SE::Yandex - Scraper dei risultati di ricerca Yandex
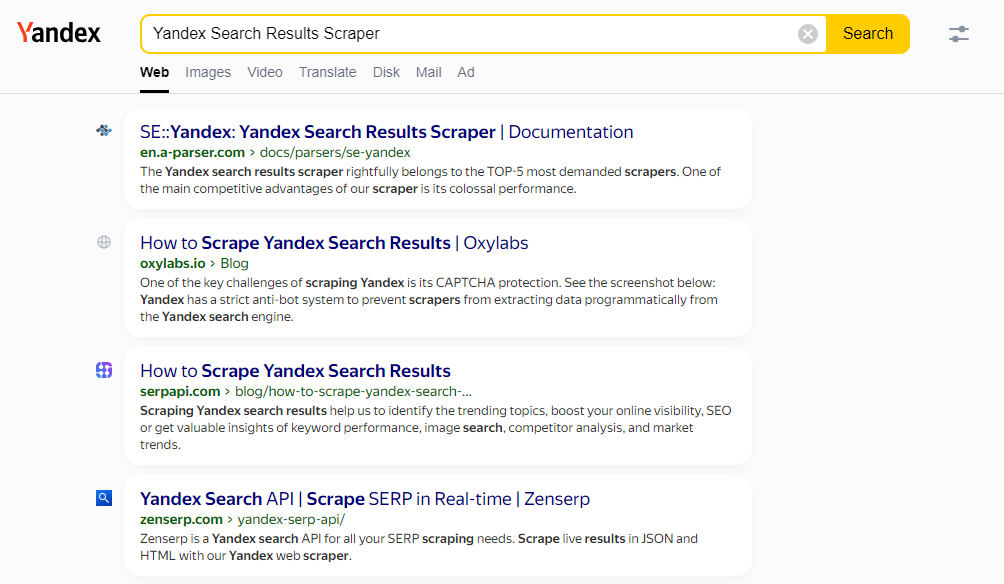
Panoramica dello scraper
Lo scraper della SERP di Yandex è giustamente tra i primi 5 scraper più richiesti. Uno dei principali vantaggi competitivi del nostro scraper è la sua colossale produttività. Grazie al multithreading di A-Parser, la velocità di elaborazione delle query può raggiungere 3000-7000 query al minuto, il che consente mediamente di ottenere fino a 5.000.000 di link al minuto, con un consumo di risorse minimo; per il funzionamento è adatto qualsiasi computer da ufficio o domestico, così come qualsiasi VDS entry-level. Il nostro scraper supporta tutti gli operatori di ricerca di Yandex, il che consente di ampliare notevolmente le possibilità di scraping. La stabilità e la continuità dello scraping della SERP sono garantite dal riconoscimento dei captcha tramite AntiCaptcha o qualsiasi altra API supportata (Anti-Captcha, RuCaptcha, CapMonster.cloud, 2captcha e altre).
La flessibilità nelle impostazioni consente di specificare il tipo di SERP (mobile/desktop), la regione, la lingua, l'ordinamento della SERP per data e molto altro. Le funzionalità di A-Parser consentono di salvare le impostazioni di scraping per un uso futuro (preset), impostare programmi di scraping e molto altro. È possibile utilizzare la generazione automatica delle query, la sostituzione di sotto-query da file, l'iterazione di combinazioni alfanumeriche e liste per ottenere il massimo numero possibile di risultati.
Il salvataggio dei risultati è possibile nella forma e nella struttura necessarie, grazie al potente motore di modelli integrato Template Toolkit che consente di applicare logica aggiuntiva ai risultati ed esportare dati in vari formati, inclusi JSON, SQL e CSV.
Casi d'uso dello scraper
🔗 SERP di Yandex e numero di posizione
Otteniamo la SERP di Yandex e il numero di posizione del risultato. Il risultato viene salvato in un file csv.
🔗 Scraping della versione lite di Yandex
In questo articolo viene esaminato un esempio di creazione di uno scraper per raccogliere informazioni dalla versione lite del motore di ricerca Yandex.
🔗 Scraping di annunci pubblicitari da Yandex
Il preset analizza il blocco pubblicitario nei risultati di ricerca di Yandex e salva il risultato in formato json.
🔗 Valutazione della concorrenza in Yandex
Il preset determina la concorrenza nel motore di ricerca Yandex in base alle parole chiave.
🔗 Scraper della cache di Yandex
Il preset implementa la possibilità di ottenere link alla cache del motore di ricerca Yandex.
🔗 Scraping di soli snippet da Yandex
Questo preset accetta come parametro una parola o una frase per la ricerca in Yandex.
Dati raccolti
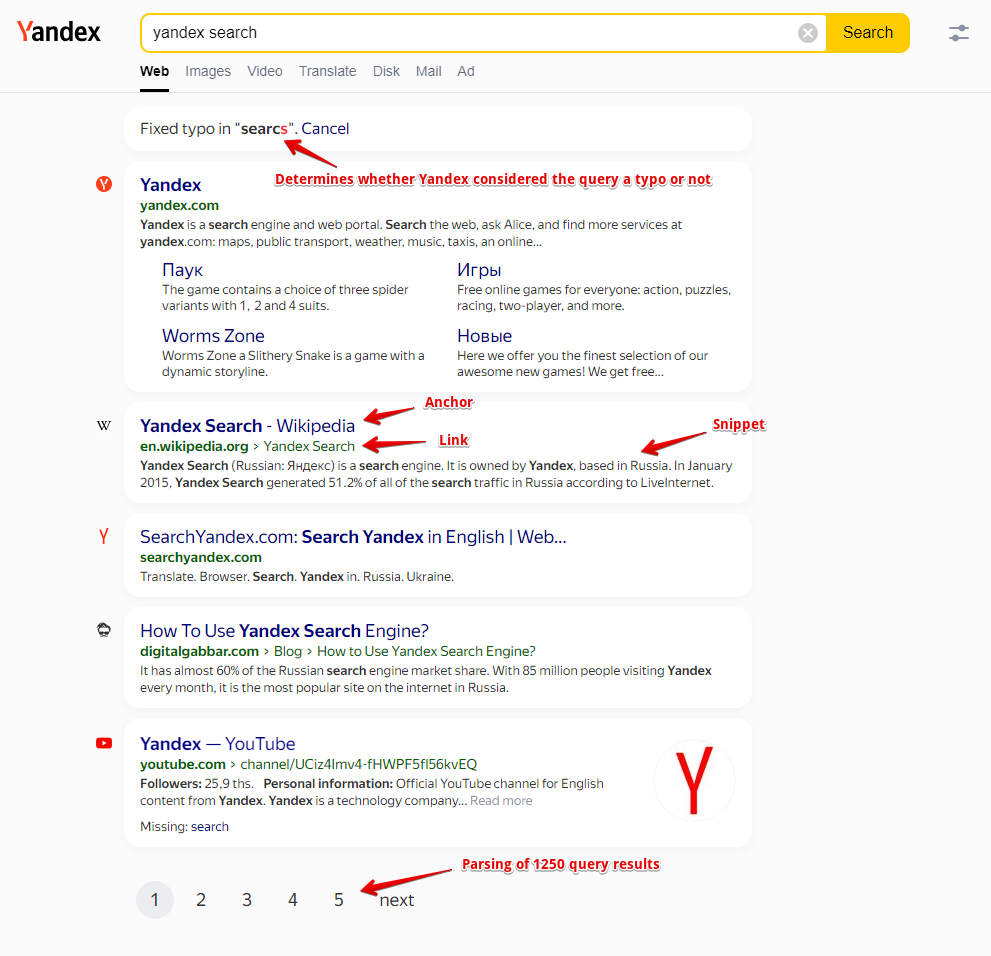
- Numero di risultati per query
- Link, anchor e snippet dalla SERP
- Vengono raccolte anche informazioni sui flag di ogni risultato; attualmente sono supportati i seguenti flag: Date, Image Preview, Video, Rich snippet, Featured snippet
- Ora della prima e dell'ultima memorizzazione nella cache (solo per la SERP desktop)
- Elenco delle parole chiave correlate (Related keywords)
- Determina se Yandex ha considerato la query come un errore di battitura o meno
- Scraping del link alla cache della pagina (solo per la SERP desktop)
- Elenco dei nomi delle icone del sito e dei loro tipi, se presenti (incluso Turbo)
- Blocchi pubblicitari superiore, medio e inferiore da tutte le pagine
- Link, link visibile, anchor, snippet e dominio
- Link e anchor aggiuntivi
- Stazione della metropolitana
- Parole mancanti (parole che possono apparire sotto ogni risultato nella SERP con la nota "Non trovato")
- Elenco delle risposte rapide (Quick answers): domande, risposte, link alle fonti (attivabile con l'opzione separata Parse Quick answers)
- Risposta AI (Ricerca con Alice), il suo tipo e l'elenco delle fonti
Funzionalità
- Scelta del tipo di SERP: mobile/desktop
- Supporto per tutti gli operatori di ricerca di Yandex (site:, lang:, ecc.)
- Esegue lo scraping del numero massimo di risultati forniti da Yandex - 25 pagine da 50 elementi nella SERP
- Possibilità di cercare parole chiave correlate
- Supporta la scelta della regione di ricerca, del dominio
- Possibilità di ordinare la SERP per data
- Esegue lo scraping dell'ora di indicizzazione della pagina, con possibilità di filtrare i risultati per questo parametro
- Opzione di emulazione del browser (consente di ottenere un'alta velocità di scraping e un basso consumo di captcha)
- Possibilità di aggirare i captcha utilizzando il servizio AntiCaptcha o qualsiasi altro che supporti la loro API (si consiglia di attivare il parametro is_russian nelle impostazioni dell'antigate)
- Possibilità di impostare il numero di risposte rapide (Quick answers) che lo scraper deve raccogliere, cliccando in profondità su ogni domanda

Sulla base dello scraper Yandex funzionano i seguenti scraper:
 SE::Yandex::Position - verifica delle posizioni del sito per parole chiave in Yandex
SE::Yandex::Position - verifica delle posizioni del sito per parole chiave in Yandex
Casi d'uso
- Raccolta di database di link - per A-Poster, XRumer, AllSubmitter, ecc.
- Valutazione della concorrenza per le parole chiave
- Ricerca di backlink (menzioni) di siti
- Verifica dell'indicizzazione dei siti
- Ricerca di siti vulnerabili
- Qualsiasi altra variante che implichi lo scraping di Yandex in una forma o nell'altra
Query
Come query è necessario indicare frasi di ricerca, esattamente come se venissero inserite direttamente nel modulo di ricerca di Yandex, ad esempio:
finestre Mosca
lang:en windows Moscow
url:a-parser.com
site:a-parser.com
"a-parser.com"
Sostituzioni nelle query
È possibile utilizzare le macro integrate per moltiplicare le query; ad esempio, se vogliamo ottenere un database molto grande di forum, indichiamo alcune query di base in diverse lingue:
forum
forum
foro
论坛
Nel formato della query indichiamo l'iterazione dei caratteri da a a zzzz; questo metodo consente di ruotare al massimo la SERP e ottenere molti nuovi risultati unici:
$query {az:a:zzzz}
Questa macro creerà 475254 query aggiuntive per ogni query di ricerca iniziale, il che darà un totale di 4 x 475254 = 1901016 query di ricerca; una cifra impressionante, ma non è affatto un problema per A-Parser. Alla velocità di 2000 query al minuto, tale attività verrà elaborata in sole 16 ore.
Utilizzo degli operatori
È possibile utilizzare gli operatori di ricerca nel formato della query, in modo che vengano aggiunti automaticamente a ogni query della lista:
site:$query
Account
Per il funzionamento dello scraper  SE::Yandex potrebbero essere necessari account Yandex. Gli account possono essere registrati utilizzando lo scraper
SE::Yandex potrebbero essere necessari account Yandex. Gli account possono essere registrati utilizzando lo scraper  SE::Yandex::Register o semplicemente aggiungendo gli account esistenti al file
SE::Yandex::Register o semplicemente aggiungendo gli account esistenti al file files/SE-Yandex/accounts.txt nel formato supportato.
Oppure è possibile attivare la registrazione degli account "al volo".
Per lavorare utilizzando l'autorizzazione per sessione, è necessario che la stringa con i dati sia in questo formato:
[email protected];MAQT78Z31Rinx4H;{"answer":"qmfhsxdcrk","proxy":"185.104.120.45:3128","session_id":"3:1748440908.5.0.1748440867459:ZXBxpg:47e4.1.2:1|2191075974.41.2.2:41.3:1748440908|3:10308131.797655.5pfkoRZWgLJGntKTlcUhYdysNfk"}
Esempi di output dei risultati
A-Parser supporta la formattazione flessibile dei risultati grazie al motore di modelli integrato Template Toolkit, che gli consente di produrre risultati in forma libera o strutturata, come CSV o JSON
Esportazione della lista di link
Formato del risultato:
$serp.format('$link\n')
Esempio di risultato:
https://TestoMetrika.com/tests/
https://onlinetestpad.com/ru/tests
https://www.speedtest.net/
https://ustaliy.ru/testi/
https://yandex.ru/internet/
https://konstruktortestov.ru/popular
https://TestEdu.ru/test/
https://kto-chto-gde.ru/category/tests/
https://weekend.rambler.ru/tests/
https://GadalkinDom.ru/test
...
Link + anchor + snippet con output della posizione
Formato del risultato:
[% FOREACH item IN serp; loop.count _ ' - ' _ item.link _ ' - ' _ item.anchor _ ' - ' _ item.snippet _ "\n"; END %]
Esempio di risultato:
1 - http://forum.r-rp.ru/ - <b>forum</b>.r-rp.ru -
2 - https://forum.arizona-rp.com/ - <div class=a11y-hidden>Risultato web con link aggiuntivi</div><b>Forum</b> – Arizona Role Play - Menu. Home. <b>Forum</b>. Nuovi messaggi. Cosa c'è di nuovo? Nuovi messaggi. Utenti. Visitatori attuali. <b>Forum</b>. Accedi. ... Statistiche del <b>forum</b>. Discussioni. 1,247,176. Messaggi. 5,225,340. Utenti. 623,675.
3 - https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC - <b>Forum</b> — Wikipedia - <b>Fórum</b> (lat. <b>forum</b> — arch. vestibolo della tomba; area nel torchio per l'uva da lavorare; piazza del mercato, mercato cittadino; mercato, piazza centrale):
4 - https://zen.yandex.ru/media/propromotion/chto-takoe-forum-i-vse-chto-s-nim-sviazano-5d65164c1d656a00ad52ba30 - Cos'è un <b>forum</b> e tutto ciò che lo riguarda | Creativa... - Oggi parleremo di cos'è un <b>forum</b> e di tutto ciò che lo riguarda con parole semplici e accessibili. Ognuno di noi cerca di trovare una persona con cui costruire una comunicazione su interessi comuni, condividere la propria esperienza, dare consigli. Nel mondo moderno, tutto questo è diventato possibile senza uscire di casa. Proprio una delle forme di tale contatto virtuale è il web-<b>forum</b>.
5 - https://forum.vimeworld.ru/ - VimeWorld - <b>Forum</b> - <b>Forum</b> del progetto di server di gioco ideali Minecraft - VimeWorld...
...
Output di link, anchor e snippet in una tabella CSV
L'utility integrata $tools.CSVLine consente di creare documenti tabulari corretti, pronti per l'importazione in Excel o Google Fogli.
Formato generale del risultato:
[% FOREACH i IN p1.serp; tools.CSVline(i.link, i.anchor, i.snippet); END %]
Nome del file:
$datefile.format().csv
Testo iniziale:
Link,Anchor,Snippet
Nel Formato generale dei risultati viene applicato il motore di modelli Template Toolkit per l'output dell'array $serp in un ciclo FOREACH.
Nel nome del file dei risultati è sufficiente cambiare l'estensione del file in csv.
Affinché l'opzione "Testo iniziale" sia disponibile nell' Editor delle attività, è necessario attivare "Più opzioni". In "Testo iniziale" scriviamo i nomi delle colonne separati da virgola e rendiamo vuota la seconda riga.
Output dei blocchi pubblicitari
Formato del risultato:
$ads.format('$link - $anchor - $snippet\n')
Esempio di risultato:
http://yabs.yandex.ru/count/WcOejI_zO3C2vH80P1zY-_ryBtnaD0K0CmCnZYWCO000000u109mhiMfd8qUW07CkUOvY07Kyz3GCP01vCcQhIwO0PgqhFigk06qZQ3m6C01NDW1gkAR5E01kAZK4-W1y06W0kYCvAl-Wue5-0Bmwl7WeSQurUK1c0FRc3lkh0Ju1Bpr48W5lFKGa0MxjssW1Qxa1QW5hkG5i0Mkv0Mu1OYr9S05eTt90SW5aFn4YkWqZwuhO8VP1W00012H0000gGVlTvJIyeiV0R07W82O3BW7W0Nn1tjIyvgFUtz-X8A0WSIqXdB92j4AXC7wM-4_u3nZJEzt003CKjw5aRa50DaBw0kyzRAxthu1gGn-j62AsN3cl-WCemBW3OE0W4293eDHIPs09kwAqTFvwFMAi8VO3WAX3zaFW13WszlG4DcTXo9ZI0HkD3-n4YxXl0bOc-q2u1E8jIMW58Yr9QWKkxTjl9wVx0Ne58m2q1Mydf_i1TWLmOhsxAEFlFnZyA0Mq92TW0R95l0_q1Qokzw-0O4N0F0_c1UwdvGKg1S9m1Uq0jWNm8GzcHYW60wm68UTi806q1WX-1Yf-9keZlxncYM06R3qkEBGlP6v890P0Q0PmWEm6RWP____0T8P4dbXOdDVSsLoTcLoBt8qEJSjCkWPWC83y1c0mWE16l__WxZFMxv27W2GPM2khLr2HGBSgKCU4fSjR_apLy29ToVZBSaX0K10aLK2xDc6HsxyWlx3mqOzRTCnV7G7IDvEXnY4YqauFXdHmHcIWrcJNGT1NfMC_8eB8q1m1-WEYbKFtWBTZHwcD4A80G00~1?from=yandex.ru%3Bsearch%26%23x2F%3B%3Bweb%3B%3B0%3B&q=%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C+%D0%B0%D0%B2%D0%B8%D0%B0%D0%B1%D0%B8%D0%BB%D0%B5%D1%82%D1%8B&etext=2202.wBaB7RlytlP_PRaU6jPhHD2nHBNT_4gSF6009OyJEfpWjUPoA5WrSJAqCfap0m9ReXhoaGRlaWhmYmllemF2ZA.f04b1271668949ea17ffcafcb11c72c2ab6454c5 - <b>Acquista</b> <b>biglietto aereo</b> per / aviasales.ru - Offriamo: <b>Acquista</b> <b>biglietto aereo</b> per qui. Super offerta! Affrettati!
http://yabs.yandex.ru/count/WgGejI_zO5e2rHG092HY-_ryhkYFF0K0MWCnZYWCO000000u109mhDZpa8WGW07ZZm680U2f-wrQa07AywxRoe20W0AO0ShphjjAk06oWAxe8C01NDW1e8MobW7W0TJCXm_e0O01c0BImFq2e0BuQjW20l02g_w3YWNu0l3gyU2XnhZLvG600vF6eiSFY0FStR-O39W3cyKxYga3-0JJpWI81TFE1905Z-zGe0MPj06e1PMM0R05bPO1k0NInnJ01TF1ZG781PNz8uheD8-kAs27sGO0000GaG000Aa7xtUKqlAB7m6m1u20c0ou1u05yGTxKlEQZtj_VeI2l3M02W712l_aZtPQIU8_oGeJ5NRdMhxJFweB4E0yOqplTm00p5BUXP6v1G3P2-WBqyu4y0i6Y0ookzw-0QaCu_jL-Yu3zB_e3AC2u0s3W810YGwgO5HI9w3dYj7J-UZrYh27s0u2-0x7dPAe2Q4FFGhNet0zzZ_P3_0_W13GmC4Rm92GPpgqxC9xJZC_iHAuM7p6uhZj0k0JqiSKe1JInnIe58_lKB0KYw381hWKmAo0jQI04TWK-FpP_WNe58m2q1Nu_Dd-1TWLmOhsxAEFlFnZyA0Mq92TW0R95j0MihlUlW615vWNfwZz3wWN2S0Nj0BO5y24FPaOe1WAi1Z9fB201j0O8VWOgVYRg8x-yPebW1cmzBZYqBsHkI2G6G6W6S83i1cu6V___m7I6H9vOM9pNtDbSdPbSYzoD3atBJBe6O320_0PWC83WHh__oD2TTsApne0jsLWrgrT_2INXiZt8r8kcvWxe0SCE37tPBmjEYG0203ecjreFlD0AY-khXXjgcFZa190IXd9BOrkl3guMzzraExES_xHXH4WwWDq1xIoUlHJ6Y74~1?from=yandex.ru%3Bsearch%26%23x2F%3B%3Bweb%3B%3B0%3B&q=%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C+%D0%B0%D0%B2%D0%B8%D0%B0%D0%B1%D0%B8%D0%BB%D0%B5%D1%82%D1%8B&etext=2202.wBaB7RlytlP_PRaU6jPhHD2nHBNT_4gSF6009OyJEfpWjUPoA5WrSJAqCfap0m9ReXhoaGRlaWhmYmllemF2ZA.f04b1271668949ea17ffcafcb11c72c2ab6454c5 - <b>Acquista</b> <b>biglietto aereo</b> online su Tutu.ru! Sito ufficiale! - Biglietti aerei a basso prezzo! Voli vantaggiosi in tutto il mondo! <b>Acquista</b> biglietto online!
http://yabs.yandex.ru/count/WcOejI_zO3C2vH80P1zY-_ryBtnaD0K0CmCnZYWCO000000u109mhiMfd8qUW07CkUOvY07Kyz3GCP01vCcQhIwO0PgqhFigk06qZQ3m6C01NDW1gkAR5E01kAZK4-W1y06W0kYCvAl-Wue5-0Bmwl7WeSQurUK1c0FRc3lkh0Ju1Bpr48W5lFKGa0MxjssW1Qxa1QW5hkG5i0Mkv0Mu1OYr9S05eTt90SW5aFn4YkWqZwuhO8VP1W00012H0000gGVlTvJIyeiV0R07W82O3BW7W0Nn1tjIyvgFUtz-X8A0WSIqXdB92j4AXC7wM-4_u3nZJEzt003CKjw5aRa50DaBw0kyzRAxthu1gGn-j62AsN3cl-WCemBW3OE0W4293eDHIPs09kwAqTFvwFMAi8VO3WAX3zaFW13WszlG4DcTXo9ZI0HkD3-n4YxXl0bOc-q2u1E8jIMW58Yr9QWKkxTjl9wVx0Ne58m2q1Mydf_i1TWLmOhsxAEFlFnZyA0Mq92TW0R95l0_q1Qokzw-0O4N0F0_c1UwdvGKg1S9m1Uq0jWNm8GzcHYW60wm68UTi806q1WX-1Yf-9keZlxncYM06R3qkEBGlP6v890P0Q0PmWEm6RWP____0T8P4dbXOdDVSsLoTcLoBt8qEJSjCkWPWC83y1c0mWE16l__WxZFMxv27W2GPM2khLr2HGBSgKCU4fSjR_apLy29ToVZBSaX0K10aLK2xDc6HsxyWlx3mqOzRTCnV7G7IDvEXnY4YqauFXdHmHcIWrcJNGT1NfMC_8eB8q1m1-WEYbKFtWBTZHwcD4A80G00~1?from=yandex.ru%3Bsearch%26%23x2F%3B%3Bweb%3B%3B0%3B&q=%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C+%D0%B0%D0%B2%D0%B8%D0%B0%D0%B1%D0%B8%D0%BB%D0%B5%D1%82%D1%8B&etext=2202.wBaB7RlytlP_PRaU6jPhHD2nHBNT_4gSF6009OyJEfpWjUPoA5WrSJAqCfap0m9ReXhoaGRlaWhmYmllemF2ZA.f04b1271668949ea17ffcafcb11c72c2ab6454c5 - <b>Acquista</b> <b>biglietto aereo</b> per / aviasales.ru - Offriamo: <b>Acquista</b> <b>biglietto aereo</b> per qui. Super offerta! Affrettati!
...
Salvataggio delle parole chiave correlate
Formato del risultato:
$related.format('$key\n')
Esempio di risultato:
<b>test</b> tanki online
tanki online
tutti i <b>test</b> punto ru
i exam ru test
<b>test</b> velocità internet
<b>tests</b>24.ru
speedtest
test<b>prestazioni pc</b> online
test online
my <b>test</b> student come scoprire le risposte
...
Per rimuovere automaticamente i tag HTML nel risultato, è necessario utilizzare il Costruttore di risultati, selezionare l'array $related e applicare Remove HTML tags.
Concorrenza delle parole chiave
Formato del risultato:
$query - $totalcount\n
Esempio di risultato:
tutti i test punto ru - 25000000
test online - 13000000
tanki online - 7000000
i exam ru test - 27000000
tests24.ru - 238000000
test online prestazioni pc - 16000000
speedtest - 2000000
test velocità internet - 16000000
test tanki online - 19000000
my test student come scoprire le risposte - 16000000
Definizione di parole chiave con errori
Formato del risultato:
$query - $misspell\n
Esempio di risultato:
test online - 0
test velocità internet - 0
test onlain - 1
test velocià intrnet - 1
Verifica dell'indicizzazione dei link
Formato della query:
site:$query
Formato del risultato:
$query.orig - $totalcount\n
Esempio di risultato:
https://a-parser.com/pages/buy - 2
https://a-parser.com/wiki/parsers - 16
https://trjkjfkdf.bg.ky - 0
https://a-parser.com/resources - 1000
https://a-parser.com/forum - 499
Per verificare l'indicizzazione dei link, inseriamo nel Formato della query l'operatore corrispondente: site:.
Il formato del risultato viene visualizzato come "url originale - numero di pagine nell'indice".
Come risultato otteniamo l'indirizzo delle pagine e il loro numero nell'indice del motore di ricerca.
Se la pagina è assente, il risultato sarà: 0.
Salvataggio in formato SQL
Formato del risultato:
[% FOREACH serp; "INSERT INTO serp VALUES('" _ query _ "', '"; link _ "', '"; anchor _ "')\n"; END %]
Esempio di risultato:
INSERT INTO serp VALUES('test', 'https://konstruktortestov.ru/popular', 'Popolari <b>test</b>')
INSERT INTO serp VALUES('test', 'https://TestoMetrika.com/tests/', ' <b>Test</b> c online con risultati accurati da psicologici...')
INSERT INTO serp VALUES('test', 'https://ustaliy.ru/testi/', ' <b>Test</b> online: i migliori, interessanti e popolari')
INSERT INTO serp VALUES('test', 'https://www.SunHome.ru/tests/Interesting_tests', 'Interessanti <b>test</b>. Sottoponiti a interessanti test psicologici...')
INSERT INTO serp VALUES('test', 'https://onlinetestpad.com/ru/tests', ' <b>Test</b> online | Online Test Pad')
...
Dump dei risultati in JSON
Formato comune del risultato:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.links = [];
FOREACH item IN p1.serp;
obj.links.push(item.link);
END;
obj.json %]
Testo iniziale:
[
Testo finale:
]
Esempio di risultato:
[{"totalcount":113000000,"links":["https://TestoMetrika.com/tests/","https://konstruktortestov.ru/popular","https://ustaliy.ru/testi/","https://www.SunHome.ru/tests/Interesting_tests","https://GadalkinDom.ru/test","https://zen.yandex.ru/tes","https://onlinetestpad.com/ru/tests","https://kto-chto-gde.ru/category/tests/","https://psytests.org/top.html","https://MixTests.com/new/","https://TestEdu.ru/test/","https://testserver.pro/index","https://onedio.ru/tests","https://BankTestov.ru/","https://weekend.rambler.ru/tests/","https://edieta.org/testi","https://trikky.ru/?%21","https://BBF.ru/tests/","https://dropi.ru/c/tests/raznie","https://cadelta.ru/tests","https://www.Elle.ru/tests/","https://www.adme.ru/svoboda-psihologiya/polnyj-spisok-psihologicheskih-testov-dlya-poznaniya-sebya-kotorye-mozhno-projti-onlajn-2071715/","https://www.ellegirl.ru/tests/","https://test.tankionline.com/","https://vraki.net/onlajn-testy/","https://Lifehacker.ru/psixologicheskie-testy/","https://iq2u.ru/tests","https://www.b17.ru/tests/","https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%81%D1%82","https://gurutest.ru/test/","https://www.psychologies.ru/tests/","https://peopletalk.ru/category/tests/","https://obrazovaka.ru/testy","https://likeyou.io/category/test/","https://ProfTest.me/tests","https://TayniyMir.com/testy","https://psi-technology.net/psytest/","https://www.kp.ru/putevoditel/online-test/","https://tvoytest.ru/","https://twizz.ru/tests/","https://lunanews.net/testy/","https://www.ivi.ru/titr/tests","https://sntch.com/tests/","https://testy.online/","https://videouroki.net/tests/","https://www.speedtest.net/ru","https://rb.ru/tests/","https://aznaetelivy.ru/tests/","https://woman-psy.com/psihologicheskie-testy/testy_na_eruditsiyu_i_znaniya/interesnye_testy/","https://mamochka-club.com/psihologicheskie-testy/interesnye-testy/"]}]
Affinché le opzioni "Testo iniziale" e "Testo finale" siano disponibili nell' Editor delle attività, è necessario attivare "Più opzioni".
Elaborazione dei risultati
A-Parser consente di elaborare i risultati direttamente durante lo scraping; in questa sezione abbiamo riportato i casi più popolari per lo scraper Yandex
Deduplicazione dei link
Aggiungere la deduplicazione e selezionare dall'elenco a discesa $serp.$i.link - Link.
Scarica esempio
Come importare l'esempio in A-Parser
eJx9VE2P2jAQ/SurEYdWQqvQLpfcWFSqVnTZLuyhohy8ZIJcHNu1HQqK+O+dCUkc
ttVeoszze/NtVxCE3/tHhx6Dh3Rdga3/IYXlpzT9IXSGx5u51Ht/86zl7xJhCFY4
j47p6x6LDjLMRakCDCsIJ4vkxBzQOZmxSmZkW2eOJ4fBSfSEHYQqmTZKkgTOb8jE
Drem1CFqRm/QFedr0bEsKsZJT1K2xVC5nHK6BqrJEsBi2AwbxupC95Sx3kGLflbm
RShIgyvxvNm0XvzMuEJw8wZ2dNt0sjtcigOuDB3mUsXIfkbWgyg4yiATAfn0Nq8d
vXt/G47sQWSZDNJooS4RuPcxajOYFLQhLv1yd2fOFAQFrB0weGqzW8OgtmOV3y8a
SHOhPA7BU6ozQYlkr09kQCeCcQvL+RBegdETpeZ4QBVptf/7UqqMFmWSk+hLI/w/
ZfGPj3NXXj8UDfqPoxw6L7V1v/gWVZmZmx1Vnr3UwyxkINtP6+1JISFwj2i7nj1w
zwrjsAvTeG6i092wqHmr4sgmNkJXZVyN5RrcGp3L3aLZ1JZZ6hVdwIWemsIq5Lp0
qRSNxeNTXI+Jb8bARkzwtXhah+DS23sIwRjlvy4vqVonaf3GnGBBnexHbVxuhVLP
T/P+CcSVIuNnmdzdfeDvx3H9P7ogwNqAO0NbRZWdN90r0b0tVf+tSKszjeqXf7yQ
uC6mEEYN8jQHvuB/AYBymo0=
Vedere anche: Deduplicazione dei risultati
Deduplicazione dei link per dominio
Aggiungere la deduplicazione e selezionare dall'elenco a discesa $serp.$i.link - Link. Scegliere il tipo di deduplicazione: Dominio.
Scarica esempio
Come importare l'esempio in A-Parser
eJx9VE2P2jAQ/SvI4tBKCIV2ueTG0lK1ost2YQ8V5WDIBLk4tms7FBTx33fGCXHY
VnuxPG/mzbddMc/dwT1acOAdS9cVM+HOUrb8nKY/ucrg1JsLdXC9ZyX+lNDbnnuf
dMGFYgNmuHVgibju2KMig5yX0rNBxfzZALrTR7BWZIBKkaFsrD6dLXgrwCF25LIk
s1GSJOzyBo3vYadL5SNn9Ia5pMwNWKJFxjjpUMpQFiqxcEo5XTOsySBAZLYZNBar
2jy71l6jX6TecslSb0u4bDZXL26mbcGpjX0zGjY9bZVLfoSVRmUuZIzsZig98IKi
9DPugbTDPDh6937oT+SBZ5nwQisu6wjU+xi1HhHylUZbvFJ3Z1YXCHkIDgg8X7Nb
s36QY5U/ag5Lcy4dDJjDVGccE8lea4QHy722C0P5IF4xrSZSzuEIMpoF//elkBku
yiRH0teG+H+TxT8+Lm153VA46L8Wc2i9BOl+8T2yMj3XexrZNgyzEB5lNw3bk7IE
wQOAaXv2QD0rtIU2TOO5iY6vxICirYojm5gI3ZRxM5ZbcKdVLvaLZlOvlqVa4VNc
qKkujASqS5VS4lgcPMX1mLhmDCTEBF+TpyEElX59h8xrLd23ZZ2qsQLXb0wJFtjJ
btTG5Y5L+fw072pYXCkUfpXJ3d0HOj+Ow31UI4y4HvYatworu2zaX6L9ZaruX5FW
FxzVb/dYG1FdZIIYNsjhHOiBvwAa7J3h
Vedere anche: Deduplicazione dei risultati
Estrazione dei domini
Aggiungere il Costruttore di risultati e selezionare la fonte dall'elenco a discesa: $p1.serp.$i.link - Link. Scegliere il tipo: Extract Domain.
Scarica esempio
Come importare l'esempio in A-Parser
eJx9VEtv2zAM/isFkcMGBIGzNRff0qwBNmRN17SHIetBi+lAiyxpkpwlMPzfR8qO
7XZDL4b5+Eh+fKiCIPzB3zv0GDyk2wps/IcUNrdp+l3oDE9Xt6fgxC5cfTKFkNrD
GKxwHh0jtgNHMmSYi1IFGFcQzhYpjjmiczJDMsqMZOvM6ewwOIkc6ShUyW7TJEmg
fgMm9rgzpQ49ZvqGu5L64C06hvWIWVI/P4+BKFKNfmlcIZjqyE4nLe/OuBFHfDRk
zKXCXr0k6U4UnHKUiYBsneQx0Lv3k3DiCCLLZJBGC9Vk4Db1WZ+0/B0Za0O+9MuN
WDpTkCpgDMDK86W6LYyiDBSijNhvDQbSXCiPY/BU6lJQIdlriwzoRDBubbke0ldg
9FypFR5R9W4x/k0pVUYznecE+twC/++y/idG3dEbpqKZ/HFUQxclSjfrrz0qMyuz
J+bZT+KtZCEDyX4RB51CQsoDou16dsc9K4zDLk0buc1Om2xR8wL0I5vbXvWCxoux
DJQVeFO6HeXbJuMt0KLbWJw+AG9Pu3HYHEVzEzx158SZ9K17MO0WQk2YndG53K/b
Jb1kLvUjnd9aL0xhFXKfdKkUjdnjQ79uc9+OlYWe8GvwIqbgVl5OkGowyn/ZNNSt
k1TSjAkXNJlh1jbkTij19LAaWqBfURJ+lMn19Qf+fpzF/2mjAcYG3BvaUmLGhNsH
ontZquEzkVY1jf6Xv2+cmBe7kI4a5GmufNt/AaiMmIc=
Vedere anche: Costruttore di risultati
Rimozione dei tag da anchor e snippet
Aggiungere il Costruttore di risultati e selezionare la fonte dall'elenco a discesa: $p1.serp.$i.anchor - Anchor. Scegliere il tipo: Remove HTML tags.
Aggiungere nuovamente il Costruttore di risultati e selezionare la fonte dall'elenco a discesa: $p1.serp.$i.snippet - Snippet. Scegliere il tipo: Remove HTML tags.
Scarica esempio
Come importare l'esempio in A-Parser
eJyVVN9v2jAQ/lcii4dNQihs5SVvFA11Ey0dtA8T64NHLszDsT3bYaCI/313jknS
rqq0lyi+u++7X59dM8/d3t1bcOAdyzY1M+GfZWz9Kcu+cZXDMVlBqQ+Q3DzcLhLP
dy4prC6Tqdr+1NYlGJOslTCGKIbMcOvAEtmmx4GOHApeSc+GNfMnA5gCSa0VOaBT
5Hg2Vh9PFrwVQEwHLisKG6dpys5vwPgOtrpSvsOM3wiXQu2dAUuwDjFJz09PQ4bd
Y41urm3JaQoDMx7FkbTONT/Ag0ZnISR05jme7nhJKQc590DeURGI3r0f+SMx8DwX
XmjFZZOBxtRlfVTid+hYaYzFXxrEHGeNJg+BgIynS3UbNghnhhRVwH5tMCwruHQw
ZA5LnXMsJH/pER4s99ouDdWD9pppNZVyAQeQXVjgv66EzHGn0wJBnyPw9ZDlPxzn
tr1+KtzJH4s1tCzhdL287VC5Xugddp7/wL6lKIXHs5uFRWcsReMewLQzu6OZldpC
myYyx+wocgOKBNCtbGo607M2nq2lZ6yZ05XdYr5NOtwwFLqhrYabwEg/UXM23Jgb
X0pyW8tPaIzRnqQTISTT1xhdc5/+i/KCOSNmq1Uhdsuo/Es7lXrA675UM10aCTR8
VUmJ2nGw6jQ8dVErdOim+BI8CyloP5d7jWVo6b6sm3kaK7CqyTAW3s8aKbdcysfV
ou9hne7x8L1Kr64+0PfjJPyPGwsjrIedRuljZ9RwfHXal6zuvz1ZfUY9/XL3TRD1
RSFowwE5FAs9GH8BhLW+Jg==
Il Costruttore di risultati può essere aggiunto tutte le volte che è necessario.
Vedere anche: Costruttore di risultati
Filtrare i link per inclusione
Aggiungere un filtro e selezionare dall'elenco a discesa: $serp.$i.link - Link. Scegliere il tipo: Contiene la stringa. Successivamente, in Stringa è necessario scrivere il criterio di filtraggio; ad esempio, se vogliamo che vengano salvati solo i link che contengono .com, scriviamo questo in "Stringa".
Scarica esempio
Come importare l'esempio in A-Parser
eJx9VE2P2jAQ/SvI4tBKCMFhL7mxqEit6LJd2EOFOHjxJHJxbNd2KCjKf++ME+Kw
rfaW+Xhv3nw4NQvcn/yzAw/Bs2xfMxu/Wca2X7LsJ9cCLqOVVAGc1MXo7TryIX5J
PVJSn9iEWe48OELvByAMCMh5pQKb1CxcLSCnOYNzUgAGpUDbOnO5OkBG8Og7c1VR
2nw2m7HmAxgv4GgqHRJm/kE66fQWHMES4mE2gOSxQwxi9yQ52zPsyaIjNnmYdBm7
Nv1odOBSDyRPj6ZE09ggjUbbg/asORxujH5lXMlprmM7n3ZD7oNbfoadaXVAcuPc
4YmXxD8WPABFp3kk+vR5Gi7EwIWQVJOrtgLtIVV91fJ31KcN5uInTXrlUGvGAkQC
cl5v6vZsHG3quIrYHy2GZTlXHibMo9QVRyHifUTifHgwbhNngP6aGb1Qag1nUCkt
8j9WUgk8mkWOoK8d8P8pm384mr69YSlc+h+HGnqWaD1uvieUMGtTYOfiLS62lAFt
v4yXlLEZOk8Atp/ZE82sNA76Mh1zVx2fjQVNF5ZWtrDJddfG3VrunXhNuSw23dXe
Miu9w7e50UtTWgXUl66UwrV4eEnnsfDdGshIAt+Dl7EEtX57kywYo/y3bSvVOonn
90ACS5zksGpHeeRKvb6shxGWTiqekyfaI95pYfCCsIvm0P8d+l9MPfxHZHWDa/nl
n9sk6oFS0IfD8PElzZu/Z6ed/A==
Vedere anche: Filtri dei risultati
Impostazioni possibili
| Nome parametro | Valore predefinito | Descrizione |
|---|---|---|
| AntiGate preset | default | Scelta del preset  Util::AntiGate, dettagli sulla configurazione qui Util::AntiGate, dettagli sulla configurazione qui |
| AntiGate preset for old captcha | default | Simile a AntiGate preset, ma utilizzato solo per i captcha ordinari (vecchi, sotto forma di singola immagine). Se non viene selezionato un preset qui, per tali captcha verrà utilizzato il preset selezionato in AntiGate preset. |
| Experimental img captcha max count | 5 | Numero massimo di tentativi di captcha immagine ripetuti per tentativo |
| Preffered captcha type | Click | Scelta del tipo di captcha preferito: Click o Puzzle |
| Engine | HTTP (Fast, JavaScript Disabled) | Consente di scegliere il motore: HTTP (più veloce, ma maggiore probabilità di captcha) o browser (più lento, ma minore probabilità di captcha) |
| Device | Modern desktop computer (Windows 10, Chrome 84) | Scelta del tipo di SERP (Desktop computer / Mobile device) |
| Pages count | 5 | Numero di pagine da sottoporre a scraping (da 1 a 25) |
| Sort serp by date | ☐ | Ordinamento della SERP per data |
| Serp time | All time | Periodo di ricerca |
| Yandex domain | www.yandex.ru | Dominio Yandex per lo scraping, sono supportati tutti i domini (.ru, .ua, .by, .kz, .com.tr, .com). A partire dalla versione 1.1.345 viene selezionato automaticamente in base alla regione scelta. |
| Region of serp (lr=) | Mosca | Scelta della regione di ricerca (parametro lr=) |
| Custom region ID | Possibilità di specificare l'id di una regione non presente nel campo di selezione. Questa opzione ha la priorità sull'opzione Region of serp (lr=). È obbligatorio impostare il dominio corrispondente in Yandex domain. | |
| Search sites from (rstr=) | Not set | Scelta del vincolo regionale dei siti (parametro rstr=) |
| Language | Any | Lingua dei risultati di ricerca (Russo, Inglese, Bielorusso, Francese, Tedesco, Indonesiano, Kazako, Tataro, Turco, Ucraino) |
| Parse not found | ☑ | Determina se eseguire lo scraping della SERP se per la query cercata sono stati trovati zero risultati ed è stata proposta una SERP per un'altra query |
| Not personalized | ☐ | Personalizzazione della ricerca. Dettagli qui |
| Filter pages | Moderate filter | Filtraggio dei risultati da contenuti indesiderati (Family search / Moderate filter / Do not filter) |
| Use Accounts | ☐ | Lavoro con gli account esistenti nel file files/SE-Yandex/accounts.txt. SE::Yandex::Register - Consente di registrare account in Yandex |
| Remove bad accounts | ☑ | Rimozione degli account non validi |
| Quick answers count | 0 | Numero massimo di domande-risposte (Quick answers) per ogni query che lo scraper deve raccogliere |
| Parse generative answer | ☐ | Se eseguire lo scraping della risposta generativa (questo aggiunge una sotto-query supplementare e di conseguenza rallenta il lavoro complessivo) |
| Accounts | Only from "accounts.txt" | Scelta del metodo di lavoro con gli account: Always auto register - registra sempre automaticamente gli account "al volo", è necessario selezionare un preset configurato nel parametro SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - vengono prima utilizzati gli account esistenti da accounts.txt, e se terminano viene utilizzata la registrazione automatica "al volo", per la quale è necessario selezionare un preset configurato nel parametro SE::Yandex::Register preset. Only from "accounts.txt" - utilizza solo gli account esistenti da accounts.txt, e se terminano attende il tempo impostato (parametro Wait new accounts in "accounts.txt") per la comparsa di nuovi. Only by session_id from "accounts.txt" - autorizzazione tramite cookie. |
| Remove bad accounts | Always, except wrong login/password | Rimozione automatica degli account "cattivi": Always - rimuovi sempre. Always, except wrong login/password - rimuovi sempre, tranne nei casi in cui Yandex ha segnalato che sono stati indicati login/password errati. Il fatto è che Yandex può fornire tale messaggio in caso di ban dell'IP per un account assolutamente funzionante, quindi opzionalmente è possibile lasciare tali account per un riutilizzo. Never - non rimuovere mai. Indipendentemente dall'opzione scelta, in caso di errori del proxy/browser gli account non vengono rimossi |
| Use sessions | ☑ | Utilizzo delle sessioni |
| Wait new accounts in "accounts.txt" | 0 | Tempo di attesa per la comparsa di nuovi account in accounts.txt |
| SE::Yandex::Register preset | default | Scelta del preset di impostazioni per SE::Yandex::Register |
| Force neuro | ☐ | Attivazione forzata della risposta neurale, simile al passaggio manuale tra "Ricerca" e "Ricerca con Alice" |