Desduplicação de resultados
Desduplicação, remoção de duplicatas, remoção de repetições - tudo isso implica que não precisamos de resultados repetidos. No A-Parser, existem 2 métodos de desduplicação, vamos analisar cada um detalhadamente.
Desduplicação de resultados por linha
Este método funciona após a formatação do resultado; imediatamente antes de gravar o resultado no arquivo, cada linha é verificada quanto à unicidade e apenas novas linhas únicas são gravadas no arquivo.
Veja também: Ordem de processamento de consultas
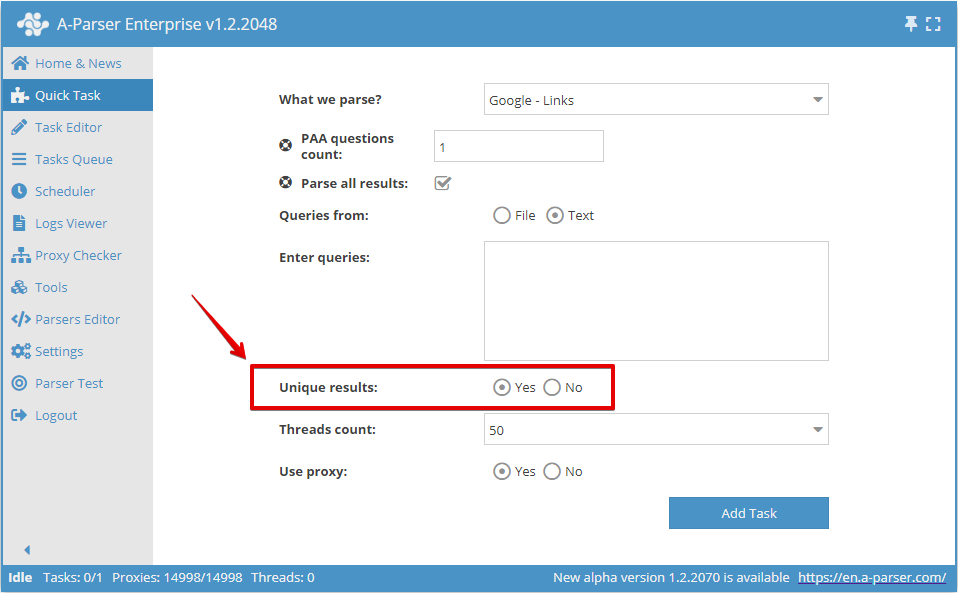
Você pode ativar a unicidade por linha na Tarefa Rápida:
Ou no Editor de Tarefas:
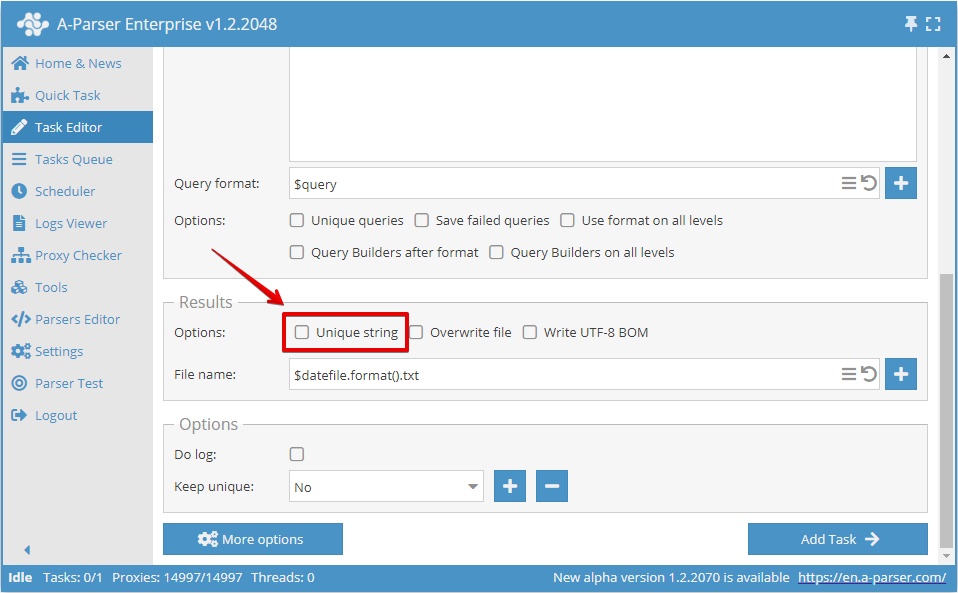
Desduplicação por qualquer resultado
A desduplicação por qualquer resultado permite realizar a desduplicação diretamente no resultado selecionado de um scraper específico. Você pode adicionar este tipo de desduplicação no Editor de Tarefas, clicando no ícone de ferramenta à direita do scraper e selecionando Add unique result (Adicionar desduplicação):
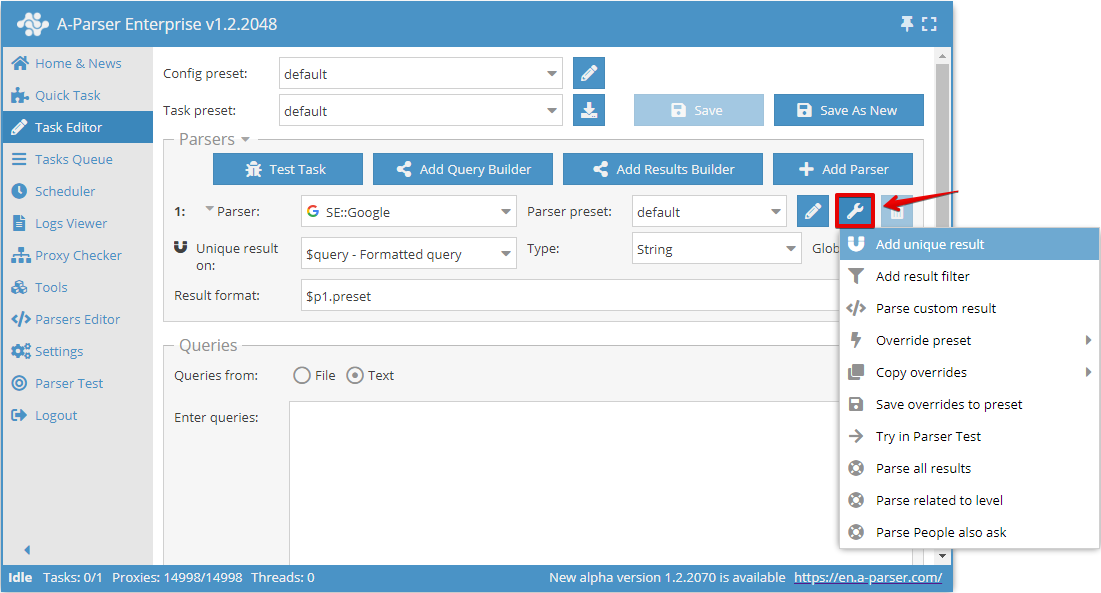
Agora você pode escolher em qual resultado aplicar a desduplicação e o tipo de desduplicação:
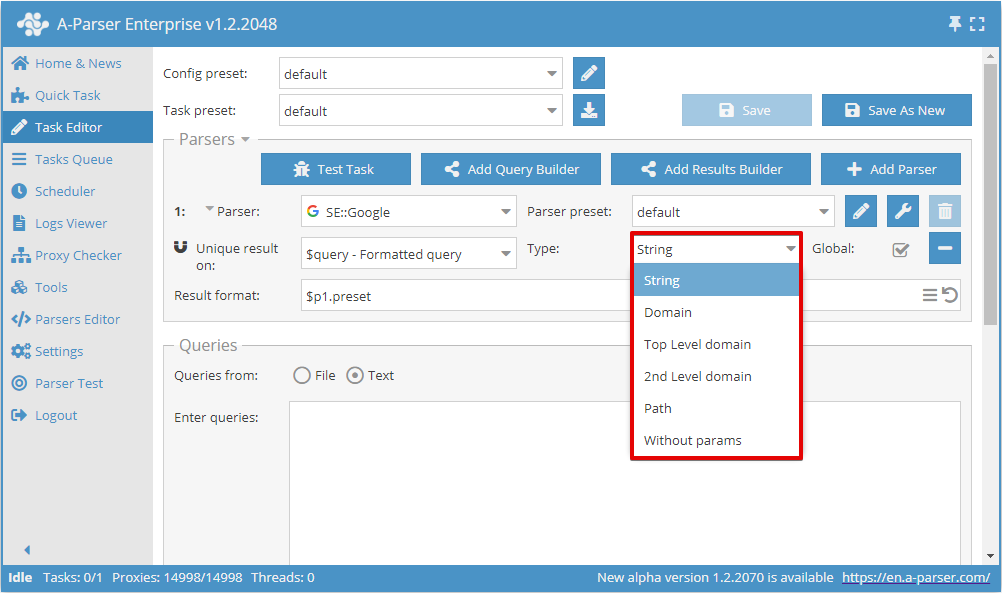
A opção Global (Globalmente) é utilizada quando 2 ou mais scrapers são selecionados; ela define se deve ser feita uma desduplicação geral ou individual para cada scraper.
Tipos de desduplicação
| Parâmetro | Descrição |
|---|---|
| String | Desduplicação por linha (toda a linha do resultado é comparada integralmente) |
| Domain | Desduplicação por domínio (o domínio é comparado integralmente, por exemplo, www.domain.com e domain.com são domínios diferentes) |
| Top Level domain | Desduplicação pelo domínio principal, considerando domínios regionais, comerciais, educacionais e outros (por exemplo, domain.co.uk e domain2.co.uk são domínios diferentes, enquanto sub1.domain.com e sub2.domain.com são iguais) |
| Domínio de 2º nível | Desduplicação por domínio de segundo nível (compara domínios de segundo nível, por exemplo, www.domain.com, domain.com e user.subdomain.domain.com são todos o mesmo domínio) |
| Path | Desduplicação por caminho (compara as partes do link até o arquivo, por exemplo, http://domain.com/path1/file.php e http://domain.com/path1/file2.php são partes iguais do link até o arquivo) |
| Without params | Desduplicação por link sem parâmetros (compara links sem parâmetros, por exemplo, http://domain.com/file.php?page=1 e http://domain.com/file.php?page=2 são links iguais) |
Desduplicação de consultas
A desduplicação de consultas envia para a extração de dados apenas consultas únicas que não foram processadas anteriormente na tarefa atual. Principais casos de uso:
- Se houver duplicatas nas consultas de origem e não for desejável processá-las (trabalho duplo)
- Ao usar a opção Parse to level (Extrair até o nível), é necessário usar apenas consultas únicas para evitar o crescimento excessivo e o loop de consultas (por exemplo, ao usar o scraper
 HTML::LinkExtractor)
HTML::LinkExtractor)
Em todos os outros casos, o uso desnecessário da desduplicação de consultas apenas tornará a operação geral do scraper mais lenta
Salvar estado de desduplicação entre tarefas
Existe a possibilidade de salvar a base de desduplicação para uso em tarefas futuras, o que permite salvar apenas novos resultados únicos em novas tarefas (por exemplo, links ao realizar a extração de dados da SERP no  SE::Google)
SE::Google)
Para salvar a base de desduplicação, é necessário criar um novo nome de base ao adicionar a primeira tarefa:
Para todas as tarefas subsequentes, deve-se selecionar o nome da base criado anteriormente; assim, apenas novos resultados únicos serão salvos, independentemente de os resultados estarem sendo gravados no mesmo arquivo da primeira tarefa ou em um novo arquivo.