结果去重
去重、重复数据删除、删除重复项、删除重复内容——所有这些都意味着我们不需要重复的结果。 在 A-Parser 中有两种去重方法,让我们详细分析每一种。
按行去重
该方法在生成结果后运行,在将结果写入文件之前,每一行都会检查唯一性,只有新的唯一行会被写入文件。
提示
另请参阅:查询处理顺序
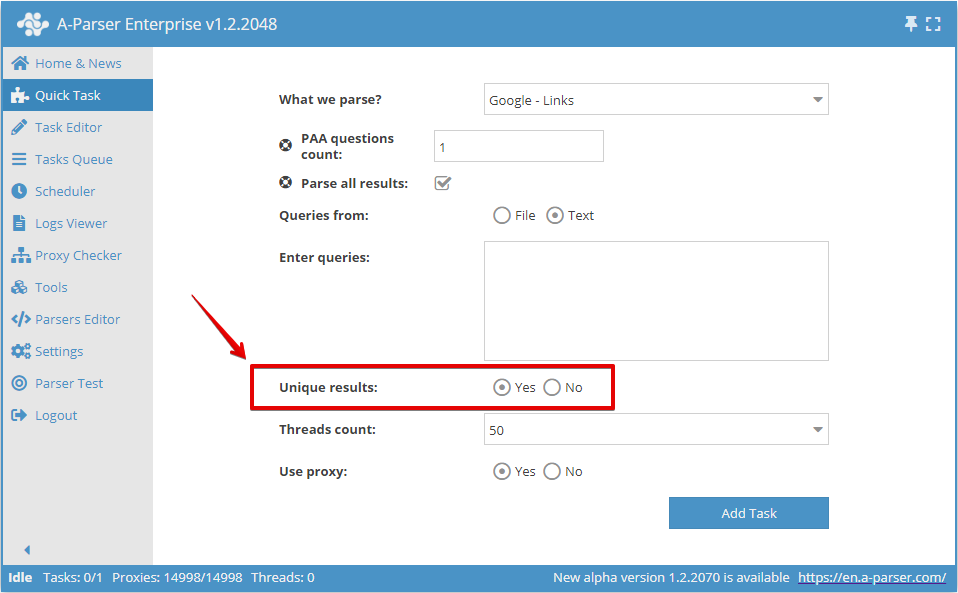
可以在快速任务中开启按行去重:
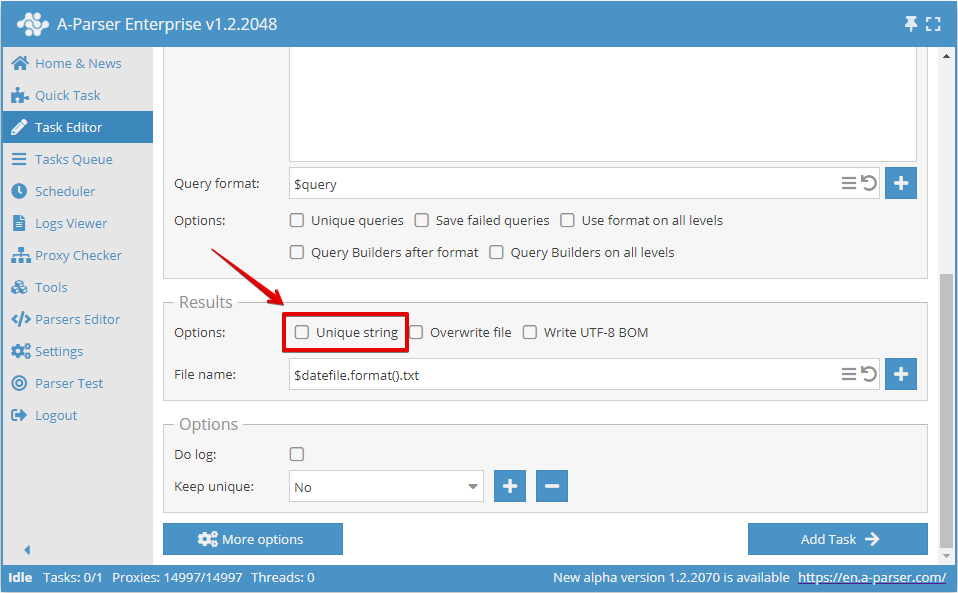
或者在任务编辑器中:
按任意结果去重
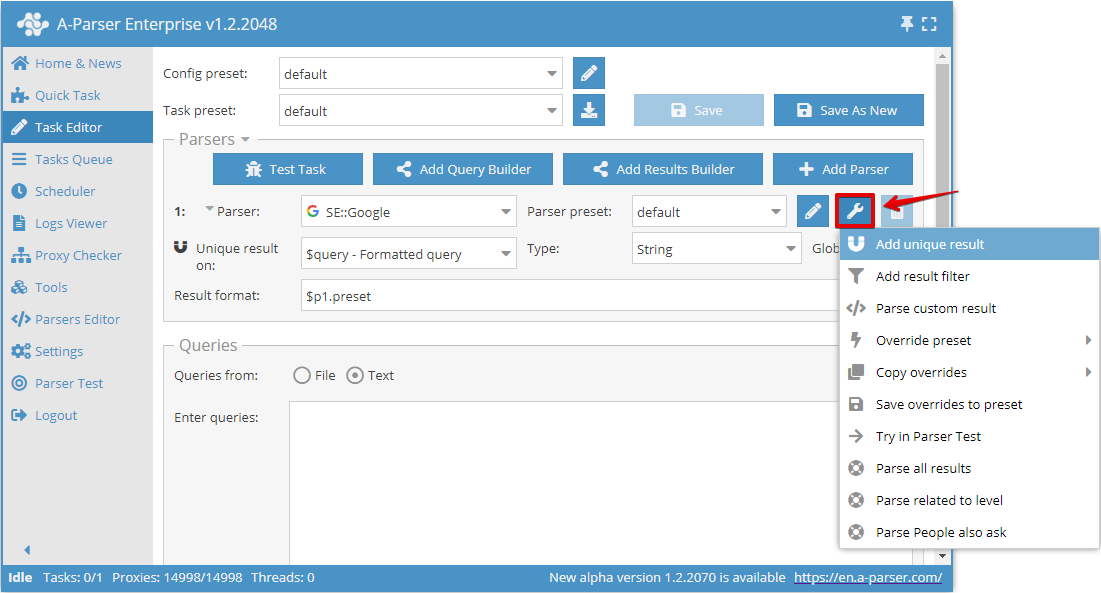
按任意结果去重允许直接对特定爬虫工具选定的结果进行去重。可以在任务编辑器中添加此类去重,点击爬虫工具右侧的工具图标并点击Add unique result (添加去重):
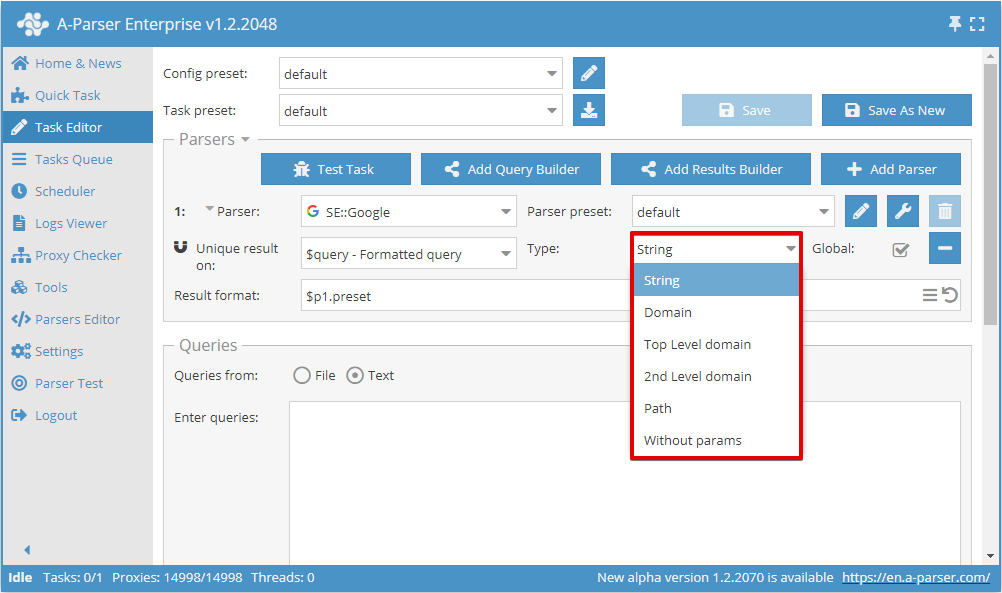
现在可以选择对哪个结果进行去重以及去重类型:
备注
当选择了 2 个或更多爬虫工具时使用Global (全局)开关,它决定是进行整体去重还是对每个爬虫工具分别去重。
去重类型
| 参数 | 描述 |
|---|---|
| String | 按行去重(比较整个结果行) |
| Domain | 按域名去重(比较整个域名,例如 www.domain.com 和 domain.com 是不同的域名) |
| Top Level domain | 按主域名去重,考虑地区、商业、教育等后缀(例如 domain.co.uk 和 domain2.co.uk 是不同的域名,而 sub1.domain.com 和 sub2.domain.com 是相同的) |
| 二级域名 | 按二级域名去重(比较二级域名,例如 www.domain.com、domain.com 和 user.subdomain.domain.com 都被视为同一个域名) |
| Path | 按路径去重(比较链接到文件前的部分,例如 http://domain.com/path1/file.php 和 http://domain.com/path1/file2.php - 链接到文件前的部分相同) |
| Without params | 按不带参数的链接去重(比较不带参数的链接,例如 http://domain.com/file.php?page=1 和 http://domain.com/file.php?page=2 - 视为相同的链接) |
查询去重
查询去重仅将唯一的查询发送到数据抓取环节,即在当前任务中之前未抓取过的查询。主要使用场景:
- 如果原始查询中存在重复项且不希望重复抓取(避免重复劳动)
- 使用 Parse to level (抓取至层级) 选项时,必须仅使用唯一查询,以防止查询数量激增和出现死循环(例如在使用
 HTML::LinkExtractor 爬虫工具时)
HTML::LinkExtractor 爬虫工具时)
备注
在所有其他情况下,不必要地使用查询去重只会降低爬虫工具的整体运行速度
在任务之间保存去重状态
可以保存去重数据库以便在未来的任务中使用,这使得在执行新任务时能够仅保存新的唯一结果(例如在使用  SE::Google 进行搜索结果数据抓取时的链接)
SE::Google 进行搜索结果数据抓取时的链接)
为了保存去重数据库,在添加第一个任务时需要创建一个新的数据库名称:
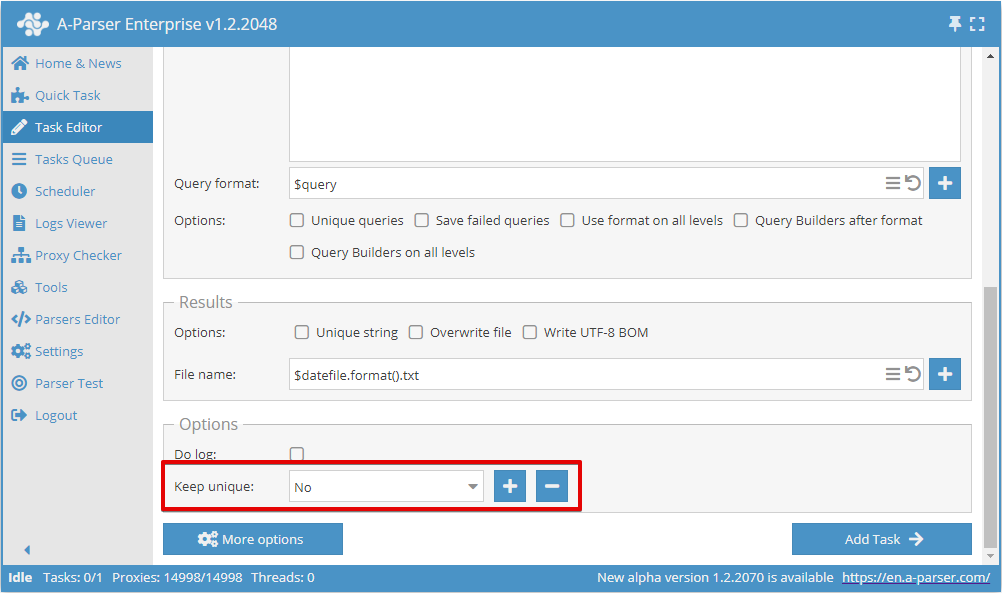
对于所有后续任务,需要选择之前创建的数据库名称,这样无论结果是写入与第一个任务相同的文件还是新文件,都只会保存新的唯一结果。