Net::HTTP - Scraper di base universale con supporto per lo scraping multipagina e bypass di CloudFlare
Panoramica dello scraper
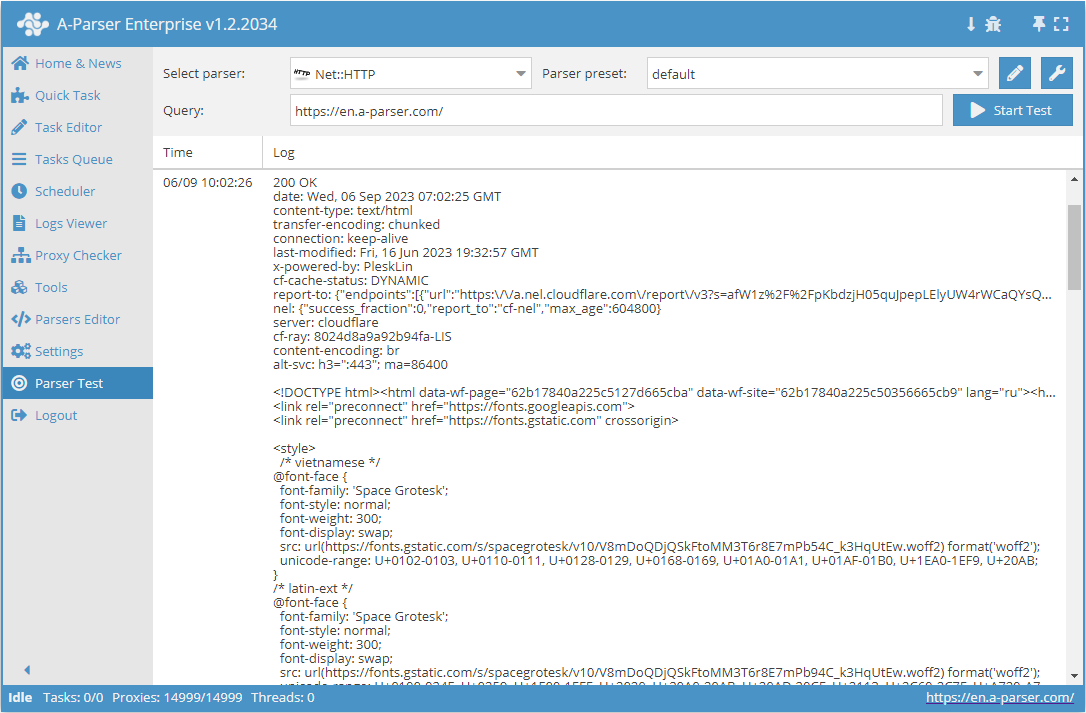
 Net::HTTP – è uno scraper universale che consente di risolvere la maggior parte delle attività non standard. Può essere utilizzato come base per lo scraping di contenuti arbitrari da qualsiasi sito. Consente di scaricare il codice della pagina tramite link, supporta lo scraping multipagina (navigazione tra le pagine), il lavoro automatico con i proxy e consente di verificare la risposta corretta in base al codice o al contenuto della pagina.
Net::HTTP – è uno scraper universale che consente di risolvere la maggior parte delle attività non standard. Può essere utilizzato come base per lo scraping di contenuti arbitrari da qualsiasi sito. Consente di scaricare il codice della pagina tramite link, supporta lo scraping multipagina (navigazione tra le pagine), il lavoro automatico con i proxy e consente di verificare la risposta corretta in base al codice o al contenuto della pagina.Casi d'uso dello scraper
🔗 Asta domini REG.RU
Scraping dell'asta dei domini in scadenza con possibilità di filtraggio
🔗 Dati del certificato SSL
Scraping dei dati del certificato SSL dei domini dal sito leaderssl.ru
🔗 Scraping della risorsa Booking.com
Ottenimento dei risultati di ricerca per appartamenti e hotel sul sito
🔗 Raccolta delle caratteristiche del prodotto
Esempio di scraping di un numero sconosciuto di caratteristiche del prodotto
🔗 Scraping del database di film da IMDB
Ottiene i dati di ogni film e li scrive nel risultato
🔗 Verifica della presenza di HTTPS
Il preset verifica la presenza di HTTPS sul sito
Dati raccolti
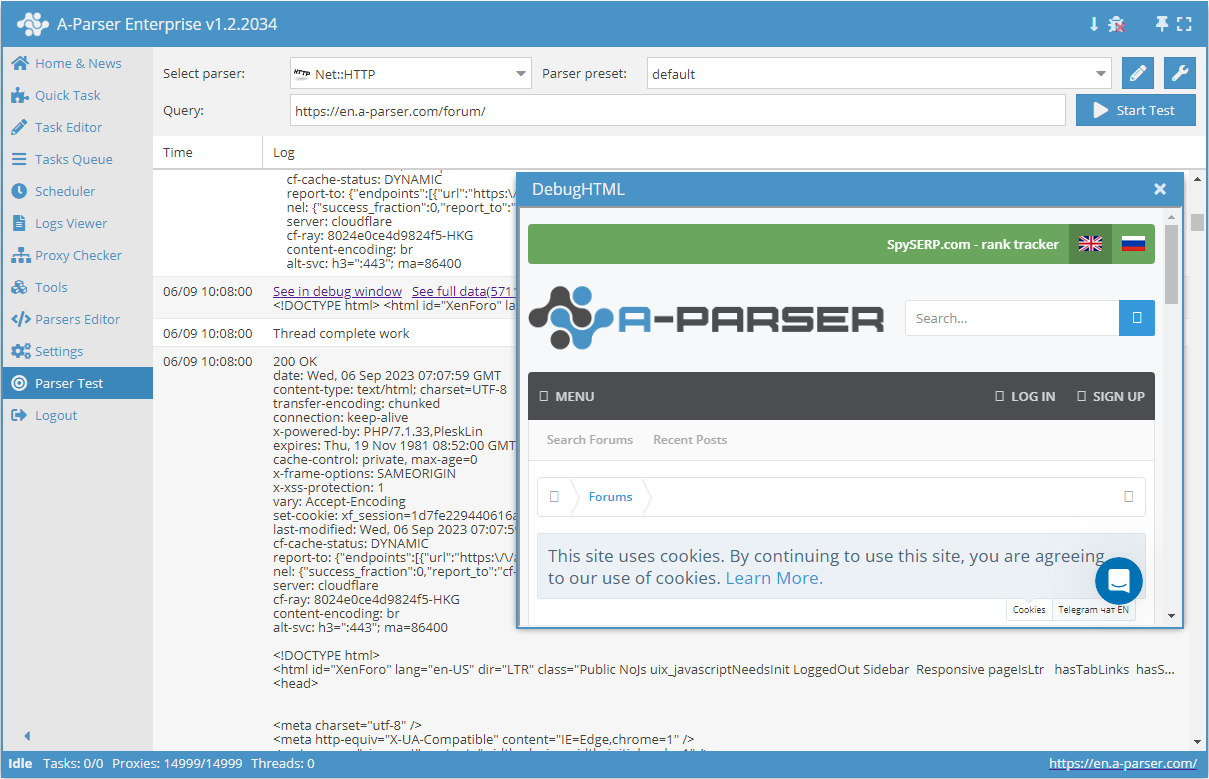
- Contenuto
- Codice di risposta del server
- Descrizione della risposta del server
- Intestazioni della risposta del server
- Proxy utilizzati durante la richiesta
- Array con tutte le pagine raccolte (utilizzato quando l'opzione Use Pages è attiva)
Funzionalità
- Scraping multipagina (navigazione tra le pagine)
- Gestione automatica dei proxy
- Verifica della risposta corretta tramite codice o contenuto della pagina
- Supporta la compressione gzip/deflate/brotli
- Rilevamento e conversione delle codifiche dei siti in UTF-8
- Bypass della protezione CloudFlare
- Scelta del motore (HTTP o Chrome)
- Opzione Check content – esegue l'espressione regolare specificata sulla pagina ottenuta. Se l'espressione non corrisponde, la pagina verrà caricata nuovamente con un altro proxy.
- Opzione Use Pages – consente di scorrere un numero specificato di pagine con un determinato passo. La variabile
$pagenumcontiene il numero della pagina corrente durante l'iterazione. - Opzione Check next page – è necessario specificare un'espressione regolare che estrarrà il link alla pagina successiva (solitamente il pulsante "Avanti"), se esistente. La navigazione tra le pagine avviene entro il limite specificato (0 - senza limiti).
- Opzione Page as new query – il passaggio alla pagina successiva avviene in una nuova richiesta. Consente di rimuovere il limite al numero di pagine per la navigazione.
Varianti di utilizzo
- Download di contenuti
- Download di immagini
- Verifica del codice di risposta del server
- Verifica della presenza di HTTPS
- Verifica della presenza di reindirizzamenti
- Visualizzazione dell'elenco degli URL di reindirizzamento
- Ottenimento della dimensione della pagina
- Raccolta di meta-tag
- Estrazione di dati dal codice sorgente della pagina e/o dalle intestazioni
Query
Come query è necessario specificare i link alle pagine, ad esempio:
http://lenta.ru/
http://a-parser.com/pages/reviews/
Esempi di output dei risultati
A-Parser supporta la formattazione flessibile dei risultati grazie al motore di modelli integrato Template Toolkit, che gli consente di produrre risultati in forma arbitraria, così come in forma strutturata, ad esempio CSV o JSON
Output del contenuto
Formato del risultato:
$data
Esempio di risultato:
<!DOCTYPE html><html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<!-- Google Tag Manager -->
<!-- End Google Tag Manager -->
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<base href="https://a-parser.com/" />
<title>A-Parser - lo scraper per i professionisti SEO</title>
<noscript><style>.JsOnly, .jsOnly { display: none !important; }</style></noscript>
<link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" />
Codice di risposta del server
Formato del risultato:
$code
Esempio di risultato:
200
Il formato del risultato [% response.Redirects.0.Status || code %] consente di visualizzare lo stato 301 se nella richiesta sono presenti reindirizzamenti.
Ottenimento dei dati sulla richiesta
La variabile $response aiuta a ottenere informazioni sulla richiesta e sulla risposta del server
Formato del risultato:
$response.json\n
Esempio di risultato:
{
"Time": 3.414,
"connection": "keep-alive",
"Decode": "Decode from utf-8(meta charset)",
"cache-control": "max-age=3600,public",
"last-modified": "Tue, 18 May 2021 12:42:56 GMT",
"transfer-encoding": "chunked",
"date": "Thu, 27 May 2021 14:18:42 GMT",
"Status": 200,
"content-encoding": "gzip",
"Body-Length-Decoded": 1507378,
"Reason": "OK",
"Proxy": "http://51.255.55.144:25302",
"content-type": "text/html",
"Redirects": [],
"server": "nginx",
"Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n",
"URI": "https://a-parser.com/",
"HTTPVersion": "1.1",
"Body-Length": 299312,
"Decode-Mode": "auto-html",
"etag": "W/\"60a3b650-170032\"",
"Decode-Time": 0.003,
"IP": "remote",
"expires": "Thu, 27 May 2021 15:18:42 GMT"
}
Ottenimento dei reindirizzamenti
Query:
https://google.it
Formato del risultato:
$response.Redirects.0.URI -> $response.URI
Esempio di risultato:
https://google.it/ -> https://www.google.it/
JSON con reindirizzamenti
Formato del risultato:
$response.Redirects.json
Esempio di risultato:
[{"x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n"}]
Output dello stato della risposta del server
Formato del risultato:
$reason
Esempio di risultato:
OK
Tempo di risposta del server
Formato del risultato:
$response.Time
Esempio di risultato:
1.457
Ottenimento della dimensione della pagina
Come esempio, la dimensione è presentata in tre diverse varianti.
Formato del risultato:
[% "data-length: " _ data.length _ "\n";
"Body-Length: " _ response.${'Body-Length'} _ "\n";
"Body-Length-Decoded: " _ response.${'Body-Length-Decoded'} _ "\n" %]
Esempio di risultato:
data-length: 70257
Body-Length: 23167
Body-Length-Decoded: 75868
Elaborazione dei risultati
A-Parser consente di elaborare i risultati direttamente durante lo scraping; in questa sezione abbiamo riportato i casi più popolari per lo scraper Net::HTTP
Output dei tag H1-H6
Aggiungere una regex (opzione Parse custom results (Usa regex)) <(h\d+)[^>]+>(.+?)<\/h\d+>, nel campo "Parse result" scegliere $pages.$i.data - Page content, nel campo accanto alla regex scegliere i modificatori sg. Come tipo di risultato verrà selezionato automaticamente un array. Nel campo "Name" indicare headers, poi in "$1 to" indicare tag, fare clic su

content. Nel formato generale del risultato impostare l'output $p1.headers.format('$tag - $content\n').Scarica esempio
Come importare l'esempio in A-Parser
eJxtVNuO2jAQ/RVkIS2IW3loH6IVFYuK2ooSlmWfIJUsMgR3HTu1HboI8e+dcUIC
tE+Jj+ccn7nYJ+a4fbMLAxacZcH6xDL/zwI2BxcEX1erRWOrpYStEypp7Ie9/SfW
ZRk3Fgwx1nUg4jHseC4d656YO2aAMtvcOp0uwXqYmeInWKNEApYo3HEW0U4C70h4
bO03m7jTXv8cRZ1Rq9/53H7cbAYeHLEyblWI26SSLBFuDD8i6L9znhK2Bx6T2Uso
2cbEibvVyoFyLDpHUbU91SblVIJmNuyX5P7Og62HJhIbvUazZG426qFdK7/wA6w0
UndCQg1PcVWaaWK+QLsXxXbfvVNleBwLJ7TisjifXNaeXpX4nRNfaYzFXyPATo1O
EXLgBQg8XryvWdOvqbK55z4XHBbsuLTQZRatTjkaie93hAPDnTZhRn4QPzGtxlLO
4ACyDvP6T7mQVJ/xDknfSuL/Q8J/NM5VetdHHcD8MeihUvGrp/BHzYr1TCeXYkiR
CodrO9G5orZ9QPANIKtqNqewVBuojimVy9Nx/jNQMUbWLRtnNXSTxk1bbkGciZ1I
QkzAiBgukbla4SUL1USnmQTKS+VSYlssLOvxGNuyDbSoDd6TJ/4ItFXdNOa0lvb7
S2E1MwLH7yMZTLGS16eWklsu5etydr1DRLylWai+GHPXPj8YbO9cZoPBgPeKm9/f
6nRA9weHOdE4ZpjqOarehepBOV29DsHpjK37ZRdFDOVJEYhhwSz2hQXD81+VjpX2
Raccolta di meta-tag
Aggiungere una regex (opzione Parse custom results (Usa regex)) (<meta[^>]+>), nel campo "Parse result" selezionare $pages.$i.data - Page content, nel campo accanto alla regex selezionare il modificatore g. Come tipo di risultato verrà selezionato automaticamente un array. Nel campo "Name" indicare meta, in "$1 to" indicare item. Nel Formato del risultato utilizzare $p1.meta.format('$item\n').
Scarica esempio
Come importare l'esempio in A-Parser
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB
bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj
3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm
Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z
Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL
SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9
iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK
zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY
rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF
Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY
i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1
gDE=
Varianti di navigazione della paginazione
Utilizzo di Use pages
Use pages. Questa funzione consente di navigare attraverso la paginazione specificando in anticipo il numero di pagine noto.
Per esempio, prendiamo una delle categorie sul sito del catalogo prodotti https://www.proball.ru/catalog/myachi/. In alto e in basso vediamo il pannello di paginazione. Cliccando sulle icone con i numeri di pagina, si può vedere nella barra del browser come avviene il passaggio del parametro con il numero di pagina alla fine della richiesta:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
Use pages è una sorta di contatore che sostituisce effettivamente i numeri in ordine nella variabile $pagenum, aumentandoli del valore che specifichiamo
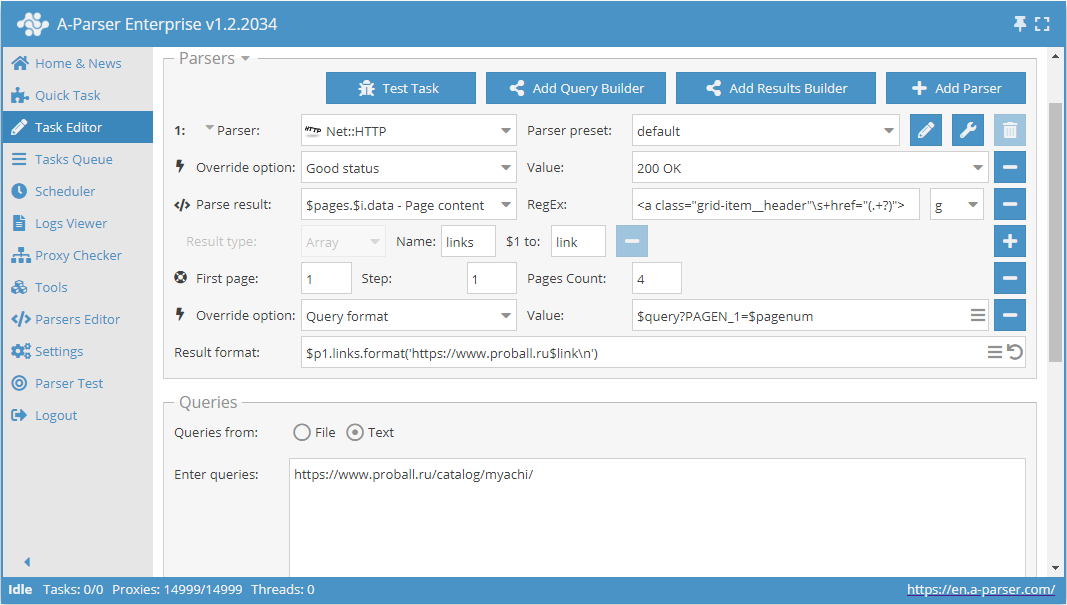
Come si vede nello screenshot, nel formato della richiesta dello scraper viene utilizzata la variabile $pagenum nel punto appropriato.
La funzione Use pages itererà e sostituirà tutti i valori nella richiesta, ottenendo effettivamente i link per la richiesta
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum
dove al posto della variabile $pagenum verrà inserito il numero della pagina, partendo da 1 fino a 4 con passo 1.
In questo modo si ottiene la navigazione attraverso le pagine dell'intervallo desiderato. In questo risiede il limite di questo metodo: è necessario conoscere in anticipo il numero di pagine presenti nella paginazione. È ovvio che durante lo scraping simultaneo di più categorie, il numero di pagine sarà diverso ovunque e, come soluzione, possiamo semplicemente indicare un numero maggiore di pagine previste. Ma questo non è del tutto corretto, quindi esiste una soluzione più ottimale, di cui parleremo più avanti
Scarica esempio
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2
pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn
PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0
9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+
1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh
9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob
jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4
YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5
QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u
kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp
sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9
P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8
z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M
vOJ4VZ5BGJXHUBcgGBZ/AXULzRU=
Utilizzo di Check next page
Check next page è un'altra funzione che consente di organizzare la navigazione attraverso la paginazione. La particolarità del suo utilizzo è che per passare alla pagina successiva è necessario utilizzare un'espressione regolare che restituirà il link alla pagina successiva. Questo è un metodo più comodo e applicato più frequentemente. Ma non sarà possibile applicarlo per https://www.proball.ru/catalog/myachi/, poiché nel codice non ci sono link alle pagine successive. I link lì sono generati da uno script. Pertanto, prendiamo come esempio il sito http://www.imdb.com/search/name?gender=female. Qui c'è la paginazione sia all'inizio che alla fine dell'elenco. Guardando e analizzando il codice sorgente, si può vedere la presenza di un link che consente di passare alla pagina successiva:
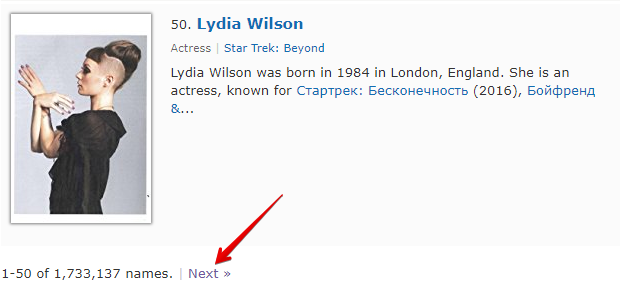
- nel campo Next page RegEx scriveremo l'espressione regolare
- nel campo Limit (Limite) indicheremo il numero di pagine da percorrere
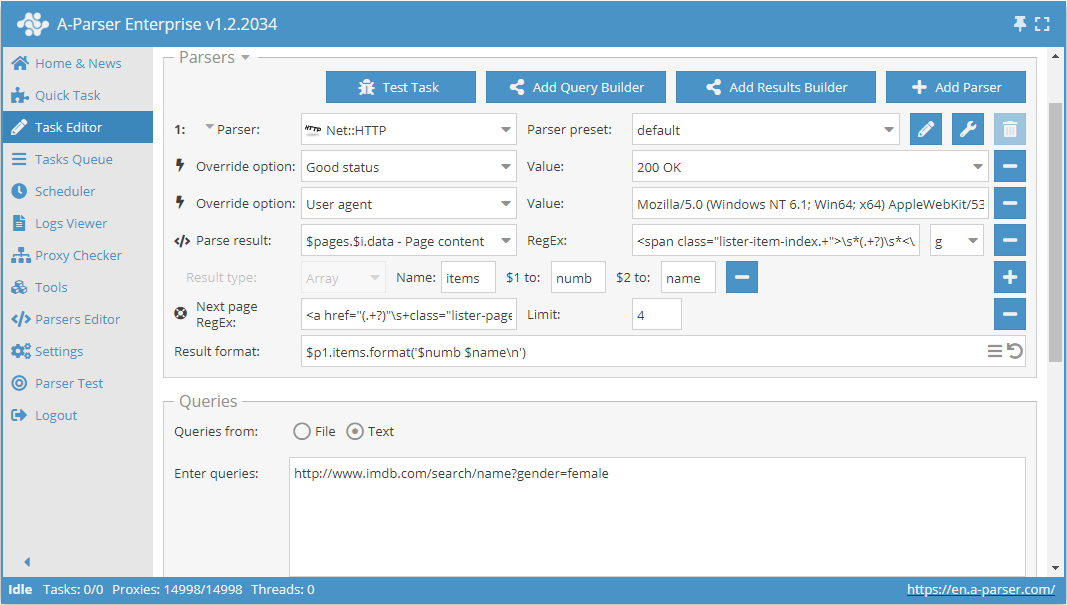
Nell'esempio è indicato 4. Specificando il limite, determiniamo quante pagine lo scraper deve percorrere. Nel nostro caso verranno percorse 5 pagine, poiché il conteggio inizia da 0. Se si specifica il limite 0, lo scraper lavorerà finché non avrà percorso tutte le pagine indipendentemente dal loro numero. Questo è molto comodo da usare quando è necessario sottoporre a scraping tutti i risultati di tutte le pagine
Scarica esempio
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS
sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr
gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp
ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I
22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY
FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI
HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu
NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O
MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7
exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x
+JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L
itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy
KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18
bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq
iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU
tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY
11r9ASIaBUM=
Come detto sopra, è possibile limitare dinamicamente il numero di pagine in Use pages. Per fare ciò, è necessario utilizzare congiuntamente Use pages e Check next page. Integriamo l'esempio esaminato nella descrizione di Use pages e aggiungiamo la funzione Check next page:
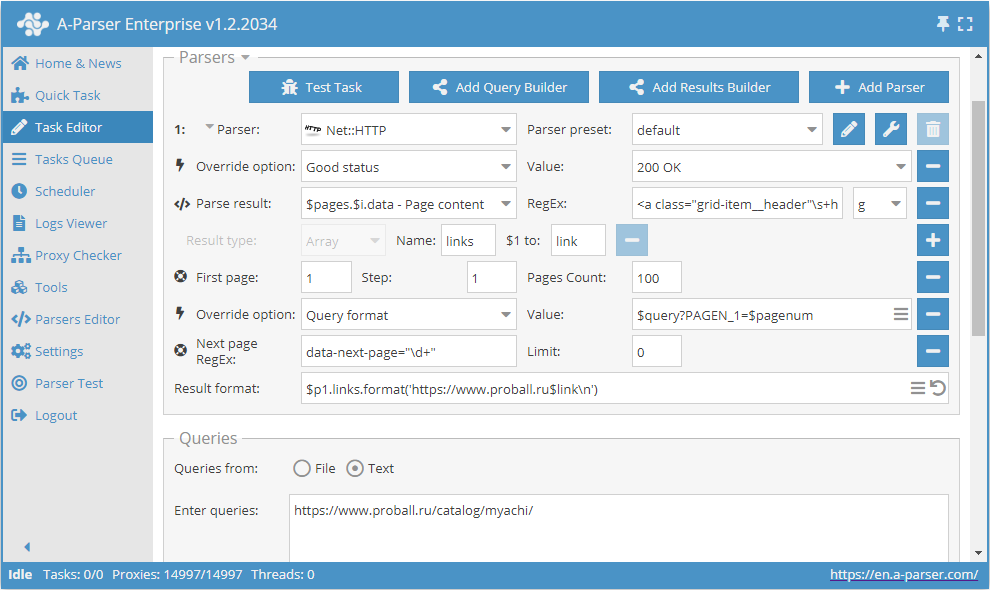
Queste due funzioni in coppia lavorano nel seguente modo: Use pages garantisce la navigazione tra le pagine, mentre Check next page verifica se esiste la successiva. Non appena Check next page non troverà la pagina successiva, lo scraping di questa categoria verrà interrotto senza attendere il completamento di tutto il numero indicato in Use pages. Combinando queste funzioni, aggiungiamo efficienza al lavoro dello scraper, risparmiando tempo e risorse
Scarica esempio
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF
XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG
eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY
LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve
u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals
SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8
Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g
45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa
eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS
mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x
GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ
NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ
EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0
0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g
KP8Byg3yDQ==
Utilizzo delle macro di sostituzione
Le macro di sostituzione consentono di implementare la sostituzione sequenziale di valori da un intervallo specificato
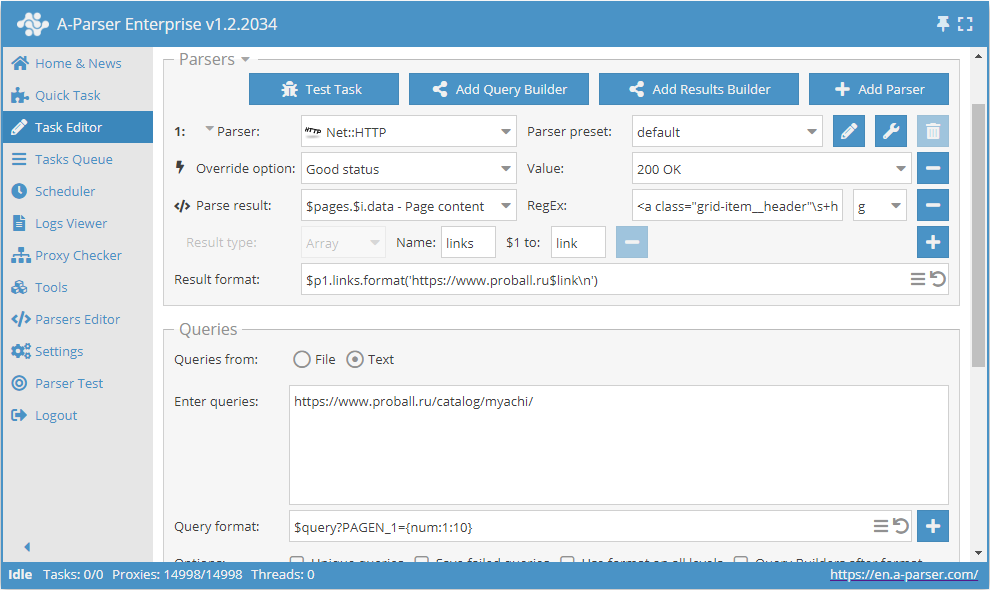
Questo preset funzionerà nel seguente modo. Specificando nel formato della richiesta il modello:
$query?PAGEN_1={num:1:10}
aggiungiamo la sostituzione dei valori da 1 before 10 (l'intervallo può essere qualsiasi) nella richiesta stessa. In questo modo otteniamo richieste che garantiscono la navigazione attraverso il numero desiderato di pagine, del tipo:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
https://www.proball.ru/catalog/myachi/?PAGEN_1=2
...
https://www.proball.ru/catalog/myachi/?PAGEN_1=10
L'utilizzo delle macro di sostituzione per la navigazione attraverso la paginazione è simile alla funzione Use pages e presenta le stesse limitazioni, ovvero è necessario specificare un intervallo concreto di valori. Il vantaggio di questo metodo è che tramite le macro di sostituzione è possibile inserire diversi valori, sia numerici che testuali, ad esempio parole o espressioni. In questo modo possiamo inserire in modo più flessibile le parti necessarie nelle richieste o formare le richieste stesse da parti che saranno collocate in file diversi, se il compito lo richiede
Scarica esempio
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a
AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix
JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi
Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6
OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ
IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC
4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv
nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk
vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke
AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa
F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q
MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU
1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg==
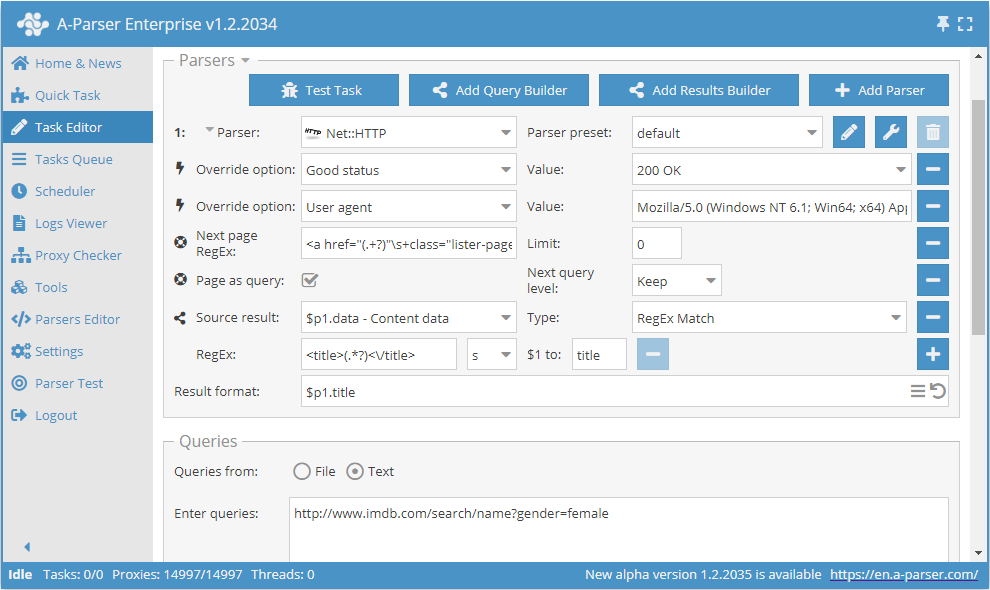
Utilizzo di Page as query
Per ridurre il consumo di memoria, la logica può essere definita utilizzando l'opzione Page as query. Quando attivata, le funzioni Check next page e Use pages inseriranno ogni pagina successiva nelle richieste come una richiesta indipendente a sé stante, evitando così di accumulare il loro contenuto in memoria. Page as query consente inoltre di definire se aumentare il livello della richiesta Increase (simile al funzionamento dello strumento tools.query.add), o meno Keep
Scarica esempio
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM
tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA
DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z
ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv
dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i
pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr
mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa
VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1
Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl
CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa
lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0
ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn
5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob
7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD
yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj
geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8=
Impostazioni possibili
| Nome parametro | Valore predefinito | Descrizione |
|---|---|---|
| Good status | All | Scelta di quale risposta dal server sarà considerata corretta. Se durante lo scraping si riceve un'altra risposta dal server, la richiesta verrà ripetuta con un altro proxy |
| Good code RegEx | Possibilità di specificare un'espressione regolare per verificare il codice di risposta | |
| Ban Proxy Code RegEx | Possibilità di bannare i proxy temporaneamente (Proxy ban time) in base al codice di risposta del server | |
| Method | GET | Metodo della richiesta |
| POST body | Contenuto da trasmettere al server quando si utilizza il metodo POST. Supporta le variabili $query – URL della richiesta, $query.orig – richiesta originale e $pagenum - numero della pagina quando si utilizza l'opzione Use Pages. | |
| Cookies | Possibilità di specificare i cookie per la richiesta. | |
| User agent | _Viene inserito automaticamente lo user-agent della versione attuale di Chrome_ | Intestazione User-Agent durante la richiesta delle pagine |
| Additional headers | Possibilità di specificare intestazioni di richiesta arbitrarie con il supporto delle funzionalità del motore di modelli e l'uso di variabili dal costruttore di query | |
| Read only headers | ☐ | Leggi solo le intestazioni. In alcuni casi consente di risparmiare traffico se non è necessario elaborare il contenuto |
| Detect charset on content | ☐ | Riconoscere la codifica in base al contenuto della pagina |
| Emulate browser headers | ☑ | Emulare le intestazioni del browser |
| Max redirects count | 7 | Numero massimo di reindirizzamenti che lo scraper seguirà |
| Follow common redirects | ☑ | Consente di effettuare reindirizzamenti http <-> https e www.domain <-> domain all'interno dello stesso dominio bypassando il limite Max redirects count |
| Max cookies count | 16 | Numero massimo di cookie da salvare |
| Engine | HTTP (Fast, JavaScript Disabled) | Consente di scegliere il motore HTTP (più veloce, senza JavaScript) o Chrome (più lento, JavaScript abilitato) |
| Chrome Headless | ☐ | Se l'opzione è attiva, il browser non verrà visualizzato |
| Chrome DevTools | ☐ | Consente di utilizzare gli strumenti di debug di Chromium |
| Chrome Log Proxy connections | ☐ | Se l'opzione è attiva, nel log verranno visualizzate le informazioni sulle connessioni chrome |
| Chrome Wait Until | networkidle2 | Determina quando la pagina è considerata caricata. Maggiori informazioni sui valori. |
| Use HTTP/2 transport | ☐ | Determina se utilizzare HTTP/2 invece di HTTP/1.1. Alcuni siti bannano immediatamente se si utilizza HTTP/1.1, mentre altri, al contrario, non funzionano con HTTP/2. |
| Try use HTTP/1.1 for Protocol error | ☑ | Indica allo scraper di ripetere la richiesta con HTTP/1.1 se era attivo HTTP/2 ed è stato ricevuto un errore di protocollo (ovvero se il sito non funziona con HTTP/2) |
| Don't verify TLS certs | ☐ | Disattivazione della validazione dei certificati TLS |
| Randomize TLS Fingerprint | ☐ | Questa opzione consente di bypassare il ban dei siti tramite l'impronta TLS |
| Bypass CloudFlare with Chrome | ☐ | Bypass automatico della verifica CloudFlare |
| Bypass CloudFlare with Chrome Max Pages | 20 | Numero massimo di pagine durante il bypass di CF tramite Chrome |
| Bypass CloudFlare with Chrome Headless | ☑ | Se l'opzione è attiva, il browser non verrà visualizzato durante il bypass di CF tramite Chrome |