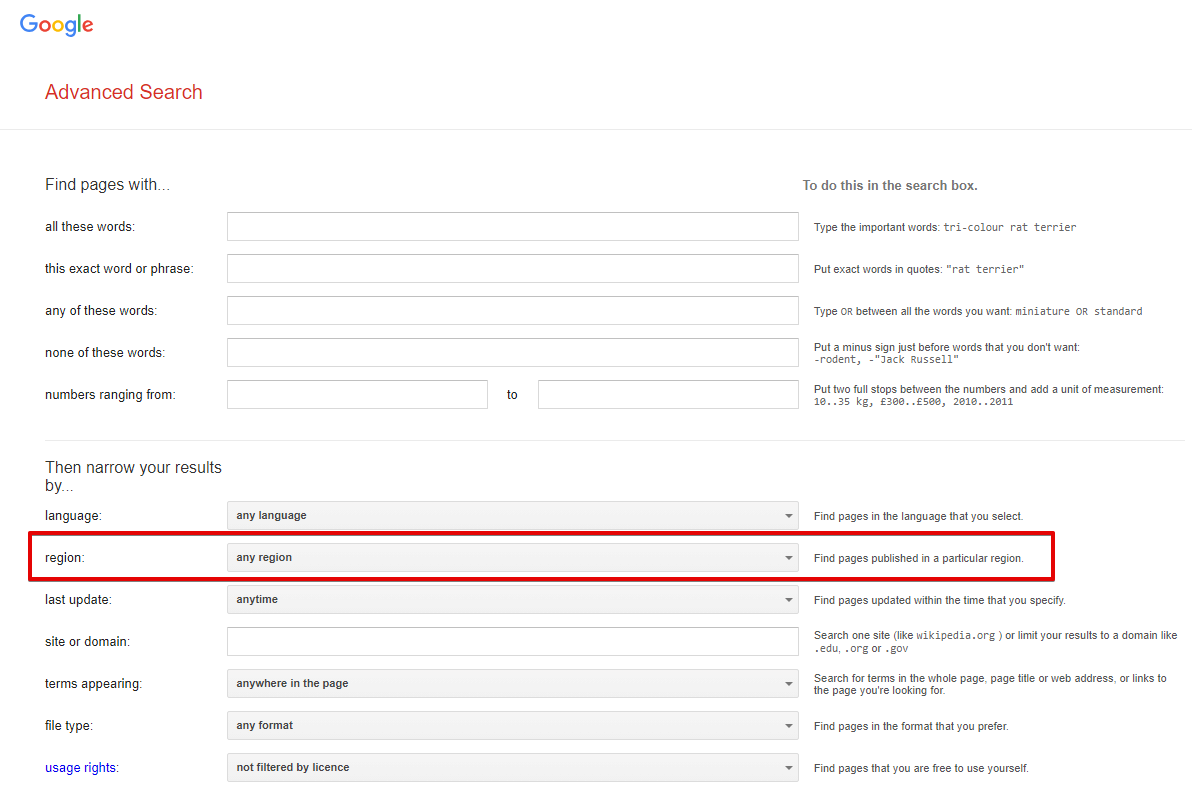
Search from country - wybór regionu wyszukiwania, w przeglądarce to Języki -> Region wyszukiwania (parametr url gl). Domyślnie nieustawione, co oznacza automatyczne wykrywanie na podstawie IP
Spoiler: Zrzut ekranu
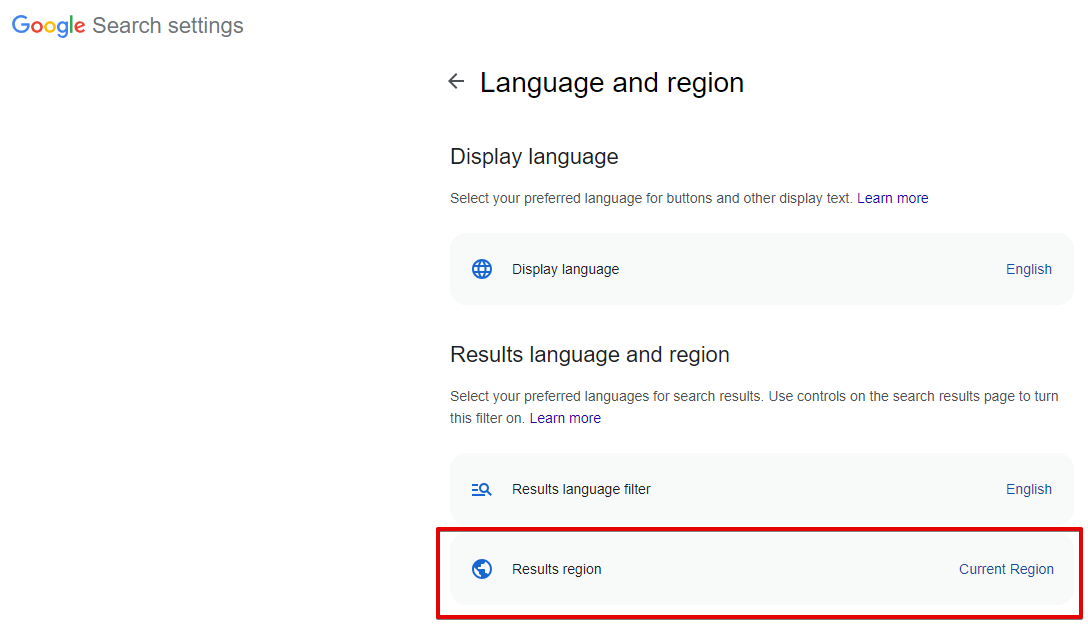
Narrow results by region - wyszukiwanie stron utworzonych w konkretnym kraju, w przeglądarce to Wyszukiwanie zaawansowane -> Dodatkowe ustawienia -> Kraj (parametr url cr). Domyślnie nieustawione, co oznacza wyłączenie tej opcji
Spoiler: Zrzut ekranu
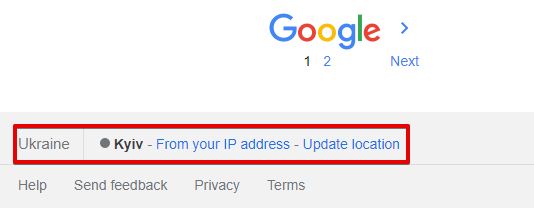
Location (city) - dokładna lokalizacja wyszukiwania, w przeglądarce określana automatycznie na podstawie lokalizacji użytkownika. Domyślnie nieustawione, co oznacza automatyczne określanie na podstawie IP zapytania
Spoiler: Zrzut ekranu
Wszystkie parametry regionalne w mniejszym lub większym stopniu wpływają na wyniki.
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Device | Desktop | Wybór wyników desktopowych lub mobilnych: Desktop / Mobile |
| Pages count | 5 | Liczba stron do scrapowania (od 1 do 100) |
| Parse pages links from first page | ☑ | Z pierwszej strony wyników zbiera linki do wszystkich dostępnych stron paginacji. Uwzględniane tylko przy Device: Desktop; nie działa dla wyników mobilnych |
| Serp type | Default (All) | Określa, czy scrapować ze strony głównej, z wiadomości czy z książek (Books, News, Videos) |
| Hide omitted results | ☑ | Określa, czy ukrywać pominięte wyniki (parametr filter=) |
| Serp time | Anytime | Czas SERP (wyszukiwanie zależne od czasu, parametr tbs=, możliwe wartości: Past 1 hour, Past 24 hours, Past week, Past month, Past year) |
| Parse not found | ☑ | Określa, czy scrapować wyniki, jeśli Google poinformował, że dla danego zapytania nic nie znaleziono i zaproponował wyniki dla innego zapytania |
| Disable autocorrect | ☐ | Pozwala wyłączyć autokorektę Google i scrapować wyniki dokładnie dla podanego zapytania |
| Exact match | ☐ | Odpowiada opcji w wyszukiwarce "Exact match". Uwaga, ta opcja nadpisuje wartość parametru Serp time (analogicznie do działania tych opcji w przeglądarce). |
| Safe search | Blur | Możliwość włączenia "Safe search" |
| Google domain | www.google.com | Domena Google do scrapowania, obsługiwane są wszystkie domeny (www.google.ac, www.google.com.af, www.google.co.ck itp.) |
| Narrow results by region | Any region | Możliwość zawężenia wyszukiwania do konkretnego kraju |
| Results language | Auto (Based on IP) | Wybór języka wyników (parametr lr=) |
| Search from country | Auto (Based on IP) | Wybór kraju, z którego realizowane jest wyszukiwanie (wyszukiwanie zależne od geolokalizacji, parametr gl=) |
| Interface language | English | Możliwość wyboru języka interfejsu Google, dla maksymalnej identyczności wyników w scraperze i w przeglądarce |
| Location (city) | Wyszukiwanie według miasta, regionu. Można podawać miasta w formacie novosibirsk, russia; pełną listę lokalizacji można znaleźć w Geotargets (kopia - należy użyć wartości z kolumny Canonical Name). Należy również ustawić poprawną domenę Google | |
| Util::ReCaptcha2 preset | default | Określa, czy używać  Util::ReCaptcha2 do omijania reCaptcha Util::ReCaptcha2 do omijania reCaptcha |
| Util::AntiGate preset | default | Określa, czy używać  Util::AntiGate do omijania graficznych captcha Util::AntiGate do omijania graficznych captcha |
| ReCaptcha2 retries | 3 | Liczba prób wysłania odpowiedzi dla reCaptcha określoną ilość razy, bez zmiany proxy |
| ReCaptcha2 pass proxy | ☐ | Pozwala przekazywać proxy (używane w zapytaniu do Google) oraz ciasteczka (otrzymane w odpowiedzi od Google) do serwisu rozpoznawania ReCaptcha |
| Use sessions | ☑ | Zapisuje dobre sesje, co pozwala na jeszcze szybsze scrapowanie przy mniejszej liczbie błędów. |
| Don't take session | ☐ | Możliwość nieużywania zapisanych dobrych sesji |
| Additional headers | Pozwala na podanie dowolnych własnych nagłówków | |
| PAA questions count | 0 | Maksymalna liczba pytań i odpowiedzi (People also ask) dla każdego zapytania, które scraper powinien zebrać |
| Empty totalcount is error | ☐ | Przy włączeniu tego parametru zapytanie zostanie uznane za nieudane, jeśli brakuje wartości dla $totalcount, i odpowiednio będą podejmowane ponowne próby |
| Count of retries when result is empty | 10 | Liczba ponownych prób zapytania, jeśli strona wyników jest całkowicie pusta |
| Redirect browser max pages | 10 | Liczba stron przeglądarki używanych do omijania zabezpieczeń w formie sprawdzania włączonego JavaScript |
| Single redirect browser for task | ☑ | Jeśli w zadaniu wskazano kilka scraperów Google — używaj tylko jednej przeglądarki dla wszystkich podzadań; maksymalna liczba stron i pozostałe ustawienia są pobierane z pierwszego scrapera Google w zadaniu |