Net::HTTP - Extractor base universal con soporte para extracción de datos multipágina y bypass de CloudFlare
Información general del extractor
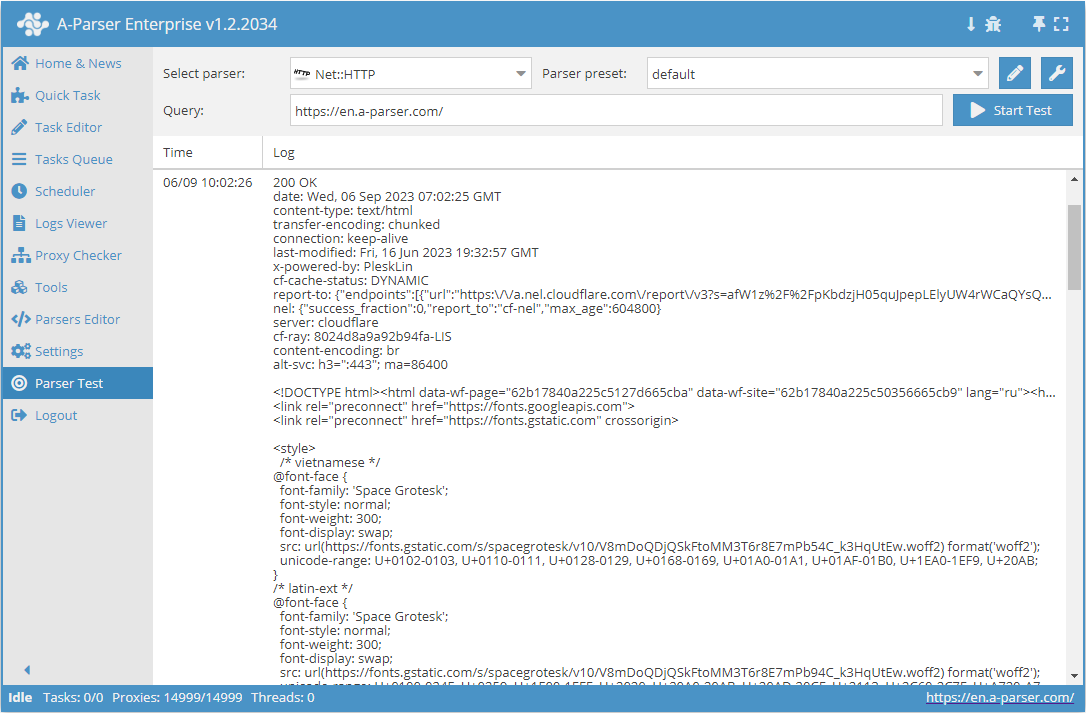
 Net::HTTP – es un extractor universal que permite resolver la mayoría de las tareas no estándar. Puede ser utilizado como base para la extracción de datos de contenido arbitrario de cualquier sitio. Permite descargar el código de la página mediante un enlace, admite la extracción de datos multipágina (navegación por páginas), el trabajo automático con proxies y permite verificar el éxito de la respuesta por código o por contenido de la página.
Net::HTTP – es un extractor universal que permite resolver la mayoría de las tareas no estándar. Puede ser utilizado como base para la extracción de datos de contenido arbitrario de cualquier sitio. Permite descargar el código de la página mediante un enlace, admite la extracción de datos multipágina (navegación por páginas), el trabajo automático con proxies y permite verificar el éxito de la respuesta por código o por contenido de la página.Casos de uso del extractor
🔗 Subasta de dominios REG.RU
Extracción de datos de la subasta de dominios que quedan libres con posibilidad de filtrado
🔗 Datos del certificado SSL
Extracción de datos del certificado SSL de dominios desde el sitio leaderssl.ru
🔗 Extracción de datos del recurso Booking.com
Obtención de resultados de búsqueda de apartamentos y hoteles en el sitio
🔗 Recopilación de características del producto
Ejemplo de extracción de datos de una cantidad desconocida de características del producto
🔗 Extracción de base de datos de películas de IMDB
Obtiene datos sobre cada película y los escribe en el resultado
🔗 Verificación de presencia de HTTPS
El ajuste preestablecido verifica la presencia de HTTPS en el sitio
Datos recopilados
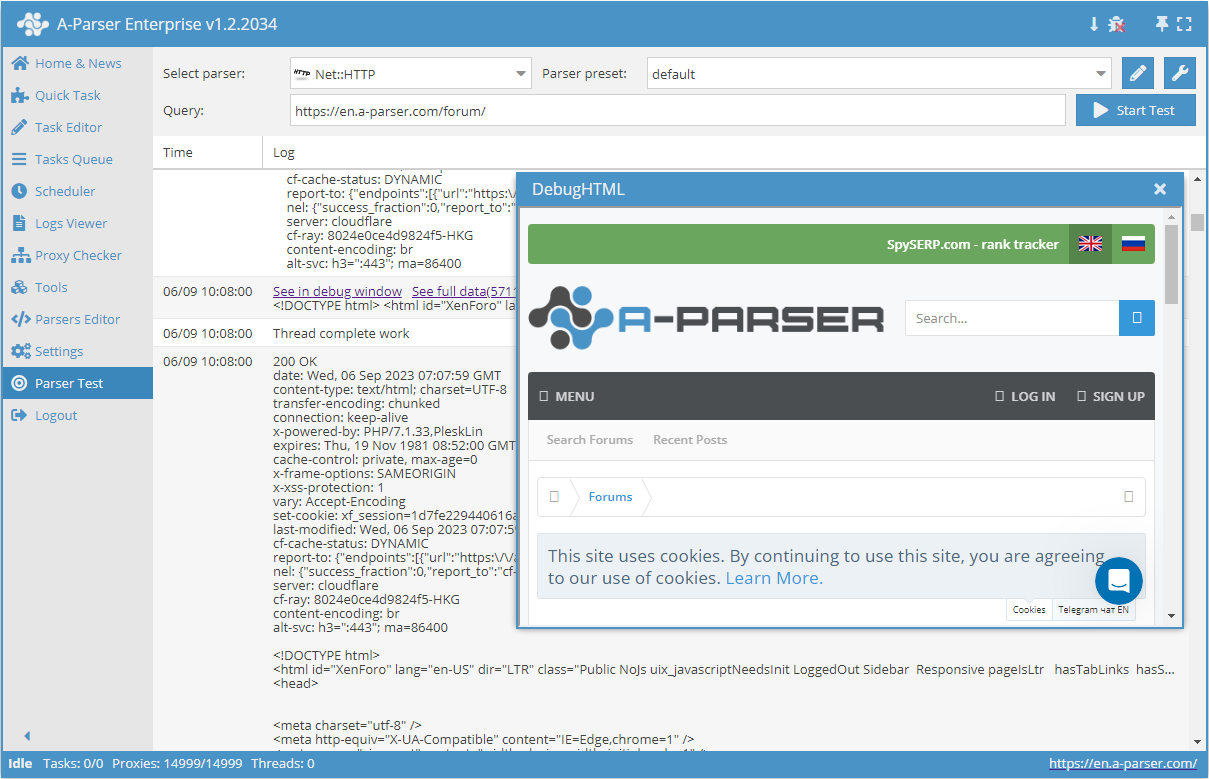
- Contenido
- Código de respuesta del servidor
- Descripción de la respuesta del servidor
- Encabezados de respuesta del servidor
- Proxies utilizados en la solicitud
- Matriz con todas las páginas recopiladas (se utiliza cuando la opción Use Pages está activa)
Capacidades
- Extracción de datos multipágina (navegación por páginas)
- Trabajo automático con proxies
- Verificación de respuesta exitosa por código o por contenido de la página
- Soporta compresión gzip/deflate/brotli
- Detección y conversión de codificaciones de sitios a UTF-8
- Omisión de la protección de CloudFlare
- Elección del motor (HTTP o Chrome)
- Opción Check content: ejecuta la expresión regular especificada en la página obtenida. Si la expresión no coincide, la página se cargará de nuevo con otro proxy.
- Opción Use Pages: permite recorrer un número específico de páginas con un paso determinado. La variable
$pagenumcontiene el número de página actual durante el recorrido. - Opción Check next page: requiere especificar una expresión regular que extraerá el enlace a la siguiente página (generalmente el botón "Siguiente"), si existe. La transición entre páginas se realiza dentro del límite especificado (0 - sin restricciones).
- Opción Page as new query: la transición a la siguiente página ocurre en una nueva solicitud. Permite eliminar el límite en el número de páginas para la transición.
Casos de uso
- Descarga de contenido
- Descarga de imágenes
- Verificación del código de respuesta del servidor
- Verificación de presencia de HTTPS
- Verificación de presencia de redirecciones
- Listado de URLs de redirección
- Obtención del tamaño de la página
- Recopilación de metaetiquetas
- Extracción de datos del código fuente de la página y/o encabezados
Consultas
Como consultas, es necesario indicar enlaces a las páginas, por ejemplo:
http://lenta.ru/
http://a-parser.com/pages/reviews/
Opciones de salida de resultados
A-Parser admite un formateo flexible de resultados gracias al motor de plantillas integrado Template Toolkit, lo que le permite mostrar los resultados en forma arbitraria, así como estructurada, por ejemplo, CSV o JSON.
Salida de contenido
Formato del resultado:
$data
Ejemplo de resultado:
<!DOCTYPE html><html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<!-- Google Tag Manager -->
<!-- End Google Tag Manager -->
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<base href="https://a-parser.com/" />
<title>A-Parser - extractor para profesionales SEO</title>
<noscript><style>.JsOnly, .jsOnly { display: none !important; }</style></noscript>
<link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" />
Código de respuesta del servidor
Formato del resultado:
$code
Ejemplo de resultado:
200
El formato del resultado [% response.Redirects.0.Status || code %] permite mostrar el estado 301 si hay redirecciones presentes en la solicitud.
Obtención de datos sobre la solicitud
La variable $response ayuda a obtener información sobre la solicitud y la respuesta del servidor.
Formato del resultado:
$response.json\n
Ejemplo de resultado:
{
"Time": 3.414,
"connection": "keep-alive",
"Decode": "Decode from utf-8(meta charset)",
"cache-control": "max-age=3600,public",
"last-modified": "Tue, 18 May 2021 12:42:56 GMT",
"transfer-encoding": "chunked",
"date": "Thu, 27 May 2021 14:18:42 GMT",
"Status": 200,
"content-encoding": "gzip",
"Body-Length-Decoded": 1507378,
"Reason": "OK",
"Proxy": "http://51.255.55.144:25302",
"content-type": "text/html",
"Redirects": [],
"server": "nginx",
"Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n",
"URI": "https://a-parser.com/",
"HTTPVersion": "1.1",
"Body-Length": 299312,
"Decode-Mode": "auto-html",
"etag": "W/\"60a3b650-170032\"",
"Decode-Time": 0.003,
"IP": "remote",
"expires": "Thu, 27 May 2021 15:18:42 GMT"
}
Obtención de redirecciones
Consulta:
https://google.it
Formato del resultado:
$response.Redirects.0.URI -> $response.URI
Ejemplo de resultado:
https://google.it/ -> https://www.google.it/
JSON con redirecciones
Formato del resultado:
$response.Redirects.json
Ejemplo de resultado:
[{"x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n"}]
Salida del estado de respuesta del servidor
Formato del resultado:
$reason
Ejemplo de resultado:
OK
Tiempo de respuesta del servidor
Formato del resultado:
$response.Time
Ejemplo de resultado:
1.457
Obtención del tamaño de la página
Como ejemplo, el tamaño se presenta en tres variantes diferentes.
Formato del resultado:
[% "data-length: " _ data.length _ "\n";
"Body-Length: " _ response.${'Body-Length'} _ "\n";
"Body-Length-Decoded: " _ response.${'Body-Length-Decoded'} _ "\n" %]
Ejemplo de resultado:
data-length: 70257
Body-Length: 23167
Body-Length-Decoded: 75868
Procesamiento de resultados
A-Parser permite procesar los resultados directamente durante la extracción de datos; en esta sección presentamos los casos más populares para el extractor Net::HTTP.
Extracción de etiquetas H1-H6
Agregar la expresión regular (opción Parse custom results (Parse custom result) (Usar expresión regular)) <(h\d+)[^>]+>(.+?)<\/h\d+>, en el campo "Parse result" seleccionar $pages.$i.data - Page content, en el campo junto a la expresión regular elegir los modificadores sg. Como tipo de resultado se seleccionará automáticamente un arreglo. En el campo "Name" indicar headers, luego en "$1 to" indicar tag, pulsar en

content. En el formato general del resultado escribir la salida $p1.headers.format('$tag - $content\n').Descargar ejemplo
Cómo importar un ejemplo a A-Parser
eJxtVNuO2jAQ/RVkIS2IW3loH6IVFYuK2ooSlmWfIJUsMgR3HTu1HboI8e+dcUIC
tE+Jj+ccn7nYJ+a4fbMLAxacZcH6xDL/zwI2BxcEX1erRWOrpYStEypp7Ie9/SfW
ZRk3Fgwx1nUg4jHseC4d656YO2aAMtvcOp0uwXqYmeInWKNEApYo3HEW0U4C70h4
bO03m7jTXv8cRZ1Rq9/53H7cbAYeHLEyblWI26SSLBFuDD8i6L9znhK2Bx6T2Uso
2cbEibvVyoFyLDpHUbU91SblVIJmNuyX5P7Og62HJhIbvUazZG426qFdK7/wA6w0
UndCQg1PcVWaaWK+QLsXxXbfvVNleBwLJ7TisjifXNaeXpX4nRNfaYzFXyPATo1O
EXLgBQg8XryvWdOvqbK55z4XHBbsuLTQZRatTjkaie93hAPDnTZhRn4QPzGtxlLO
4ACyDvP6T7mQVJ/xDknfSuL/Q8J/NM5VetdHHcD8MeihUvGrp/BHzYr1TCeXYkiR
CodrO9G5orZ9QPANIKtqNqewVBuojimVy9Nx/jNQMUbWLRtnNXSTxk1bbkGciZ1I
QkzAiBgukbla4SUL1USnmQTKS+VSYlssLOvxGNuyDbSoDd6TJ/4ItFXdNOa0lvb7
S2E1MwLH7yMZTLGS16eWklsu5etydr1DRLylWai+GHPXPj8YbO9cZoPBgPeKm9/f
6nRA9weHOdE4ZpjqOarehepBOV29DsHpjK37ZRdFDOVJEYhhwSz2hQXD81+VjpX2
Recopilación de metaetiquetas
Añadir una expresión regular (opción Parse custom results (Parse custom result) (Usar expresión regular)) (<meta[^>]+>), en el campo "Parse result" seleccionar $pages.$i.data - Page content, en el campo opuesto a la expresión regular seleccionar el modificador g. Como tipo de resultado se seleccionará automáticamente una matriz. En el campo "Name" indicar meta, en "$1 to" indicar item. En el Formato del resultado usar $p1.meta.format('$item\n').
Descargar ejemplo
Cómo importar un ejemplo a A-Parser
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB
bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj
3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm
Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z
Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL
SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9
iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK
zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY
rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF
Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY
i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1
gDE=
Opciones de navegación por paginación
Uso de Use pages
Use pages. Esta función permite recorrer la paginación indicando de antemano un número conocido de páginas.
Como ejemplo, tomemos una de las categorías del sitio de catálogo de productos https://www.proball.ru/catalog/myachi/. Arriba y abajo vemos un panel de paginación. Al hacer clic en los iconos con los números de página, se puede ver en la barra del navegador cómo se transmite el parámetro con el número de página al final de la solicitud:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
Use pages es una especie de contador que sustituye secuencialmente en la variable $pagenum los números, incrementándolos por el valor que indiquemos.
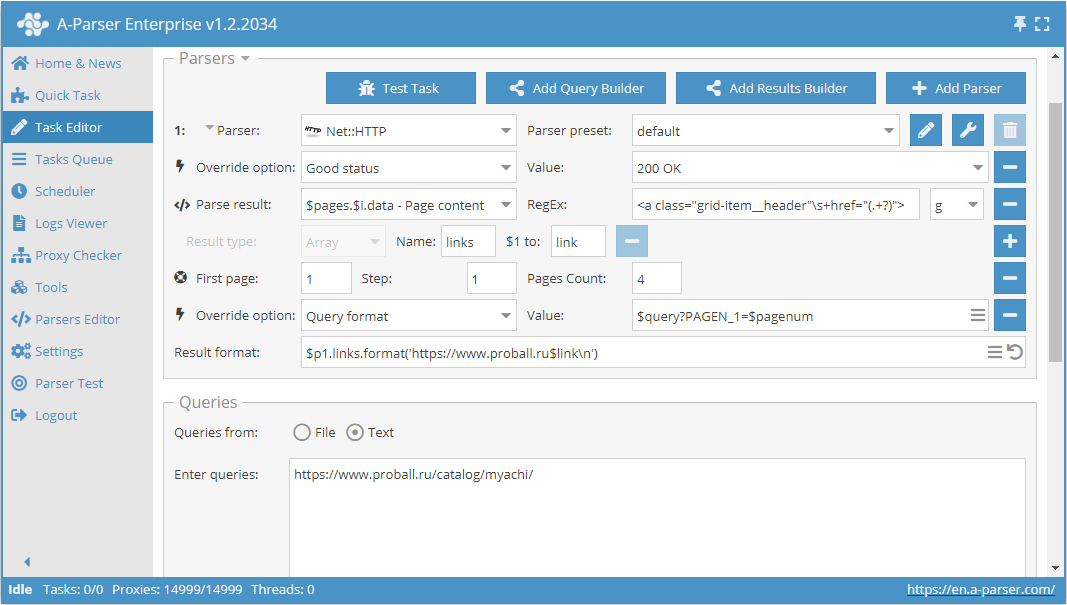
Como se ve en la captura de pantalla, en el formato de consulta del extractor se utiliza la variable $pagenum en el lugar adecuado.
La función Use pages recorrerá y sustituirá en la consulta todos los valores; de hecho, obtendremos enlaces para la consulta:
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum
donde en lugar de la variable $pagenum se sustituirá el número de página, comenzando desde 1 hasta 4 con un paso de 1.
De esta manera, se logra el recorrido por las páginas del rango deseado. En esto reside la limitación de este método: es necesario conocer de antemano el número de páginas que hay en la paginación. Obviamente, al extraer datos de varias categorías simultáneamente, el número de páginas será diferente en cada una, y como solución, simplemente podemos indicar un número mayor de páginas supuestas. Pero esto no es del todo correcto, por lo que existe una solución más óptima que se tratará más adelante.
Descargar ejemplo
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2
pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn
PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0
9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+
1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh
9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob
jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4
YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5
QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u
kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp
sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9
P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8
z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M
vOJ4VZ5BGJXHUBcgGBZ/AXULzRU=
Uso de Check next page
Check next page es otra función que permite organizar el recorrido por la paginación. La particularidad de su uso es que, para pasar a la siguiente página, se debe utilizar una expresión regular que devuelva el enlace a la página siguiente. Este es un método más conveniente y el más aplicado con frecuencia. Sin embargo, no se puede aplicar para https://www.proball.ru/catalog/myachi/, ya que en el código no hay enlaces a las páginas siguientes. Los enlaces allí son generados por un script. Por lo tanto, tomaremos como ejemplo el sitio http://www.imdb.com/search/name?gender=female. Aquí hay paginación tanto al principio como al final de la lista. Al observar y analizar el código fuente, se puede ver la presencia de un enlace que permite pasar a la página siguiente:
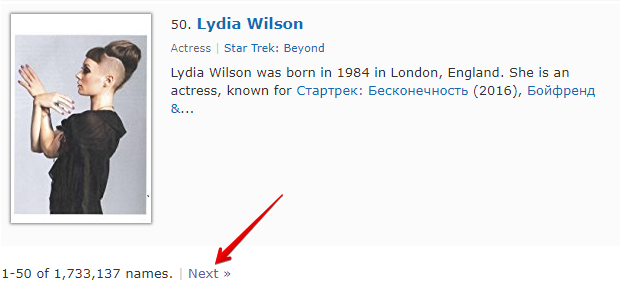
- en el campo Next page RegEx escribiremos la expresión regular
- en el campo Limit (Límite) indicaremos el número de páginas que se deben recorrer
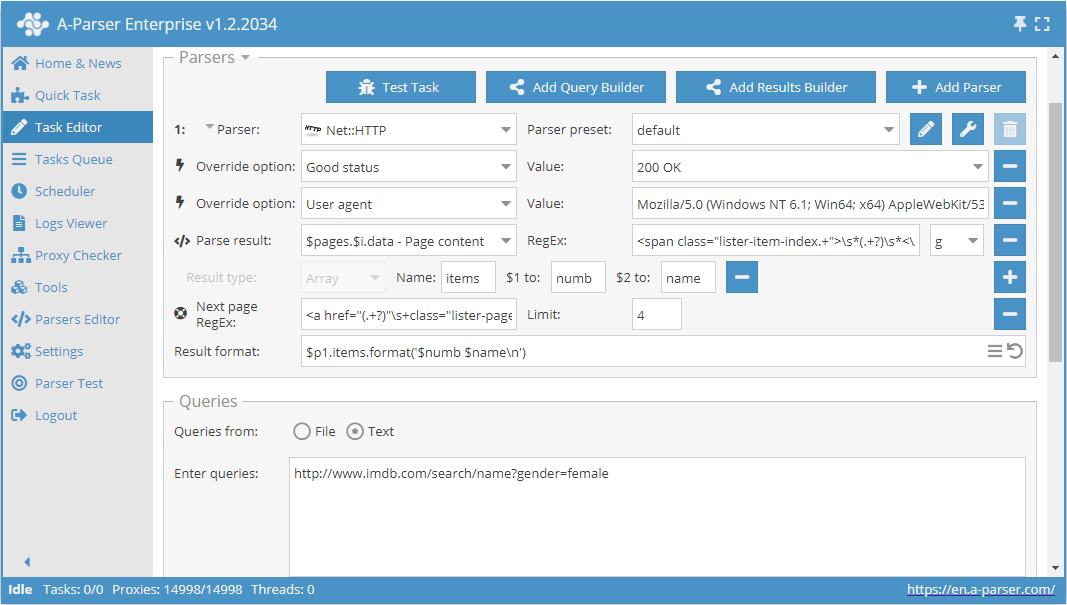
En el ejemplo se indica 4. Al indicar el límite, definimos cuántas páginas debe recorrer el extractor. En nuestro caso se recorrerán 5 páginas, ya que el conteo comienza desde 0. Si se indica un límite de 0, el extractor funcionará hasta que recorra todas las páginas independientemente de su cantidad. Esto es muy útil cuando se necesita extraer todos los resultados de todas las páginas.
Descargar ejemplo
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS
sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr
gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp
ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I
22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY
FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI
HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu
NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O
MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7
exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x
+JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L
itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy
KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18
bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq
iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU
tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY
11r9ASIaBUM=
Como se mencionó anteriormente, existe la posibilidad de limitar dinámicamente el número de páginas en Use pages. Para ello, se deben usar conjuntamente Use pages y Check next page. Complementemos el ejemplo que se analizó al describir Use pages y añadamos la función Check next page:
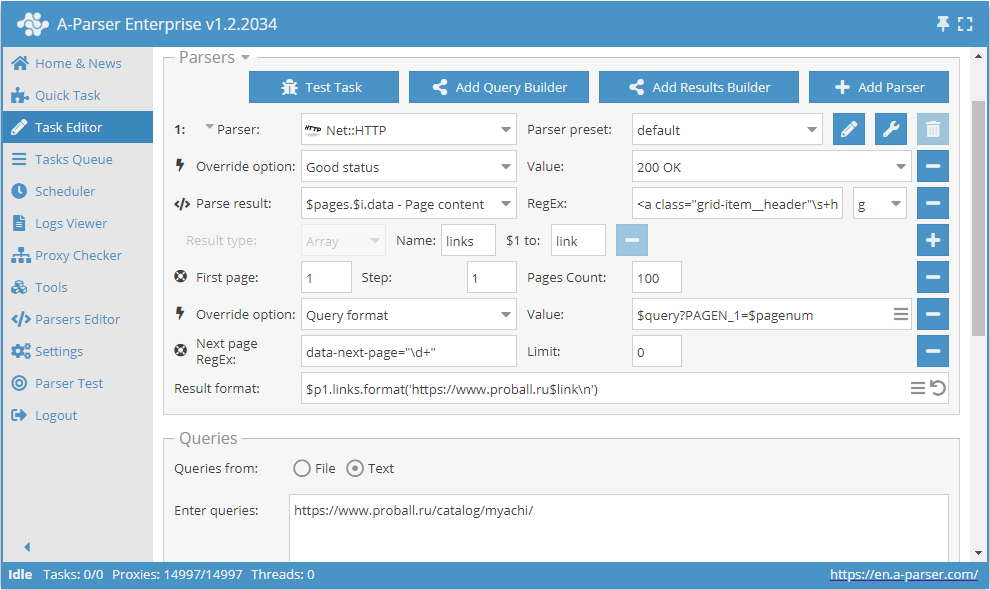
Estas dos funciones en conjunto trabajan de la siguiente manera: Use pages asegura el recorrido por las páginas, mientras que Check next page verifica si existe la siguiente. Tan pronto como Check next page no encuentre la página siguiente, la extracción de datos de esa categoría se detendrá sin esperar a completar todo el número indicado en Use pages. Al combinar estas funciones, añadimos eficiencia al trabajo del extractor, ahorrando tiempo y recursos.
Descargar ejemplo
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF
XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG
eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY
LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve
u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals
SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8
Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g
45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa
eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS
mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x
GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ
NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ
EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0
0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g
KP8Byg3yDQ==
Uso de macros de sustitución
Los macros de sustitución permiten implementar la sustitución secuencial de valores de un rango especificado.
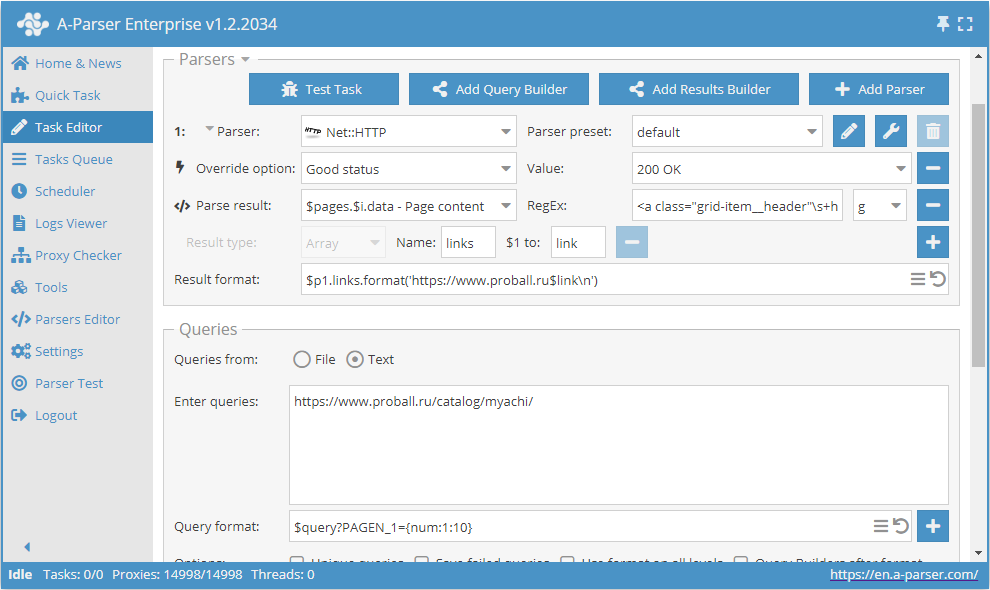
Este ajuste preestablecido funcionará de la siguiente manera. Al indicar en el formato de consulta la plantilla:
$query?PAGEN_1={num:1:10}
añadimos la sustitución de valores del 1 before 10 (se puede indicar cualquier rango) en la propia consulta. De esta manera obtenemos consultas que aseguran el recorrido por el número deseado de páginas, del tipo:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
https://www.proball.ru/catalog/myachi/?PAGEN_1=2
...
https://www.proball.ru/catalog/myachi/?PAGEN_1=10
El uso de macros de sustitución para el recorrido por la paginación es similar a la función Use pages y tiene las mismas limitaciones, es decir, es necesario indicar un rango específico de valores. La ventaja de este método es que a través de los macros de sustitución se pueden insertar diferentes valores, tanto numéricos como de texto, por ejemplo, palabras o expresiones. De esta manera podemos insertar de forma más flexible las partes necesarias en las consultas o formar las propias consultas a partir de partes que se ubicarán en diferentes archivos, si la tarea lo requiere.
Descargar ejemplo
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a
AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix
JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi
Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6
OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ
IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC
4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv
nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk
vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke
AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa
F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q
MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU
1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg==
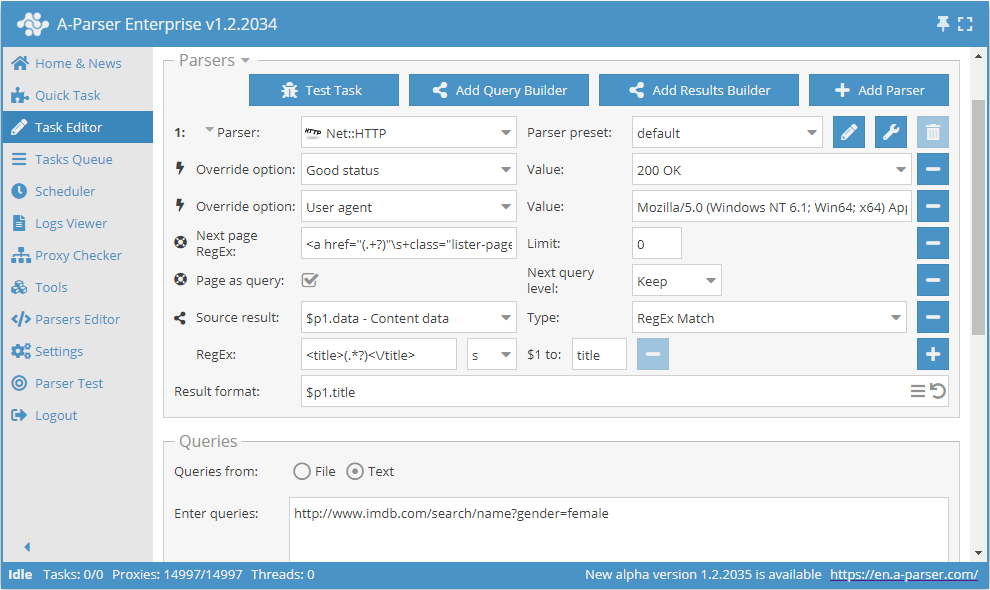
Uso de Page as query
Para reducir el consumo de memoria, se puede definir la lógica mediante la opción Page as query. Al activarla, las funciones Check next page y Use pages sustituirán cada página siguiente en las consultas como una consulta independiente, evitando así acumular su contenido en la memoria. Page as query también permite definir si se debe aumentar el nivel de la consulta Increase (similar al funcionamiento de la herramienta tools.query.add) o no Keep.
Descargar ejemplo
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM
tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA
DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z
ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv
dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i
pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr
mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa
VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1
Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl
CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa
lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0
ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn
5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob
7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD
yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj
geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8=
Configuraciones posibles
| Nombre del parámetro | Valor por defecto | Descripción |
|---|---|---|
| Good status | All | Selección de qué respuesta del servidor se considerará exitosa. Si durante la extracción de datos se recibe otra respuesta del servidor, la solicitud se repetirá con otro proxy. |
| Good code RegEx | Posibilidad de indicar una expresión regular para verificar el código de respuesta. | |
| Ban Proxy Code RegEx | Posibilidad de banear proxies temporalmente (Proxy ban time) basándose en el código de respuesta del servidor. | |
| Method | GET | Método de solicitud. |
| POST body | Contenido para enviar al servidor cuando se utiliza el método POST. Admite las variables $query – URL de la solicitud, $query.orig – solicitud original y $pagenum - número de página al usar la opción Use Pages. | |
| Cookies | Posibilidad de indicar cookies para la solicitud. | |
| User agent | _Se sustituye automáticamente el user-agent de la versión actual de Chrome_ | Encabezado User-Agent al solicitar páginas. |
| Additional headers | Posibilidad de indicar encabezados de solicitud arbitrarios con soporte para las capacidades del motor de plantillas y el uso de variables del constructor de consultas. | |
| Read only headers | ☐ | Leer solo encabezados. En algunos casos permite ahorrar tráfico si no es necesario procesar el contenido. |
| Detect charset on content | ☐ | Reconocer la codificación basándose en el contenido de la página. |
| Emulate browser headers | ☑ | Emular encabezados de navegador. |
| Max redirects count | 7 | Número máximo de redirecciones que seguirá el extractor. |
| Follow common redirects | ☑ | Permite realizar redirecciones http <-> https y www.domain <-> domain dentro de un mismo dominio omitiendo el límite Max redirects count. |
| Max cookies count | 16 | Número máximo de cookies a guardar. |
| Engine | HTTP (Fast, JavaScript Disabled) | Permite elegir el motor HTTP (más rápido, sin JavaScript) o Chrome (más lento, JavaScript habilitado). |
| Chrome Headless | ☐ | Si la opción está activada, el navegador no se mostrará. |
| Chrome DevTools | ☐ | Permite utilizar herramientas de depuración de Chromium. |
| Chrome Log Proxy connections | ☐ | Si la opción está activada, se mostrará información sobre las conexiones de Chrome en el registro. |
| Chrome Wait Until | networkidle2 | Determina cuándo se considera que la página ha cargado. Más información sobre los valores. |
| Use HTTP/2 transport | ☐ | Determina si usar HTTP/2 en lugar de HTTP/1.1. Algunos sitios banean inmediatamente si se usa HTTP/1.1, mientras que otros no funcionan con HTTP/2. |
| Try use HTTP/1.1 for Protocol error | ☑ | Indica al extractor que repita la solicitud con HTTP/1.1 si HTTP/2 estaba activado y se recibió un error de protocolo (es decir, si el sitio no funciona con HTTP/2). |
| Don't verify TLS certs | ☐ | Desactivación de la validación de certificados TLS. |
| Randomize TLS Fingerprint | ☐ | Esta opción permite omitir el baneo de sitios por huella TLS. |
| Bypass CloudFlare with Chrome | ☐ | Omisión automática de la verificación de CloudFlare. |
| Bypass CloudFlare with Chrome Max Pages | 20 | Número máximo de páginas al omitir CF a través de Chrome. |
| Bypass CloudFlare with Chrome Headless | ☑ | Si la opción está activada, el navegador no se mostrará durante la omisión de CF a través de Chrome. |