Khử trùng lặp kết quả
Khử trùng lặp, loại bỏ trùng lặp, xóa bản sao - tất cả những điều này có nghĩa là chúng ta không cần các kết quả lặp lại. Trong A-Parser có 2 phương pháp khử trùng lặp, hãy cùng tìm hiểu chi tiết từng phương pháp.
Khử trùng lặp kết quả theo dòng
Phương pháp này hoạt động sau khi hình thành kết quả, ngay trước khi ghi kết quả vào tệp, mỗi dòng sẽ được kiểm tra tính duy nhất và chỉ những dòng duy nhất mới được ghi vào tệp.
Xem thêm: Thứ tự xử lý truy vấn
Có thể bật tính duy nhất theo dòng trong Quick Task:
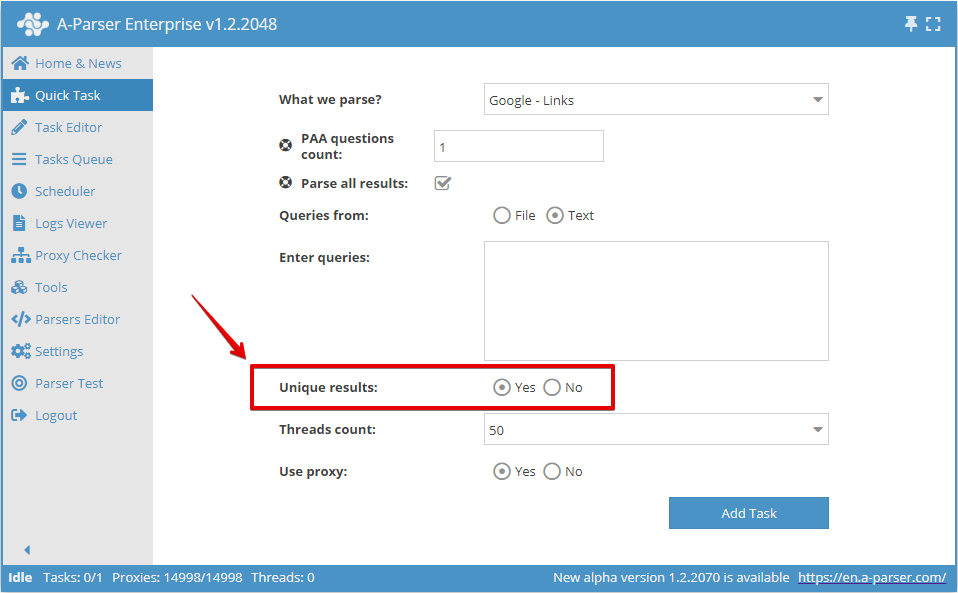
Hoặc trong Task Editor:
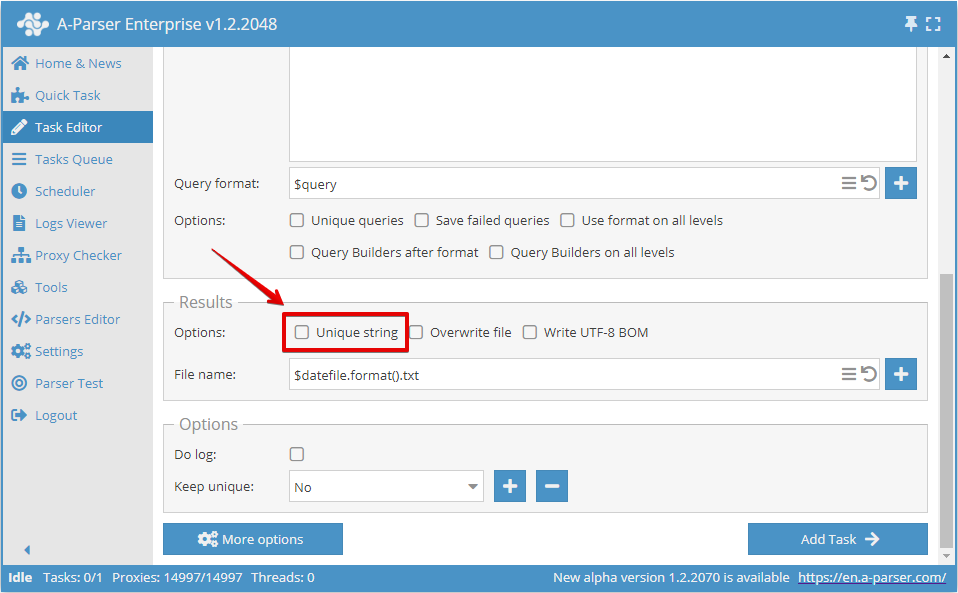
Khử trùng lặp theo bất kỳ kết quả nào
Khử trùng lặp theo bất kỳ kết quả nào cho phép thực hiện khử trùng lặp trực tiếp trên kết quả đã chọn từ một công cụ cào dữ liệu cụ thể. Có thể thêm loại khử trùng lặp này trong Task Editor bằng cách nhấp vào biểu tượng công cụ bên phải công cụ cào dữ liệu và nhấn Add unique result (Thêm khử trùng lặp):
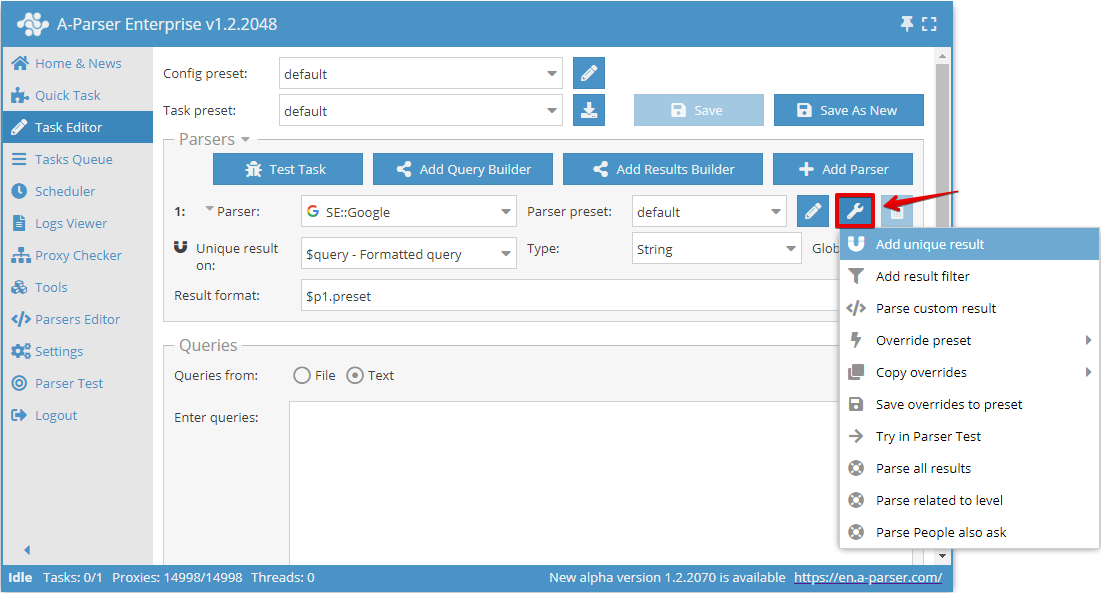
Bây giờ bạn có thể chọn kết quả nào để thực hiện khử trùng lặp và loại khử trùng lặp:
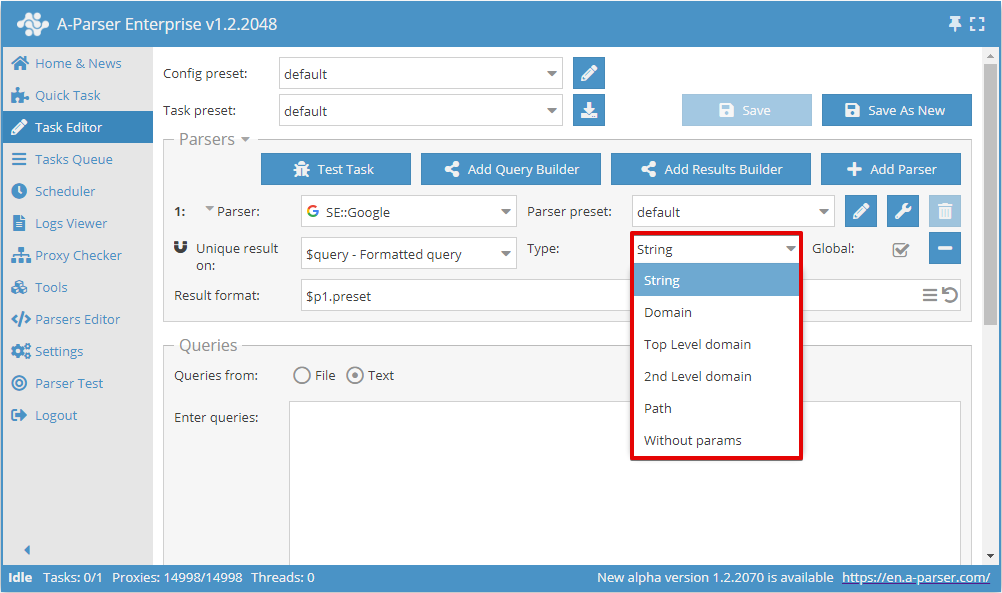
Nút gạt Global được sử dụng khi chọn 2 hoặc nhiều công cụ cào dữ liệu, nó xác định việc thực hiện khử trùng lặp chung hay riêng cho từng công cụ cào dữ liệu.
Các loại khử trùng lặp
| Tham số | Mô tả |
|---|---|
| String | Khử trùng lặp theo dòng (so sánh toàn bộ dòng kết quả) |
| Domain | Khử trùng lặp theo tên miền (so sánh toàn bộ tên miền, ví dụ www.domain.com và domain.com là các tên miền khác nhau) |
| Top Level domain | Khử trùng lặp theo tên miền chính có tính đến các tên miền khu vực, thương mại, giáo dục và các tên miền khác (ví dụ domain.co.uk và domain2.co.uk là các tên miền khác nhau, còn sub1.domain.com và sub2.domain.com là giống nhau) |
| Tên miền cấp 2 | Khử trùng lặp theo tên miền cấp 2 (so sánh các tên miền cấp hai, ví dụ www.domain.com, domain.com và user.subdomain.domain.com đều là một tên miền) |
| Path | Khử trùng lặp theo đường dẫn (so sánh các phần của liên kết cho đến tệp, ví dụ http://domain.com/path1/file.php và http://domain.com/path1/file2.php - các phần liên kết đến tệp là giống nhau) |
| Without params | Khử trùng lặp theo liên kết không có tham số (so sánh các liên kết không có tham số, ví dụ http://domain.com/file.php?page=1 và http://domain.com/file.php?page=2 - là các liên kết giống nhau) |
Khử trùng lặp truy vấn
Khử trùng lặp truy vấn chỉ gửi những truy vấn duy nhất chưa được cào dữ liệu trước đó trong tác vụ hiện tại để thực hiện cào dữ liệu. Các trường hợp sử dụng chính:
- Nếu trong các truy vấn gốc có các bản trùng lặp và không muốn cào dữ liệu chúng (tránh làm việc trùng lặp)
- Khi sử dụng tùy chọn Parse to level (Cào dữ liệu đến cấp độ), cần phải chỉ sử dụng các truy vấn duy nhất để ngăn chặn việc mở rộng và lặp vô hạn các truy vấn (ví dụ: khi sử dụng công cụ cào dữ liệu
 HTML::LinkExtractor)
HTML::LinkExtractor)
Trong tất cả các trường hợp khác, việc sử dụng khử trùng lặp truy vấn không cần thiết sẽ chỉ làm chậm tốc độ chung của công cụ cào dữ liệu
Lưu trạng thái khử trùng lặp giữa các tác vụ
Có khả năng lưu cơ sở dữ liệu khử trùng lặp để sử dụng trong các tác vụ tương lai, điều này cho phép trong các tác vụ mới chỉ lưu các kết quả duy nhất mới (ví dụ: các liên kết khi cào dữ liệu SERP trong  SE::Google)
SE::Google)
Để lưu cơ sở dữ liệu khử trùng lặp, khi thêm tác vụ đầu tiên, bạn cần tạo một tên cơ sở dữ liệu mới:
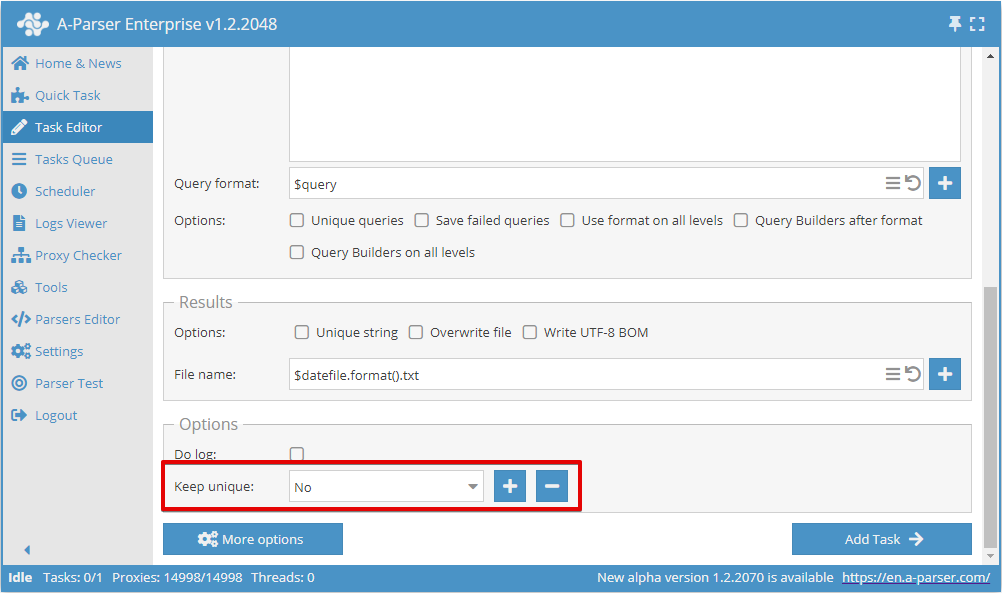
Đối với tất cả các tác vụ tiếp theo, bạn cần chọn tên cơ sở dữ liệu đã tạo trước đó, do đó chỉ những kết quả duy nhất mới được lưu lại, bất kể kết quả được ghi vào cùng một tệp như trong tác vụ đầu tiên hay vào một tệp mới.