Cloudflare::Radar - Extractor de Cloudflare Radar
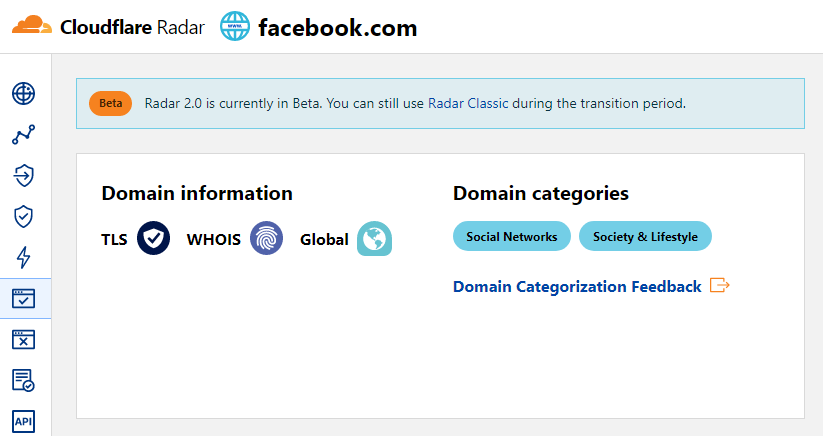
Descripción general del extractor
El extractor Cloudflare Radar permite determinar rápidamente la categoría de un sitio mediante su nombre de dominio.
Es posible guardar los resultados en el formato y la estructura que necesite, gracias al potente motor de plantillas integrado Template Toolkit, que permite aplicar lógica adicional a los resultados y exportar datos en varios formatos, incluidos JSON, SQL y CSV
Datos recopilados
Los datos se recopilan del servicio radar.cloudflare.com
- Categorías del sitio
Casos de uso
- Determinar a qué categoría de sitios pertenece un dominio
Consultas
Como consultas, es necesario especificar una lista de dominios, por ejemplo:
a-parser.com
yandex.ru
google.com
vk.com
facebook.com
youtube.com
Ejemplos de salida de resultados
A-Parser admite un formateo flexible de los resultados gracias al motor de plantillas integrado Template Toolkit, lo que le permite presentar los resultados en forma libre, así como estructurada, por ejemplo, CSV o JSON
Salida por defecto
Formato del resultado:
$query: $categories.format('$name, ')\n
Ejemplo de resultado, en el que se muestran las categorías y su descripción:
a-parser.com: Business, Business & Economy,
yandex.ru: News & Media, Entertainment,
vk.com: Social Networks, Society & Lifestyle,
youtube.com: Video Streaming, Entertainment,
facebook.com: Social Networks, Society & Lifestyle,
google.com: Search Engines, Technology,
Salida en tabla CSV
Formato del resultado:
[% FOREACH categories;
tools.CSVline(name, desc);
END %]
Ejemplo de resultado:
Business,"Sites related to business."
"Business & Economy","Sites that are related to business, economy, finance, education, science and technology."
"Social Networks","Sites that facilitate interaction and networking between people."
"Society & Lifestyle","Sites related to lifestyle that are not included in other categories like fashion, food & drink etc."
"Social Networks","Sites that facilitate interaction and networking between people."
"Society & Lifestyle","Sites related to lifestyle that are not included in other categories like fashion, food & drink etc."
"Search Engines","Sites that allow users to search for content using keywords."
Technology,"Sites related to technology that are not included in the science category."
"News & Media","Sites related to news and media."
Entertainment,"Sites related to entertainment that are not includeded in other categories like Comic books, Audio streaming, Video streaming etc."
Volcado de resultados en JSON
Formato general del resultado:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.query = query;
obj.categories = [];
FOREACH item IN p1.categories;
obj.categories.push({
name = item.name
desc = item.desc
});
END;
obj.json %]
Texto inicial:
[
Texto final:
]
Ejemplo de resultado:
[{"query":"yandex.ru","categories":[{"desc":"Sites related to news and media.","name":"News & Media"},{"desc":"Sites related to entertainment that are not includeded in other categories like Comic books, Audio streaming, Video streaming etc.","name":"Entertainment"}]},{"query":"google.com","categories":[{"desc":"Sites that allow users to search for content using keywords.","name":"Search Engines"},{"desc":"Sites related to technology that are not included in the science category.","name":"Technology"}]},{"query":"a-parser.com","categories":[{"desc":"Sites related to business.","name":"Business"},{"desc":"Sites that are related to business, economy, finance, education, science and technology.","name":"Business & Economy"}]}]
Para que las opciones "Prepend text" y "Append text" estén disponibles en el Editor de tareas, debe activar "More options".
Configuraciones posibles
| Nombre del parámetro | Valor por defecto | Descripción |
|---|---|---|
| Bypass CloudFlare with Chrome Max Pages | 10 | Cantidad máx. de páginas al evadir CF mediante Chrome |
| Bypass CloudFlare with Chrome Headless | ☑ | Si la opción está activada, el navegador no se mostrará durante la evasión de CF mediante Chrome |
| Use session | ☑ | Guarda sesiones válidas, lo que permite extraer datos aún más rápido, obteniendo un menor número de errores. |