SE::Yandex::Position - Comprobación de posiciones de sitios web por palabras clave en Yandex
Descripción general del extractor
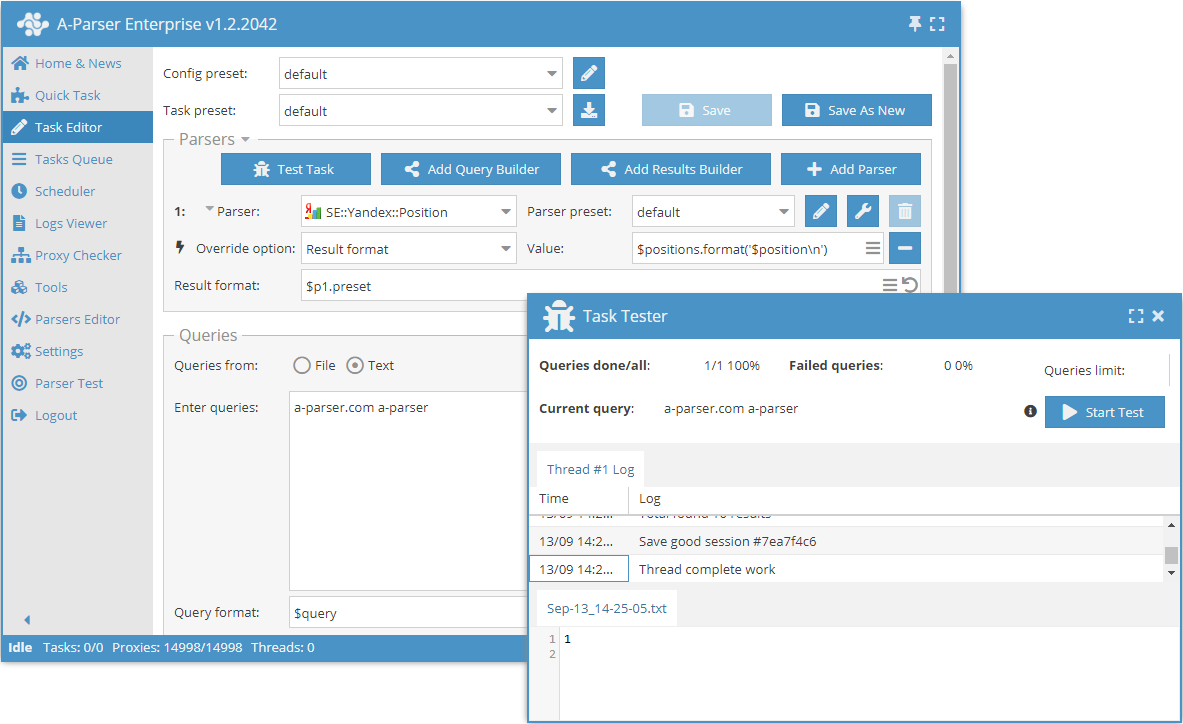
Extractor de verificación de posiciones de sitios web por palabras clave en Yandex. Gracias al extractor SE::Yandex::Position, podrá verificar automáticamente las posiciones en los resultados de búsqueda de Yandex utilizando sus propias bases de datos de dominios. Utilizando el extractor SE::Yandex::Position, es posible determinar de manera fácil, precisa y rápida la posición de un sitio en Yandex. La verificación de posiciones en Yandex se realiza en modo multihilo, con la posibilidad de utilizar servicios de resolución de captchas (AntiCaptcha o cualquier otro que admita su API). El extractor de posiciones de Yandex siempre está actualizado, ya que nuestros especialistas lo mantienen al día regularmente.
La funcionalidad de A-Parser permite guardar la configuración de extracción del extractor SE::Yandex::Position para su uso posterior (ajustes preestablecidos), establecer programas de extracción y mucho más. Puede utilizar la sustitución automática de subconsultas desde archivos.
El guardado de resultados es posible en la forma y estructura que necesite, gracias al potente motor de plantillas integrado Template Toolkit, que permite aplicar lógica adicional a los resultados y exportar datos en varios formatos, incluyendo JSON, SQL y CSV.
Casos de uso del extractor
🔗 Resumen de opciones de visualización
El artículo analiza 4 opciones diferentes para presentar el resultado: texto, CSV, JSON, HTML
🔗 ⏩Posiciones para múltiples regiones
Obtención de posiciones del sitio simultáneamente para varias regiones
Datos recopilados
- La posición del sitio y el enlace a la página del sitio
- Lista de todas las posiciones del sitio y enlaces a las páginas
Características
- Todas las capacidades del extractor
 SE::Yandex
SE::Yandex - Detiene automáticamente la extracción al encontrar el sitio
- Soporta la búsqueda de subdominios
- Posibilidad de comparar la posición buscada por dominio, por dominio principal y por enlace completo
- Recopilación de posiciones de varios dominios a la vez
Casos de uso
- Verificación de posiciones de sitios propios y de la competencia
- Búsqueda de páginas con tráfico del sitio
Consultas
Como consultas, es necesario indicar el dominio del sitio buscado y la consulta de búsqueda separados por un espacio, por ejemplo:
lenta.ru noticias
lenta.ru noticias online
Si es necesario verificar un solo sitio con una lista de consultas, se puede indicar el dominio en el formato de consulta (Query format):
lenta.ru $query
O simplemente usar una lista de palabras clave. Para usar varios dominios a la vez en la consulta, debe indicar la lista de dominios separados por comas y, tras un espacio, la palabra clave, por ejemplo:
lenta.ru,ria.ru,notfound.com noticias cinta
Los resultados se grabarán en el array $bulkcheck.
La opción Stop when found también es compatible; la extracción terminará si se encuentran posiciones para todos los dominios.
Sustituciones de consultas
Puede utilizar macros integradas para la sustitución automática de subconsultas desde archivos; por ejemplo, si queremos verificar sitios/un sitio mediante una base de claves, indicaremos varias consultas principales:
ria.ru
lenta.ru
rbc.ru
yandex.ru
En el formato de consultas indicaremos la macro de sustitución de palabras adicionales del archivo Keywords.txt; este método permite verificar una base de sitios contra una base de claves y obtener las posiciones como resultado:
$query {subs:Keywords}
Esta macro creará tantas consultas adicionales como haya en el archivo para cada consulta de búsqueda inicial, lo que resultará en [cantidad de consultas iniciales (dominios)] x [cantidad de consultas en el archivo Keywords] = [cantidad total de consultas] como resultado del trabajo de la macro.
Variantes de salida de resultados
A-Parser admite un formateo flexible de resultados gracias al motor de plantillas integrado Template Toolkit, lo que le permite mostrar los resultados en forma arbitraria, así como en forma estructurada, por ejemplo CSV o JSON.
Exportación de la lista de posiciones
Obtención del resultado en formato:
dominio buscado - clave: número de posición en los resultados
Formato del resultado:
$domain - $key: $position\n
Ejemplo de resultado:
lenta.ru - noticias: 3
lenta.ru - noticias online: 13
...
Verificación simultánea de varios dominios (verificación por lotes)
La información de todos los dominios en una verificación simultánea se encuentra en el array $bulkcheck.
Formato del resultado:
$bulkcheck.format('$domain - $position\n')
Ejemplo de consulta:
lenta.ru,ria.ru,notfound.com noticias cinta
Ejemplo de resultado:
lenta.ru - 1
ria.ru - 4
notfound.com - 0
Enlaces + anclas + snippets con salida de posición
Salida de enlaces, anclas y snippets en tabla CSV
Guardado de palabras clave relacionadas
Competencia de palabras clave
Verificación de indexación de enlaces
Guardado en formato SQL
Volcado de resultados en JSON
Procesamiento de resultados
A-Parser permite procesar los resultados directamente durante la extracción; en esta sección presentamos los casos más populares para el extractor SE::Yandex::Position.
Guardado de dominios sin posiciones cero
Se tomó como base el ejemplo de verificación simultánea de varios dominios (ver arriba en variantes de salida de resultados) y se añadió un filtro.
Añadir un filtro y en la lista desplegable seleccionar la variable de salida de posición. Seleccionar el tipo: >. Luego, en Number (Número), escribir 0. Con este filtro podrá eliminar todos los resultados con posición cero.
Descargar ejemplo
Cómo importar un ejemplo en A-Parser
eJx1VE1v2zAM/SuGEKAr4AXJ1gKDDwPSYAE2dE3Xj8OQ5KBGdKtFFj1JTpsF/u+j
ZNlOuu4im9Qj+fhEac8ctxt7bcCCsyxb7FkZ/lnGbr9k2U+uBbxk2TVa6STq5H1y
y7eQCCy41DZ5lu4JK5fw5A8YTMoIYykrubFgfMrFm5kIIiDnlXIs3TO3K4FK4haM
kQJoUwqyczQFd0QowNiWq8rDBg+V2qyfYL0ZNoh3J4OGEfEbtCSWS31yyur/Z68s
lAZfdn3mnCsLBxG5VA4M7UcK2YJ1pX2PbS+rNELvmrjPB2RH9I9lgGXMgrasXq3a
jHYW+PueyvEwSt9teqnvsOEBvXtG1hUvghKCO/C7rRCnQ/fiM3AhAjWumgr+IPqq
91r+DuQ0EpZ+jQQ7M1iQy0FI4J27lt2CDYLtG61C7I8mJkqWMktUZ5yIiNc7kmTh
Ds08aED+PUM9UeoStqB6WMh/UUklaGomOQV9jYFvQ+b/5Ki79g5L0Zk/G+LQZQnW
xfx7HyXwEh+pc/FAfStZSEe2nWKlXTy/DUDZaXblNSvQQFcmZo7V6TKVoP2A9Uc2
KXvXURtHx3LsXKPO5eM8Dm2LrPQd3di5nmJRKvB96Uqp1A/zTT8eExuPwRs9wdfB
01DCt95eReYQlf1221AtjaTxO/cEC1LysGpMueZK3d9cHu6wfqTIUKAdH5oqNTJ8
NLqclBXDNRbJshqdfRRhhbB+6P/PxmFtPJ8a6ENYz/uwuD1a+vdkTXfhEWlKSal6
1T1B3eO2f/shyvY1DcEve93AvWIeTD6S3gbEuP4LmbnKEA==
Ver también: Filtros de resultados
Unicidad de enlaces
Unicidad de enlaces por dominio
Extracción de dominios
Eliminación de etiquetas de anclas y snippets
Filtrado de enlaces por inclusión
Configuraciones posibles
Soporta todas las configuraciones del extractor SE::Yandex, así como adicionalmente:
| Nombre del parámetro | Valor por defecto | Descripción |
|---|---|---|
| Pages count | 1 | Cantidad de páginas de extracción de resultados (de 1 a 25) |
| Links per page | 20 | Cantidad de enlaces en los resultados por página (10 / 20 / 30 / 50) |
| Result format | $domain - $key: $position\n | Formato de salida de resultados por defecto |
| Stop when found | ☑ | Detener la extracción si se encuentra el dominio, no pasará a las siguientes páginas |
| Match type | Exact domain | Posibilidad de comparar la posición buscada por dominio, por dominio principal y por enlace completo (Exact domain / Top level domain / Exact url) |