Sonuç deduplikasyonu
Deduplikasyon, sonuç deduplikasyonu, kopyaların silinmesi, tekrarların kaldırılması - tüm bunlar tekrarlanan sonuçlara ihtiyacımız olmadığı anlamına gelir. A-Parser içerisinde 2 deduplikasyon yöntemi bulunmaktadır, her birini detaylıca inceleyelim.
Satır bazlı deduplikasyon
Bu yöntem sonuç oluşturma işleminden sonra çalışır, sonuç dosyaya yazılmadan hemen önce her satır benzersizlik açısından kontrol edilir ve dosyaya sadece yeni benzersiz satırlar kaydedilir.
Ayrıca bakınız: Sorgu işleme sırası
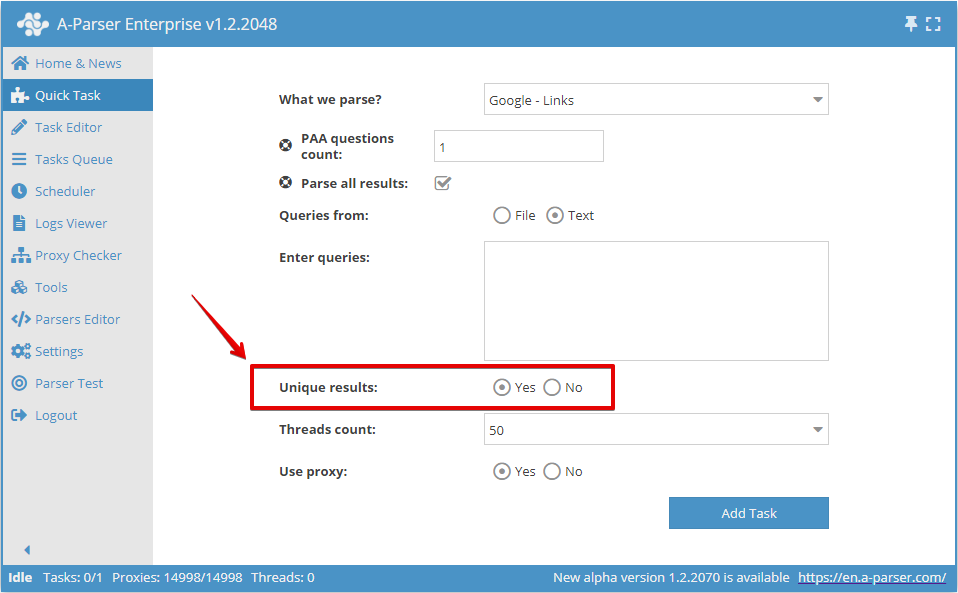
Satır bazlı benzersizliği Hızlı Görev kısmından etkinleştirebilirsiniz:
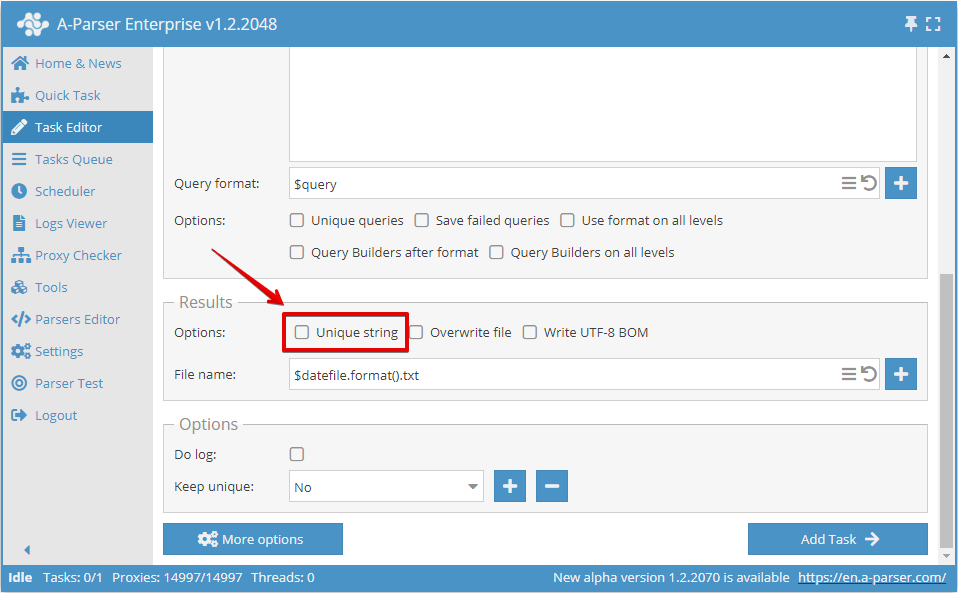
Veya Görev Düzenleyici içerisinde:
Herhangi bir sonuca göre deduplikasyon
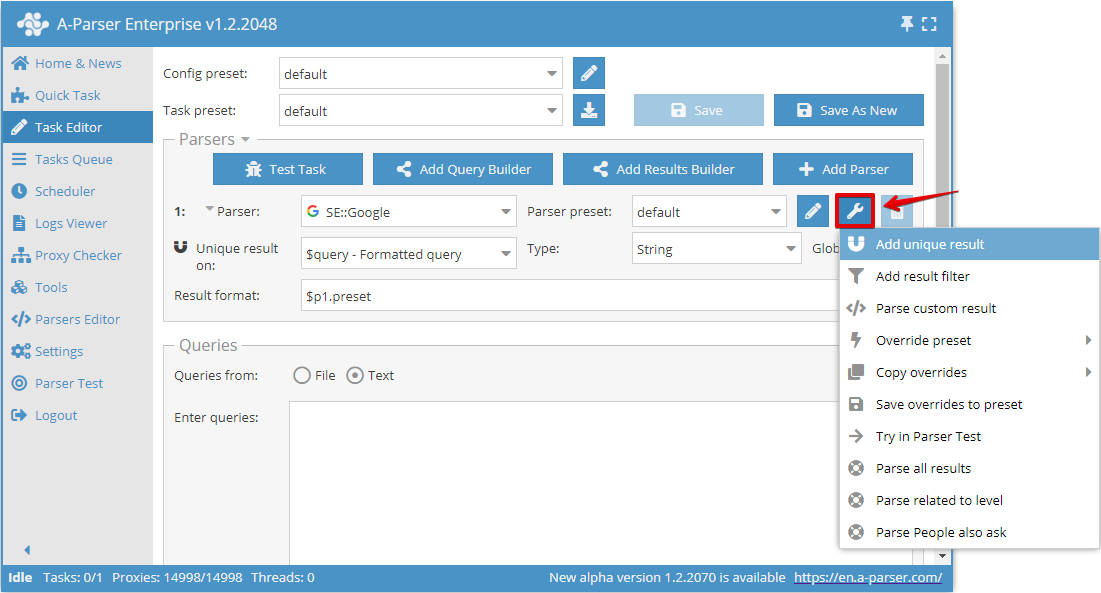
Herhangi bir sonuca göre deduplikasyon, belirli bir veri kazıyıcıdan gelen seçili sonuç üzerinde doğrudan deduplikasyon yapılmasına olanak tanır. Bu deduplikasyon türünü Görev Düzenleyici'de, veri kazıyıcının sağındaki araç simgesine tıklayıp Add unique result (Deduplikasyon ekle) diyerek ekleyebilirsiniz:
Şimdi hangi sonuç üzerinde deduplikasyon yapılacağını ve deduplikasyon türünü seçebilirsiniz:
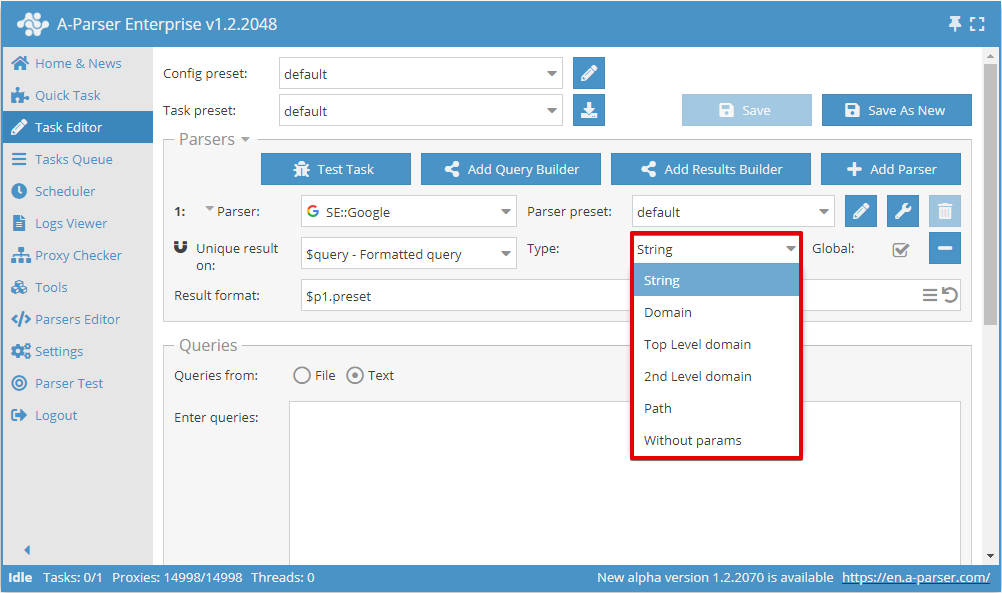
Global anahtarı, 2 veya daha fazla veri kazıyıcı seçildiğinde kullanılır; ortak bir deduplikasyon mu yoksa her veri kazıyıcı için ayrı mı yapılacağını belirler.
Deduplikasyon türleri
| Parametre | Açıklama |
|---|---|
| String | Satır bazlı deduplikasyon (sonuç satırının tamamı karşılaştırılır) |
| Domain | Alan adına göre deduplikasyon (alan adının tamamı karşılaştırılır, örneğin www.domain.com ve domain.com farklı alan adlarıdır) |
| Top Level domain | Bölgesel, ticari, eğitim ve diğer alan adları dikkate alınarak ana alan adına göre deduplikasyon (örneğin domain.co.uk ve domain2.co.uk farklı alan adlarıdır, ancak sub1.domain.com ve sub2.domain.com aynıdır) |
| 2. Seviye Alan Adı | 2. seviye alan adına göre deduplikasyon (ikinci seviye alan adları karşılaştırılır, örneğin www.domain.com, domain.com ve user.subdomain.domain.com'un hepsi tek bir alan adıdır) |
| Path | Yola göre deduplikasyon (bağlantının dosyaya kadar olan kısımları karşılaştırılır, örneğin http://domain.com/path1/file.php ve http://domain.com/path1/file2.php - bağlantının dosyaya kadar olan kısımları aynıdır) |
| Without params | Parametresiz bağlantıya göre deduplikasyon (bağlantılar parametreler olmadan karşılaştırılır, örneğin http://domain.com/file.php?page=1 ve http://domain.com/file.php?page=2 - aynı bağlantılardır) |
Sorgu deduplikasyonu
Sorgu deduplikasyonu, yalnızca mevcut görevde daha önce veri çekme işlemi yapılmamış benzersiz sorguları doğrudan veri çekme işlemine gönderir. Temel kullanım durumları:
- Kaynak sorgularda kopyalar varsa ve bunların kazınması istenmiyorsa (çift iş yükü)
- Parse to level seçeneğini kullanırken, sorguların büyümesini ve döngüye girmesini önlemek için yalnızca benzersiz sorguların kullanılması gerekir (örneğin
 HTML::LinkExtractor veri kazıyıcı kullanıldığında)
HTML::LinkExtractor veri kazıyıcı kullanıldığında)
Diğer tüm durumlarda, sorgu deduplikasyonunun gereksiz kullanımı veri kazıyıcının genel çalışma hızını yavaşlatacaktır
Görevler arasında deduplikasyon kaydı
Gelecekteki görevlerde kullanmak üzere deduplikasyon veritabanını kaydetme imkanı vardır; bu, yeni görevlerde yalnızca yeni benzersiz sonuçların kaydedilmesine olanak tanır (örneğin  SE::Google ile SERP veri çekme işlemi sırasında bağlantılar)
SE::Google ile SERP veri çekme işlemi sırasında bağlantılar)
Deduplikasyon veritabanını kaydetmek için ilk görevi eklerken yeni bir veritabanı adı oluşturmanız gerekir:
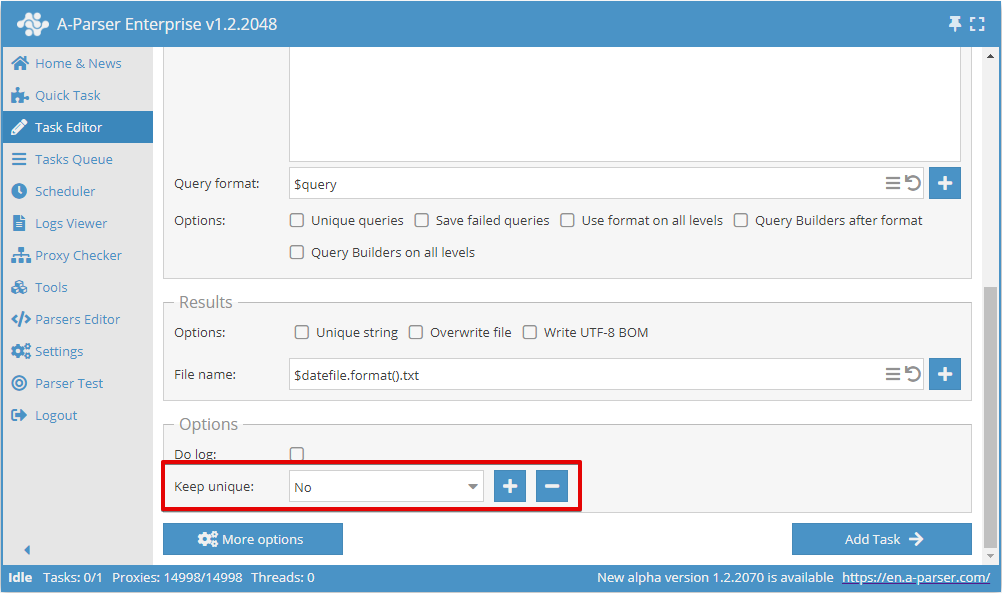
Sonraki tüm görevler için önceden oluşturulmuş veritabanı adını seçmeniz gerekir; böylece sonuçların ilk görevdekiyle aynı dosyaya mı yoksa yeni bir dosyaya mı yazıldığına bakılmaksızın yalnızca yeni benzersiz sonuçlar kaydedilecektir.