SE::Yandex::WordStat - Extractor de WordStat. Recopilación de palabras clave y estadísticas de impresiones
Descripción del extractor
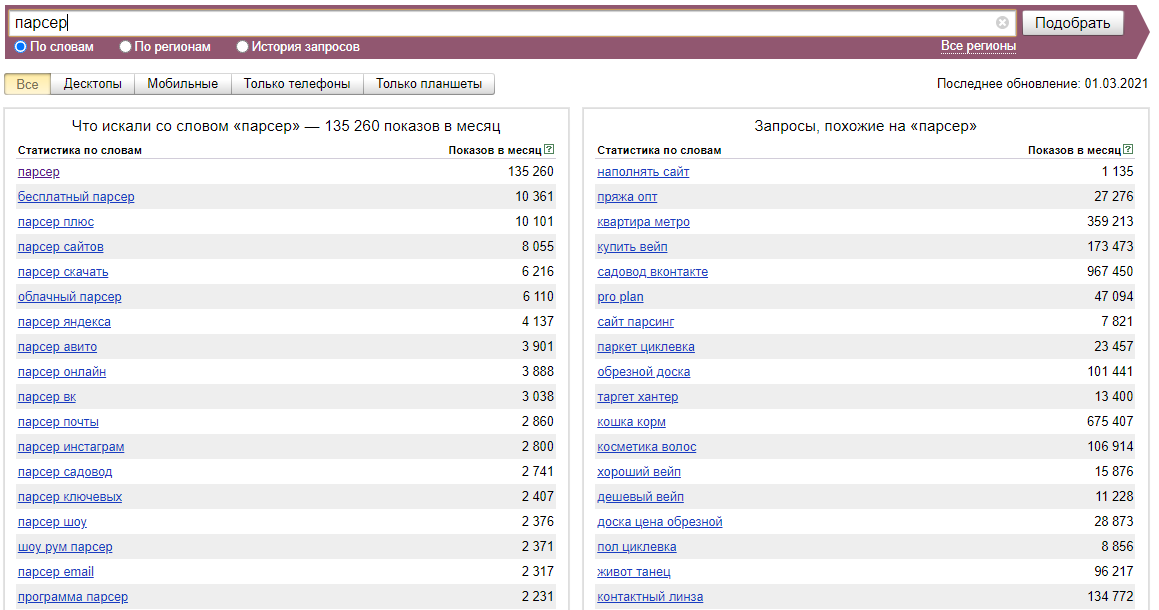
Wordstat es un servicio de Yandex diseñado para evaluar el interés de los usuarios en diversos temas y seleccionar palabras clave para la optimización SEO y la publicidad contextual. Además, con la ayuda de Wordstat Yandex, se puede evaluar la estacionalidad y la dependencia geográfica de las consultas de búsqueda.
El extractor de palabras clave Yandex WordStat admite la multiplicación automática de consultas, lo que garantiza que obtendrá el máximo número de resultados de la emisión. Además, A-Parser puede navegar automáticamente a través de consultas relacionadas hasta la profundidad especificada.
La funcionalidad de A-Parser permite guardar la configuración de la extracción de datos para su uso posterior (ajustes preestablecidos), establecer programas de extracción de datos y mucho más. Puede utilizar la multiplicación automática de consultas, la sustitución de subconsultas desde archivos, la iteración de combinaciones alfanuméricas y listas para obtener la mayor cantidad posible de resultados al realizar la extracción de datos de Yandex Wordstat.
Es posible guardar los resultados en la forma y estructura que necesite, gracias al potente motor de plantillas integrado Template Toolkit, que permite aplicar lógica adicional a los resultados y exportar datos en varios formatos, incluidos JSON, SQL y CSV.
Casos de uso del extractor
🔗 Extracción de datos de Wordstat en profundidad
Uso del extractor Yandex WordStat para la extracción de datos en profundidad.
🔗 Evaluación de frecuencia por WordStat
Evaluación de frecuencia por WordStat
Cuentas
Para el funcionamiento del extractor  SE::Yandex::WordStat se requieren cuentas de Yandex. Las cuentas se pueden registrar utilizando el extractor
SE::Yandex::WordStat se requieren cuentas de Yandex. Las cuentas se pueden registrar utilizando el extractor  SE::Yandex::Register o simplemente añadiendo cuentas existentes al archivo
SE::Yandex::Register o simplemente añadiendo cuentas existentes al archivo files/SE-Yandex/accounts.txt en el formato compatible.
O bien, puede activar el registro de cuentas "sobre la marcha".
Para trabajar utilizando la autorización por sesión, es necesario que la cadena de datos tenga este formato:
[email protected];MAQT78Z31Rinx4H;{"answer":"qmfhsxdcrk","proxy":"185.104.120.45:3128","session_id":"3:1748440908.5.0.1748440867459:ZXBxpg:47e4.1.2:1|2191075974.41.2.2:41.3:1748440908|3:10308131.797655.5pfkoRZWgLJGntKTlcUhYdysNfk"}
Datos recopilados
- Número de impresiones para la consulta especificada
- Fecha de actualización de las estadísticas
- Lista de todas las palabras clave relacionadas con la especificada y su número de impresiones mensuales
- Lista de todas las palabras clave adicionales que los usuarios buscaron y su número de impresiones mensuales
Características
- Extrae el número máximo de resultados entregados por Wordstat: 40 páginas con 50 elementos por emisión
- Admite la selección de la región de búsqueda (con subgrupos)
- Puede sustituir automáticamente las palabras clave encontradas de nuevo en las consultas (opción Parse to level)
- Posibilidad de seleccionar varias regiones a la vez para la evaluación
- Soporte para la omisión automática de Smart captcha y la posibilidad de omitir captchas gráficos mediante el servicio AntiCaptcha o cualquier otro que admita su API
- Selección del tipo de dispositivo
- Posibilidad de elegir el método de autorización
- Posibilidad de registrar cuentas "sobre la marcha"
- Admite el trabajo con formato extendido de cuentas y puede responder a la pregunta secreta (si la respuesta está en
info). También utiliza el proxy guardado para la autorización (si está eninfo).
Casos de uso
- Evaluación del volumen de tráfico por palabra clave (frecuencia)
- Búsqueda de nuevas palabras clave de temática similar
- Recopilación de grandes bases de datos de palabras clave de diferentes temáticas
- Cualquier otra variante que implique la extracción de datos de Yandex.WordStat de una forma u otra
Consultas
Como consultas, se deben indicar palabras clave, exactamente igual que si se introdujeran directamente en el formulario de búsqueda de Wordstat, por ejemplo:
ventanas moscú
"ventanas moscú"
!ventanas !moscú
Opciones de salida de resultados
A-Parser admite un formateo flexible de los resultados gracias al motor de plantillas integrado Template Toolkit, lo que le permite mostrar los resultados en forma arbitraria, así como estructurada, por ejemplo CSV o JSON
Salida por defecto
Formato del resultado:
$query - $totalcount, updated: $updatedate\nkeywords:\n$keys.format('$key: $count\n')\nadditional keywords:\n$search.format('$key: $count\n')
Como resultado, se muestra la consulta original, su número de impresiones, la fecha de actualización de las estadísticas, la lista de palabras clave relacionadas y sus impresiones mensuales, la lista de palabras clave adicionales y sus impresiones mensuales:
!ventanas !moscú - 10368, updated: 16/05/2013
keywords:
ventanas moscú: 32367
ventanas de plástico moscú: 8994
ventanas pvc moscú: 4813
comprar ventanas moscú: 2561
ventanas precios moscú: 1706
moscú trabajo ventanas: 1547
vacantes ventanas moscú: 1187
ventanas de madera moscú: 1087
servicio +de una ventana moscú: 1021
...
additional keywords:
producción de ventanas pvc: 8512
ventanas rehau: 15686
ventanas salamander: 1576
ventanas kbe: 3798
ventanas kbe: 6089
ventanas kbe: 3227
acristalamiento de balcones: 83216
cenadores: 471213
acristalamiento de logias: 26366
tabiques de oficina: 18740
montaje de ventanas: 26223
Salida en tabla CSV
Formato del resultado:
[% FOREACH i IN keys;
tools.CSVline(query, i. key, i.count);
END %]
Ejemplo de resultado:
extractor de sitios, extractor de sitios, 8055
extractor de sitios, extractor de sitios gratuito, 1122
extractor de sitios, extractor sitio oficial, 666
extractor de sitios, sitios extractor en la nube, 507
extractor de sitios, extractor email +de sitio, 477
extractor de sitios, descargar extractor de sitio, 434
extractor de sitios, extractor de direcciones de sitios, 390
extractor de sitios, extractor de sitios online, 366
extractor de sitios, turbo extractor de sitios, 342
extractor de sitios, turbo extractor sitio oficial, 309
extractor de sitios, extractor en la nube sitio oficial, 308
extractor de sitios, extractor de sitios excel, 276
extractor de sitios, sliza extractor sitio, 259
Guardado en formato SQL
Formato del resultado:
[% FOREACH i IN keys;
"INSERT INTO keys VALUES('" _ query _ "', '"; i.key _ "', '"; i.count _ "')\n";
END %]
Ejemplo de resultado:
INSERT INTO serp VALUES('test', 'test', '10837937')
INSERT INTO serp VALUES('test', 'test drive', '1164338')
INSERT INTO serp VALUES('test', 'masa +para masa', '879980')
INSERT INTO serp VALUES('test', 'tests online', '792560')
INSERT INTO serp VALUES('test', 'test drive video', '550164')
INSERT INTO serp VALUES('test', 'receta de masa', '484489')
INSERT INTO serp VALUES('test', 'tests +con respuestas', '449401')
INSERT INTO serp VALUES('test', 'test 2014', '427602')
INSERT INTO serp VALUES('test', 'tests gratis', '315144')
INSERT INTO serp VALUES('test', 'tests gratuitos', '315096')
INSERT INTO serp VALUES('test', 'tests +para niñas', '309355')
INSERT INTO serp VALUES('test', 'tests +por temas', '293917')
INSERT INTO serp VALUES('test', 'juegos de tests', '288989')
Volcado de resultados en JSON
Formato general del resultado:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.updatedate = p1.updatedate;
obj.totalcount = p1.totalcount;
obj.keys = [];
FOREACH item IN p1.keys;
obj.keys.push({
key = item.key
count = item.count
});
END;
obj.json %]
Texto inicial:
[
Texto final:
]
Ejemplo de resultado:
[{
"updatedate": "12.03.2014",
"totalcount": "10837937",
"keys": [
{
"count": "10837937",
"key": "test"
},
{
"count": "1164338",
"key": "test drive"
},
{
"count": "879980",
"key": "masa +para masa"
},
{
"count": "792560",
"key": "tests online"
},
]
}]
Ver también: Filtros de resultados
Configuraciones posibles
| Parámetro | Valor por defecto | Descripción |
|---|---|---|
| Pages count | 10 | Número de páginas para extraer |
| Region | All | Región de búsqueda |
| Remove + from keywords | ☐ | Eliminar el símbolo más (+) de las consultas encontradas |
| AntiGate preset | default | Es necesario configurar previamente el extractor  Util::AntiGate - indicar su clave de acceso y otros parámetros, y luego seleccionar el ajuste preestablecido creado aquí Util::AntiGate - indicar su clave de acceso y otros parámetros, y luego seleccionar el ajuste preestablecido creado aquí |
| AntiGate preset for Login | default | Ajuste preestablecido de AntiGate para el inicio de sesión. Es necesario configurar previamente el extractor Util::AntiGate con los parámetros, y luego seleccionar el ajuste preestablecido creado aquí |
| Type | All | Selección del tipo de dispositivo |
| Accounts | Only from "accounts.txt" | Selección del método de trabajo con cuentas: Always auto register - registrar siempre cuentas automáticamente "sobre la marcha", requiere seleccionar un ajuste preestablecido configurado en el parámetro SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - primero se utilizan las cuentas existentes de accounts.txt, y si se agotan, se utiliza el registro automático "sobre la marcha", para lo cual se debe seleccionar un ajuste preestablecido configurado en el parámetro SE::Yandex::Register preset. Only from "accounts.txt" - usar solo cuentas existentes de accounts.txt, y si se agotan, esperar el tiempo especificado (parámetro Wait new accounts in "accounts.txt") a que aparezcan nuevas. Only by session_id from "accounts.txt" - autorización por cookies. |
| Wait new accounts in "accounts.txt" | 0 | Tiempo de espera para la aparición de nuevas cuentas en accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Eliminación automática de cuentas "malas": Always - eliminar siempre. Always, except wrong login/password - eliminar siempre, excepto cuando Yandex informe que el usuario/contraseña son incorrectos. El hecho es que Yandex puede dar este mensaje al bloquear la IP para una cuenta totalmente funcional, por lo que opcionalmente se pueden dejar tales cuentas para su reutilización. Never - no eliminar nunca. Independientemente de la opción elegida, las cuentas no se eliminan en caso de errores de proxy/navegador |
| SE::Yandex::Register preset | default | Selección del ajuste preestablecido de configuración para SE::Yandex::Register |
| Authorization method | HTTP | Método de autorización: HTTP - rápido, poco exigente con los recursos. Chrome - lento, exigente con los recursos, teóricamente puede prolongar la vida de las cuentas |
| Chrome headless | ☑ | Si la opción está activada, el navegador no se mostrará |
| Use sessions | ☑ | Uso de sesiones |
| Do not reset session if authorization passed | ☑ | No restablecer la sesión en caso de errores si el extractor ya se ha autorizado |
| Use Wordstat 2 | ☐ | Uso de Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Permite descargar directamente los 2000 resultados por consulta sin pasar por la paginación |
