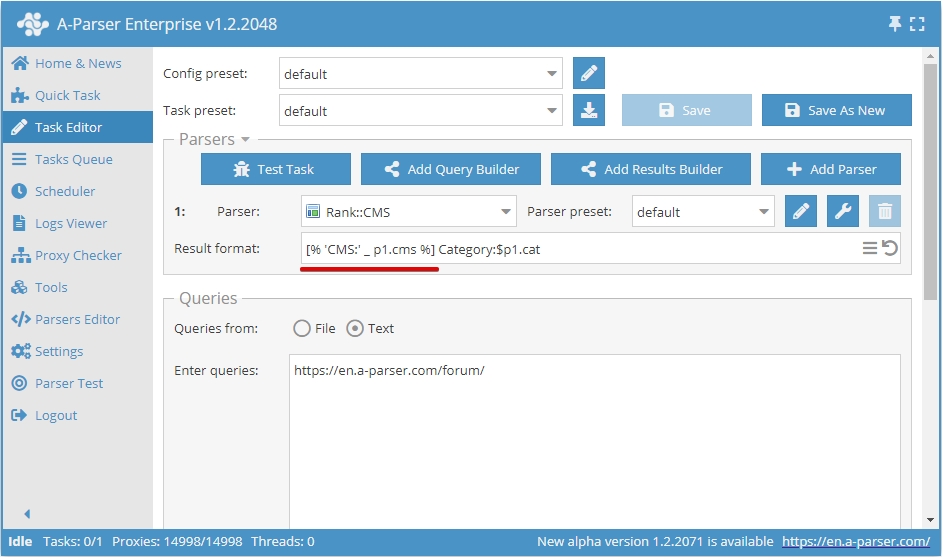
Rappresentazione e formattazione dei risultati
Formati disponibili per il salvataggio dei risultati
Per la formattazione dei risultati in A-Parser viene utilizzato il motore di modelli Template Toolkit, che permette di salvare facilmente i risultati dello scraping in vari formati:
- In file di testo come elenco: un risultato per riga, tramite separatore, in formato arbitrario
- In file
CSVcon possibilità di successiva importazione in Excel, Google Docs, ecc. - In
XML,JSONe altri formati di archiviazione dati - In
HTMLgenerando pagine "al volo" - In formato dump
SQLper l'importazione diretta nel database o scrivendo direttamente nel database SQLite - In formato binario per il salvataggio di immagini (
jpg, png, gif,...), documenti (pdf, docx,...), file eseguibili e archivi (exe, dmg, zip,...) e qualsiasi altro tipo di dati
Modifica del formato del risultato
Result format (Formato del risultato) - permette di formattare i risultati nell'aspetto desiderato utilizzando i modelli, si applica a ogni combinazione query-risultati.
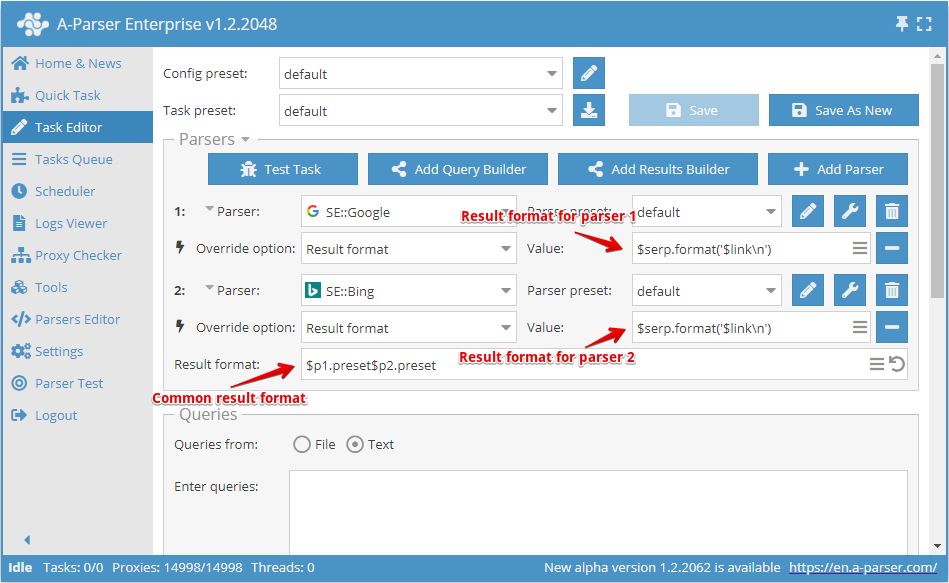
- Il formato generale del risultato si imposta nel campo
Result format - Il formato del risultato per ogni scraper può essere impostato separatamente nelle impostazioni dello scraper in
Result format
A-Parser supporta il lavoro con più scraper in un unico task; nel formato generale dei risultati è necessario indicare da quale scraper visualizzare il risultato:
$p1- risultati dal primo scraper ( SE::Google nello screenshot),
SE::Google nello screenshot), $p2- risultati dal secondo scraper ( SE::Bing nello screenshot)
SE::Bing nello screenshot)- Il numero d'ordine dello scraper è visualizzato a sinistra del campo di selezione dello scraper
$p1.presete$p2.presetimplicano che è necessario prendere il valore del formato del risultato dalle impostazioni dei rispettivi scraper- In questo esempio
$p1.presetpuò essere sostituito con$p1.serp.format('$link\n')che avrà lo stesso effetto, mentre il formato del risultato dalle impostazioni non verrà più utilizzato
Il Result format (Formato del risultato) può essere indicato in un comodo editor multilinea cliccando sull'icona corrispondente nel campo di modifica:
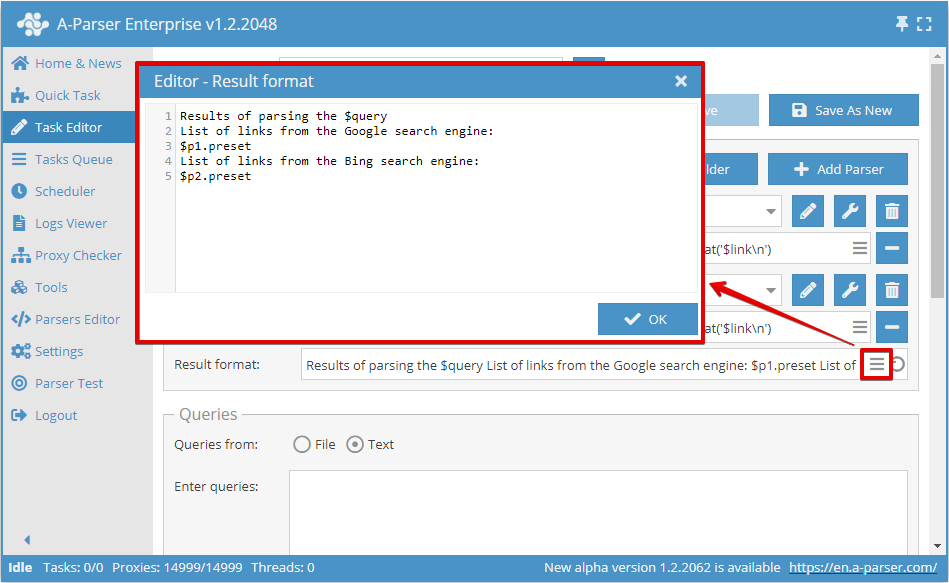
Nel formato generale dei risultati sono disponibili le seguenti variabili:
$query- query dopo la formattazione$query.*- tutte le variabili relative alla query, descritte nell'articolo Modelli nelle query$p1, $p2, ...- variabili per l'accesso ai risultati dello scraping per ogni scraper separatamente (Visualizzazione dei possibili risultati per ogni scraper)$p1.query, $p2.query, ...- query dopo la formattazione tenendo conto del formato della query indicato nelle impostazioni di ogni scraper
Testo iniziale e finale
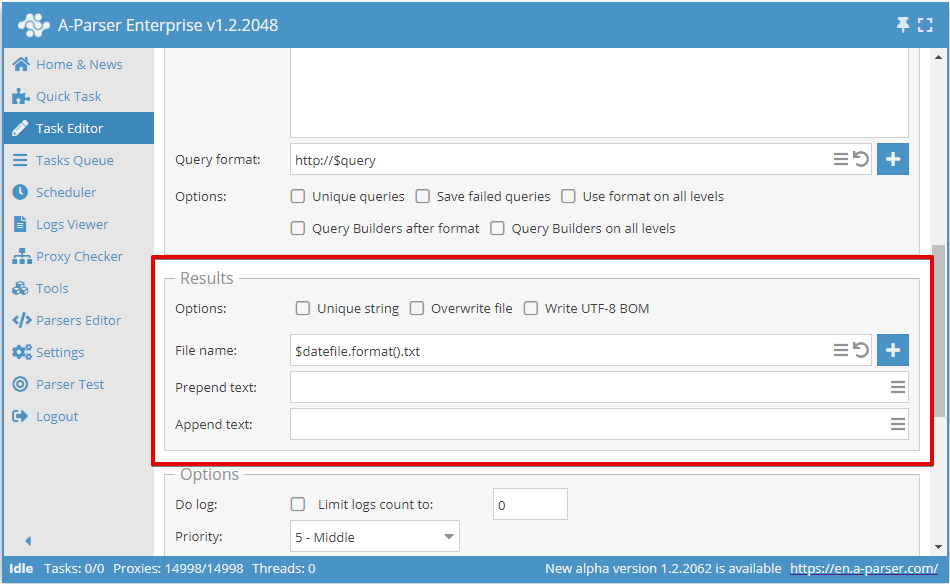
Per ogni file dei risultati viene indicato un Testo iniziale/finale separato:
- Per la creazione dell'intestazione del file CSV
- Per i tag iniziali e finali del file XML
- Per l'header, l'intestazione e il footer dei file HTML
- Per qualsiasi altra variante di applicazione
Per attivare questa funzionalità è necessario cliccare sul pulsante More options (Più opzioni) nella parte inferiore dell'Editor dei task
Nel testo iniziale e finale è supportato l'uso del motore di modelli Template Toolkit, variabili disponibili:
$query- query dopo la formattazione$query.*- tutte le variabili relative alla query, descritte nell'articolo Modelli nelle query
Importante! Queste variabili sono disponibili solo quando si salva ogni query in un file separato o quando si utilizzano queste stesse variabili nel Formato del nome del file del risultato.
Formato del nome del file dei risultati
A-Parser permette di utilizzare i modelli anche nei nomi dei file risultanti, il che consente di creare automaticamente file e cartelle in base alla data corrente, al numero d'ordine della query, alla query stessa e in qualsiasi altro formato.
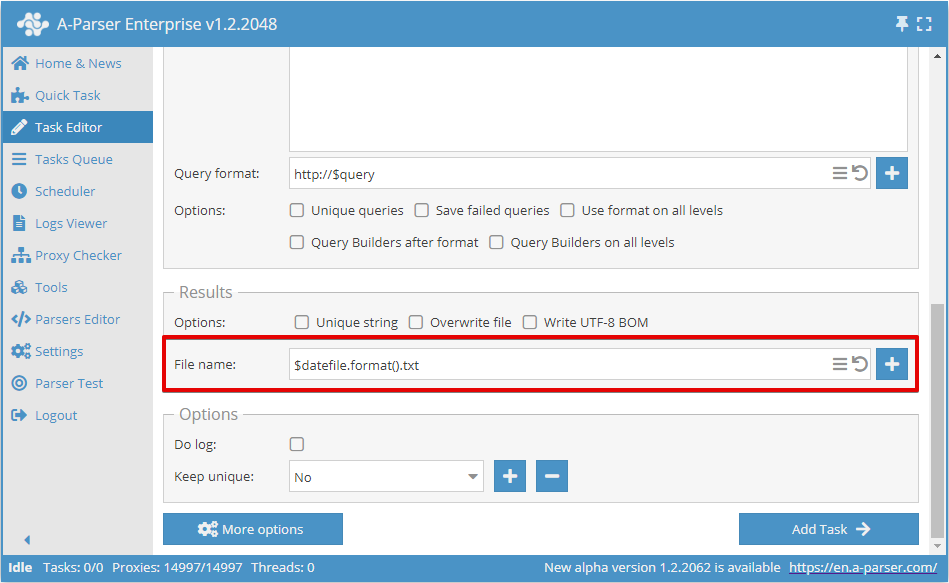
Nel campo File name (Nome file) sono supportate le seguenti variabili:
- Tutte le variabili disponibili per il Formato generale del risultato
$queriesfile- percorso e nome del file con le query; se le query sono indicate tramite il modulo, conterrà queries_from_text.txt$datefile- oggetto del plugin date del motore di modelli Template Toolkit, configurato per il formato data%b-%d_%H-%M-%S; durante la formattazione restituisce l'ora e la data correnti sotto forma di May-08_20-08-38, il formato può essere modificato nelle Impostazioni aggiuntive
Per impostazione predefinita, il nome del file viene creato in base alla data e all'ora al momento dell'avvio del task
Esempio complesso
reports/$queriesfile/${query}.txt
- Verrà creata la cartella reports
- Verrà creata una sottocartella con il nome del file delle query
- Nella sottocartella verranno creati tanti file quante sono le query utilizzate nel task; come nome del file verrà utilizzata la query stessa con l'estensione
.txt
La variabile $query è scritta nel formato ${query} per prevenire l'interpolazione dell'estensione .txt come parte della variabile, maggiori dettagli nella documentazione del motore di modelli Template Toolkit
⏩ Video. Denominazione dei file dei risultati
In questo video presenteremo alcuni esempi di denominazione del file del risultato:
- Numerazione del file del risultato in base alle query.
- Numerazione del file del risultato + parte del nome della query.
- Denominazione del file del risultato in base alla query, se la query è un link.
Visualizzazione dei risultati disponibili
Ogni scraper ha il suo set di risultati; è possibile visualizzare l'elenco dei risultati disponibili passando il puntatore sullo scraper: nel suggerimento a comparsa verrà visualizzato l'elenco dei risultati semplici e degli array, con l'elenco degli elementi nidificati:
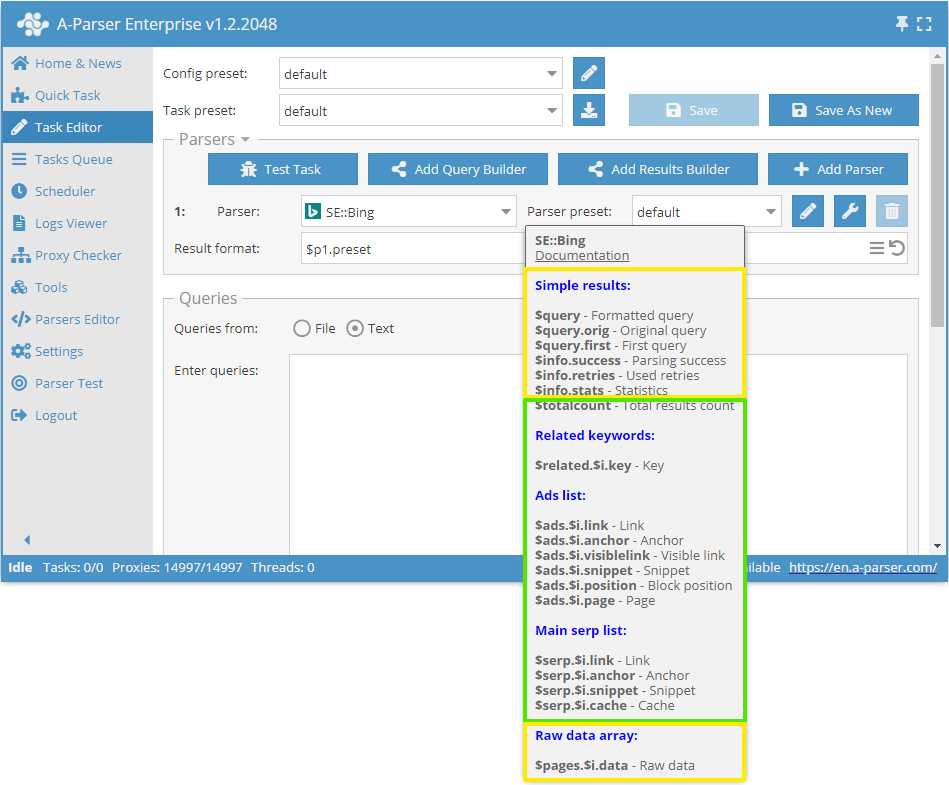
In giallo sono contrassegnati i risultati comuni a tutti gli scraper:
$query- query passata allo scraper dopo la formattazione$query.orig- query originale (così come appariva nel file o nel campo di inserimento query)$query.first- prima query quando si utilizzano le opzioni di scraping nidificato (Parse all results o Parse to level)$info.success- informazioni sul successo dello scraping di questa query$info.retries- numero di tentativi utilizzati per questa query$info.stats- statistiche di funzionamento dello scraper per questa query$pages.$i.data- array con le risposte non elaborate dal server per la possibilità di estrarre autonomamente informazioni aggiuntive
In verde sono contrassegnati i risultati disponibili solo per lo scraper SE::Bing:
$totalcount- numero di risultati della ricerca$adscon gli elementi$link,$anchor,$visiblelink,$snippet,$positione$page- array con l'elenco degli annunci$related.$i.key- array con l'elenco delle parole chiave correlate$serpcon gli elementi$link,$anchor,$snippet,$cache- array con i risultati principali del motore di ricerca
Si noti che per gli array viene indicata esplicitamente la variabile $i, il che significa che ci sono più elementi e che è possibile accedervi tramite indice (numero di posizione) o scorrere ogni elemento in un ciclo.
Il risultato $pages.$i.data verrà automaticamente modificato in $data per quegli scraper che non "visitano le pagine" nell'ambito di una singola richiesta. Per esempio come  DeepL::Translator.
DeepL::Translator.
Rappresentazione dei risultati
A-Parser è stato creato per lo scraping di informazioni di ogni tipo; per questo sono stati introdotti 2 tipi di risultati:
- Risultati semplici (Flat)
- Array di risultati (Array)
Consideriamo ogni tipo usando come esempio lo scraper SE::Google, screenshot dei risultati:
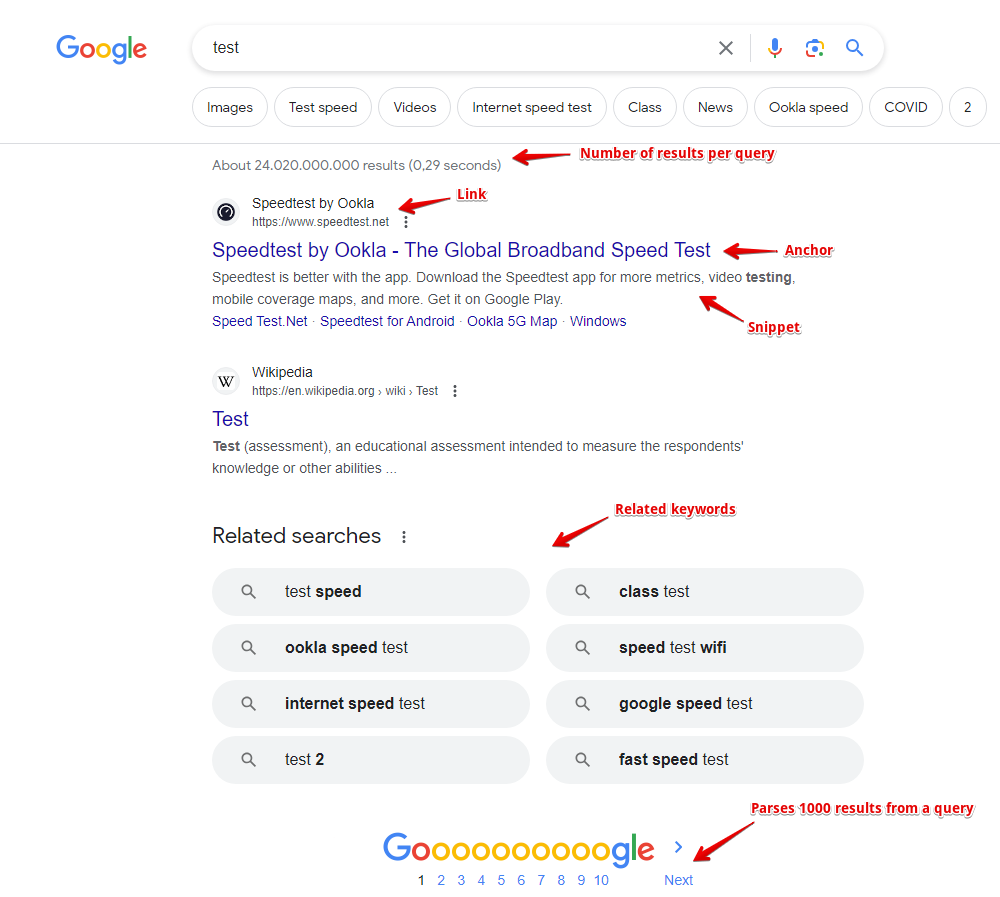
Risultati semplici
Simple results (Risultati semplici) - quando a una query corrisponde un solo risultato, esempi:
- Numero di risultati per query ($totalcount)
- Se la query è un errore di battitura ($misspell, non presente nello screenshot)
Altri esempi:
- Valore del testo tradotto ($translated) nello scraper DeepL::Translator
- Numero di domini referenti ($domains), valore di trust ($trustflow), backlink ($backlinks) ecc. nello scraper
 Rank::MajesticSEO
Rank::MajesticSEO
I risultati singoli vengono salvati in variabili ordinarie (prefisso $ + nome in caratteri latini)
Array di risultati
Array di risultati - quando a una query corrisponde un elenco di risultati, ogni elemento dell'elenco a sua volta può contenere diversi elementi nidificati. Analizziamo l'esempio dei risultati di Google: sono rappresentati nello scraper dall'array $serp; per chiarezza utilizzeremo una tabella, scrivendo i primi 5 risultati:
| Link ($link) | Ancora ($anchor) | Snippet ($snippet) |
|---|---|---|
| http://www.speedtest.net/ | Speedtest.net by Ookla - The Global Broadband Speed Test | Test your Internet connection bandwidth to locations around the world with this interactive broadband speed test from Ookla. |
| http://en.wikipedia.org/wiki/Test_cricket | Test cricket - Wikipedia, the free encyclopedia | Test cricket is the longest form of the sport of cricket. Test matches are played between national representative teams with "Test status", as determined by the ... |
| http://www.speakeasy.net/speedtest/ | Speakeasy Speed Test | Saturday 03-May 2014, 11:04:29 AM Your IP: The Speakeasy Speed Test requires Flash v7 or higher. Please update your browser. See Pricing Or Call Today |
| http://www.humanmetrics.com/cgi-win/jtypes2.asp | Personality test based on C. Jung and I. Briggs Myers type theory | Humanmetrics Jung Typology Test™ instrument uses methodology, questionnaire, scoring and software that are proprietary to Humanmetrics, and shall not be ... |
| http://test-ipv6.com/ | Test your IPv6. | This will test your browser and connection for IPv6 readiness, as well as show you your current IPV4 and IPv6 address. ... Test your IPv6 connectivity. JavaScript ... |
Ogni posizione dei risultati viene scritta in un array con 3 elementi nidificati - link ($link), ancora ($anchor), snippet ($snippet)
Un altro esempio - l'elenco delle parole chiave correlate, che viene salvato nell'array $related:
| Parola chiave ($key) |
|---|
| test wwe |
| depression test |
| test my speed |
| wonderlic test |
| test personality |
| act test |
| jiggle test |
| bipolar test |
Come si può vedere, in questo array c'è un solo elemento nidificato - parola chiave ($key)
La numerazione degli elementi degli array inizia da 0, esempio di accesso ai singoli elementi dell'array:
$serp.0.link- primo link dai risultati$serp.3.anchor- quarta ancora dai risultati$related.0.key- prima parola chiave correlata
Più avanti verrà descritta in dettaglio la formattazione dei risultati semplici e degli array
Principi di formattazione
Dopo che lo scraper ha raccolto i dati in risultati semplici e array, è necessario visualizzarli (salvarli in un file) nel formato desiderato. Per comodità e funzionalità, A-Parser utilizza il motore di template Template Toolkit. Esaminiamo le costruzioni usate frequentemente; a tale scopo utilizzeremo lo strumento Test dei modelli. Selezioniamo un progetto per lo scraper SE::Google:
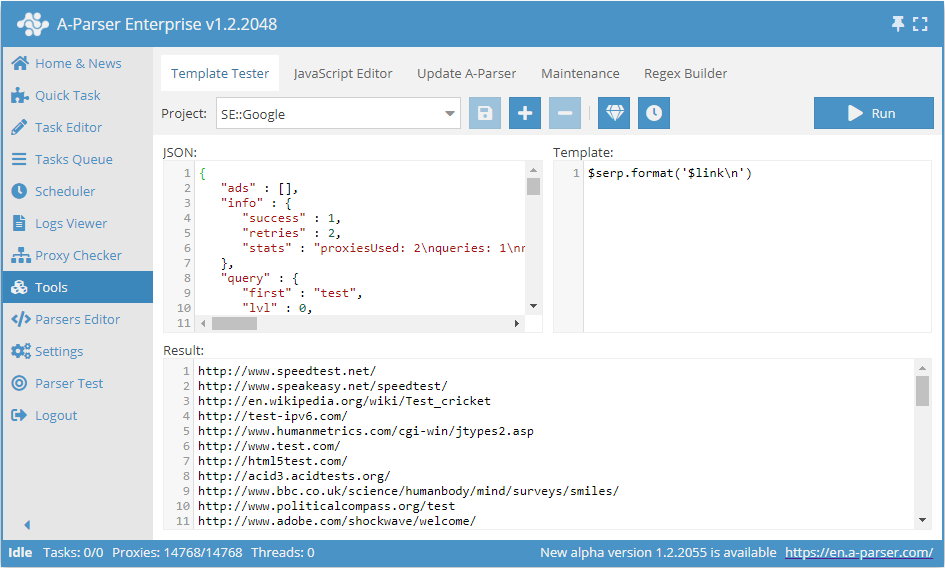
Nello screenshot sono presentati 3 campi:
- JSON - rappresentazione interna dei dati nello scraper
- Template - modello secondo il quale avviene la formattazione del risultato
- Result - dati direttamente trasformati secondo il modello indicato; il risultato verrà scritto nel file esattamente in questa forma
Cambiando il modello possiamo cambiare l'aspetto del risultato, consideriamo il seguente modello:
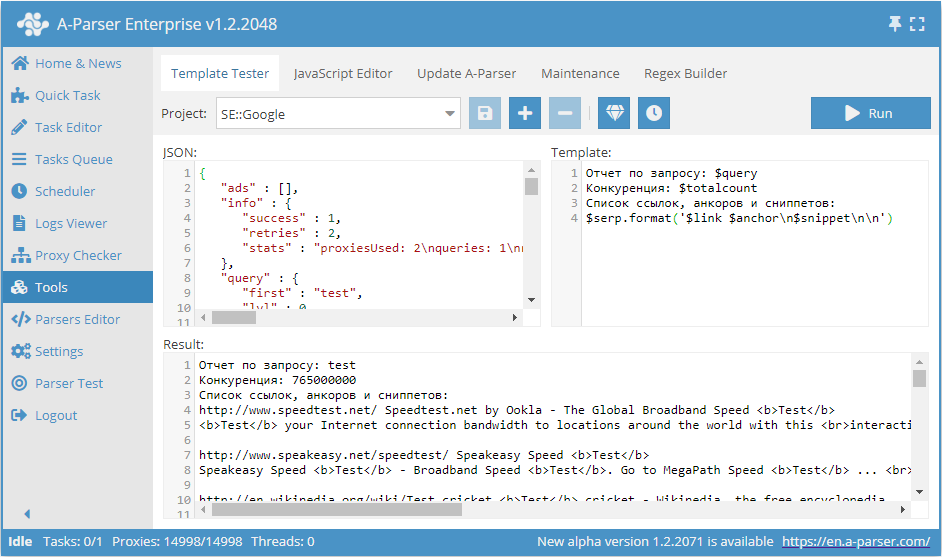
Testo nel campo Template (Modello):
Rapporto per la query: $query
Concorrenza: $totalcount
Elenco di link, ancore e snippet:
$serp.format('$link $anchor\n$snippet\n\n')
Evidenziamo le regole principali:
- Il testo normale viene visualizzato nel risultato così com'è, senza modifiche
- Per visualizzare i risultati semplici è necessario inserire nel punto desiderato la variabile contenente il risultato richiesto con il prefisso
$ - Per la formattazione degli array viene utilizzato il metodo
.format, di cui parleremo tra poco \nè responsabile dell'andata a capo
Formattazione degli array
Analizziamo la costruzione:
$serp.format('$link $anchor\n$snippet\n\n')
Questa scrittura significa che per l'array $serp è necessario chiamare il metodo .format con il parametro '$link $anchor\n$snippet\n\n'. Il metodo .format unisce in una stringa tutti gli elementi dell'array secondo il modello indicato nel parametro; il modello stesso significa: per ogni elemento dell'array $serp visualizzare il link e l'ancora separati da uno spazio, poi visualizzare lo snippet su una nuova riga, seguito da altri due ritorni a capo, che generano una riga vuota tra i risultati.
Utilizzo del motore di modelli
Visualizzazione delle variabili
Per utilizzare il motore di modelli è necessario inserire i tag [% %], e all'interno dei tag inserire la logica da eseguire.
Ciclo sull'array
Per visualizzare gli elementi dell'array è necessario utilizzare la costruzione FOREACH:
[% FOREACH i IN p1.list;
i.cms _ "\n";
END %]
Maggiori informazioni ed esempi sul motore di modelli in Caratteristiche del funzionamento dei modelli in A-Parser.
Esempi
Visualizzazione della concorrenza
Output della concorrenza per query (numero di risultati per query) per tutti gli scraper dei motori di ricerca (SE::Google,  SE::Yandex...).
SE::Yandex...).
Formato del risultato:
$query: $totalcount\n
Esempio di risultato:
test: 3910000000
viagra: 278000000
finestre pvc: 3220000
...
Scraping dei link
Visualizzazione dei link dai risultati dei motori di ricerca.
Formato del risultato:
$serp.format('$link\n')
Esempio di risultato:
http://www.speedtest.net/
http://www.speakeasy.net/speedtest/
http://en.wikipedia.org/wiki/Test_cricket
http://www.humanmetrics.com/cgi-win/jtypes2.asp
http://html5test.com/
http://test-ipv6.com/
...
Scraping dei suggerimenti
Visualizzazione dei suggerimenti dei motori di ricerca.
Formato del risultato:
$results.format('$suggest\n')
Esempio di risultato:
test server tanki online
test esame di stato russo
ricetta impasto per pancake
testicolo
impasto per pizza al latte
Visualizzazione dei dati sulla query
In  Net::HTTP e negli scraper basati su di esso è inoltre disponibile l'output di:
Net::HTTP e negli scraper basati su di esso è inoltre disponibile l'output di:
$proxy- proxy su cui è stata eseguita la query$headers- intestazioni della risposta$code- codice di risposta$reason- stato della risposta
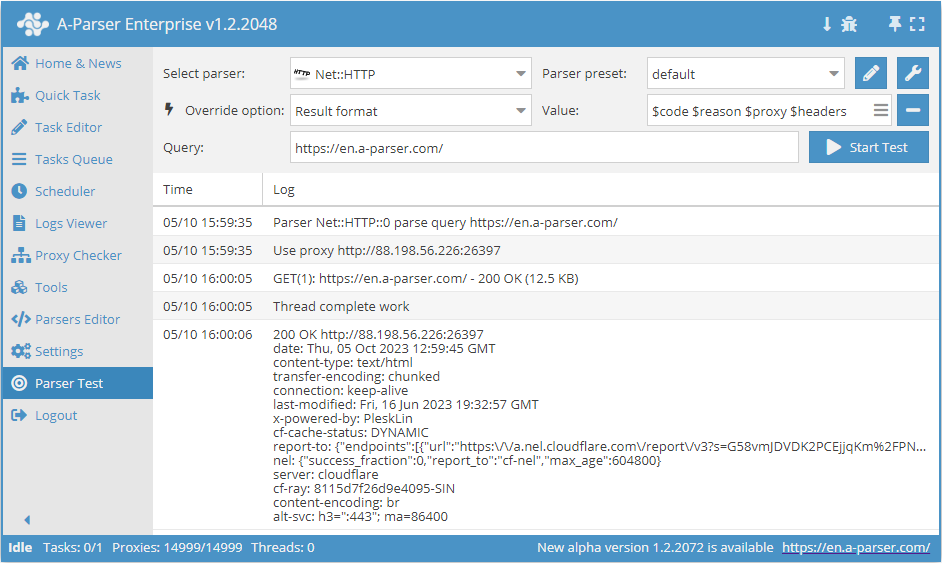
Visualizzazione dei valori delle variabili in JSON
Visualizzazione di tutti i redirect della query
Per questo compito è disponibile la variabile $response, che permette di ottenere qualsiasi variabile della query, inclusi tutti i redirect precedenti.
Formato del risultato:
$response.Redirects.format('$URI\n--> ')$response.URI
Risultato del funzionamento dello scraper:
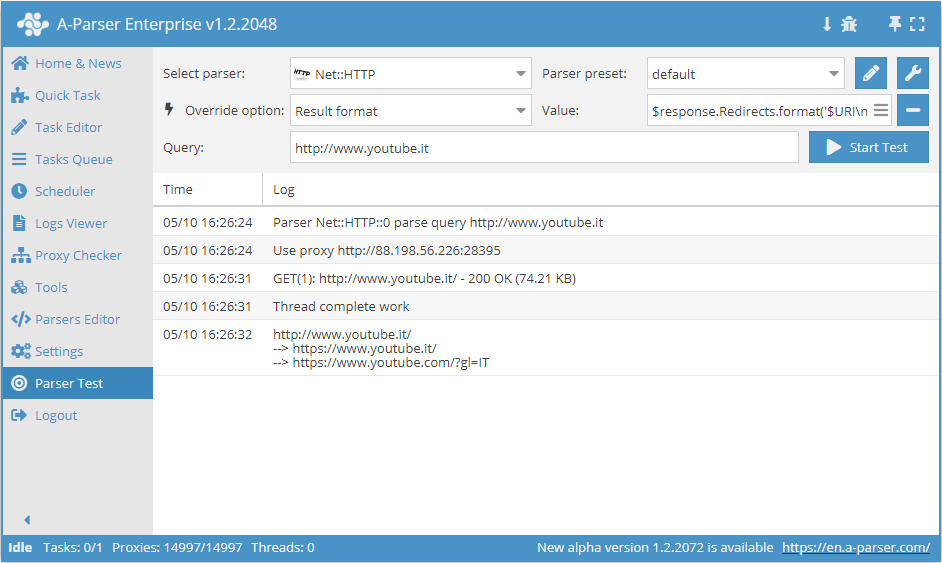
Visualizzazione in JSON con l'uso del motore di modelli per la registrazione della data
L'esempio mostra l'output dei risultati dello scraper  Net::Whois in formato JSON.
Net::Whois in formato JSON.
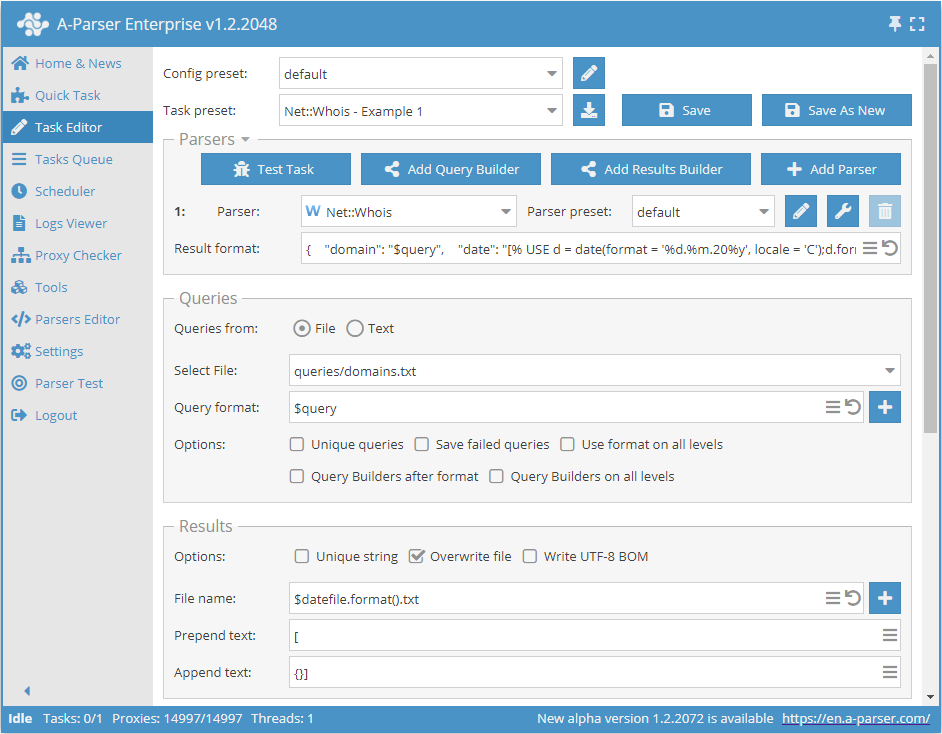
Il risultato sarà il dominio controllato, la data al momento del controllo e il risultato del controllo. Come si vede nel Formato del risultato, otteniamo la data tramite il motore di modelli Template Toolkit.
Formato del risultato:
{
"domain": "$query",
"date": "[% USE d = date(format = '%d.%m.20%y', locale = 'C');d.format() %]",
"expire": "$p1.expire_date",
},
Esempio di risultato:
[{
"domain": "a-parser.com",
"date": "05.05.2021",
"expire": "25.02.2022",
},
{}]
Scarica esempio
Come importare l'esempio in A-Parser
eJxtVG1v2jAQ/ivWCUQrZaxM2pdM+0BRkTYx6ErRPgQ0efWFeXXszHYYVZT/3nMS
EtruQyTf23P33EtK8Nw9uluLDr2DOCkhr98QwxJ9HP/4baRj79jNkWe5QjaBCHJu
HdrgnZw5kUFgygvlYbeLgFDo6ebGZjyglVvNGNuCMBmXegsxvQd/C7RPW4hONu6x
sSRDtlnfMME+s6C8SGsYkkZDMR5m4w9Xw6dRxJR54FQUqWejy09i3LhdXLLhrkfF
Yy5tizvIJ+NG/tkkI6eKPugKXvMD3hsqOJUKe/WcpCXPkAyDEBmsXbqxP3py5UJI
L43mqmEdOtR3YqMl0aV4bcg3MJfo5tZkfa66HaeOJW17gCCKOvZ7EwNxypXDCByV
OucUKl5bpEfLvbGrPNRD+hKMniq1wAOq3q3Gvy6kEjTOaUpBX9rA/7us3mBUHb3z
VAe0/yzVALG3BYHUwvXqWx8kzMLsibj4RbSVzKQn2c1MocOuXJHyETHvWrYMLcuM
xS5LA9zmpvXNUQtyTPqJTfNWV1Y7eEXkxWBeKh+MTuV+RRSsFHjyLPQ93clKz0y4
gsBMF0rRYBze9Qsyde0ggtC18E3wrE4R2Lf3EoE3Rrmva9KF+7KSFvBjKDCjXp5n
bSFp69XmbnFugbOlqrMnJ/F9c3Ku3tLAkNZ3b2ixiFq16865+weU50cdlxWN64+7
bZwCdK2MgDrkaBYQT6pnHsF5pA==
Verifica della presenza del sito in Google News per parola chiave
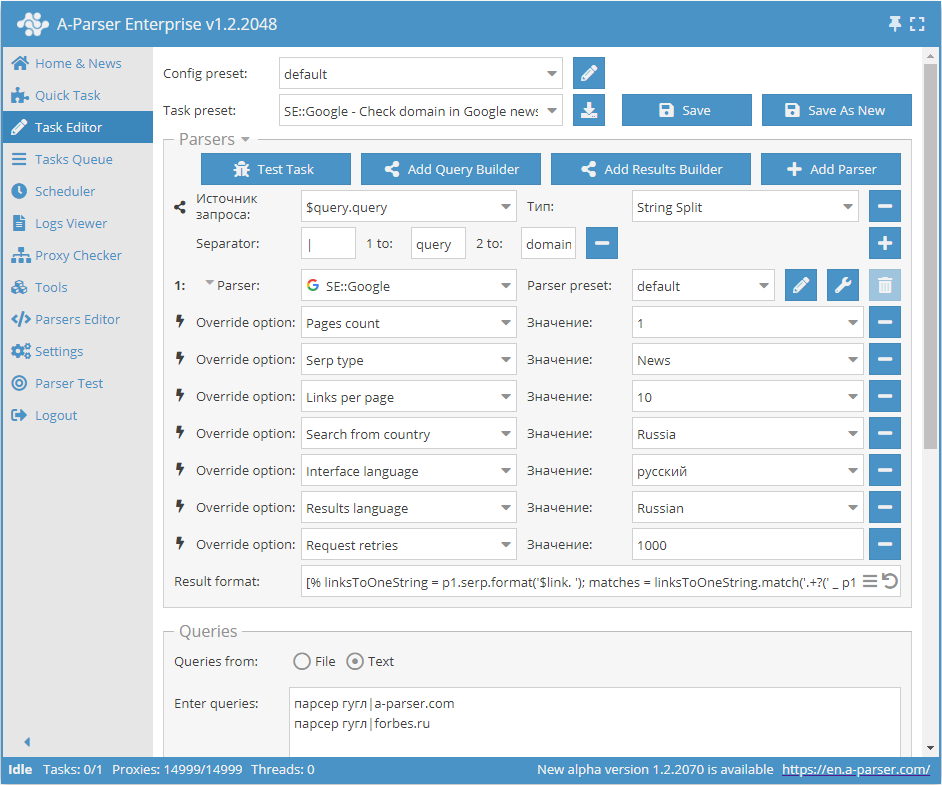
Formato del risultato:
[% linksToOneString = p1.serp.format('$link. ');
matches = linksToOneString.match('.+?(' _ p1.query.domain _ ').+?');
IF matches.0;
p1.query.orig _';yes' _ "\n";
ELSE;
p1.query.orig _';no' _ "\n";
END %]
Esempio di risultato:
scraper google|a-parser.com;no
scraper google|forbes.ru;yes
Scarica esempio
Come importare l'esempio in A-Parser
eJylVVFv2jAQ/iuR1YpWo1EQ7UuqaaIMpk6stKV9AoRccqQeju3aCQVR/vvOTkjS
ruNlEoq4u+++O9+dz1uSUrM0txoMpIaE4y1R7j8JyagXhj+kjDl4Z173GeZLL5IJ
ZcLDX2EQ8Go8WNNEcSBNoqg2oC3PuOaOhggWNOMpaW5JulGA7HIFWrPIGlmEsqIx
zGUmEENWlGeIae3+DccwqkIS8WrIATRnYmkUumCQGn9wwCXmNfr7x0Psz3Wozg4m
omtQTkU8O4xXWq43GlLNwNQ8W0EQkN102iTYLKyr6UudUNu08fFEuNM+yKGAETqK
2PvqqZZvK+YvHO6kcWQxvtc4vZwIVMyfwSDqo6PvTCcN/8u3k4Y3sywvGeiNX8zB
DAnQ5lg+CTvzJmSCFuLM132viOQHqCi5pGYIbVxuwDTeufQGo95nQCE/4G6+T8Tx
lJTFGNEVPEgsxoK54dvXCKUbmtj6HUU0BWvdF+TUT9d28mgUsZRJQXleUTvKVZUf
BXvJx00i1maFbelrmaAqBUfgUt13Y0yOnEyQInO+d7kPCReUG2gSg6n2KSYSlZZU
Z2hgKWiaSj1UNh1Ub4kUHc4HsAJe+Tv6q4zxCK9dZ4FO14Xj55DhXxy78nT1UDiG
rxpzKFmcdDX8VXlFciBjPHj0hMfmLGEpyqbrrnBIAlQuAVRZshtbskRqKMMUzEV0
XEEKhJ35qmMdVaneHcMtKiMzPbfUeY2b+ztk3PSNFGe2IQZwKeUFIW8WJG1f9i75
IJPprmpyLQYq51IsWDwsruV+HDLxgGtzKLrSLj5bJpFxjk02cF8NW8cUTbVCdd6P
zl0XwlZyvyQxScnNz1F+cqUZ5nxhE0ywMfWoBeWccv54P6hbSDWgKEyy4Ly9cN/A
fs/zb8tpLnKN54S2E9rV//bTGz3L97o/lwneuf/iwvv2hBsAt55NO4VYYh9sN939
CUkvf0vssoO1oiKCKL8SO9ej4oEp36tt/ZkJtzucy9/mNgfZqlsI6rB9BofOPil/
AGn6WSM=
Visualizzazione del valore timestamp in formato data
A volte capita che nei risultati non ci sia una data normale, ma un valore timestamp come nello scraper  Social::Instagram::Tag. Questo valore può essere rappresentato in formato data utilizzando il motore di template Template-Toolkit.
Social::Instagram::Tag. Questo valore può essere rappresentato in formato data utilizzando il motore di template Template-Toolkit.
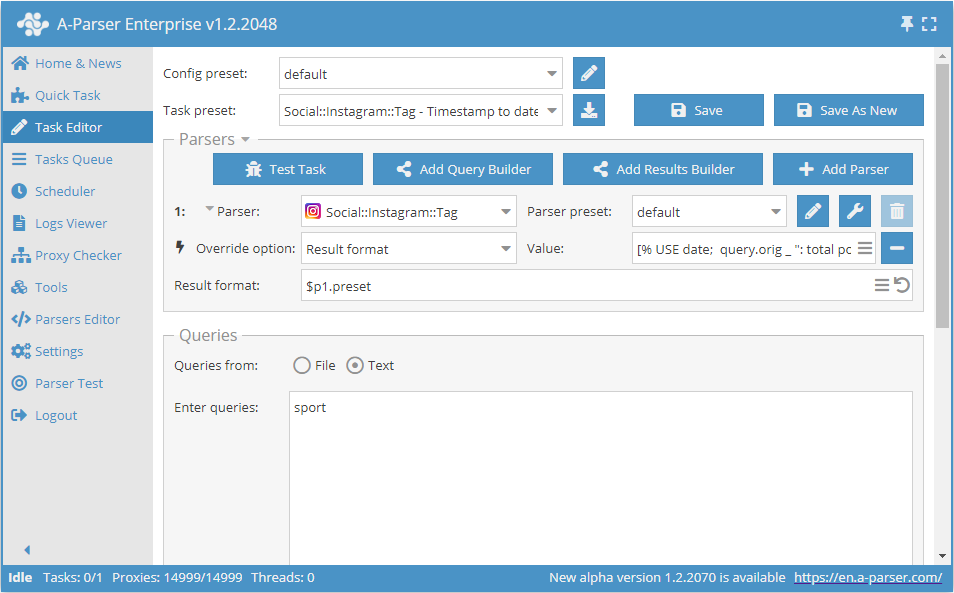
Formato del risultato:
[% USE date;
query.orig _ ": total posts - " _ postscount _ "\nPosts:\n";
FOREACH i IN posts;
d = date.format(i.time, format => '%d.%m.20%y');
i.link _ " - " _ d _ ":\n";
i.text _ "\n";
END %]
Esempio di risultato:
sport: total posts - 96500663
Posts:
https://www.instagram.com/p/COfJHshAkeD/ - 05.05.2021:
Quelques exemples de notre nouvelle campagne de communication personnalisable avec le nom des clubs 😀
Vous préférez quel visuel : 1, 2, 3, 4, 5 ? 🤔
#clubnormand #tennis #padel #beachtennis #tenniscourt #padelcourt #beachtenniscourt #lnt #LigueNormandieTennis #🎾 #sport #normandie #normandietourisme
https://www.instagram.com/p/COfJG7olavg/ - 05.05.2021:
💥 Sau màn lật đổ “Bà già” thành công, Nửa xanh thành Milan chính thức vượt qua Nửa đỏ về số lần lên đỉnh nước Ý nhiều nhất lịch sử.
-----------------------------
➖ Website: https://webthethao247.com/
➖ https://g.page/webthethao247?share
#wtt247 #webthethao247 #thethao #sport #bongda #SerieA #InterMilan #Juventus #ACMilan
https://www.instagram.com/p/COfJG1Hg7ax/ - 05.05.2021:
Which Skill was better 1 or 2? 🤔👇
Follow @ftb4ll for more 💥
Follow @ftb4ll for more 💥
Follow @ftb4ll for more 💥
________________________________________
Leave a Like 👍🏽
Subscribe for more 🔔
Leave your thoughts in the Comments 💬
________________________________________
❌Ignore the Tags ❌
#football #soccer #fussball #futbol #fifa #championsleague #bundesliga #ucl #footballmemes #goal #transfer #sports #penalty #ultimateteam #pacybits #fut #ultras #laliga #freekick #referee #sport #calcio #messi #ronaldo #skills #premierleague #foul #footballseason
https://www.instagram.com/p/COfIlXqhfAa/ - 05.05.2021:
Be Fuckin’ Ready 🤣🤣🤣
Get ready to fly!!!! 🏐🏐🏐🏐
Follow - @crackonkings
#beachball #nalin&kane #trance #music #90s #onyerhead #festival #party #afterparty #love #summer #uk #happy #sesh #crackon #football #sport #festivaloutfit #festivalfashion #sun #dj #dancing #club #festivalgirl #house #techno #rave
...
Scarica esempio
Come importare l'esempio in A-Parser
eJx1VNtuGjEQ/RXLCkoj0VVSqS9bpRKhoFJRNuXyxKLKxQa58dqO7aVBiH/vjPeW
pM0+7RzPzDlzsU80MP/g753wIniark/Uxn+a0oXZSqbSdKJ9YHvHijRdsj15T5ay
EAAVlgRDOAuCiCewlKB9apnzwmGm9RsJwImLHStVoP0TDUcrgMschHOSYwbJwd4Z
V7AASqIbPTBVotu6R1aLUeT8lOtcP5bCHRPj5J78JDlNQVBgiljjgwehOQU4GltT
6hB98lzfI5LCT05jlnE2Hw2GX4kkk1nljnDg5DYyJZWYdzIJUHifVCa5/Uwuezzp
FcmH697x8gpiCHwyUVI/RKpGAa/ENYSVVxBPraAIj2ZfSG9Dz5tNn1aF+3Fkgrov
7E1Sz6U9XLCDWBrslYydb2LAmrECu3WB6vG0qeAqCU+YgXEugzSaqYoBx9WxrrR8
jN3WBnyxxVL4sTMFQKi6Bo+NujW9iDaFFGWM/VHF0HTHlBd96kHqmIEQ/vpEBuFY
MC6zqAfwEzV6oNRUHITq3GL+u1IqDrs12EHQpA78v0v2T45zW95zKti6Pw40tFmi
dZd976K4mZo9VM5/Qd1KFjKA7Ye4T4BeA/gghG17NsOeFcaJlqbOXLPDTbNC44p3
IxvYDnpRxouxvAS3Ru/kPquvTeNZ6iVc50wPDV5HrEuXSsFYvJh36zHw9RjQ6AS+
Dh5GCiy9ua40GKP8t0Ul1ToJ6/cRBRbQyeesdcotU2o1nz4/wUAfjM30yLlX44uL
Qb01Drm2sLx7A2sFpZ037cvSPlWnt96X9HSGuf3291UAFonugEG3PAyFpjfnvwdy
t1Y=