SE::Google - Scraper de resultados de busca do Google
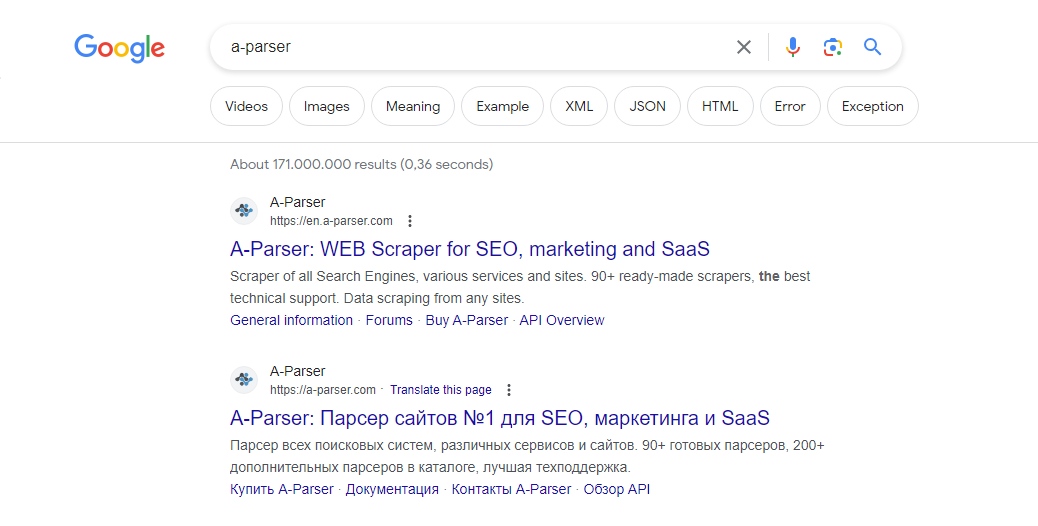
Visão geral do scraper
O scraper de resultados de pesquisa do Google é um dos mais requisitados, permitindo que você obtenha enormes bases de links prontos para uso posterior. Você pode usar consultas da mesma forma que as digita no Google, incluindo operadores de pesquisa (inurl, intitle, etc.).
O scraper do Google suporta a multiplicação automática de consultas, garantindo que você obtenha o número máximo de resultados da pesquisa. Além disso, o A-Parser pode navegar automaticamente por consultas relacionadas até a profundidade especificada. Graças ao processamento em múltiplas threads do A-Parser, a velocidade de processamento pode atingir 3000-7000 consultas por minuto, o que permite obter, em média, até 500000 links por minuto.
A funcionalidade do A-Parser permite salvar as configurações de extração de dados para uso futuro (presets), definir agendamentos de extração de dados e muito mais. Você pode usar a multiplicação automática de consultas, substituição de subconsultas a partir de arquivos, combinação de caracteres alfanuméricos e listas para obter o máximo possível de resultados.
A gravação dos resultados é possível no formato e estrutura que você desejar, graças ao poderoso motor de modelos integrado Template Toolkit, que permite aplicar lógica adicional aos resultados e exibir dados em vários formatos, incluindo JSON, SQL e CSV.
Casos de uso do scraper
🔗 Extração de domínios
Extração de domínios temáticos por palavra-chave do Google e obtenção de vários parâmetros dos domínios
🔗 Extração de dados do Google News
Este preset extrai notícias do Google por consulta de pesquisa e coleta as datas dessas notícias
🔗 Verificação de indexação
O preset verifica a indexação de páginas do site no Google, percorrendo a lista de links especificados
🔗 Avaliação de concorrência
O preset determina a concorrência no sistema de busca Google por palavras-chave
🔗 Extração de dados do top 3
O preset salva os três primeiros snippets dos resultados de busca do Google
🔗 Perguntas e respostas
Scraper que coleta perguntas e respostas da seção People Also Ask
Dados coletados
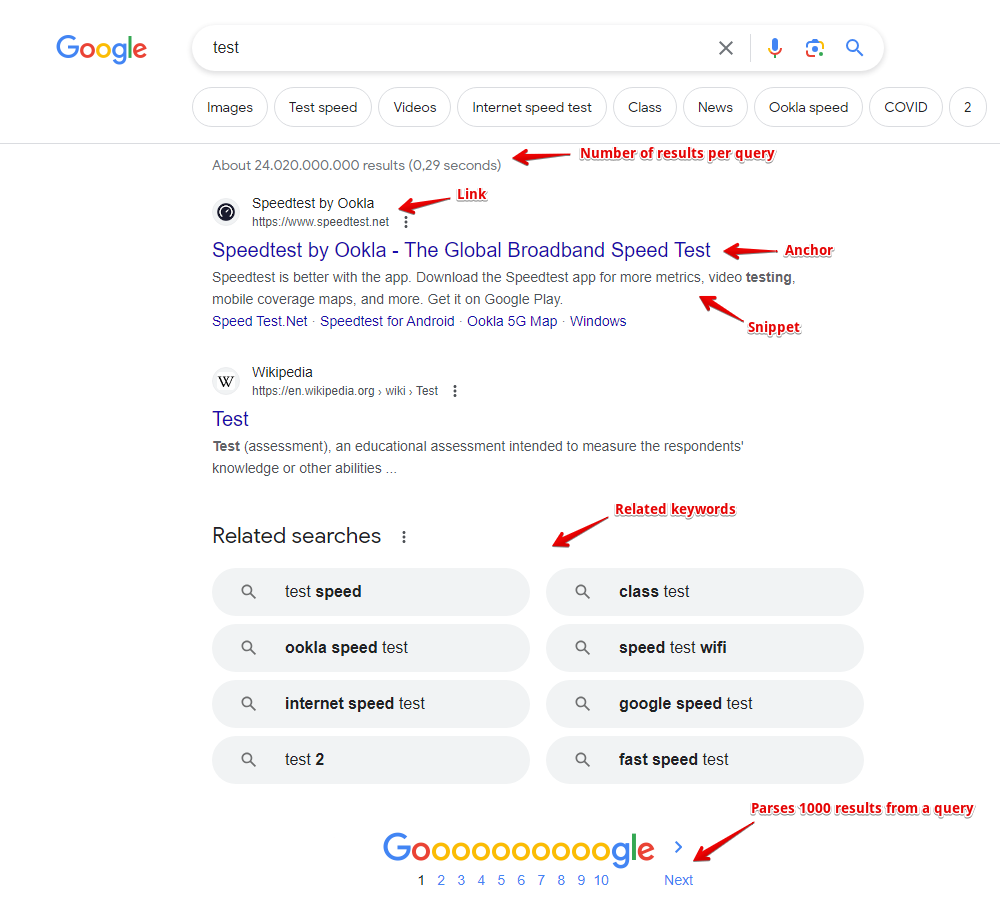
- Links, âncoras e snippets dos resultados, bem como a data do snippet (se disponível)
- Também são coletadas informações sobre as flags de cada resultado; atualmente são suportadas: Date, AMP, Image Preview, Video, Rich snippet, Featured snippet
- Presença e conteúdo de blocos de anúncios, bem como sua posição na página
- Quantidade de resultados por consulta (concorrência)
- Lista de palavras-chave relacionadas (Related keywords)
- Presença de blocos adicionais na página: carrossel de produtos, vídeos, etc.
- O scraper também coleta os seguintes dados adicionais:
- Presença de erro de digitação na consulta e a consulta corrigida
- Localização geográfica determinada pelo Google
- Presença de páginas AMP
- Lista de People also ask: perguntas, respostas, links para fontes, suas âncoras e links para mídia (ativado pela opção separada Parse People also ask)
- Resposta de IA (AI overview), seu tipo e lista de fontes
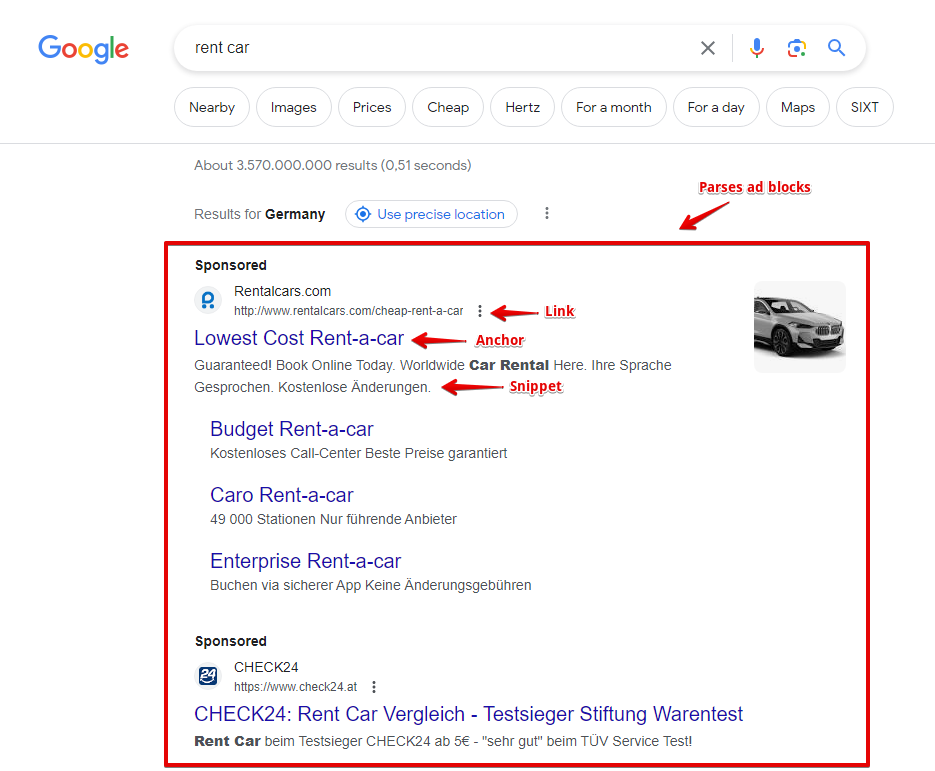
Recursos
O scraper do sistema de busca Google possui diversos recursos e configurações:
- suporte a todos os operadores de pesquisa do Google (site:, inurl:, etc.)
- especificação do tamanho dos resultados (10, 20, 30, 50 ou 100 resultados) e do número de páginas (de 1 a 10); em configurações máximas, o Google fornece de 300 a 500 resultados por consulta, e o A-Parser contorna facilmente essa limitação através da multiplicação de consultas
- possibilidade de navegação automática por palavras-chave relacionadas
- especificação do idioma e país dos resultados, opção de escolher o domínio local do Google, bem como o idioma da interface dos resultados
- possibilidade de especificar a geolocalização, o que permite obter resultados locais precisos para qualquer lugar do globo terrestre
- escolha entre visualização desktop ou móvel
- possibilidade de escolher o tipo de resultado: além da busca orgânica principal, o scraper do Google pode coletar resultados de notícias, livros ou vídeos
- se necessário, é possível conectar o reconhecimento automático de ReCaptcha2 através de serviços de resolução ou via XEvil/CapMonster
- suporte à especificação do período dos resultados (todo o período ou um intervalo específico de 24 horas a um ano)
- possibilidade de desativar o filtro do Google que oculta resultados semelhantes (filter=)
- possibilidade de definir se deve extrair dados se o Google informar que nada foi encontrado para a consulta e sugerir resultados para uma consulta semelhante
- possibilidade de definir a quantidade de People also ask que o scraper deve coletar, clicando em profundidade em cada pergunta
- possibilidade de coletar tags
Os seguintes scrapers funcionam com base no scraper do Google:
 SE::Google::Position - determinação de posições de quaisquer sites nos resultados de busca por uma lista de consultas
SE::Google::Position - determinação de posições de quaisquer sites nos resultados de busca por uma lista de consultas SE::Google::Compromised - verifica domínios quanto à limpeza do ponto de vista do Google, capaz de identificar sites hackeados e de phishing
SE::Google::Compromised - verifica domínios quanto à limpeza do ponto de vista do Google, capaz de identificar sites hackeados e de phishing SE::Google::TrustCheck - verifica o Trust (confiança) do Google em relação ao site
SE::Google::TrustCheck - verifica o Trust (confiança) do Google em relação ao site
Opções de uso
- Coleta de bases de links - para XRumer, AllSubmitter, GSA Ranker, etc.
- Dump completo do SERP, incluindo links, âncoras, snippets, blocos de anúncios e outras informações, permitindo análises profundas para especialistas em SEO e profissionais de marketing
- Avaliação da concorrência para palavras-chave
- Avaliação da concorrência em resultados de PPC (anúncios)
- Busca de backlinks e menções a sites
- Verificação de indexação de sites
- Busca de sites vulneráveis
- Quaisquer outras opções que envolvam a obtenção de resultados de pesquisa para um número ilimitado de consultas
Consultas
Como consultas, devem ser indicadas frases de pesquisa, exatamente como se fossem digitadas diretamente no formulário de busca do Google, por exemplo:
compra de carro
janelas em lisboa
site:https://lenta.ru
inurl:guestbook
Substituições de consultas
Você pode usar macros integradas para multiplicar consultas; por exemplo, se quisermos obter uma base muito grande de fóruns, indicaremos algumas consultas principais em diferentes idiomas:
forum
fórum
foro
论坛
No formato de consultas, indicaremos a permutação de caracteres de a até zzzz; este método permite rotacionar ao máximo os resultados de pesquisa e obter muitos novos resultados únicos:
$query {az:a:zzzz}
Esta macro criará 475254 consultas adicionais para cada consulta de pesquisa inicial, resultando em um total de 4 x 475254 = 1901016 consultas de pesquisa, um número impressionante, mas que não é problema para o A-Parser. Com uma velocidade de 2000 consultas por minuto, essa tarefa seria processada em apenas 16 horas.
Uso de operadores
Você pode usar operadores de pesquisa no formato da consulta, de modo que eles sejam adicionados automaticamente a cada consulta da sua lista:
inurl:$query
Opções de exibição de resultados
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, permitindo exibir resultados em formato livre ou estruturado, como CSV ou JSON.
Exportação de lista de links
Formato do resultado:
$serp.format('$link\n')
Exemplo de resultado:
https://www.weforum.org/open-forum/
https://www.weforum.org/about/world-economic-forum/
https://www.merriam-webster.com/dictionary/forum
https://en.wikipedia.org/wiki/Forum
https://dictionary.cambridge.org/dictionary/english/forum
https://www.collinsdictionary.com/dictionary/english/forum
https://www.linkedin.com/company/world-economic-forum
https://docs.moodle.org/en/Forum_activity
https://wordpress.org/support/forums/
https://www.facebook.com/worldeconomicforum/
...
Links + âncoras + snippets com exibição de posição
Formato do resultado:
[% FOREACH item IN serp; loop.count _ ' - ' _ item.link _ ' - ' _ item.anchor _ ' - ' _ item.snippet _ "\n"; END %]
Exemplo de resultado:
1 - https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC - Fórum — Wikipédia - <em>Fó́rum</em> (lat. forum — antigo átrio de túmulo; área em lagar para uvas a serem processadas; praça de mercado, mercado da cidade; ...
2 - https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC_(%D0%BC%D0%B5%D1%80%D0%BE%D0%BF%D1%80%D0%B8%D1%8F%D1%82%D0%B8%D0%B5) - Fórum (evento) — Wikipédia - <em>Fórum</em> — evento realizado para identificar ou resolver quaisquer<wbr>problemas suficientemente globais. Este conceito é encontrado em ...
3 - https://support.google.com/googleplay/community?hl=ru - Bem-vindo ao fórum de ajuda da comunidade ... - Bem-vindo ao fórum de ajuda da <em>fórum</em> comunidade Google Play. Postagens em destaque. Ver todas as postagens interessantes · Precisa de ajuda com um jogo?
4 - https://support.google.com/mail/community?hl=en - Gmail Community - Google Support - Welcome to the Gmail Help Community · Featured posts · Categories.
5 - https://www.weforum.org/ - The World Economic Forum - The World Economic Forum is an independent international organization committed to improving the state of the world by engaging business, political, academic ...
6 - https://www.kunena.org/ - Home - Kunena - To Speak! Next Generation Forum ... - Kunena! - To Speak! Next Generation Forum Component for Joomla.
7 - https://forum.adguard.com/index.php - AdGuard Forum - <em>Fórum</em> de testadores beta. Escreva aqui relatórios de bugs das versões beta. Tópicos: 355. Mensagens: 11.6K. Sub-fóruns: Comentários sobre lançamentos de versões beta ...
8 - https://www.sofiaforum.bg/ - Fórum de Segurança de Sófia: Plataforma para discussão ... - Fórum de Segurança de <em>Sófia</em> Segurança / Sofia Security Forum.
9 - https://forum.keenetic.net/ - Forums - Keenetic Community - Keenetic fan club. A place to meet software developers, get the latest updates, and share experience.
10 - https://forum.euroaion.com/ - Perfect quality European private server of Aion - EuroAion.com - Perfect quality European private server of Aion!
...
Exibição de links, âncoras e snippets em tabela CSV
A utilidade integrada $tools.CSVLine permite criar documentos tabulares corretos, prontos para importação no Excel ou Google Planilhas.
Formato geral do resultado:
[% FOREACH i IN p1.serp; tools.CSVline(i.link, i.anchor, i.snippet); END %]
Nome do arquivo:
$datefile.format().csv
Texto inicial:
Link,Âncora,Snippet
Exemplo de resultado:
Link,Âncora,Snippet
https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC,"Fórum — Wikipédia",
https://en.wikipedia.org/wiki/Forum,"Forum - Wikipedia","<em>Forum</em> (plural forums or fora) may refer to: Contents. 1 Common uses; 2 Places. 2.1 Natural features; 2.2 Populated places. 3 Arts and entertainment; 4 Media."
https://www.weforum.org/,"The World Economic Forum","The World Economic <em>Forum</em> is an independent international organization committed to improving the state of the world by engaging business, political, academic ..."
https://support.google.com/webmasters/community?hl=ru,"Bem-vindo ao fórum de ajuda da comunidade ...","Bem-vindo ao fórum de ajuda da <em>fórum</em> comunidade Central da Pesquisa Google. Postagens em destaque. Ver todas as postagens interessantes · Respostas para ..."
https://support.google.com/chrome/community?hl=ru,"Bem-vindo ao fórum de ajuda da comunidade ...","Bem-vindo ao fórum de ajuda da <em>fórum</em> comunidade Google Chrome. Em destaque ..."
...
No Formato geral de resultados, aplica-se o motor de modelos Template Toolkit para exibir o array $serp em um loop FOREACH.
No nome do arquivo de resultados, basta alterar a extensão do arquivo para csv.
Para que a opção "Prepend text" esteja disponível no Editor de tarefas, é necessário ativar "More options". No "Prepend text", escrevemos os nomes das colunas separados por vírgula e deixamos a segunda linha vazia.
Exibição de blocos de anúncios
Formato do resultado:
$ads.format('$link - $anchor - $snippet\n')
Exemplo de resultado:
https://www.rentalcars.com/ - Rent a Car Worldwide - Best Prices Online Guaranteed - Secure Your <em>Car Hire</em> Today. The Best Price Guaranteed. Book at Over 53,000 Locations. Search, Compare and Save Using the World's Biggest Online <em>Car Rental</em> Service.
https://www.kayak.com/United-States-Car-Rentals.253.crc.html - United States from $9/day - Search for Rental Cars on Kayak - Find and Compare Great <em>Car</em> Deals in USA. Book with Confidence on KAYAK®!
https://www.discovercars.com/ - -70% Worldwide Car Rental - Rent Your Car in 5 Minutes - <em>Car rental</em> prices are rising, but if you act fast, you can get a good deal. Don’t stress! We...
https://www.economybookings.com/ - Rent a Car for Summer Holidays - Car Rentals for the Best Price - Theft protection and Third Party liability part of a great deal. Free Mileage included.
...
Salvando palavras-chave relacionadas
Formato do resultado:
$related.format('$key\n')
Exemplo de resultado:
test <b>speed</b>
<b>net speed</b> test
<b>google speed</b> test
<b>fast speed</b> test
<b>ping</b> test
<b>xfinity speed</b> test
<b>speed</b> test <b>mobile</b>
test <b>my</b>
...
Para remover automaticamente as tags HTML no resultado, você deve usar o Construtor de resultados, selecionar o array $related e aplicar Remove HTML tags.
Concorrência de palavras-chave
Formato do resultado:
$query - $totalcount\n
Exemplo de resultado:
speed test mobile - 1080000000
test score - 4020000000
net speed test - 1210000000
fast speed test - 2150000000
speed test - 2500000000
test match - 4160000000
ping test - 425000000
google speed test - 1870000000
Identificação de palavras-chave com erros
Formato do resultado:
$query - $misspell\n
Exemplo de resultado:
spead test - 1
test match - 0
speed test - 0
temst match - 1
Verificação de indexação de links
Formato da consulta:
site:$query
Formato do resultado:
$query.orig - $totalcount\n
Exemplo de resultado:
https://a-parser.com/pages/buy - 2
https://a-parser.com/wiki/parsers - 4
https://a-parser.com/resources - 883
https://trjkjfkdf.bg.ky - none
https://a-parser.com/forum - 371
Para verificar a indexação de links, insira no Formato da consulta o operador correspondente: site:.
O formato do resultado é exibido como "url original - quantidade de páginas no índice".
Como resultado, obtemos o endereço das páginas e sua quantidade no índice do buscador.
Se a página estiver ausente, o resultado será: none.
Salvando em formato SQL
Formato do resultado:
[% FOREACH serp; "INSERT INTO serp VALUES('" _ query _ "', '"; link _ "', '"; anchor _ "')\n"; END %]
Exemplo de resultado:
INSERT INTO serp VALUES('test', 'https://www.speedtest.net/', 'Speedtest by Ookla - The Global Broadband Speed Test')
INSERT INTO serp VALUES('test', 'https://fast.com/', 'Fast.com: Internet Speed Test')
INSERT INTO serp VALUES('test', 'https://www.business-standard.com/article/sports/ind-vs-aus-live-score-4th-day-5-india-vs-australia-live-cricket-score-online-brisbane-weather-121011900103_1.html', 'IND vs AUS 4th Test highlights: India creates history, wins ...')
INSERT INTO serp VALUES('test', 'https://www.test.com/', 'Find online tests, practice test, and test creation software | Test ...')
INSERT INTO serp VALUES('test', 'https://www.espncricinfo.com/series/india-in-australia-2020-21-1223867/australia-vs-india-4th-test-1223872/match-report-4', 'Recent Match Report - Australia vs India 4th Test 2020 ...')
INSERT INTO serp VALUES('test', 'https://www.icc-cricket.com/world-test-championship/standings', 'World Test Championship (2019-2021) Points Table - Live ...')
INSERT INTO serp VALUES('test', 'https://www.icc-cricket.com/rankings/mens/team-rankings/test', 'ICC Test Match Team Rankings International Cricket Council')
INSERT INTO serp VALUES('test', 'https://projectstream.google.com/speedtest', 'Speedtest - Google')
INSERT INTO serp VALUES('test', 'https://www.google.com/search?hl=en&q=Software+Testing&stick=H4sIAAAAAAAAAONgecQ4g5Fb4OWPe8JSfYyT1py8xtjOyMUVnJFf7ppXkllSKaTCxQZlSXHxSHHo5-obmJul5GkwSHFxwXlKwUbuuy5NO8fmKMgABGJm_g5SmlpCXOyexT75yYk5ggpvuB68mfLeXkuYiyMksSI_Lz-3UtCBgcHhx__39kqcnEBND7aoddhrMTTtW3GIjYWDUYCBZxGrQHB-Wkl5YlGqQkhqcUlmXjoAS5B1P7EAAAA&sa=X&ved=2ahUKEwiW-rnmlajuAhWpAGMBHR-JAv4Q6RMwHXoECDQQBQ', '')
...
Dump de resultados em JSON
Formato geral do resultado:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.links = [];
FOREACH item IN p1.serp;
obj.links.push(item.link);
END;
obj.json %]
Texto inicial:
[
Texto final:
]
Exemplo de resultado:
[{"totalcount":"6450000000","links":["https://www.speedtest.net/","https://fast.com/","https://projectstream.google.com/speedtest","https://www.test.com/","https://www.speakeasy.net/speedtest/","https://www.att.com/support/speedtest/","https://speedtest.xfinity.com/","https://developers.google.com/speed/pagespeed/insights/","https://www.espncricinfo.com/series/india-in-australia-2020-21-1223867/australia-vs-india-4th-test-1223872/match-report-4","https://nasional.tempo.co/read/1424570/listyo-sigit-temui-ahy-menjelang-fit-and-profer-test-calon-kapolri","https://www.google.com/search?hl=en&q=Test+Assessment&stick=H4sIAAAAAAAAAONgecRYyC3w8sc9YamMSWtOXmNM4uIKzsgvd80rySypFNLiYoOyFLj4pbj10_UNjQyzKsvyzDQYpHi5kAWUNIxkdl2ado5NTJABCMTKAhyUODmBLIVA-wX2WgxN-1YcYmPhYBRg4FnEyh-SWlyi4FhcnFpcnJuaVwIAwEAP9ogAAAA&sa=X&ved=2ahUKEwj17MzXmajuAhW8CWMBHRlzBP4Q6RMwDHoECBEQBQ"]}]
Para que as opções "Prepend text" e "Append text" estejam disponíveis no Editor de tarefas, é necessário ativar "More options".
Processamento de resultados
O A-Parser permite processar os resultados diretamente durante a extração de dados; nesta seção, apresentamos os casos mais populares para o scraper do Google.
Desduplicação de links
Adicionar desduplicação e selecionar $serp.$i.link - Link na lista suspensa.
Baixar exemplo
Como imortar o exemplo no A-Parser
eJx9VE1v2zAM/SsFkcMGBEFy2MW3NFiKDVnTNekpyEGNaUOLLGmSnDUw/N9H+ktO
N/Rmko+PfCTlCoLwZ//k0GPwkBwqsM03JLD7miQPxuQK7zZSn/3di5a/S4QpWOE8
OoYfRigKpJiJUgWYVhCuFonEXNA5mXJQpmRbZ96uDoOT6Ml3Eapk2GI+n0P9QZrI
8WRKHWLO4gO44n4tOk4bZcxHKWUvhuRyy8kBSJMlByfDcdoh9i3cU8c6h977oMyr
UJAEV2J9PPYsfm1cIXh4E7uYdZMcgjtxwb2hYCZVrOzXZD2KgqtMUhGQo7OsIfr0
eRbemEGkqQzSaKHaCjz7WLVbTALaEJY+ebprZwpyBWwI2HntuzvApLGjyp9tDiSZ
UB6n4KnVtaBG0vcRGdCJYNzWcj/kr8DopVIbvKCKsIb/vpQqpUNZZpT0rUv8P2T7
D0c9yBuXokX/cdTDwNJY99sfMSs1G5OT8vS1WWYhA9l+1VxPAnNynhHtMLNHnllh
HA5lOuauOr0Ni5qvKq5saaPrRsbNWm6dJ6MzmW+7S+2Rpd7TA9zqlSmsQtalS6Vo
LR6f43ksfbcGNmKD75NXTQmW3r9DCMYo/33XtmqdpPP7wg0WNMlx1Y7yJJR6ed6M
IxBPqjknz7QnutPc0AWRivo4/BGG/0g1/i8kVU1r+eWfWhBrYAj5aBieZs6P+S/t
6pW4
Veja também: Desduplicação de resultados
Desduplicação de links por domínio
Adicionar desduplicação e selecionar $serp.$i.link - Link na lista suspensa. Selecionar o tipo de desduplicação: Domain.
Baixar exemplo
Como imortar o exemplo no A-Parser
eJx9VE2P2jAQ/SvI4tBKaAWHXnJj6bJqRZftwp4QB0MmyMXxuLZDF0X89844IQ7b
am+ZmffefDq1CNIf/bMDD8GLbFMLG79FJlYPWfaIeNAwWChz9INXo35XMNidB1+x
lMqIkbDSeXBM3PTwFMihkJUOYlSLcLZAcngC51TOQZWTbR2+nR0Ep8CT7yR1xbDJ
eDwWlw9o8gB7rExInMkHcM2VW3BM6zHGPUoV26IgNc4lZxtBPVlyMFlsRy1i3cDz
a++N91HjTmqRBVfBZbu9qvg5ulLyGId2ctfOtAuu5AnWSMFC6ZTZz8l6kiVnGeYy
AEfviij06fNdeGMFmecqKDRSNxl49ilrsyLiGyQsffJ05w5LcgWIAuw8X6vbiGG0
U5c/G47ICqk9jISnUueSCsnfR1QAJwO6peV6yF8LNFOtF3ACnWBR/75SOqdDmRZE
+tYS/w9Z/qNx6drrp6JF/3FUQ6cSrfvlj8TKcYEHXtkuLrNUgWw/i9eTiTE5jwC2
m9kTz6xEB12aVrnNTq/EguGrSiub2uS6aeNmLbfOPZpCHZbtpV6RlVnTU1yaGZZW
A/dlKq1pLR5e0nlMfbsGNlKB78mzmIJbv75DERC1/75qSrVO0fl94QJLmmQ/ayu5
l1q/viz6EZFOKp6TZ9k93ekB6YKoi8u2+yN0f5S6/1/I6gut5Zd/bkDcA0PIR8Pw
NHN+zH8BRVyZDA==
Veja também: Desduplicação de resultados
Extração de domínios
Adicionar Result Builders (Construtor de resultados) e selecionar a fonte na lista suspensa: $p1.serp.$i.link - Link. Selecionar o tipo: Extract Domain.
Baixar exemplo
Como imortar o exemplo no A-Parser
eJx9VE1v2zAM/SuFkMMGBIFz2MW3NGuGDVnTNe0p6EGzaUOLLGqSnCUw8t9HKort
dkNv5scj+cgndyJIv/cPDjwEL/JdJ2z8FrnY3uX5F8Raw83dMThZhJvP2EhlxFRY
6Tw4BuxGeRQooZKtDmLaiXCyQGXwAM6pkoOqJNs6PJ4cBKfAk+8gdctp8yzLxPkd
mKyhwNaEATN/J10rs/cWHMNGiOz88jIVxJBm9Ct0jWSmEzufJdp9cCsP8IQUrFQk
dsWQdS8bbjkpZQCOzqpY6MPHWThyBVmWKig0Ul868JqGrs9G/Y6MDVIuffIiVg4b
cgWIBdh5uk63E5NoCyrRRuyPC0bkldQepsLTqCtJg5RvIyqAkwHdxvI85O8EmoXW
aziAHtJi/dtW6ZJuuqgI9DUB/5+y+afGuac3bkU3+eNohr5KtG433wdUiWusiXn5
k3hr1ahAtl/GQ+ciI+cewPY7u+edNeigb5Mqp+4kZAuGBTCcbGEH1ysar84ycnbC
Y+sK6rfLpjtBQrdxOLMXrJ6kOLi8if5JSOfkifwpPWBSoTgTpkBTqXqTRHrt3Jon
en0bs8TGauA9mVZrOrOHx0FuC5/OysZA+C14GVvwKq9PkGZA7b9tL9StUzTSJybc
0GXGXVPJQmr9/LgeR8Qg0ShPz2UL0n2NpEhiweTSz6D/iXTjX0LenenMv/zDJYk5
cAr5aBmebsjv+C86oZM/
Veja também: Construtor de resultados
Remoção de tags de âncoras e snippets
Adicionar Result Builders (Construtor de resultados) e selecionar a fonte na lista suspensa: $p1.serp.$i.anchor - Anchor. Selecionar o tipo: Remove HTML tags.
Adicionar novamente o Result Builders (Construtor de resultados) e selecionar a fonte na lista suspensa: $p1.serp.$i.snippet - Snippet. Selecionar o tipo: Remove HTML tags.
Baixar exemplo
Como imortar o exemplo no A-Parser
eJyVVD1v2zAQ/SsC4aEFBEMeumhzjLpp4cSp7UxGBlY6qawpkiUpN4bg/947mpaU
NAjQjby79+7rkR3z3B3cgwUH3rF83zETzixn2895/kXrWkKygUYfIbnd3a0Sz2uX
VFY3yVwVP7V1CVdlslXCGKJImeHWgSWy/YgDHSVUvJWepR3zJwOYAkmtFSU5RYl3
Y/XzyYK3AojpyGVLYbMsy9j5HRivodCt8gNm9k64FOrgDFiCjRDZ+ekpZdg91uiW
2jacpjAxs2kcSe/c8iPsNDorERq7YvB2zxtKOSm5B/JOq0D04ePUPxMDL0vhhVZc
XjLQmIasj0r8Dh0rjbF4pEEscdZo8hAIyHi6Vrdnk3BnSNEG7PcLhuUVlw5S5rDU
JcdCytce4cFyr+3aUD1o75hWcylXcAQ5hAX+m1bIEnc6rxD0NQLfDln/w3Hu2xun
wp38sVhDzxJuN+u7AVXqla6x8/IH9i1FIzze3SIsOmcZGg8App/ZPc2s0Rb6NJE5
ZkeRG1AkgGFlczOYXrTxYi0jY8ecbm2B+fZZumcodENbDS+BkX6i5mx4Mbe+keS2
lp/QGKM9SSdCSKZvMbrLe/ovyivmjJhCq0rU66j8azut2uFzX6uFbowEGr5qpUTt
ONgMGp67qBW6DFN8DV6EFLSf67vGMrR037aXeRorsKpPaSx8nDVSFlzKx81q7GGD
7oPmHdEW+JhqjTLHLqi5+MP0v1Y3/mfy7oza+eUeLkHUA4WgDYfhUBj0OfwFH/O5
UQ==
O Construtor de resultados pode ser adicionado quantas vezes você precisar.
Veja também: Construtor de resultados
Filtragem de links por ocorrência
Adicionar filtro e selecionar na lista suspensa: $serp.$i.link - Link. Selecionar o tipo: Contain string. Em seguida, no campo String, digite o critério de filtragem.
Baixar exemplo
Como imortar o exemplo no A-Parser
eJx9VE1v2kAQ/StoxSGVEIJDL74RVKpWNKSBnBCHDR5bG9Y72901DbL83zuzNrZJ
qtw8H+/Nm491JYL0J//owEPwItlXwsZvkYjttyT5jphrGK2UDuCUyUcvl5EP8UuZ
kVbmJCbCSufBMXo/AFEghUyWOohJJcLFAnHiGZxTKQdVSrZ1+HZxQIzgyXeWuuS0
+Ww2E/UnMJnDEUsTesz8k3TW6S04hg0QswEkix1SkLpnycleUE+WHLHJw6TN2DXp
RzRBKjOQPD1iQSbaoNCQ7cF4UR8OV0a/QldInuvYzqftkLvgVp5hh40O6N00d3iQ
BfOPUxmAo9MsEt19mYY3ZpBpqrim1E0F3kNf9dmoP1GfQcqlT570ypHWRASIBOy8
XNXtxTja3HEZsb8bjEgyqT1MhCepK0lC0vcRRfORAd0mzoD8lUCz0HoNZ9B9WuS/
L5VO6WgWGYF+tMD/p2w+cNRde8NStPS/jjR0LNG63/zqUSmuMafO05e42EIFsv0y
XlIiZuQ8AdhuZg88swIddGVa5rY6PRsLhi+sX9nC9q6bNm7Wcuuka8pUvmmv9ppZ
mh29zY1ZYmE1cF+m1JrW4uGpP4+Fb9fARi/wPXgZS3Dr1zcpAqL2P7eNVOsUnd9X
FljQJIdVW8qj1Pr5aT2MiP6k4jl5pj3SneZIF0Rd1Ifu79D9YqrhPyKpalrLq39s
krgHTiEfDcPHlzSv/wHtZp3U
Veja também: Filtros de resultados
Configurações possíveis
Parâmetros regionais
Google domain - o domínio do Google utilizado, por padrão google.com
Results language - busca de páginas no idioma selecionado; no navegador, isso corresponde à opção Pesquisa Avançada -> Configurações Adicionais -> Pesquisar em (parâmetro url lr). Por padrão, não definido, o que significa detecção automática baseada no IP
Spoiler: Captura de tela
Interface language - idioma dos produtos Google; no navegador, isso é Idiomas -> Idioma da interface (parâmetro url hl). Por padrão, o idioma inglês é selecionado
Spoiler: Captura de tela
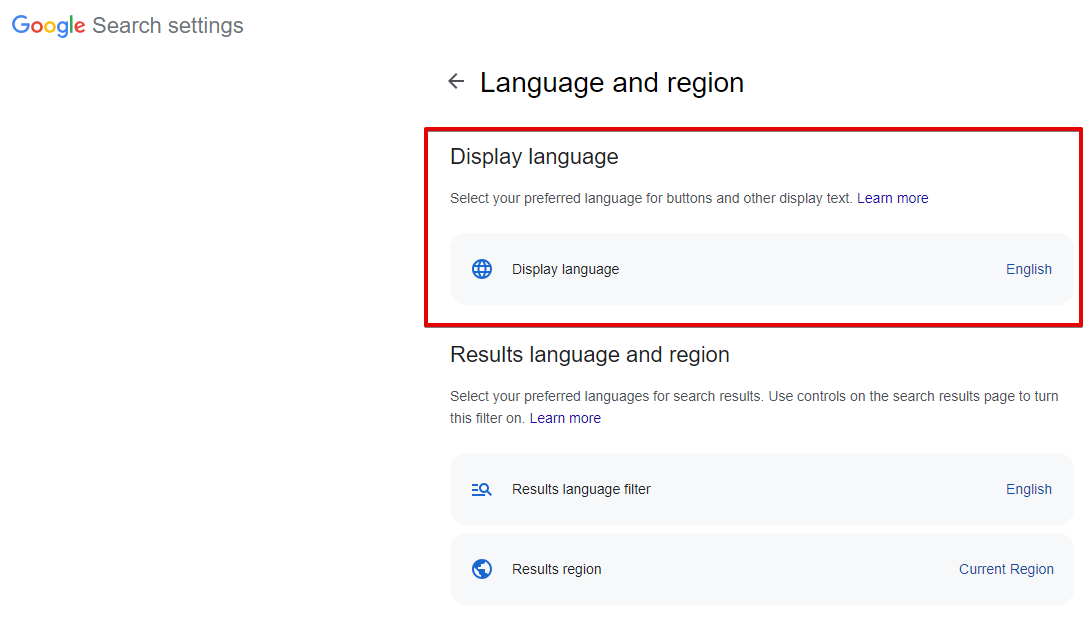
Search from country - escolha da região de busca; no navegador, isso é Idiomas -> Região de busca (parâmetro url gl). Por padrão, não definido, o que significa detecção automática baseada no IP
Spoiler: Captura de tela
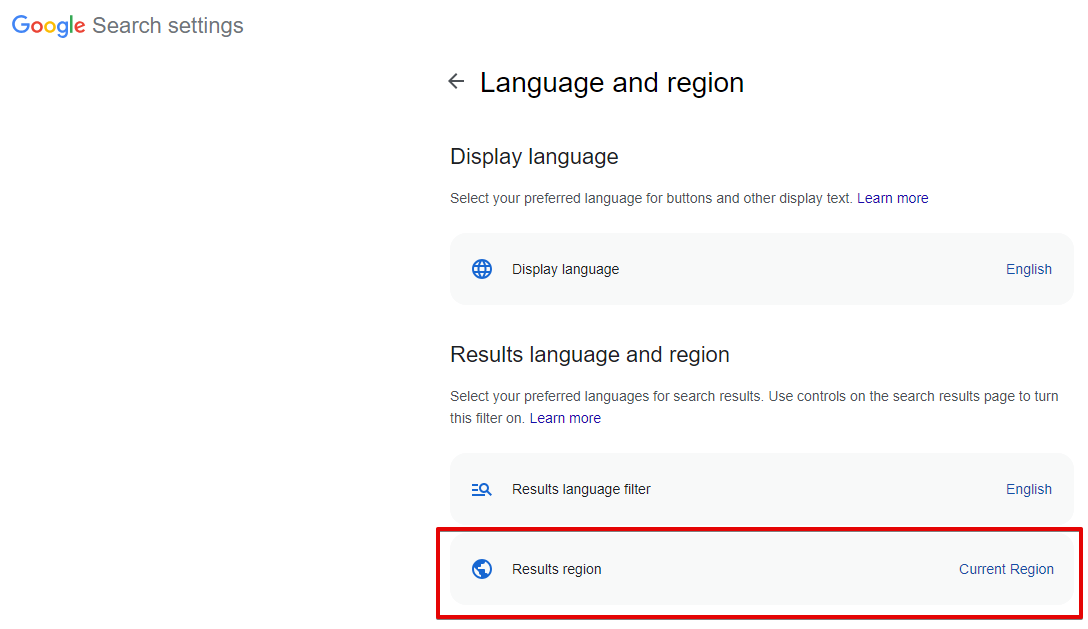
Narrow results by region - busca de páginas criadas em um país específico; no navegador, isso é Pesquisa Avançada -> Configurações Adicionais -> País (parâmetro url cr). Por padrão, não definido, o que significa que esta opção está desativada
Spoiler: Captura de tela
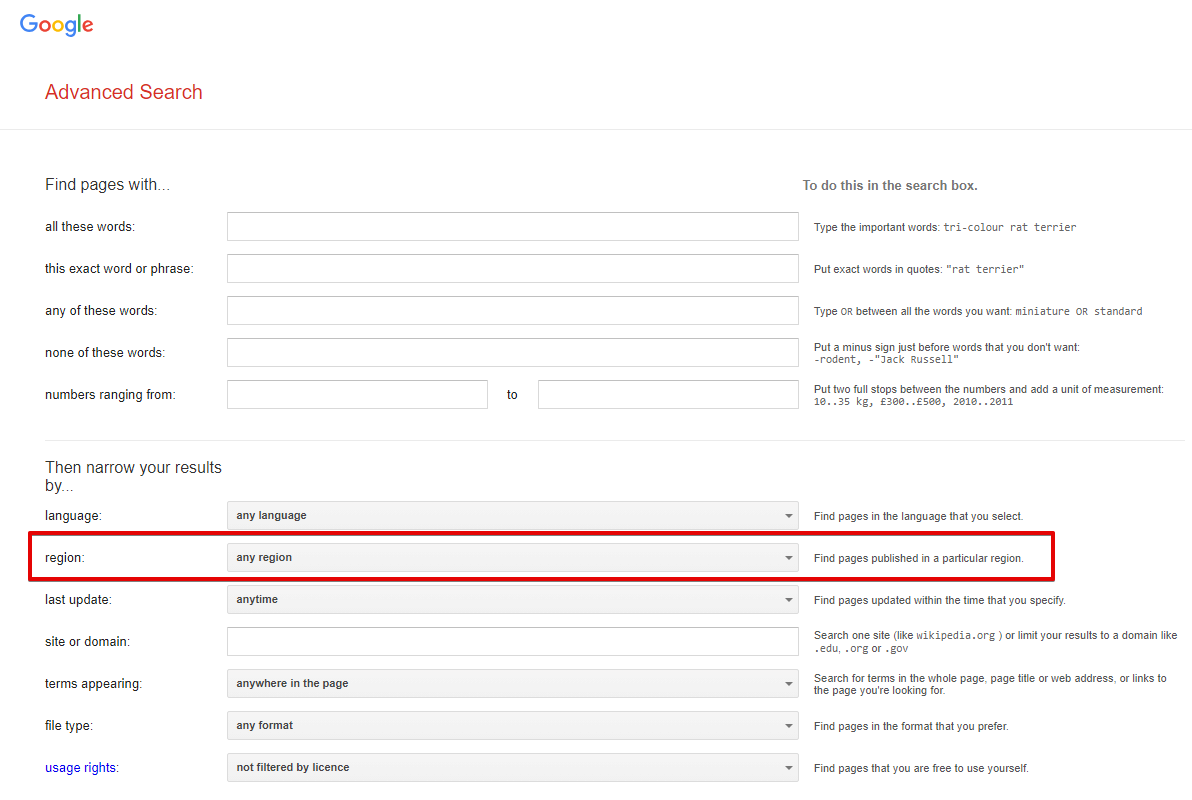
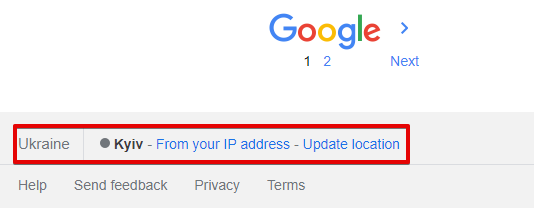
Location (city) - localização exata da busca; no navegador, é determinada automaticamente com base na localização do usuário. Por padrão, não definido, o que significa detecção automática baseada no IP da solicitação
Spoiler: Captura de tela
Todos os parâmetros regionais influenciam os resultados em maior ou menor grau.
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Device | Desktop | Escolha entre resultados para desktop ou móvel: Desktop / Mobile |
| Pages count | 5 | Número de páginas para extração de dados (de 1 a 100) |
| Parse pages links from first page | ☑ | Coleta links para todas as páginas de paginação disponíveis a partir da primeira página de resultados. Considerado apenas quando Device: Desktop; não funciona para resultados móveis |
| Serp type | Default (All) | Define se a extração de dados será da página principal, notícias ou blogs (Books, News, Videos) |
| Hide omitted results | ☑ | Define se deve ocultar resultados omitidos (parâmetro filter=) |
| Serp time | Anytime | Período do SERP (busca dependente do tempo, parâmetro tbs=, valores possíveis: Past 1 hour, Past 24 hours, Past week, Past month, Past year) |
| Parse not found | ☑ | Define se deve extrair dados se o Google informar que nada foi encontrado para a consulta e sugerir resultados para outra consulta |
| Disable autocorrect | ☐ | Permite desativar a autocorreção do Google e extrair dados exatamente para a consulta especificada |
| Exact match | ☐ | Corresponde à opção "Exact match" no buscador. Atenção, esta opção sobrescreve o valor do parâmetro Serp time (semelhante ao funcionamento dessas opções no navegador). |
| Safe search | Blur | Possibilidade de ativar o "Safe search" |
| Google domain | www.google.com | Domínio do Google para extração de dados; todos os domínios são suportados (www.google.ac, www.google.com.af, www.google.co.ck, etc.) |
| Narrow results by region | Any region | Possibilidade de restringir a busca a um país específico |
| Results language | Auto (Based on IP) | Escolha do idioma dos resultados (parâmetro lr=) |
| Search from country | Auto (Based on IP) | Escolha do país de onde a busca é realizada (busca geo-dependente, parâmetro gl=) |
| Interface language | English | Possibilidade de escolher o idioma da interface do Google, para máxima identidade entre os resultados no scraper e no navegador |
| Location (city) | Busca por cidade, região. Cidades podem ser indicadas como novosibirsk, russia; a lista completa de locais pode ser encontrada em Geotargets (cópia - deve-se usar o valor da coluna Canonical Name). Também é necessário definir o domínio correto do Google | |
| Util::ReCaptcha2 preset | default | Define se deve usar  Util::ReCaptcha2 para contornar recaptchas Util::ReCaptcha2 para contornar recaptchas |
| Util::AntiGate preset | default | Define se deve usar  Util::AntiGate para contornar captchas gráficos Util::AntiGate para contornar captchas gráficos |
| ReCaptcha2 retries | 3 | Número de tentativas de envio da resposta do recaptcha o número de vezes especificado, sem trocar o proxy |
| ReCaptcha2 pass proxy | ☐ | Permite passar o proxy (usado na solicitação ao Google) e os cookies (recebidos na resposta do Google) para o serviço de reconhecimento de ReCaptcha |
| Use sessions | ☑ | Salva sessões boas, o que permite extrair dados ainda mais rápido, obtendo menos erros. |
| Don't take session | ☐ | Possibilidade de não usar sessões boas salvas |
| Additional headers | Permite especificar quaisquer cabeçalhos personalizados | |
| PAA questions count | 0 | Quantidade máxima de perguntas e respostas (People also ask) por consulta que o scraper deve coletar |
| Empty totalcount is error | ☐ | Ao ativar este parâmetro, a consulta será considerada malsucedida se não houver valor para $totalcount, e consequentemente serão feitas novas tentativas |
| Count of retries when result is empty | 10 | Número de tentativas repetidas da consulta se a página de resultados estiver completamente vazia |
| Redirect browser max pages | 10 | Número de páginas do navegador usadas para contornar a proteção na forma de verificação de JavaScript ativado |
| Single redirect browser for task | ☑ | Se vários scrapers do Google forem especificados na tarefa — usar apenas um navegador para todas as sub-tarefas; o número máximo de páginas e outras configurações são obtidos do primeiro scraper do Google na tarefa |