Deduplicazione dei risultati
Deduplicazione, rimozione dei duplicati, rimozione delle ripetizioni: tutto questo implica che non abbiamo bisogno di risultati ripetuti. In A-Parser esistono 2 metodi di deduplicazione, analizziamoli in dettaglio.
Deduplicazione dei risultati per riga
Questo metodo funziona dopo la formazione del risultato; immediatamente prima di scrivere il risultato nel file, ogni riga viene controllata per l'unicità e solo le nuove righe uniche vengono scritte nel file.
Vedi anche: Ordine di elaborazione delle query
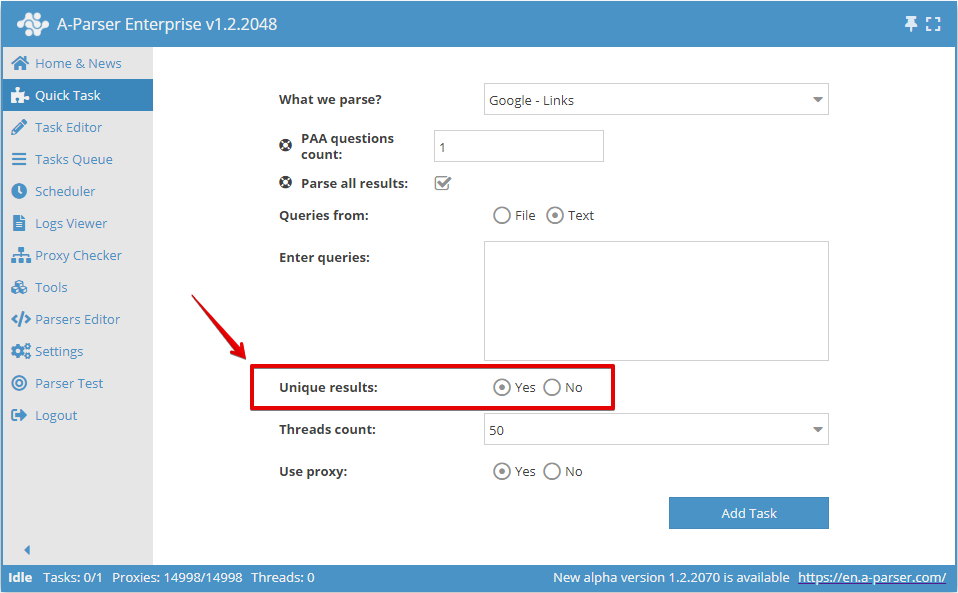
È possibile attivare l'unicità per riga in Quick Task:
O nel Task Editor:
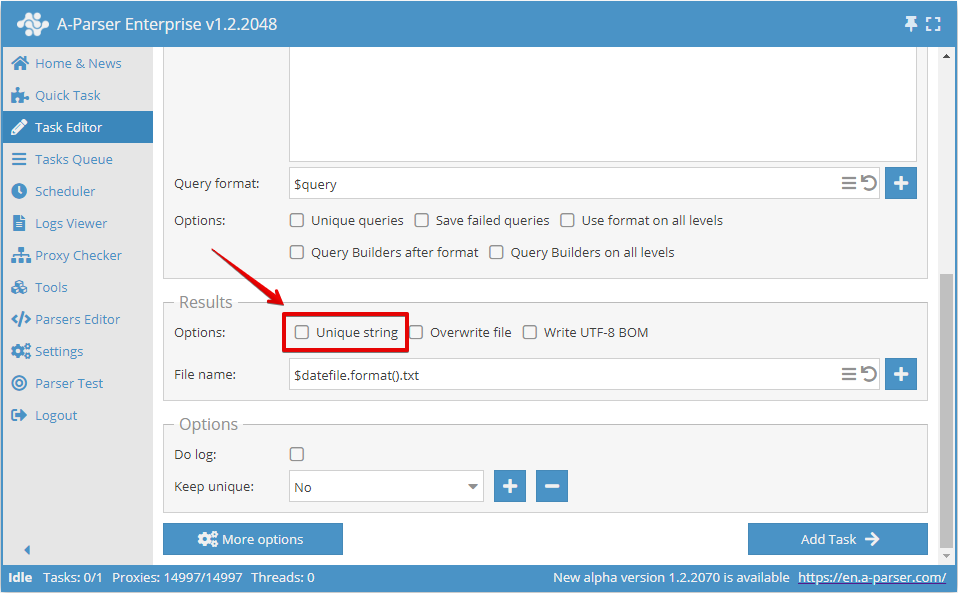
Deduplicazione per qualsiasi risultato
La deduplicazione per qualsiasi risultato consente di eseguire la deduplicazione direttamente sul risultato selezionato di uno specifico scraper. È possibile aggiungere questo tipo di deduplicazione nel Task Editor, cliccando sull'icona dello strumento a destra dello scraper e premendo Add unique result (Aggiungi la deduplicazione):
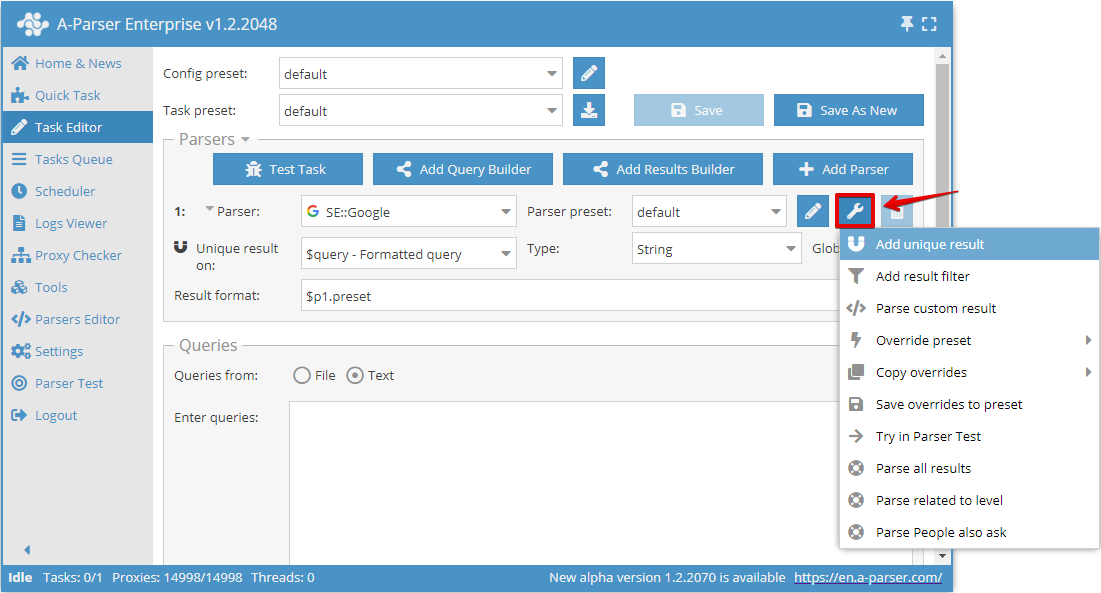
Ora è possibile scegliere su quale risultato eseguire la deduplicazione e il tipo di deduplicazione:
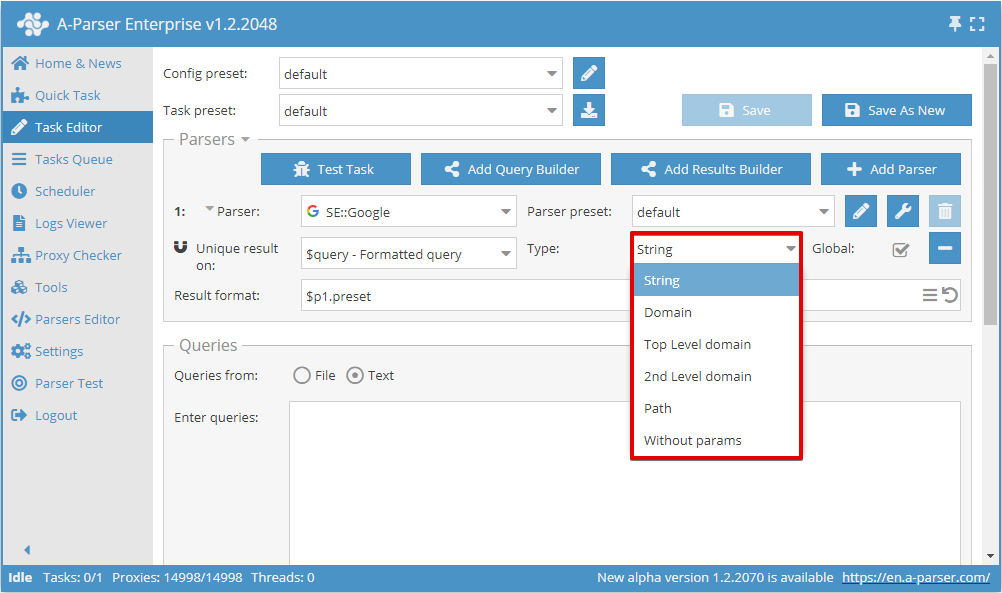
L'interruttore Global (Globalmente) viene utilizzato quando sono selezionati 2 o più scraper; esso determina se eseguire una deduplicazione comune o separata per ogni scraper.
Tipo di deduplicazione
| Parametro | Descrizione |
|---|---|
| String | Deduplicazione per riga (viene confrontata l'intera riga del risultato) |
| Domain | Deduplicazione per dominio (viene confrontato l'intero dominio, ad esempio www.domain.com e domain.com sono domini diversi) |
| Top Level domain | Deduplicazione per dominio principale tenendo conto dei domini regionali, commerciali, educativi e altri (ad esempio domain.co.uk e domain2.co.uk sono domini diversi, mentre sub1.domain.com e sub2.domain.com sono uguali) |
| Dominio di 2° livello | Deduplicazione per dominio di secondo livello (vengono confrontati i domini di secondo livello, ad esempio www.domain.com, domain.com e user.subdomain.domain.com sono tutti lo stesso dominio) |
| Path | Deduplicazione per percorso (vengono confrontate le parti del link fino al file, ad esempio http://domain.com/path1/file.php e http://domain.com/path1/file2.php hanno parti del link fino al file identiche) |
| Without params | Deduplicazione per link senza parametri (vengono confrontati i link senza parametri, ad esempio http://domain.com/file.php?page=1 e http://domain.com/file.php?page=2 sono link identici) |
Deduplicazione delle query
La deduplicazione delle query invia allo scraping solo query uniche, non precedentemente elaborate nell'attività corrente. Casi d'uso principali:
- Se nelle query originali sono presenti duplicati e non è desiderabile sottoporli a scraping (doppio lavoro)
- Quando si utilizza l'opzione Parse to level (Scansiona fino al livello), è necessario utilizzare solo query univoche per prevenire la proliferazione e il loop delle query (ad esempio quando si utilizza lo scraper
 HTML::LinkExtractor)
HTML::LinkExtractor)
In tutti gli altri casi, l'uso non necessario della deduplicazione delle query rallenterà solo il lavoro complessivo dello scraper
Salvataggio dello stato di deduplicazione tra le attività
Esiste la possibilità di salvare il database di deduplicazione per l'utilizzo in attività future, il che consente di salvare solo nuovi risultati univoci nelle nuove attività (ad esempio i link durante lo scraping della SERP in  SE::Google)
SE::Google)
Per salvare il database di deduplicazione, è necessario creare un nuovo nome per il database quando si aggiunge la prima attività:
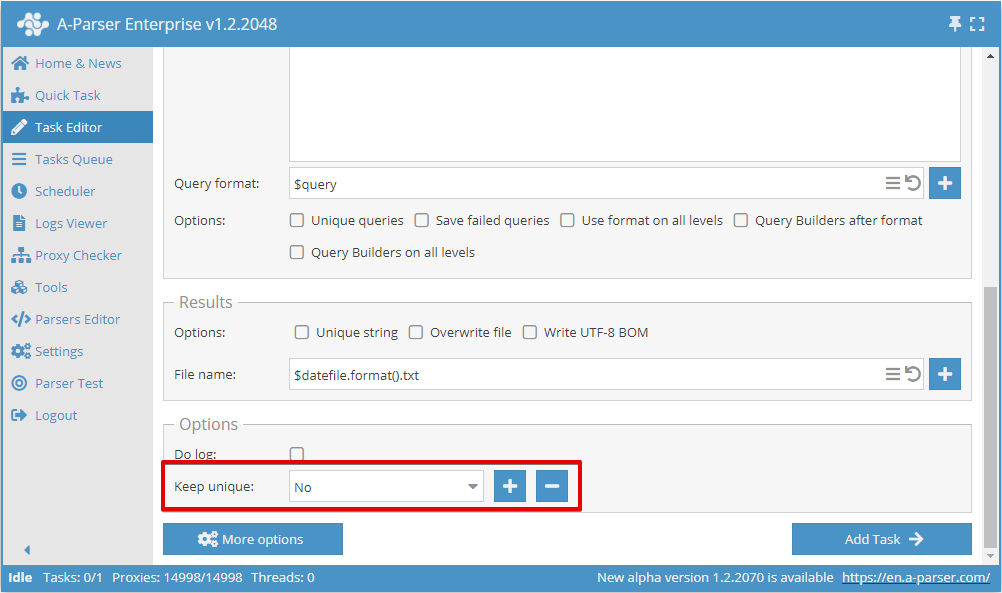
Per tutte le attività successive, è necessario selezionare il nome del database creato in precedenza; in questo modo verranno salvati solo i nuovi risultati unici, indipendentemente dal fatto che i risultati vengano scritti nello stesso file della prima attività o in un nuovo file.