Perguntas Frequentes
1. Perguntas relacionadas a demonstração, pagamento e compra
1.1. Como baixar os resultados na versão Demo?
Na versão Demo, os resultados do trabalho não estão disponíveis para download. Nós os fornecemos mediante solicitação. Envie suas consultas e diga qual scraper lhe interessa, e nós lhe enviaremos os resultados (dentro da demo, a quantidade é limitada).
1.2. É necessário pagar algo a mais após a compra do A-Parser?
Não. Mais detalhes: licenças e complementos, página de compra.
1.3. Onde e como posso pagar pelos proxies?
Ao comprar uma licença, você recebe proxies de bônus.
Lite - 20 threads por 2 semanas, Pro e Enterprise - 50 threads por um mês.
Você pode comprar mais threads ou renovar na Área de Membros na aba Loja, subseção Proxy.
1.4. Você poderia configurar uma tarefa para mim por dinheiro?
O suporte técnico para questões relacionadas ao funcionamento do A-Parser é fornecido gratuitamente. Para ajuda paga na criação de tarefas, você pode entrar em contato aqui: Serviços pagos para criação de tarefas, ajuda com configuração e treinamento no A-Parser.
1.5. Posso efetuar o pagamento pelo scraper via banco Privat24? Via KIWI?
A lista de sistemas de pagamento com os quais trabalhamos está indicada aqui: comprar A-Parser.
1.6. Se eu precisar extrair apenas a quantidade de páginas indexadas no Yandex, qual scraper é melhor eu comprar?
Para esses fins, a versão Lite é suficiente, mas a Pro é mais prática e flexível no trabalho.
1.7. Onde ver as informações sobre minha licença?
1.8. É possível usar os proxies comprados de vários IPs?
Não.
2. Perguntas sobre instalação, inicialização e atualizações
2.1. Clico no botão Download - mas o arquivo não baixa. O que fazer?
Verifique se você tem espaço livre no disco rígido, desative o antivírus. Siga as instruções de instalação. Além disso, consulte Como começar a trabalhar.
2.2. Comprei a versão Enterprise, mas continua instalando a PRO. O que fazer?
Remova a versão anterior. Na Members Area, verifique se o seu endereço IP está configurado corretamente. Antes de baixar, clique no botão Update (Atualizar). Baixe a versão mais recente. Mais detalhes nas instruções de instalação.
2.3. Instalei o programa, mas ele não inicia, o que fazer?
Verifique os aplicativos em execução, desative o antivírus, verifique o volume disponível de memória RAM livre. Também na Área de Membros, verifique se o seu endereço IP está configurado corretamente. Mais detalhes: instruções de instalação.
2.4. O que fazer se eu tiver um endereço IP dinâmico?
Não se preocupe, o A-Parser suporta o trabalho com endereços IP dinâmicos. Basta que, toda vez que ele mudar, você precise configurá-lo na Members Area. Para evitar essas manipulações, recomenda-se usar um endereço IP estático.
2.5. Quais são os parâmetros ideais de servidor ou computador para instalar o scraper?
Todos os requisitos do sistema podem ser vistos aqui: requisitos do sistema.
2.6. Iniciei a tarefa. O scraper caiu e não inicia mais, o que fazer?
É necessário parar o servidor, verificar se o processo não está travado na memória e tentar iniciar novamente. Também é possível tentar iniciar o A-Parser com a parada de todas as tarefas. Para isso, você deve iniciar com o parâmetro -stoptasks. Detalhes sobre a inicialização com parâmetro.
2.7. Qual senha inserir ao abrir o endereço 127.0.0.1:9091?
Se for a primeira inicialização, a senha está vazia. Se não for a primeira - então aquela que você definiu. Se esqueceu a senha - redefinição de senha.
2.8. Na Área de Membros insiro meu IP, mas ele não muda no campo Seu IP atual. Por quê?
O campo Your current IP (Seu IP atual) exibe o IP que é válido para você agora, e ele não deve mudar. É este que você deve inserir no campo IP 1.
2.9. Posso iniciar duas cópias simultaneamente?
Iniciar duas cópias na mesma máquina só é possível se elas tiverem portas diferentes configuradas no arquivo de configuração.
Iniciar dois A-Parser em máquinas diferentes simultaneamente só é possível se você tiver adquirido um IP adicional na Área de Membros.
2.10. O scraper tem vinculação ao hardware?
Não. Para o controle de licenças, é utilizado o seu IP.
2.11. Pergunta sobre atualização - atualizar apenas o .exe? config/config.db e files/Rank-CMS/apps.json - para que servem esses arquivos?
A menos que seja indicado o contrário, atualize apenas o .exe. O primeiro arquivo é para armazenar a configuração do A-Parser, e o segundo é a base para determinar o CMS e o funcionamento propriamente dito do scraper ![]() Rank::CMS.
Rank::CMS.
2.12. Eu tenho Win Server 2008 Web Edition - o scraper não inicia...
Nesta versão do SO, o A-Parser não funcionará. A única opção é mudar o SO.
2.13. Eu tenho um processador de 4 núcleos. Por que o A-Parser usa apenas um núcleo?
O A-Parser utiliza de 2 a 4 núcleos; núcleos adicionais são usados apenas durante a filtragem, no Construtor de resultados e no Parse custom result.
2.14. Começou a aparecer um erro de segmentação (segmentation failed, segmentation error). O que fazer?
Provavelmente o seu IP mudou. Verifique na Área de Membros.
2.15. Eu tenho Linux. O A-Parser iniciou, mas não abre no navegador. Como resolver?
Verifique o firewall - provavelmente ele está bloqueando o acesso.
2.16. Eu tenho Windows 7. O A-Parser iniciou, mas não abre no navegador e não há processo Node.js no gerenciador de tarefas. Como resolver?
Você precisa verificar as atualizações do Windows e instalar as últimas disponíveis. Especificamente, você precisa da atualização do Windows 7 SP1.
2.17. O A-Parser não inicia e no aparser.log aparece o erro FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20.
Provavelmente ocorre um problema com alguma tarefa (pasta /config/tasks/), devido a um erro de disco (por exemplo, se a energia do PC foi desligada sem o encerramento correto), mais detalhes podem ser obtidos se você iniciar o A-Parser com a flag -morelogs
Solução: iniciar o A-Parser com o parâmetro -stoptasks. Se não ajudar, limpe todo o /config/tasks/. Se mesmo depois disso o problema não for resolvido, instale o scraper novamente em um novo diretório e coloque o config do antigo (se não estiver corrompido).
3. Perguntas sobre a configuração do A-Parser e outras configurações
3.1. Como configurar o verificador de proxy?
A instrução detalhada está aqui: configuração de proxy.
3.2. Não há proxies ativos - por quê?
Verifique sua conexão com a internet, bem como a correção da configuração do verificador de proxy. Se tudo foi feito corretamente, isso significa que, no momento, sua lista de proxies não contém servidores funcionais. Solução para este problema: ou usar outros proxies, ou tentar novamente mais tarde. Se você usa nossos proxies, verifique o endereço IP na Área de Membros na seção Proxies (Proxy). Também é possível que seu provedor esteja bloqueando o acesso a outros DNS; tente seguir os passos descritos aqui: http://a-parser.com/threads/1240/#post-3582
3.3. Como conectar o antigate?
A instrução detalhada sobre a configuração do antigate está aqui.
3.4. Alterei os parâmetros nas configurações do scraper, mas eles não foram aplicados. Por quê?
O preset padrão (default) não pode ser alterado; se alguma alteração for feita, você deve clicar em Save as New Preset (Salvar como novo preset) e, depois disso, usá-lo em sua tarefa.
3.5. É possível alterar as configurações de uma tarefa em execução?
Pode, mas não todas. Em uma tarefa em execução, você pode clicar em pausar e, no mesmo menu suspenso, escolher Edit (Editar).
3.6. Como importar um preset?
Clique no botão ao lado do campo de seleção de tarefa no Editor de tarefas. Detalhes aqui.
3.7. Como configurar o scraper para que ele não use proxy?
Nas configurações do scraper desejado, desmarque a opção Use proxy.
3.8. Eu não tenho o botão Adicionar sobreposição / Override option!
Esta opção pode ser adicionada diretamente no Editor de tarefas. Opções do scraper.
3.9. Como sobrescrever no mesmo arquivo de resultados?
Ao criar a tarefa, selecione a opção Overwrite file (Sobrescrever arquivo).
3.10. Onde mudar a senha do scraper?
3.11. Coloquei 6 milhões de chaves para extração, também indiquei que todos os domínios fossem únicos. Como fazer para que, quando eu colocar novos 6 milhões de chaves, sejam gravados apenas domínios únicos que não se cruzem com a extração anterior?
É necessário utilizar a opção Keep unique (Salvar desduplicação) ao criar a primeira tarefa e indicar a base salva na segunda. Detalhes em Opções adicionais do editor de tarefas.
3.12. Como contornar o limite de 1000 resultados para o Google?
Utilize a opção Parse all results.
3.13. Como contornar o limite de 1024 threads no Linux?
3.14. Qual é o limite de threads no Windows?
Até 10.000 threads.
3.15. Como tornar as consultas únicas?
Use a opção Unique queries (Consultas únicas) no bloco Queries (Consultas) no Editor de tarefas.
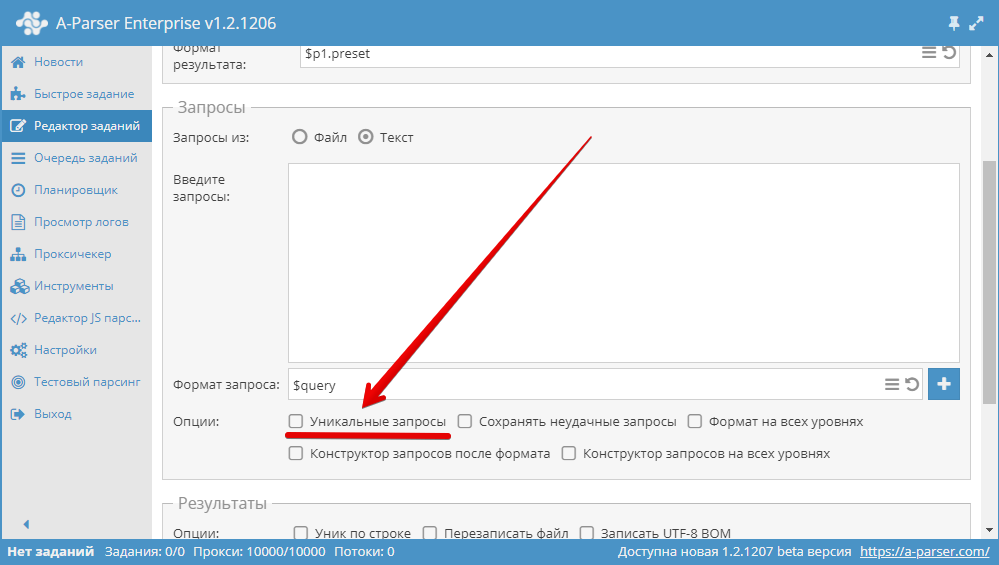
3.16. Como desativar a verificação de proxies?
Em Configurações - Configurações do verificador de proxy, escolha o verificador de proxy desejado e marque a opção No check proxies (Não verificar proxies). Salve e escolha o preset salvo.
3.17. O que é Proxy ban time? Posso colocar 0 nele?
Tempo de banimento do proxy em segundos. Sim, você pode.
3.18. Qual é a diferença entre Exact Domain e Top Level Domain no scraper  SE::Google::Position
SE::Google::Position
Exact Domain é uma correspondência estrita, ou seja, se nos resultados aparecer www.domain.com e estivermos procurando por domain.com, não haverá correspondência. Top Level Domain verifica todo o domínio de topo, ou seja, aqui haverá correspondência.
3.19. Se eu iniciar uma extração de teste - tudo funciona, se for uma comum - recebo o erro Some error.
Provavelmente o problema é no DNS, tente seguir esta instrução de configuração de DNS.
3.20. Onde é definido o Formato do resultado?
Ao formatar o resultado, use \n. Exemplo:
3.21. No  SE::Google falta o idioma holandês, embora ele esteja presente nas configurações do Google. Por quê?
SE::Google falta o idioma holandês, embora ele esteja presente nas configurações do Google. Por quê?
O idioma holandês é o Dutch, ele está na lista. Detalhes na melhoria sobre a adição do idioma holandês.
4. Perguntas sobre extração de dados e erros durante a extração
4.1. O que são threads?
Todos os processadores modernos podem executar tarefas em múltiplas threads, o que aumenta significativamente a velocidade de sua execução. Para comparação, pode-se citar um ônibus comum, que transporta uma certa quantidade de pessoas por unidade de tempo - isso seria um processamento comum, de thread única, e um ônibus de dois andares, que transporta o dobro de pessoas no mesmo tempo - isso seria o processamento em múltiplas threads. O A-Parser pode processar simultaneamente até 10.000 threads.
4.2. A tarefa não inicia - diz Some Error - por quê?
Verifique o endereço IP na Área de Membros.
4.3. Todas as consultas vão para malsucedidas, o que fazer?
Provavelmente a tarefa foi configurada incorretamente ou está sendo usado um formato de consulta inválido. Verifique também se existem proxies ativos. Além disso, você pode tentar aumentar a opção Request retries (detalhes aqui: requisições malsucedidas).
4.4. Quantas contas precisam ser registradas para extrair 1.000.000 de palavras-chave com o  SE::Yandex::Wordstat?
SE::Yandex::Wordstat?
Não é possível dizer exatamente quantas contas são necessárias, pois uma conta pode deixar de ser válida após um número desconhecido de consultas. Mas você sempre pode registrar novas contas usando o scraper  SE::Yandex::Register ou simplesmente adicionar contas existentes ao arquivo files/SE-Yandex/accounts.txt.
SE::Yandex::Register ou simplesmente adicionar contas existentes ao arquivo files/SE-Yandex/accounts.txt.
4.5. A tarefa não inicia, diz Error: Lock 100 threads failed(20 of limit 100 used) o que fazer?
É necessário aumentar o número máximo de threads disponíveis nas configurações do scraper, ou diminuí-lo nas configurações da tarefa. Detalhes em Configurações.
4.6. É possível iniciar 2 tarefas simultaneamente?
Sim, o A-Parser suporta a execução de várias tarefas simultaneamente. O número de tarefas em execução simultânea é regulado em Configurações - Configurações Gerais: Máximo de tarefas ativas.
4.7. Onde fica o arquivo com os resultados?
Na aba Tasks Queue (Fila de tarefas), após o término de cada tarefa, você pode baixar os resultados do trabalho. Fisicamente, eles estão localizados na pasta results.
4.8. É possível baixar o arquivo de resultados se a extração não terminou?
Não, enquanto a extração de dados não estiver concluída, os resultados não podem ser baixados. Mas eles podem ser copiados da pasta aparser/results com a tarefa parada ou em pausa.
4.9. É possível com o seu scraper extrair 1.000.000 de links por uma única consulta?
Sim, usando a opção Extrair todos os resultados / Parse all results.
4.10. É possível usar os scrapers  Rank::CMS,
Rank::CMS,  Net::Whois sem proxy?
Net::Whois sem proxy?
Net::Whois - não é aconselhável.4.11. Como extrair links do Google?
É necessário utilizar o SE::Google.
4.12. O scraper pode navegar pelos links?
Sim, o scraper  HTML::LinkExtractor pode fazer isso ao usar a opção Extrair até o nível / Parse to level
HTML::LinkExtractor pode fazer isso ao usar a opção Extrair até o nível / Parse to level
4.13. O Google extrai dados muito lentamente, o que fazer?
Primeiro, você deve verificar os logs da tarefa; talvez todas as consultas tenham falhado. Se for esse o caso, você precisa encontrar o motivo pelo qual as consultas falharam e corrigi-lo. Ao realizar a extração de dados com o SE::Google, as tentativas malsucedidas nos logs da tarefa geralmente estão relacionadas ao fato de o Google exibir captchas, o que é normal. Você pode conectar o Antigate para contornar captchas, para que o scraper não fique repetindo tentativas.
Além disso, há um artigo que descreve os fatores que afetam a velocidade da extração de dados e como eles influenciam: velocidade e princípio de funcionamento dos scrapers.
4.14. É possível com o seu scraper extrair links nos quais o texto está apenas em japonês?
Sim, para isso é necessário definir o idioma desejado nas configurações do scraper e também utilizar palavras-chave em japonês.
4.15. É possível com o seu scraper extrair links apenas na zona de domínio .de ou .ru?
Sim. Para isso, você deve utilizar um filtro.
4.16. Como obter cada resultado no arquivo em uma nova linha?
Ao realizar a formatação do resultado, utilize \n. Exemplo:
$serp.format('$link\n')
4.17. Como extrair o top 10 de sites do Google?
Aqui está o preset:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. Adiciono uma tarefa, vou para a aba Fila de tarefas - e ela não está lá! Por quê?
Ou foi cometido um erro ao criar a tarefa, ou ela já foi concluída e movida para Completed (Concluídas).
4.19. Diz que o arquivo não está em utf-8, mas eu não o mudei, ele já é utf-8, o que fazer?
Verifique novamente. Tente também alterar a codificação, por exemplo, usando o Notepad++.
4.20. No arquivo de resultados está tudo em uma linha, embora na tarefa eu tenha colocado quebra de linha - por quê?
Nas configurações adicionais do A-Parser, você deve usar a quebra de linha CRLF (Windows).
Mas se você já realizou a extração sem essa opção, use um visualizador mais avançado para visualizar, como o Notepad++.
4.21. Quanto tempo leva para verificar a frequência de consultas no Yandex para 1.000 consultas?
Este indicador depende muito dos parâmetros da tarefa, das características do servidor, da qualidade dos proxies, etc., portanto, não é possível dar uma resposta definitiva.
4.22. Como configuro o scraper para que o resultado seja consulta-link?
Formato do resultado:
$p1.serp.format('$query: $link\n')
O resultado será:
consulta: link 1
consulta: link 2
consulta: link 3
4.23. Como reprocessar consultas malsucedidas e onde elas são armazenadas?
Para que as consultas malsucedidas sejam salvas, você deve selecionar a opção correspondente no bloco Queries (Consultas) no Editor de tarefas. As consultas malsucedidas são armazenadas em queries\failed. Você deve criar uma nova tarefa e especificar o arquivo com as consultas malsucedidas como o arquivo de consultas.
4.24. Como se livrar das tags HTML ao extrair texto?
Utilize a opção Remove HTML tags no Construtor de resultados.
4.25. Como fazer para que sejam extraídos apenas domínios?
Utilize a option Extract Domain no Construtor de resultados.
4.26. Qual é o tamanho máximo do arquivo de consultas que pode ser usado no scraper?
Os tamanhos dos arquivos de consultas e resultados não são limitados e podem atingir valores em terabytes.
4.27. Por que, quando insiro texto no campo de consultas, o scraper exibe Queries length limited to 8192 characters?
Isso acontece porque o comprimento da consulta é limitado a 8192 caracteres. Para usar consultas mais longas, utilize arquivos como consultas.
4.28. O que significa Threads aguardando - 3?
Isso significa que faltam proxies. Reduza o número de threads ou aumente o número de proxies.
4.29. Na extração de teste diz 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) e não extrai, por quê?
Isso indica proxies que não estão funcionando.
4.30. Qual é a diferença entre o idioma dos resultados e o país de busca no scraper do Google?
A diferença é a seguinte: o país de busca é a vinculação dos resultados a um país específico. Por exemplo, se você pesquisar comprar janelas com vinculação a um país específico, os sites que oferecem comprar janelas exatamente nesse país terão prioridade. E o idioma dos resultados é em qual idioma os resultados devem ser exibidos.
4.31. Um determinado site não está sendo extraído. O que pode ser?
Frequentemente, o problema é que ocorre um bloqueio devido a um user-agent antigo no lado do servidor. Isso é resolvido com um novo user-agent ou com o seguinte código no parâmetro User agent:
[% tools.ua.random() %]
4.32. O scraper trava, fecha. No log aparece a linha syswrite: No space left on device
O A-Parser está sem espaço no disco rígido. Libere mais espaço.
4.33. O scraper começou a retornar none nos resultados (ou um resultado claramente incorreto)
4.34. Constantemente aparece uma janela com a mensagem Failed fetch news
4.35. Como exibir os n primeiros resultados da busca?
4.36. Como rastrear a cadeia de redirecionamentos?
4.37. Como verificar a indexação de um link no doador?
Para tais fins, existe um scraper separado:  Check::BackLink.
Detalhes na discussão.
Check::BackLink.
Detalhes na discussão.
4.38. O scraper fecha no Linux. No log há este registro: EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Provavelmente você precisa ajustar o número de threads, conforme descrito na Documentação: Ajuste do Linux para um maior número de threads.
4.39. Onde posso ver todos os parâmetros possíveis para uso via API?
Obtendo uma requisição de API na interface.
Além disso, você pode gerar a configuração completa da tarefa em JSON. Para isso, você deve pegar o código da tarefa e decodificá-lo de base64.
4.40. Estou baixando imagens usando o  Net::HTTP, mas por algum motivo elas estão todas corrompidas. O que fazer?
Net::HTTP, mas por algum motivo elas estão todas corrompidas. O que fazer?
1) Verifique o parâmetro Max body size - talvez seja necessário aumentá-lo. 2) Verifique nas configurações do A-Parser o formato de quebra de linha: Configurações Adicionais - Quebra de linha.
Para que a imagem não fique corrompida, deve ser usado o formato UNIX.
4.41. Como obter o admin contact do WHOIS?
Tal tarefa é facilmente resolvida usando a função Parse custom result e uma expressão regular. Detalhes na discussão.
4.42. Expressão regular para extração de telefones
4.43. Identificação de sites sem versão móvel
4.44. Como descobrir o nome do servidor NS?
4.45. Como extrair links do cache do Yandex?
4.46. Como extrair links de todas as páginas de um site?
4.47. Como extrair o title de uma página?
4.48. Como extrair todos os sites em uma determinada zona de domínio?
4.49. Como coletar todas as URLs com parâmetros?
4.50. Como filtrar resultados por vários critérios e dividi-los no relatório?
4.51. Como simplificar a construção do filtro?
4.52. Como ordenar por arquivos dependendo do resultado?
4.53. Create new result directory every X number of files (English)
4.54. Primeiros passos no trabalho com o WordStat
4.55. Coleta de blocos de texto >1000 caracteres
4.56. Exibição de uma certa quantidade de texto de uma página
Isso também é resolvido com a ajuda do Template Toolkit. Detalhes na discussão.
4.57. Verificação de concorrência e ocorrência no título no Google
4.58. Filtragem pela quantidade de ocorrências da consulta na âncora e no snippet
4.59. Como obter o conteúdo de um artigo em uma única linha?
4.60. Como comparar duas datas em formato de string?
4.61. Como extrair palavras destacadas do snippet?
4.62. Exemplo de tarefa usando vários scrapers
4.63. Como embaralhar linhas no resultado e como exibir uma quantidade aleatória de resultados?
4.64. Como assinar o resultado usando MD5?
4.65. Como converter uma data de Unix timestamp para representação em string?
4.66. Parse to level, como extrair dados com limitação?
4.67. O scraper cai no Linux ao iniciar uma tarefa. No log há estas linhas: Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
É necessário executar o comando no console:
apt-get --reinstall --purge install netbase
4.68. Erro Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
Você deve iniciar o A-Parser sem ser como root. Especificamente: a partir do usuário root, você deve criar um novo usuário sem privilégios de root (se já existir um, basta usá-lo) e depois permitir que este usuário interaja com o diretório do A-Parser, em seguida, você deve fazer login com o novo usuário e iniciá-lo a partir dele.
Sob o usuário root, crie um usuário, você pode seguir este guia.
Para permitir que o usuário criado interaja com o diretório do A-Parser, você deve dar permissões ao usuário. Para isso, entre com o usuário root e dê as permissões com o comando:
chown -R user:user aparser
4.69. Erro Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Sob o usuário root, execute o comando:
sysctl -w kernel.unprivileged_userns_clone=1
Não é necessário reiniciar o A-Parser.
Para o CentOS 7, a solução está neste tópico.
Sob o usuário root, execute o comando:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Em seguida, reinicie o sysctl com o comando:
sysctl -p
4.70. Erro JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
O erro ocorre devido à falta de bibliotecas no SO para o funcionamento do Chrome.
A lista das bibliotecas necessárias para o funcionamento do Chrome pode ser encontrada em Chrome headless doesn't launch on UNIX.
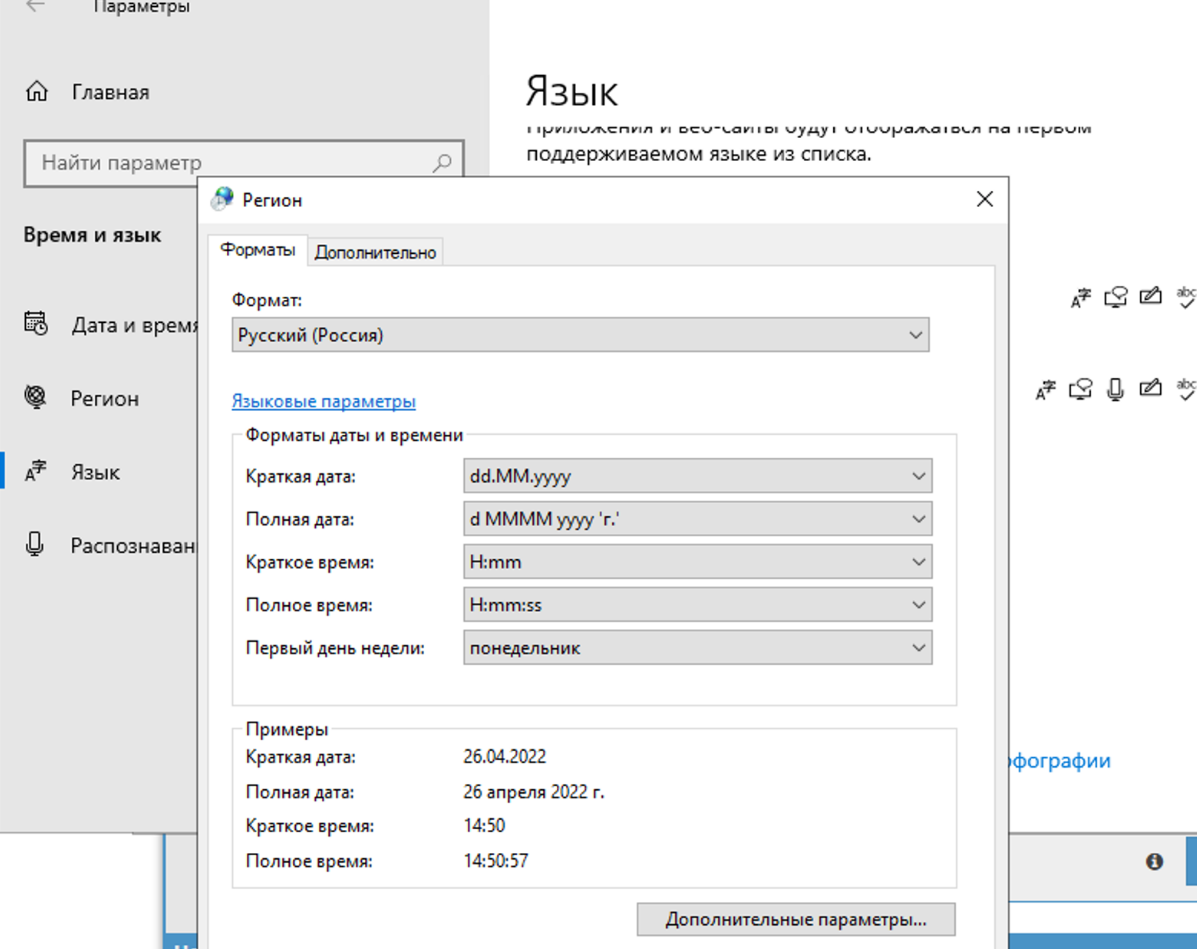
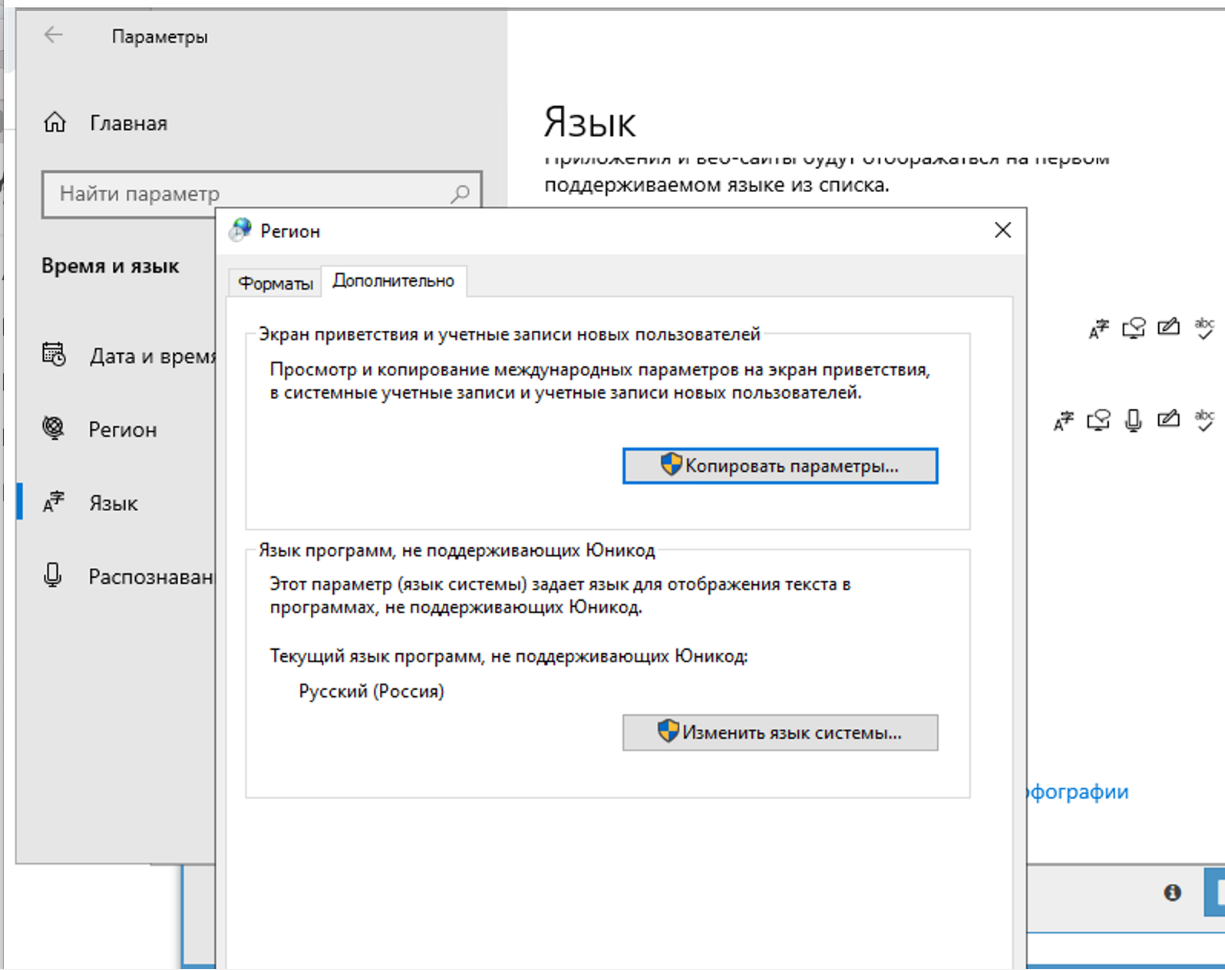
4.71. Por que o captcha não é resolvido? No log vê-se que o A-Parser recebeu pontos de interrogação do Xevil em vez da resposta do captcha
Nas configurações de região, você deve mudar para russo.
Você deve mudar apenas na aba avançado. Isso não afeta a resolução de captchas, mas no próprio Xumer haverá um problema com a codificação se você mudar em ambos os lugares.