HTML::TextExtractor - Extracción de datos de contenido (texto) de sitios web
Información general del extractor
 HTML::TextExtractor extrae bloques de texto de la página especificada. Este extractor de contenido admite la extracción multipágina (navegación por páginas). Cuenta con herramientas integradas para omitir la protección de CloudFlare y también la posibilidad de elegir Chrome como motor para la extracción de contenido de páginas cuyos datos se cargan mediante scripts. Es capaz de alcanzar una velocidad de hasta 2000 consultas por minuto, lo que equivale a 120 000 enlaces por hora.
HTML::TextExtractor extrae bloques de texto de la página especificada. Este extractor de contenido admite la extracción multipágina (navegación por páginas). Cuenta con herramientas integradas para omitir la protección de CloudFlare y también la posibilidad de elegir Chrome como motor para la extracción de contenido de páginas cuyos datos se cargan mediante scripts. Es capaz de alcanzar una velocidad de hasta 2000 consultas por minuto, lo que equivale a 120 000 enlaces por hora.Casos de uso del extractor
Extracción de texto a través de Chrome con el ejemplo de lingualeo.com
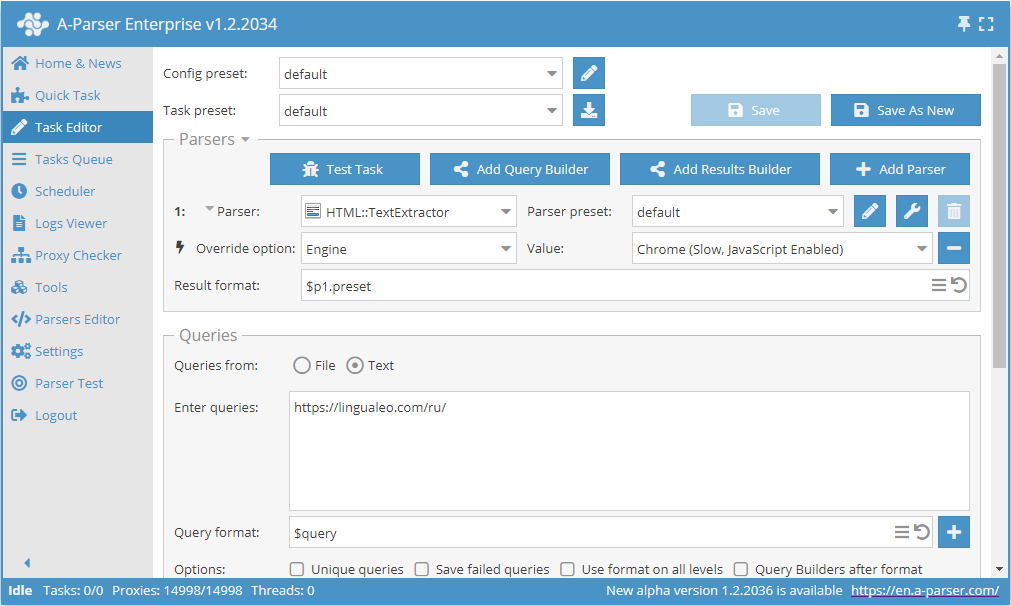
- Añadir la opción Engine, en la lista seleccionar el motor
Chrome (Slow, JavaScript Enabled). - Como consulta, indicar el enlace al sitio del cual se requiere extraer el texto.
Esta opción puede ser útil en los casos en que el sitio carga el texto principal mediante scripts durante la carga de la página y, al usar HTTP (Fast, JavaScript Disabled), el resultado no aparece o resulta incompleto.
Descargar ejemplo
Cómo importar un ejemplo en A-Parser
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Extracción de datos de texto con navegación por páginas en el ejemplo de noticias
Los resultados se guardan en el directorio aparser/results/example/textextractor en un archivo separado para cada consulta. Como nombre se indica el número de orden de la consulta.
- Añadir la opción Check next page, indicando como expresión regular
(forum\/news\/page-\d+)"[^>]+>Siguiente. - Añadir la opción Page as new query.
- Cambiar el File name (Nombre de archivo) a
example/textextractor/${query.num}.txt. - Indicar como consulta el enlace a la primera página con noticias de A-Parser:
https://a-parser.com/forum/news/.
Descargar ejemplo
Cómo importar un ejemplo en A-Parser
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Datos recopilados
- Extrae bloques de texto de la página especificada
- Matriz con todas las páginas recopiladas (se utiliza cuando la opción Use Pages está activa)
Posibilidades
- Extracción de datos de texto multipágina (navegación por páginas)
- Limpieza automática de texto de etiquetas HTML
- Posibilidad de establecer la longitud mínima del bloque de texto
- Eliminación opcional de anclas de enlace del texto
- Soporta compresión gzip/deflate/brotli
- Detección y conversión de codificaciones de sitios a UTF-8
- Evasión de la protección CloudFlare
- Selección de motor (HTTP o Chrome)
Casos de uso
- Extracción de contenido de texto de cualquier sitio
Consultas
Como consultas es necesario indicar los enlaces a las páginas de las cuales se deben extraer los bloques de texto, por ejemplo:
https://a-parser.com/
Ejemplos de salida de resultados
A-Parser admite un formateo flexible de resultados gracias al motor de plantillas integrado Template Toolkit, lo que le permite mostrar los resultados en forma libre, así como estructurada, por ejemplo CSV o JSON
Salida por defecto
Formato del resultado:
$texts.format('$text\n')
Ejemplo de resultado:
¡Hola, Súper Equipo de Altísimos Profesionales en su campo! ¡Gracias por la oportunidad de estudiar español, turco y portugués! ¡Les deseo una mayor expansión de sus posibilidades! ¡Inspiración y creatividad! ¡Y por favor añadan la posibilidad de estudiar alemán y francés!”
Llevo muchos años usando Lingualeo, empecé a estudiar por primera vez cuando no había aplicación en absoluto, solo existía el sitio web) Gracias a los desarrolladores, sigan así, con creatividad y con mucho amor por lo que hacen)
Inglés técnico para IT: diccionarios, libros de texto, revistas
Aprende idiomas online Aprende inglés online Aprende vietnamita online Aprende griego online Aprende indonesio online Aprende español online Aprende italiano online Aprende chino online Aprende coreano online Aprende alemán online Aprende neerlandés online Aprende polaco online Aprende portugués online Aprende serbio online Aprende turco online Aprende ucraniano online Aprende francés online Aprende hindi online Aprende checo online Aprende japonés online
Configuraciones posibles
| Nombre del parámetro | Valor por defecto | Descripción |
|---|---|---|
| Min block length | 50 | Longitud mínima del bloque de texto en caracteres. |
| Skip anchor text | ☐ | Si se deben omitir las anclas en el texto. |
| Ignore tags list | Opción para especificar las etiquetas que deben ignorarse. Ejemplo: div,span,p | |
| Good status | All | Selección de qué respuesta del servidor se considerará exitosa. Si durante la extracción se recibe otra respuesta del servidor, la consulta se repetirá con otro proxy. |
| Good code RegEx | Posibilidad de especificar una expresión regular para verificar el código de respuesta. | |
| Method | GET | Método de consulta. |
| POST body | Contenido a enviar al servidor al usar el método POST. Admite las variables $query – URL de la consulta, $query.orig – consulta original y $pagenum - número de página al usar la opción Use Pages. | |
| Cookies | Posibilidad de especificar cookies para la consulta. | |
| User agent | `_Se inserta automáticamente el user-agent de la versión actual de Chrome_ | Encabezado User-Agent al solicitar páginas. |
| Additional headers | Posibilidad de especificar encabezados de consulta personalizados con soporte para las funciones del motor de plantillas y el uso de variables del constructor de consultas. | |
| Read only headers | ☐ | Leer solo los encabezados. En algunos casos permite ahorrar tráfico si no es necesario procesar el contenido. |
| Detect charset on content | ☐ | Reconocer la codificación basándose en el contenido de la página. |
| Emulate browser headers | ☐ | Emular encabezados de navegador. |
| Max redirects count | 7 | Número máximo de redirecciones que seguirá el extractor. |
| Max cookies count | 16 | Número máximo de cookies a guardar. |
| Bypass CloudFlare | ☑ | Omisión automática de la verificación de CloudFlare. |
| Follow common redirects | ☑ | Permite realizar redirecciones http <-> https y www.domain <-> domain dentro de un mismo dominio omitiendo el límite de Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Permite elegir el motor HTTP (más rápido, sin JavaScript) o Chrome (más lento, JavaScript habilitado). |
| Chrome Headless | ☐ | Si la opción está activada, el navegador no se mostrará. |
| Chrome DevTools | ☑ | Permite utilizar las herramientas de depuración de Chromium. |
| Chrome Log Proxy connections | ☑ | Si la opción está activada, se mostrará información sobre las conexiones de Chrome en el registro. |
| Chrome Wait Until | networkidle2 | Define cuándo se considera que la página ha terminado de cargar. Más detalles sobre los valores. |
| Use HTTP/2 transport | ☐ | Define si se debe usar HTTP/2 en lugar de HTTP/1.1. Por ejemplo, Google y Majestic banean de inmediato si se usa HTTP/1.1. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Omisión de CF a través de Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Número máximo de páginas al omitir CF a través de Chrome. |