Resultatens dubblettkontroll
Dubblettkontroll, deduplicering, borttagning av dubbletter, borttagning av upprepningar - allt detta innebär att vi inte vill ha upprepade resultat. I A-Parser finns det 2 metoder för dubblettkontroll, låt oss gå igenom varje i detalj.
Resultatens dubblettkontroll per rad
Denna metod fungerar efter formatering av resultatet, precis innan resultatet skrivs till filen kontrolleras varje rad för unikhet och endast nya unika rader skrivs till filen.
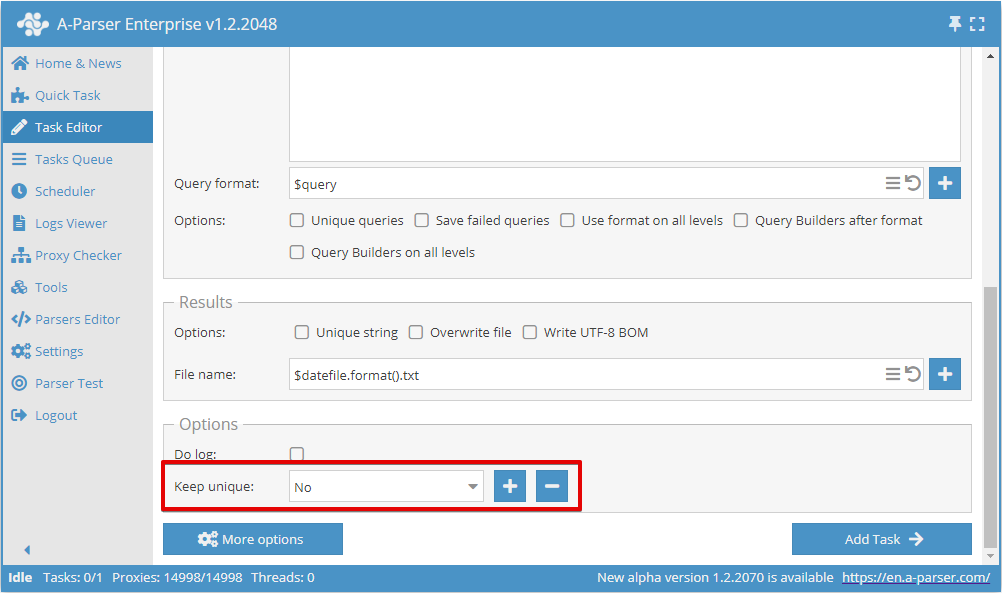
Du kan aktivera unikhet per rad i Snabbinställningar:
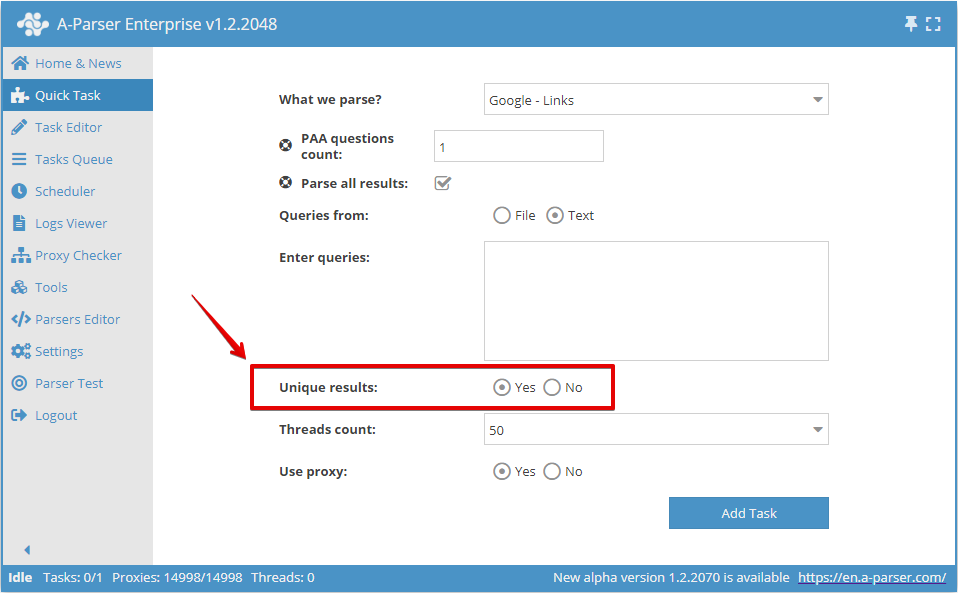
Eller i Task Editor:
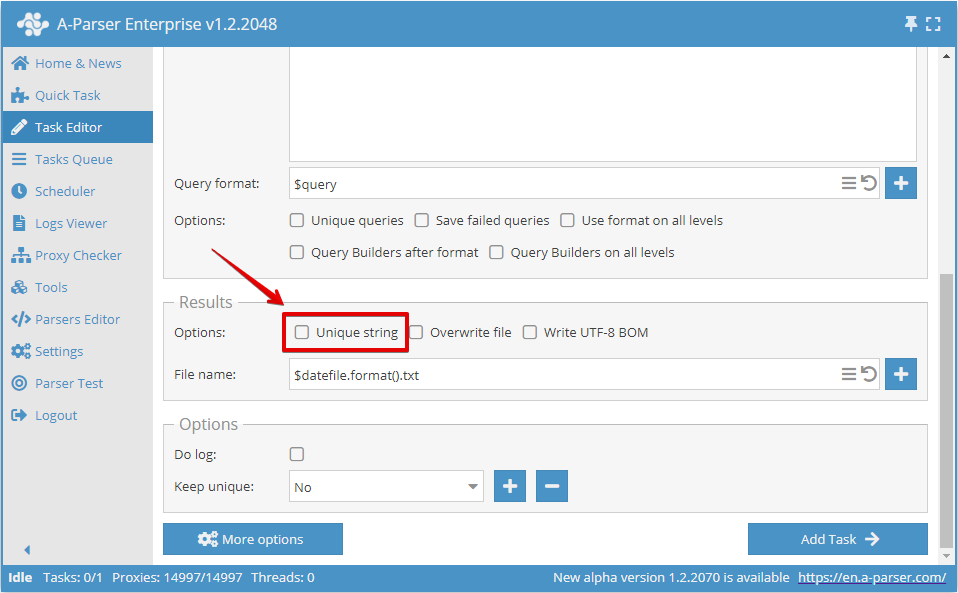
Dubblettkontroll efter valfritt resultat
Dubblettkontroll efter valfritt resultat gör det möjligt att utföra dubblettkontroll direkt på det valda resultatet från en specifik scraper. Du kan lägga till denna typ av dubblettkontroll i Task Editor genom att klicka på verktygsikonen till höger om scrapern och välja Add unique result (Lägg till dubblettkontroll):
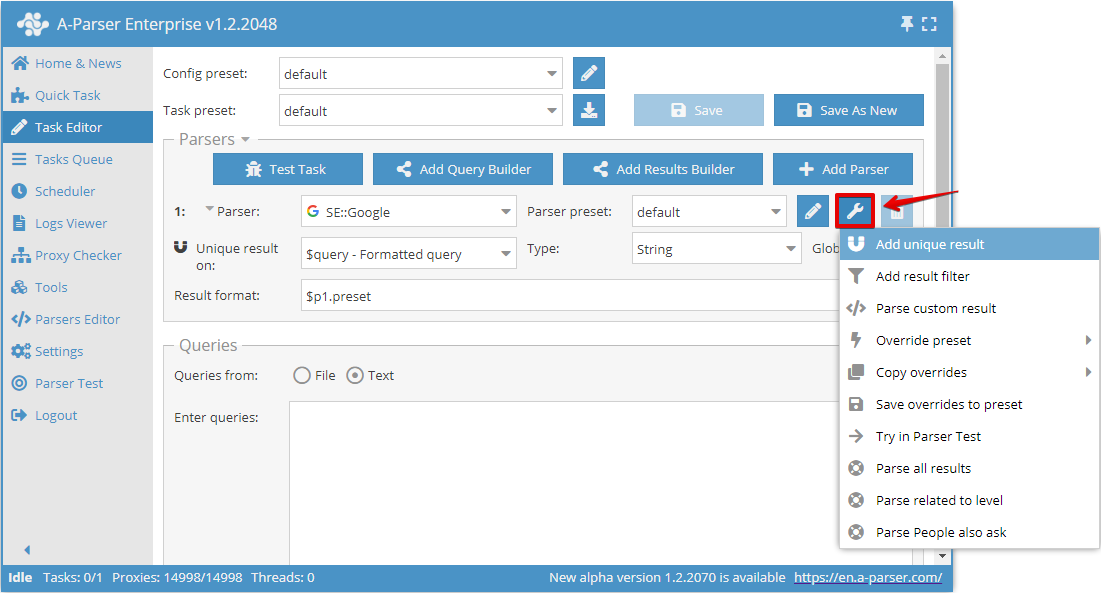
Nu kan du välja vilket resultat dubblettkontrollen ska utföras på och typ av dubblettkontroll:
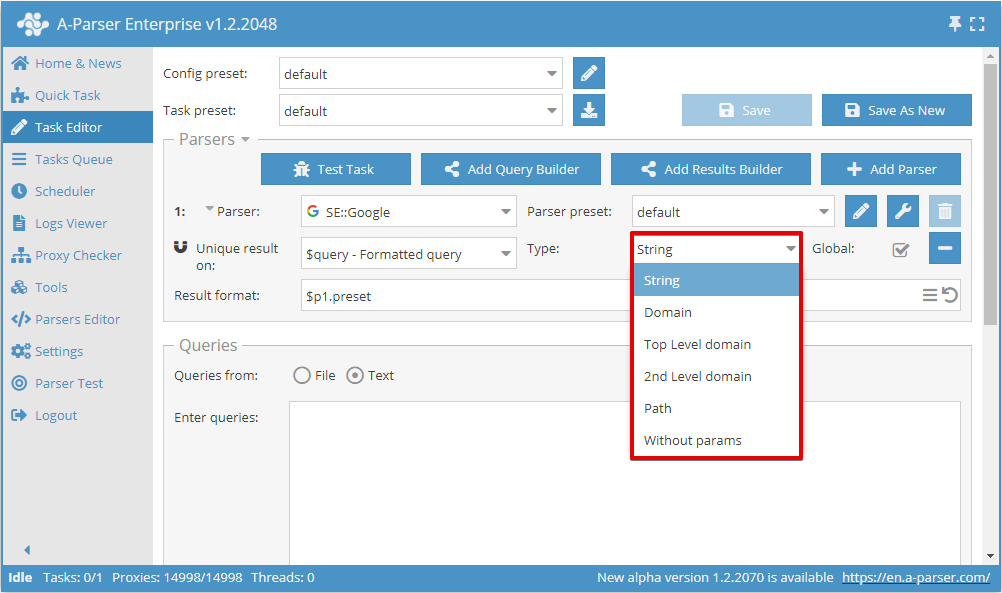
Växeln Global (Globalt) används när 2 eller fler scrapers är valda; den avgör om en gemensam dubblettkontroll ska utföras eller separat för varje scraper.
Typer av dubblettkontroll
| Parameter | Beskrivning |
|---|---|
| String | Dubblettkontroll per rad (hela resultatraden jämförs) |
| Domain | Dubblettkontroll per domän (hela domänen jämförs, till exempel är www.domain.com och domain.com olika domäner) |
| Top Level domain | Dubblettkontroll per huvuddomän med hänsyn till regionala, kommersiella, utbildnings- och andra domäner (till exempel är domain.co.uk och domain2.co.uk olika domäner, medan sub1.domain.com och sub2.domain.com är samma) |
| Andranivådomän | Dubblettkontroll per andranivådomän (andranivådomäner jämförs, till exempel är www.domain.com, domain.com och user.subdomain.domain.com alla samma domän) |
| Path | Dubblettkontroll per sökväg (delar av länken fram till filen jämförs, till exempel är http://domain.com/path1/file.php och http://domain.com/path1/file2.php samma delar av länken fram till filen) |
| Without params | Dubblettkontroll per länk utan parametrar (länkar utan parametrar jämförs, till exempel är http://domain.com/file.php?page=1 och http://domain.com/file.php?page=2 samma länkar) |
Frågedubblettkontroll
Frågedubblettkontroll skickar endast unika frågor till dataskrapning som inte tidigare har skrapats i den aktuella uppgiften. Huvudsakliga användningsområden:
- Om det finns dubbletter i ursprungsfrågorna och det är oönskat att skrapa dem (dubbelt arbete)
- Vid användning av alternativet Parse to level (Dataskrapa till nivå) är det nödvändigt att endast använda unika frågor för att förhindra att frågorna expanderar okontrollerat eller hamnar i loopar (till exempel vid användning av scrapern
 HTML::LinkExtractor)
HTML::LinkExtractor)
I alla andra fall kommer onödig användning av frågedubblettkontroll endast att sakta ner scraperns totala arbete
Spara dubblettkontrollstatus mellan uppgifter
Det finns möjlighet att spara databasen för dubblettkontroll för användning i framtida uppgifter, vilket gör det möjligt att i nya uppgifter endast spara nya unika resultat (till exempel länkar vid dataskrapning av SERP i  SE::Google)
SE::Google)
För att spara dubblettkontrollsdatabasen måste du skapa ett nytt databasnamn när du lägger till den första uppgiften:
För alla efterföljande uppgifter måste du välja det tidigare skapade databasnamnet, vilket gör att endast nya unika resultat sparas, oavsett om resultaten skrivs till samma fil som i den första uppgiften eller till en ny fil.