Net::HTTP - Universell bas-scraper med stöd för flersidig dataskrapning och kringgående av CloudFlare
Översikt av scrapern
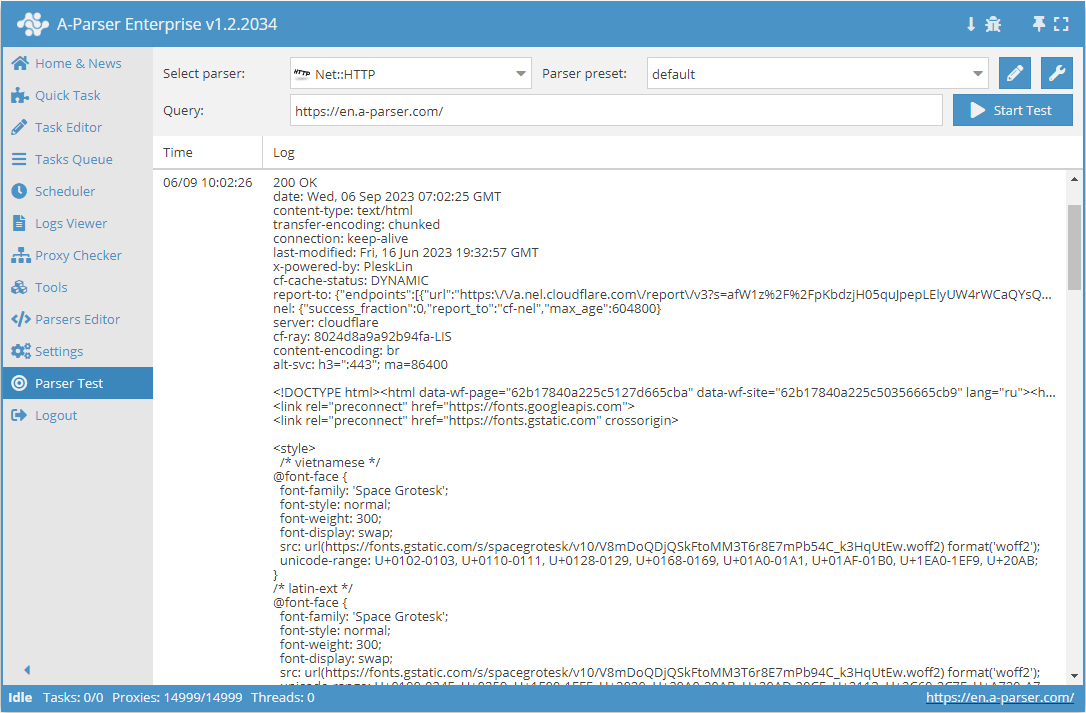
 Net::HTTP – är en universell scraper som gör det möjligt att lösa de flesta icke-standardiserade uppgifter. Den kan användas som bas för dataskrapning av godtyckligt innehåll från vilka webbplatser som helst. Den tillåter nedladdning av sidkod via länk, stöder flersidig dataskrapning (navigering mellan sidor), automatisk hantering av proxy och gör det möjligt att kontrollera om svaret lyckades baserat på kod eller sidinnehåll.
Net::HTTP – är en universell scraper som gör det möjligt att lösa de flesta icke-standardiserade uppgifter. Den kan användas som bas för dataskrapning av godtyckligt innehåll från vilka webbplatser som helst. Den tillåter nedladdning av sidkod via länk, stöder flersidig dataskrapning (navigering mellan sidor), automatisk hantering av proxy och gör det möjligt att kontrollera om svaret lyckades baserat på kod eller sidinnehåll.Användningsfall för scrapern
🔗 Domänauktion REG.RU
Dataskrapning av auktioner för utgående domäner med filtreringsmöjligheter
🔗 Data för SSL-certifikat
Dataskrapning av SSL-certifikatdata för domäner från webbplatsen leaderssl.ru
🔗 Dataskrapning av Booking.com
Hämtning av sökresultat för lägenheter och hotell på webbplatsen
🔗 Insamling av produktegenskaper
Exempel på dataskrapning av ett okänt antal produktegenskaper
🔗 Dataskrapning av filmdatabas från IMDB
Hämtar data om varje film och skriver ner dem i resultatet
🔗 Kontroll av HTTPS-tillgänglighet
Preset som kontrollerar förekomsten av HTTPS på en webbplats
Insamlade data
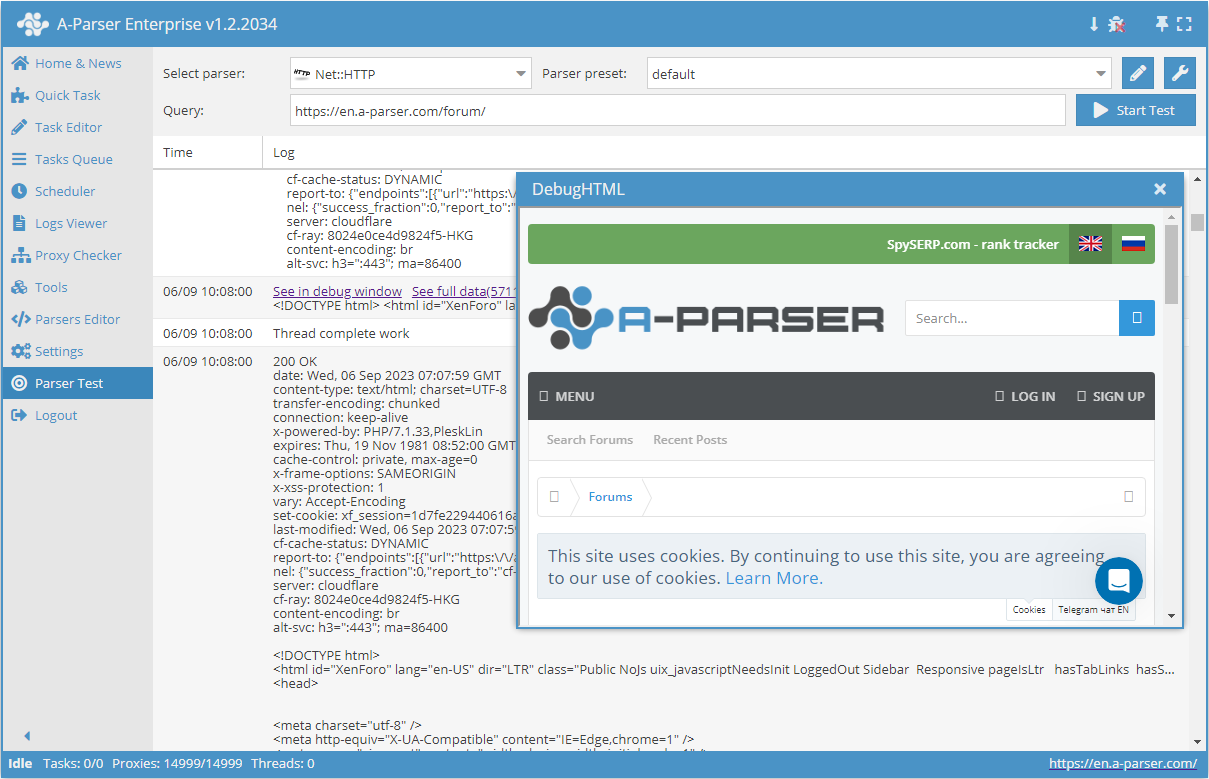
- Innehåll
- Serverns svarskod
- Beskrivning av serverns svar
- Serverns svarshuvuden
- Proxyer som användes vid begäran
- Array med alla insamlade sidor (används när alternativet Use Pages är aktiverat)
Funktioner
- Flersidig dataskrapning (navigering genom sidor)
- Automatisk hantering av proxyer
- Kontroll av lyckat svar via kod eller sidinnehåll
- Stöder komprimering gzip/deflate/brotli
- Identifiering och konvertering av webbplatsers kodning till UTF-8
- Kringgående av CloudFlare-skydd
- Val av motor (HTTP eller Chrome)
- Alternativet Check content – kör ett angivet reguljärt uttryck på den hämtade sidan. Om uttrycket inte matchar, laddas sidan om med en annan proxy.
- Alternativet Use Pages – gör det möjligt att gå igenom ett angivet antal sidor med ett visst steg. Variabeln
$pagenuminnehåller det aktuella sidnumret under genomgången. - Alternativet Check next page – kräver ett reguljärt uttryck som extraherar länken till nästa sida (vanligtvis "Nästa"-knappen), om den finns. Navigering mellan sidor sker inom den angivna gränsen (0 - obegränsat).
- Alternativet Page as new query – övergången till nästa sida sker i en ny begäran. Gör det möjligt att ta bort begränsningen för antal sidor vid navigering.
Användningsområden
- Nedladdning av innehåll
- Nedladdning av bilder
- Kontroll av serverns svarskod
- Kontroll av HTTPS-tillgänglighet
- Kontroll av omdirigeringar (redirects)
- Lista URL:er för omdirigeringar
- Hämtning av sidstorlek
- Insamling av meta-taggar
- Extrahering av data från sidans källkod och/eller rubriker
Frågor
Som frågor måste länkar till sidor anges, till exempel:
http://lenta.ru/
http://a-parser.com/pages/reviews/
Exempel på resultatutmatning
A-Parser stöder flexibel formatering av resultat tack vare den inbyggda mallmotorn Template Toolkit, vilket gör det möjligt att mata ut resultat i valfritt format, samt i strukturerad form som CSV eller JSON.
Utmatning av innehåll
Resultatformat:
$data
Exempel på resultat:
<!DOCTYPE html><html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<!-- Google Tag Manager -->
<!-- End Google Tag Manager -->
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<base href="https://a-parser.com/" />
<title>A-Parser - scraper för SEO-proffs</title>
<noscript><style>.JsOnly, .jsOnly { display: none !important; }</style></noscript>
<link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" />
Serverns svarskod
Resultatformat:
$code
Exempel på resultat:
200
Resultatformatet [% response.Redirects.0.Status || code %] gör det möjligt att visa status 301 om det finns omdirigeringar i begäran.
Hämtning av data om begäran
Variabeln $response hjälper till att få information om begäran och serverns svar.
Resultatformat:
$response.json\n
Exempel på resultat:
{
"Time": 3.414,
"connection": "keep-alive",
"Decode": "Decode from utf-8(meta charset)",
"cache-control": "max-age=3600,public",
"last-modified": "Tue, 18 May 2021 12:42:56 GMT",
"transfer-encoding": "chunked",
"date": "Thu, 27 May 2021 14:18:42 GMT",
"Status": 200,
"content-encoding": "gzip",
"Body-Length-Decoded": 1507378,
"Reason": "OK",
"Proxy": "http://51.255.55.144:25302",
"content-type": "text/html",
"Redirects": [],
"server": "nginx",
"Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n",
"URI": "https://a-parser.com/",
"HTTPVersion": "1.1",
"Body-Length": 299312,
"Decode-Mode": "auto-html",
"etag": "W/\"60a3b650-170032\"",
"Decode-Time": 0.003,
"IP": "remote",
"expires": "Thu, 27 May 2021 15:18:42 GMT"
}
Hämtning av omdirigeringar
Begäran:
https://google.it
Resultatformat:
$response.Redirects.0.URI -> $response.URI
Exempel på resultat:
https://google.it/ -> https://www.google.it/
JSON med omdirigeringar
Resultatformat:
$response.Redirects.json
Exempel på resultat:
[{"x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n"}]
Utmatning av serverns svarsstatus
Resultatformat:
$reason
Exempel på resultat:
OK
Serverns svarstid
Resultatformat:
$response.Time
Exempel på resultat:
1.457
Hämtning av sidstorlek
Som exempel presenteras storleken i tre olika varianter.
Resultatformat:
[% "data-length: " _ data.length _ "\n";
"Body-Length: " _ response.${'Body-Length'} _ "\n";
"Body-Length-Decoded: " _ response.${'Body-Length-Decoded'} _ "\n" %]
Exempel på resultat:
data-length: 70257
Body-Length: 23167
Body-Length-Decoded: 75868
Bearbetning av resultat
A-Parser gör det möjligt att bearbeta resultat direkt under dataskrapningen. I det här avsnittet har vi listat de mest populära fallen för scrapern Net::HTTP.
Utmatning av rubriker H1-H6
Lägg till ett regex (alternativet Parse custom results (Använd regex)) <(h\d+)[^>]+>(.+?)<\/h\d+>, i fältet "Parse result" välj $pages.$i.data - Page content, i fältet bredvid regexen välj modifikatorerna sg. Som resultattype väljs en array automatiskt. I fältet "Name" ange headers, därefter i "$1 to" ange tag, klicka på

content. I det övergripande resultatformatet ange utskriften $p1.headers.format('$tag - $content\n').Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJxtVNuO2jAQ/RVkIS2IW3loH6IVFYuK2ooSlmWfIJUsMgR3HTu1HboI8e+dcUIC
tE+Jj+ccn7nYJ+a4fbMLAxacZcH6xDL/zwI2BxcEX1erRWOrpYStEypp7Ie9/SfW
ZRk3Fgwx1nUg4jHseC4d656YO2aAMtvcOp0uwXqYmeInWKNEApYo3HEW0U4C70h4
bO03m7jTXv8cRZ1Rq9/53H7cbAYeHLEyblWI26SSLBFuDD8i6L9znhK2Bx6T2Uso
2cbEibvVyoFyLDpHUbU91SblVIJmNuyX5P7Og62HJhIbvUazZG426qFdK7/wA6w0
UndCQg1PcVWaaWK+QLsXxXbfvVNleBwLJ7TisjifXNaeXpX4nRNfaYzFXyPATo1O
EXLgBQg8XryvWdOvqbK55z4XHBbsuLTQZRatTjkaie93hAPDnTZhRn4QPzGtxlLO
4ACyDvP6T7mQVJ/xDknfSuL/Q8J/NM5VetdHHcD8MeihUvGrp/BHzYr1TCeXYkiR
CodrO9G5orZ9QPANIKtqNqewVBuojimVy9Nx/jNQMUbWLRtnNXSTxk1bbkGciZ1I
QkzAiBgukbla4SUL1USnmQTKS+VSYlssLOvxGNuyDbSoDd6TJ/4ItFXdNOa0lvb7
S2E1MwLH7yMZTLGS16eWklsu5etydr1DRLylWai+GHPXPj8YbO9cZoPBgPeKm9/f
6nRA9weHOdE4ZpjqOarehepBOV29DsHpjK37ZRdFDOVJEYhhwSz2hQXD81+VjpX2
Insamling av meta-taggar
Lägg till ett reguljärt uttryck (alternativet Parse custom results (Använd reguljärt uttryck)) (<meta[^>]+>), välj $pages.$i.data - Page content i fältet "Parse result", och välj modifieraren g i fältet bredvid uttrycket. Som resultattyp väljs automatiskt en array. Ange meta i fältet "Name" och item i "$1 to". Använd $p1.meta.format('$item\n') i Resultatformatet.
Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB
bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj
3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm
Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z
Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL
SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9
iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK
zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY
rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF
Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY
i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1
gDE=
Alternativ för genomgång av paginering
Användning av Use pages
Use pages. Denna funktion gör det möjligt att gå igenom paginering genom att ange ett i förväg känt antal sidor.
Som exempel tar vi en av kategorierna på produktkatalogwebbplatsen https://www.proball.ru/catalog/myachi/. Längst upp och längst ner ser vi en pagineringspanel. Genom att klicka på ikonerna med sidnummer kan man se i webbläsarens adressfält hur parametern med sidnumret skickas i slutet av begäran:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
Use pages är en sorts räknare som faktiskt sätter in nummer i ordningsföljd i variabeln $pagenum, och ökar dem med det värde vi anger.
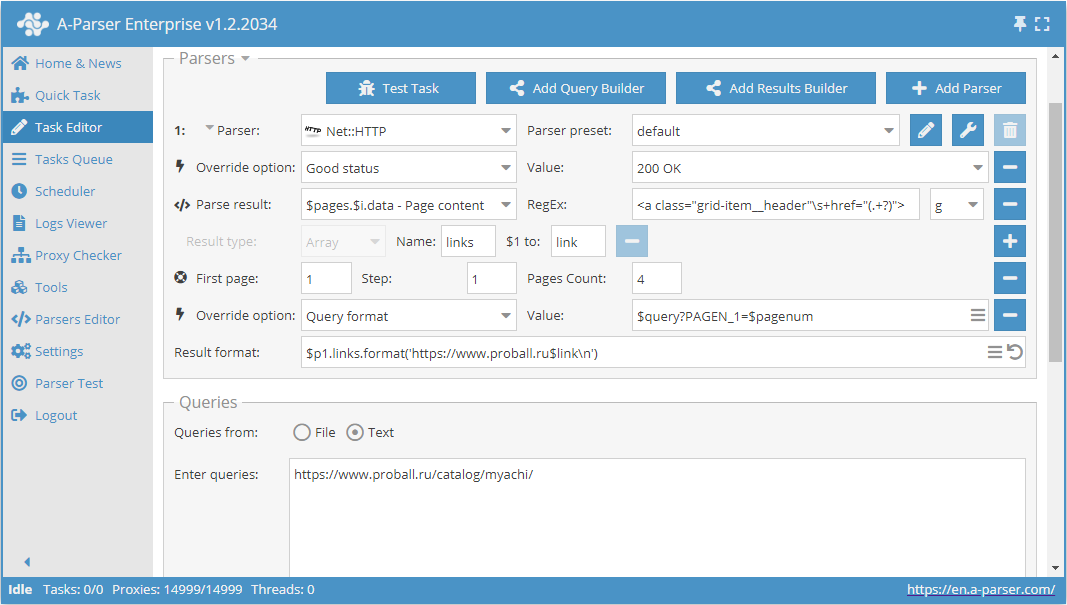
Som framgår av skärmdumpen används variabeln $pagenum på rätt plats i scraperns frågeformat.
Funktionen Use pages kommer att gå igenom och sätta in alla värden i begäran, så att vi faktiskt får länkar för begäran:
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum
där variabeln $pagenum ersätts med sidnumret, med början från 1 till 4 med steg 1.
På så sätt uppnås en genomgång av sidor i det önskade intervallet. Detta är begränsningen med denna metod – man måste i förväg veta antalet sidor som finns i pagineringen. Det är uppenbart att vid samtidig dataskrapning av flera kategorier kommer antalet sidor att vara olika överallt, och som en lösning kan vi helt enkelt ange ett större antal förväntade sidor. Men detta är inte helt korrekt, så det finns en mer optimal lösning som vi kommer att diskutera härnäst.
Ladda ner exempel
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2
pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn
PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0
9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+
1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh
9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob
jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4
YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5
QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u
kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp
sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9
P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8
z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M
vOJ4VZ5BGJXHUBcgGBZ/AXULzRU=
Användning av Check next page
Check next page är en annan funktion som gör det möjligt att organisera en genomgång av paginering. Det speciella med dess användning är att för att gå till nästa sida måste man använda ett reguljärt uttryck som returnerar länken till nästa sida. Detta är ett smidigare och det mest använda sättet. Men det går inte att använda för https://www.proball.ru/catalog/myachi/ eftersom det inte finns några länkar till nästa sidor i koden. Länkarna där genereras av ett skript. Därför tar vi webbplatsen http://www.imdb.com/search/name?gender=female som exempel. Här finns paginering både i början och i slutet av listan. Genom att titta på och analysera källkoden kan man se en länk som gör det möjligt att gå till nästa sida:
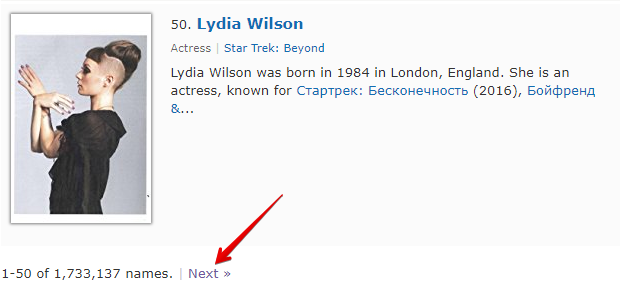
- i fältet Next page RegEx skriver vi det reguljära uttrycket
- i fältet Limit anger vi antalet sidor som ska genomgås
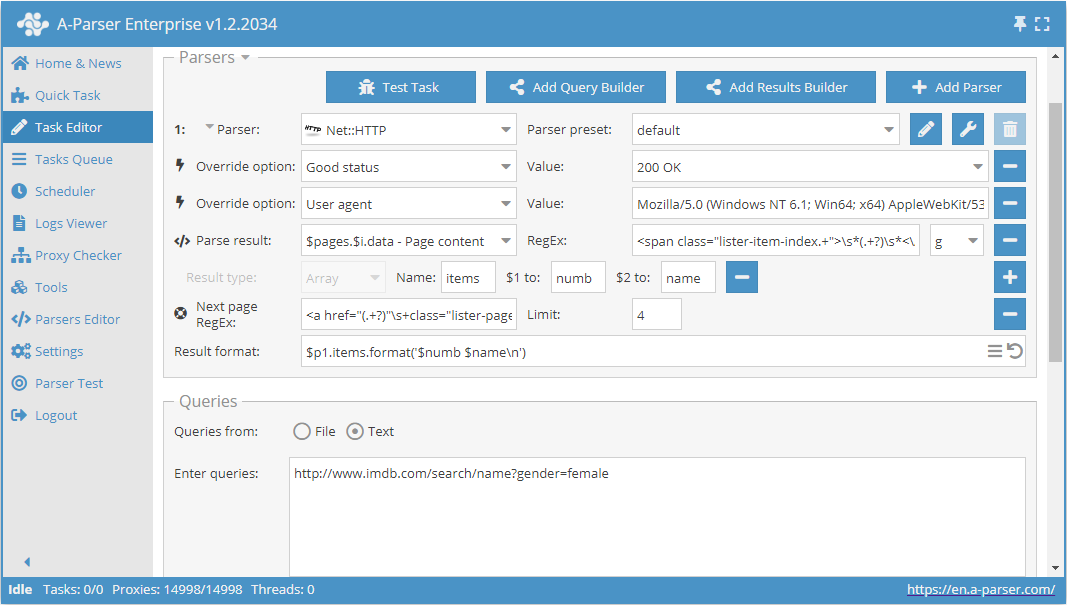
I exemplet anges 4. Genom att ange en gräns bestämmer vi hur många sidor scrapern ska gå igenom. I vårt fall kommer 5 sidor att genomgås, eftersom räkningen börjar från 0. Om man anger gränsen 0 kommer scrapern att arbeta tills den har gått igenom alla sidor, oavsett hur många de är. Detta är mycket praktiskt när man behöver skrapa alla resultat från alla sidor.
Ladda ner exempel
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS
sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr
gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp
ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I
22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY
FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI
HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu
NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O
MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7
exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x
+JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L
itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy
KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18
bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq
iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU
tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY
11r9ASIaBUM=
Som nämnts ovan finns det möjlighet att dynamiskt begränsa antalet sidor i Use pages. För att göra detta måste man använda Use pages och Check next page tillsammans. Vi kompletterar exemplet som granskades vid beskrivningen av Use pages och lägger till funktionen Check next page:
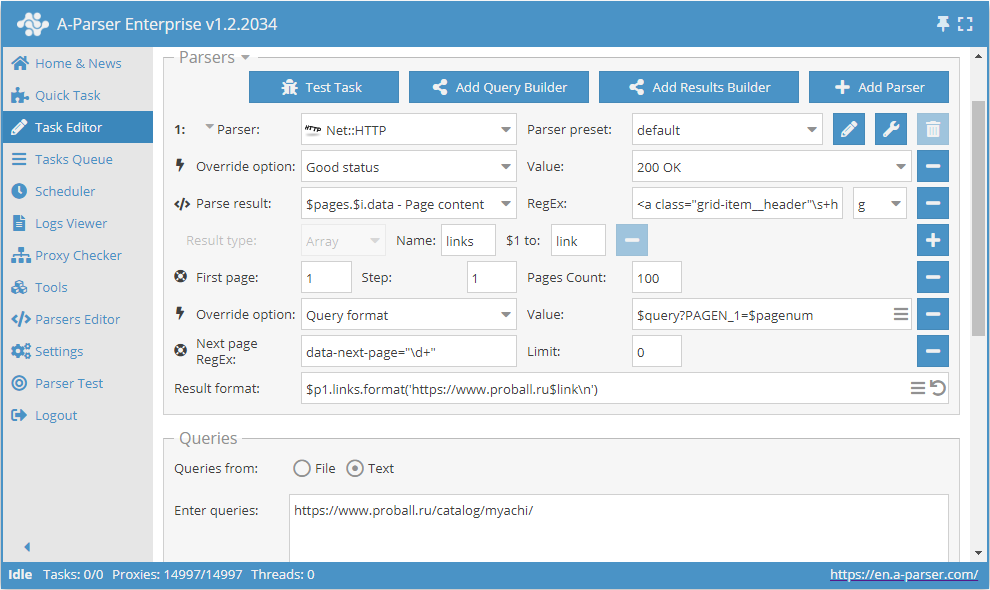
Dessa två funktioner fungerar tillsammans på följande sätt: Use pages säkerställer genomgången av sidor, medan Check next page kontrollerar om nästa sida finns. Så snart Check next page inte hittar nästa sida kommer dataskrapningen av denna kategori att stoppas, utan att vänta på att hela antalet som anges i Use pages har genomgåtts. Genom att kombinera dessa funktioner ökar vi effektiviteten i scraperns arbete och sparar tid och resurser.
Ladda ner exempel
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF
XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG
eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY
LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve
u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals
SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8
Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g
45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa
eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS
mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x
GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ
NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ
EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0
0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g
KP8Byg3yDQ==
Användning av ersättningsmakron
Ersättningsmakron gör det möjligt att implementera sekventiell ersättning av värden från ett angivet intervall.
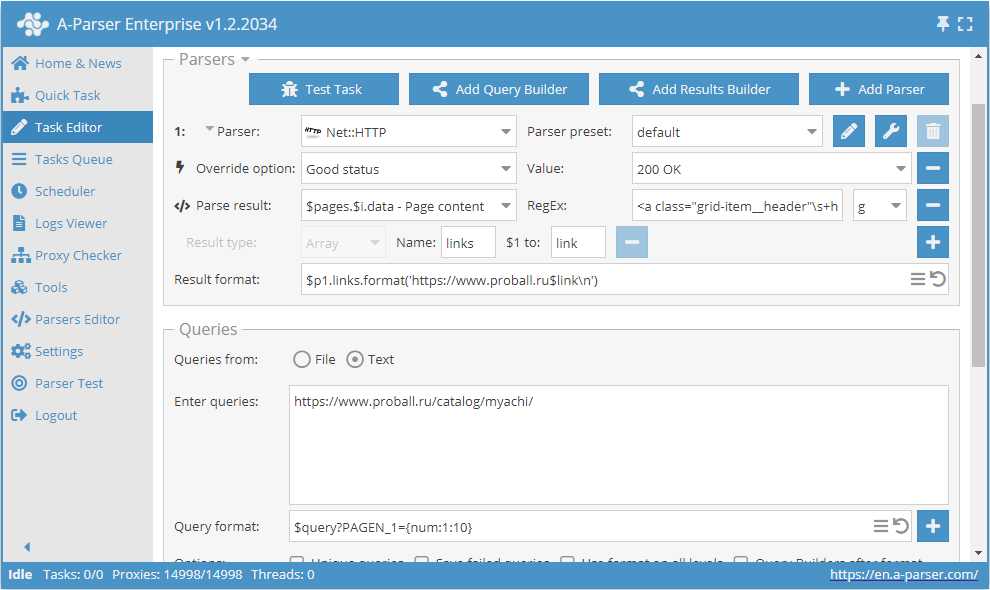
Denna förinställning kommer att fungera på följande sätt. Genom att ange mallen i frågeformatet:
$query?PAGEN_1={num:1:10}
lägger vi till ersättning av värden från 1 before 10 (vilket intervall som helst kan anges) i själva begäran. På så sätt får vi frågor som säkerställer genomgång av det önskade antalet sidor, i formen:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
https://www.proball.ru/catalog/myachi/?PAGEN_1=2
...
https://www.proball.ru/catalog/myachi/?PAGEN_1=10
Användning av ersättningsmakron för genomgång av paginering liknar funktionen Use pages och har samma begränsningar, det vill säga man måste ange ett specifikt intervall av värden. Fördelen med denna metod är att man via ersättningsmakron kan sätta in olika värden, både numeriska och textbaserade, till exempel ord eller uttryck. På så sätt kan vi mer flexibelt infoga nödvändiga delar i frågorna eller bygga själva frågorna av delar som placeras i olika filer, om uppgiften kräver det.
Ladda ner exempel
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a
AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix
JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi
Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6
OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ
IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC
4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv
nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk
vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke
AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa
F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q
MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU
1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg==
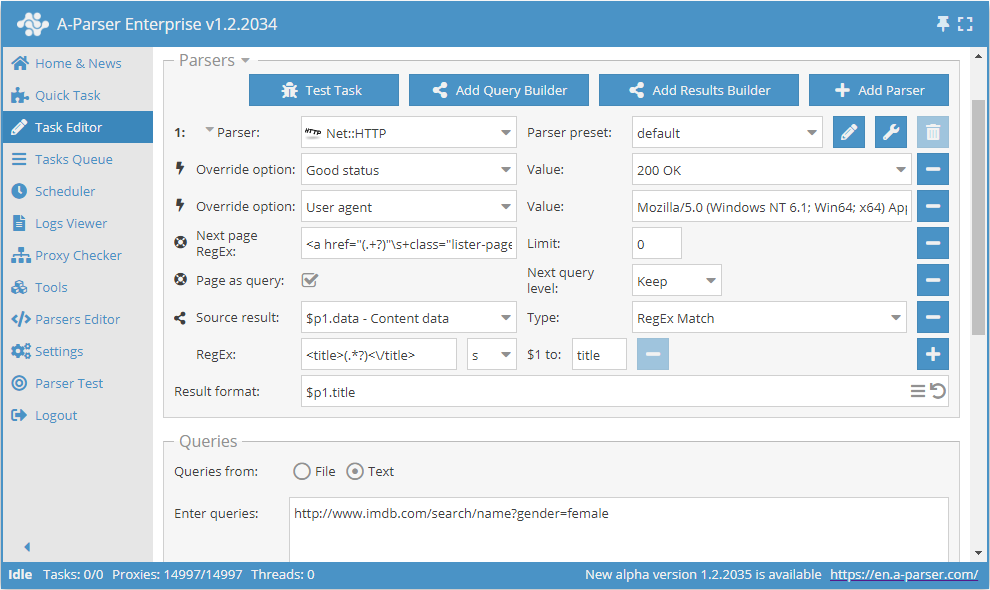
Användning av Page as query
För att minska minnesförbrukningen kan logiken definieras med alternativet Page as query. När det är aktiverat kommer funktionerna Check next page och Use pages att sätta in varje nästa sida i frågorna som en separat självständig begäran, och därmed inte ackumulera deras innehåll i minnet. Page as query gör det också möjligt att bestämma om frågenivån ska höjas Increase (liknande hur verktyget tools.query.add fungerar), eller inte Keep.
Ladda ner exempel
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM
tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA
DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z
ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv
dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i
pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr
mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa
VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1
Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl
CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa
lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0
ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn
5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob
7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD
yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj
geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8=
Möjliga inställningar
| Parameternamn | Standardvärde | Beskrivning |
|---|---|---|
| Good status | All | Val av vilket svar från servern som ska anses vara lyckat. Om ett annat svar erhålls under dataskrapningen kommer begäran att upprepas med en annan proxy. |
| Good code RegEx | Möjlighet att ange ett reguljärt uttryck för att kontrollera svarskoden. | |
| Ban Proxy Code RegEx | Möjlighet att spärra proxyer tillfälligt (Proxy ban time) baserat på serverns svarskod. | |
| Method | GET | Begäransmetod. |
| POST body | Innehåll som ska skickas till servern när POST-metoden används. Stöder variablerna $query – begärans URL, $query.orig – den ursprungliga frågan och $pagenum – sidnumret när alternativet Use Pages används. | |
| Cookies | Möjlighet att ange cookies för begäran. | |
| User agent | _User-agent för den senaste versionen av Chrome infogas automatiskt_ | Rubriken User-Agent vid begäran av sidor. |
| Additional headers | Möjlighet att ange godtyckliga svarshuvuden med stöd för mallmotorns funktioner och användning av variabler från frågebyggaren. | |
| Read only headers | ☐ | Läs endast rubriker. I vissa fall sparar detta trafik om det inte finns något behov av att bearbeta innehållet. |
| Detect charset on content | ☐ | Identifiera kodning baserat på sidans innehåll. |
| Emulate browser headers | ☑ | Emulera webbläsarens rubriker. |
| Max redirects count | 7 | Maximalt antal omdirigeringar som scrapern ska följa. |
| Follow common redirects | ☑ | Tillåter omdirigeringar http <-> https och www.domän <-> domän inom samma domän, förbi gränsen för Max redirects count. |
| Max cookies count | 16 | Maximalt antal cookies som ska sparas. |
| Engine | HTTP (Fast, JavaScript Disabled) | Gör det möjligt att välja motor: HTTP (snabbare, utan JavaScript) eller Chrome (långsammare, JavaScript aktiverat). |
| Chrome Headless | ☐ | Om alternativet är aktiverat kommer webbläsaren inte att visas. |
| Chrome DevTools | ☐ | Gör det möjligt att använda verktyg för felsökning av Chromium. |
| Chrome Log Proxy connections | ☐ | Om alternativet är aktiverat kommer information om Chrome-anslutningar att visas i loggen. |
| Chrome Wait Until | networkidle2 | Definierar när sidan anses vara laddad. Mer om värdena. |
| Use HTTP/2 transport | ☐ | Definierar om HTTP/2 ska användas istället för HTTP/1.1. Vissa webbplatser bannlyser omedelbart om HTTP/1.1 används, medan andra tvärtom inte fungerar via HTTP/2. |
| Try use HTTP/1.1 for Protocol error | ☑ | Instruerar scrapern att upprepa begäran med HTTP/1.1 om HTTP/2 var aktiverat och ett protokollfel uppstod (dvs. om webbplatsen inte stöder HTTP/2). |
| Don't verify TLS certs | ☐ | Inaktivering av validering av TLS-certifikat. |
| Randomize TLS Fingerprint | ☐ | Detta alternativ gör det möjligt att kringgå blockering av webbplatser baserat på TLS-fingeravtryck. |
| Bypass CloudFlare with Chrome | ☐ | Automatiskt kringgående av CloudFlare-kontroll. |
| Bypass CloudFlare with Chrome Max Pages | 20 | Max antal sidor vid kringgående av CF via Chrome. |
| Bypass CloudFlare with Chrome Headless | ☑ | Om alternativet är aktiverat kommer webbläsaren inte att visas under kringgående av CF via Chrome. |