Net::HTTP - Scraper de base universel avec support de la collecte de données multipage et contournement de CloudFlare
Présentation du scraper
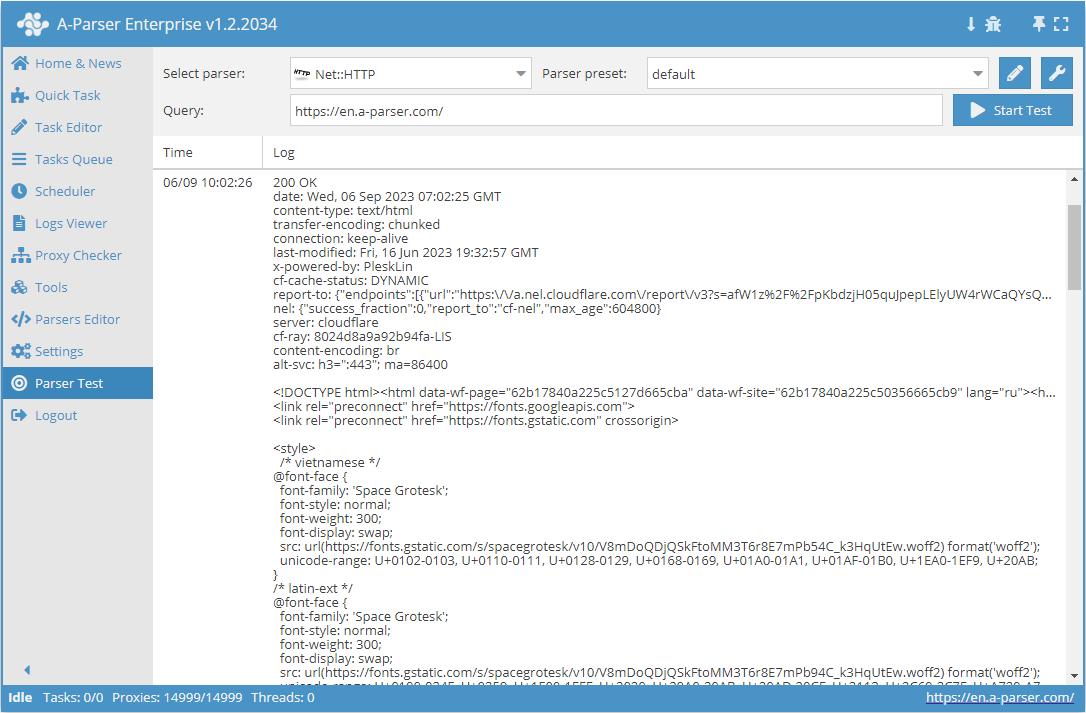
 Net::HTTP – est un scraper universel qui permet de résoudre la plupart des tâches non standard. Il peut être utilisé comme base pour la collecte de données de contenu arbitraire à partir de n'importe quel site. Il permet de télécharger le code de la page via un lien, prend en charge la collecte de données multipages (navigation entre les pages), la gestion automatique des proxys, et permet de vérifier la réussite de la réponse par le code ou par le contenu de la page.
Net::HTTP – est un scraper universel qui permet de résoudre la plupart des tâches non standard. Il peut être utilisé comme base pour la collecte de données de contenu arbitraire à partir de n'importe quel site. Il permet de télécharger le code de la page via un lien, prend en charge la collecte de données multipages (navigation entre les pages), la gestion automatique des proxys, et permet de vérifier la réussite de la réponse par le code ou par le contenu de la page.Cas d'utilisation du scraper
🔗 Enchères de domaines REG.RU
Collecte de données des enchères de domaines expirant avec possibilité de filtrage
🔗 Données du certificat SSL
Collecte de données du certificat SSL des domaines depuis le site leaderssl.ru
🔗 Collecte de données de la ressource Booking.com
Obtention des résultats de recherche d'appartements et d'hôtels sur le site
🔗 Collecte des caractéristiques du produit
Exemple de collecte de données d'un nombre inconnu de caractéristiques de produit
🔗 Collecte de données de la base de films IMDB
Récupère les données de chaque film et les enregistre dans le résultat
🔗 Vérification de la présence de HTTPS
Le préréglage vérifie la présence de HTTPS sur le site
Données collectées
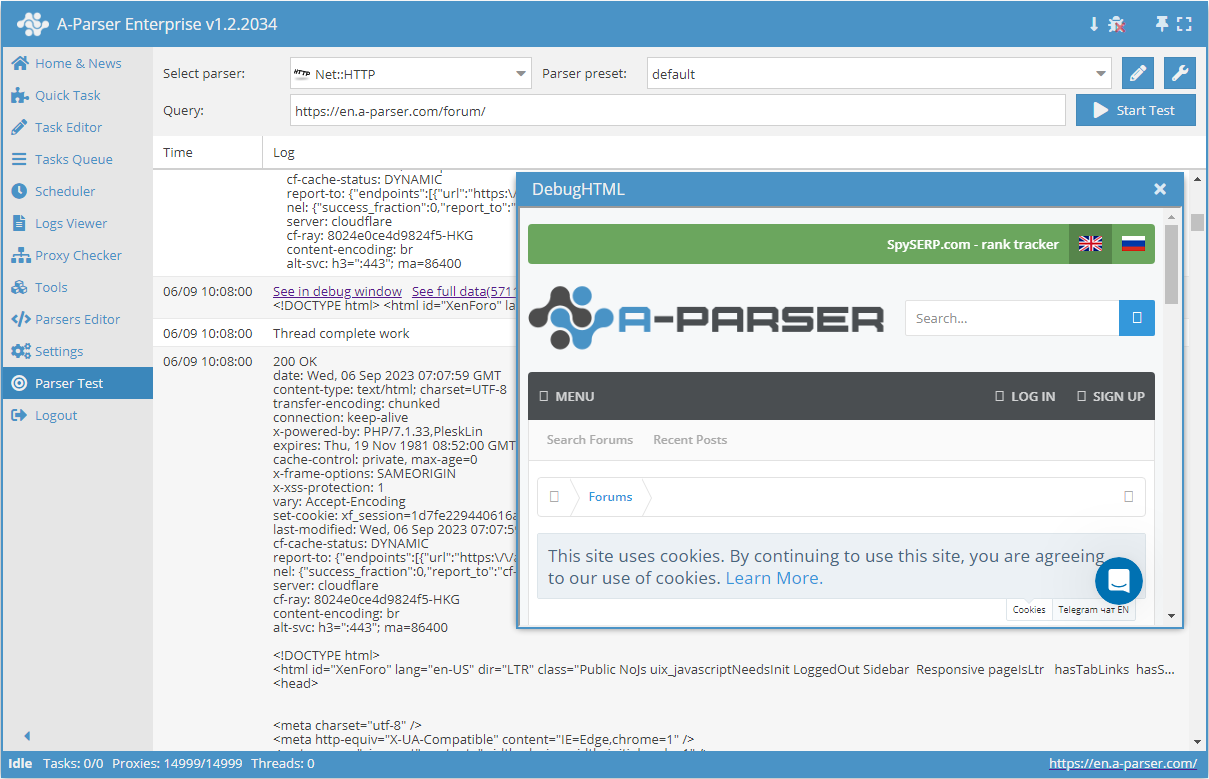
- Contenu
- Code de réponse du serveur
- Description de la réponse du serveur
- En-têtes de réponse du serveur
- Proxy utilisés lors de la requête
- Tableau avec toutes les pages collectées (utilisé avec l'option Use Pages)
Fonctionnalités
- Collecte de données multipages (navigation par pages)
- Gestion automatique des proxies
- Vérification de la réussite de la réponse par code ou par contenu de page
- Supporte les compressions gzip/deflate/brotli
- Détection et conversion des encodages de sites en UTF-8
- Contournement de la protection CloudFlare
- Choix du moteur (HTTP ou Chrome)
- Option Check content – exécute l'expression régulière indiquée sur la page obtenue. Si l'expression ne correspond pas, la page sera rechargée avec un autre proxy.
- Option Use Pages – permet de parcourir un nombre spécifié de pages avec un pas défini. La variable
$pagenumcontient le numéro de page actuel lors du parcours. - Option Check next page – nécessite d'indiquer une expression régulière qui extraira le lien vers la page suivante (généralement le bouton "Suivant"), s'il existe. La navigation entre les pages s'effectue dans la limite indiquée (0 - sans limite).
- Option Page as new query – le passage à la page suivante se fait dans une nouvelle requête. Permet de supprimer la limite du nombre de pages pour la navigation.
Variantes d'utilisation
- Téléchargement de contenu
- Téléchargement d'images
- Vérification du code de réponse du serveur
- Vérification de la présence de HTTPS
- Vérification de la présence de redirections
- Affichage de la liste des URL de redirection
- Obtention de la taille de la page
- Collecte de balises méta
- Extraction de données du code source de la page et/ou des en-têtes
Requêtes
En tant que requêtes, il est nécessaire d'indiquer les liens vers les pages, par exemple :
http://lenta.ru/
http://a-parser.com/pages/reviews/
Variantes d'affichage des résultats
A-Parser supporte un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous forme libre, ainsi que sous forme structurée, par exemple CSV ou JSON
Affichage du contenu
Format du résultat :
$data
Exemple de résultat :
<!DOCTYPE html><html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<!-- Google Tag Manager -->
<!-- End Google Tag Manager -->
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<base href="https://a-parser.com/" />
<title>A-Parser - scraper pour les professionnels du SEO</title>
<noscript><style>.JsOnly, .jsOnly { display: none !important; }</style></noscript>
<link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" />
Code de réponse du serveur
Format du résultat :
$code
Exemple de résultat :
200
Le format de résultat [% response.Redirects.0.Status || code %] permet d'afficher le statut 301 si des redirections sont présentes dans la requête.
Obtention des données sur la requête
La variable $response aide à obtenir des informations sur la requête et la réponse du serveur
Format du résultat :
$response.json\n
Exemple de résultat :
{
"Time": 3.414,
"connection": "keep-alive",
"Decode": "Decode from utf-8(meta charset)",
"cache-control": "max-age=3600,public",
"last-modified": "Tue, 18 May 2021 12:42:56 GMT",
"transfer-encoding": "chunked",
"date": "Thu, 27 May 2021 14:18:42 GMT",
"Status": 200,
"content-encoding": "gzip",
"Body-Length-Decoded": 1507378,
"Reason": "OK",
"Proxy": "http://51.255.55.144:25302",
"content-type": "text/html",
"Redirects": [],
"server": "nginx",
"Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n",
"URI": "https://a-parser.com/",
"HTTPVersion": "1.1",
"Body-Length": 299312,
"Decode-Mode": "auto-html",
"etag": "W/\"60a3b650-170032\"",
"Decode-Time": 0.003,
"IP": "remote",
"expires": "Thu, 27 May 2021 15:18:42 GMT"
}
Obtention des redirections
Requête :
https://google.it
Format du résultat :
$response.Redirects.0.URI -> $response.URI
Exemple de résultat :
https://google.it/ -> https://www.google.it/
JSON avec redirections
Format du résultat :
$response.Redirects.json
Exemple de résultat :
[{"x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n"}]
Affichage du statut de réponse du serveur
Format du résultat :
$reason
Exemple de résultat :
OK
Temps de réponse du serveur
Format du résultat :
$response.Time
Exemple de résultat :
1.457
Obtention de la taille de la page
À titre d'exemple, la taille est présentée sous trois variantes différentes.
Format du résultat :
[% "data-length: " _ data.length _ "\n";
"Body-Length: " _ response.${'Body-Length'} _ "\n";
"Body-Length-Decoded: " _ response.${'Body-Length-Decoded'} _ "\n" %]
Exemple de résultat :
data-length: 70257
Body-Length: 23167
Body-Length-Decoded: 75868
Traitement des résultats
A-Parser permet de traiter les résultats directement pendant la collecte de données, dans cette section nous avons présenté les cas les plus populaires pour le scraper Net::HTTP
Affichage des titres H1-H6
Ajouter une expression régulière (option Parse custom results (Parse custom result) (Utiliser une regex)) <(h\d+)[^>]+>(.+?)<\/h\d+>, dans le champ "Parse result" choisir $pages.$i.data - Page content, dans le champ en face de la regex choisir les modificateurs sg. Un tableau sera automatiquement sélectionné comme type de résultat. Dans le champ "Name" indiquer headers, puis dans "$1 to" indiquer tag, cliquer sur le

content. Dans le format de résultat général, inscrire la sortie $p1.headers.format('$tag - $content\n').Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJxtVNuO2jAQ/RVkIS2IW3loH6IVFYuK2ooSlmWfIJUsMgR3HTu1HboI8e+dcUIC
tE+Jj+ccn7nYJ+a4fbMLAxacZcH6xDL/zwI2BxcEX1erRWOrpYStEypp7Ie9/SfW
ZRk3Fgwx1nUg4jHseC4d656YO2aAMtvcOp0uwXqYmeInWKNEApYo3HEW0U4C70h4
bO03m7jTXv8cRZ1Rq9/53H7cbAYeHLEyblWI26SSLBFuDD8i6L9znhK2Bx6T2Uso
2cbEibvVyoFyLDpHUbU91SblVIJmNuyX5P7Og62HJhIbvUazZG426qFdK7/wA6w0
UndCQg1PcVWaaWK+QLsXxXbfvVNleBwLJ7TisjifXNaeXpX4nRNfaYzFXyPATo1O
EXLgBQg8XryvWdOvqbK55z4XHBbsuLTQZRatTjkaie93hAPDnTZhRn4QPzGtxlLO
4ACyDvP6T7mQVJ/xDknfSuL/Q8J/NM5VetdHHcD8MeihUvGrp/BHzYr1TCeXYkiR
CodrO9G5orZ9QPANIKtqNqewVBuojimVy9Nx/jNQMUbWLRtnNXSTxk1bbkGciZ1I
QkzAiBgukbla4SUL1USnmQTKS+VSYlssLOvxGNuyDbSoDd6TJ/4ItFXdNOa0lvb7
S2E1MwLH7yMZTLGS16eWklsu5etydr1DRLylWai+GHPXPj8YbO9cZoPBgPeKm9/f
6nRA9weHOdE4ZpjqOarehepBOV29DsHpjK37ZRdFDOVJEYhhwSz2hQXD81+VjpX2
Collecte de balises méta
Ajouter une regex (option Parse custom results (Parse custom result) (Utiliser une regex)) (<meta[^>]+>), dans le champ "Parse result" choisir $pages.$i.data - Page content, dans le champ en face de la regex choisir le modificateur g. Le type de résultat sera automatiquement choisi comme tableau. Dans le champ "Name" indiquer meta, dans "$1 to" indiquer item. Dans le Format du résultat utiliser $p1.meta.format('$item\n').
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB
bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj
3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm
Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z
Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL
SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9
iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK
zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY
rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF
Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY
i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1
gDE=
Variantes de parcours de la pagination
Utilisation de Use pages
Use pages. Cette fonction permet de parcourir la pagination en indiquant à l'avance un nombre connu de pages.
Pour l'exemple, prenons l'une des catégories sur le site d'un catalogue de produits https://www.proball.ru/catalog/myachi/. En haut et en bas, nous voyons un panneau de pagination. En cliquant sur les icônes avec les numéros de pages, on peut voir dans la barre du navigateur comment s'effectue la transmission du paramètre avec le numéro de page à la fin de la requête :
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
Use pages est une sorte de compteur qui substitue en fait dans la variable $pagenum les numéros dans l'ordre, en les augmentant de la valeur que nous indiquons
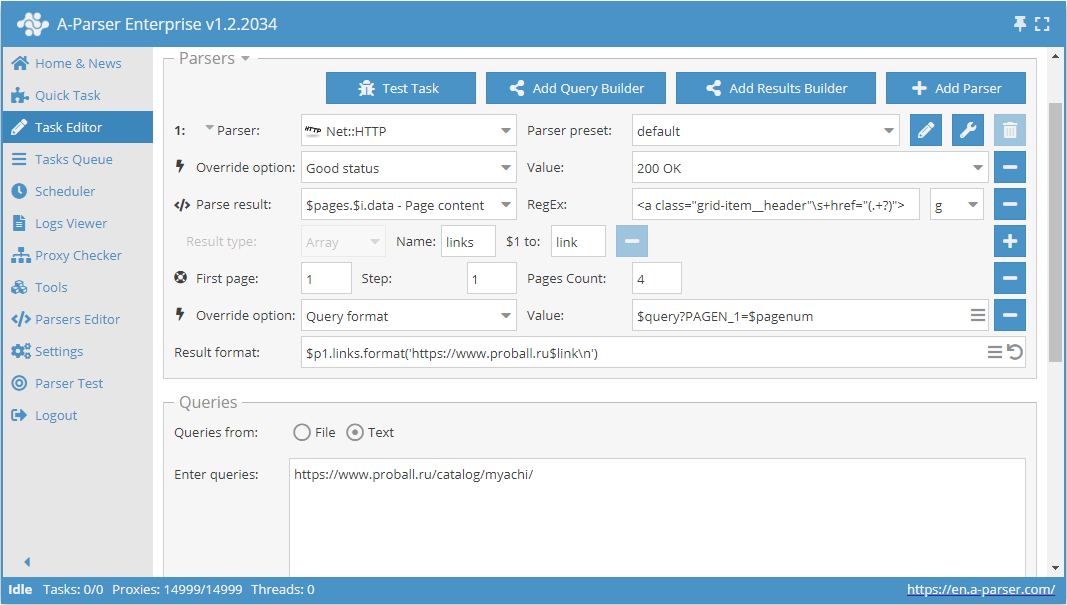
Comme on le voit sur la capture d'écran, dans le format de requête du scraper, la variable $pagenum est utilisée à l'endroit approprié.
La fonction Use pages parcourra et substituera dans la requête toutes les valeurs, nous obtiendrons en fait des liens pour la requête
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum
où à la place de la variable $pagenum sera substitué le numéro de page, commençant de 1 jusqu'à 4 avec un pas de 1.
Ainsi, on obtient un parcours des pages de la plage souhaitée. C'est là que réside la limite de cette méthode - il faut connaître à l'avance le nombre de pages présentes dans la pagination. Il est évident que lors de la collecte de données simultanée de plusieurs catégories, le nombre de pages sera partout différent, et comme solution, nous pouvons simplement indiquer un plus grand nombre de pages supposées. Mais ce n'est pas tout à fait correct, c'est pourquoi il existe une solution plus optimale dont il sera question plus loin
Télécharger l'exemple
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2
pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn
PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0
9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+
1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh
9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob
jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4
YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5
QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u
kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp
sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9
P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8
z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M
vOJ4VZ5BGJXHUBcgGBZ/AXULzRU=
Utilisation de Check next page
Check next page est une autre fonction qui permet d'organiser le parcours de la pagination. La particularité de son utilisation réside dans le fait que pour passer à la page suivante, il faut utiliser une expression régulière qui retournera le lien vers la page suivante. C'est une méthode plus pratique et la plus fréquemment utilisée. Mais il ne sera pas possible de l'appliquer pour https://www.proball.ru/catalog/myachi/, car il n'y a pas de liens vers les pages suivantes dans le code. Les liens y sont générés par script. Par conséquent, prenons comme exemple le site http://www.imdb.com/search/name?gender=female. Ici, il y a une pagination au début comme à la fin de la liste. En regardant et en analysant le code source, on peut voir la présence d'un lien qui permet de passer à la page suivante :
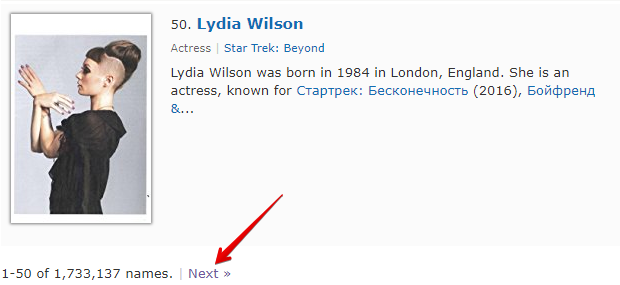
- dans le champ Next page RegEx, nous inscrirons l'expression régulière
- dans le champ Limit (Limite), nous indiquerons le nombre de pages à parcourir
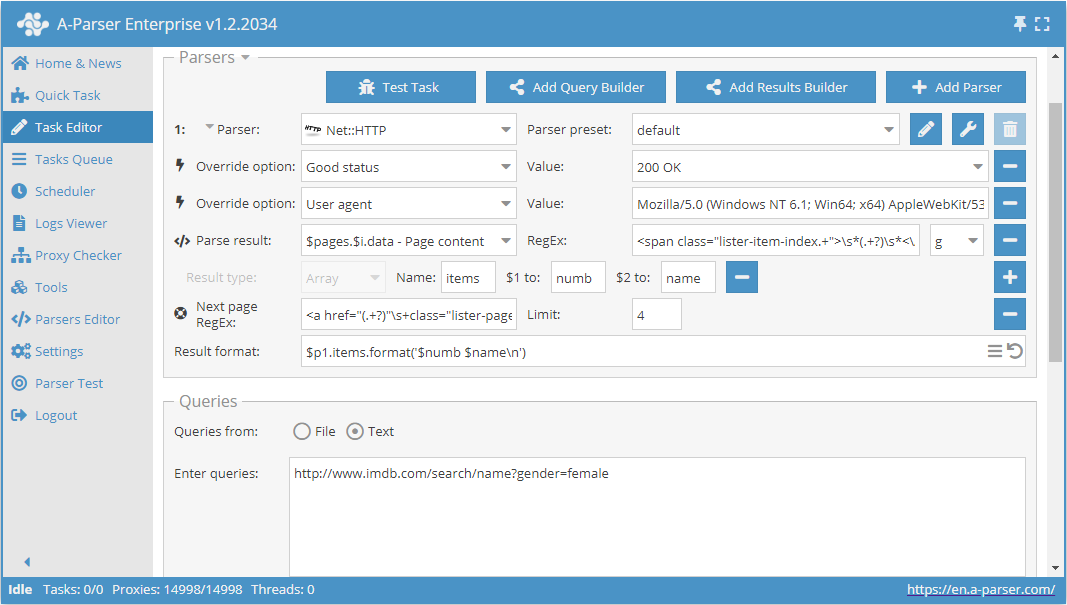
Dans l'exemple, 4 est indiqué. En indiquant une limite, nous déterminons combien de pages le scraper doit parcourir. Dans notre cas, 5 pages seront parcourues, car le décompte commence à 0. Si on indique une limite de 0, le scraper travaillera jusqu'à ce qu'il ait parcouru toutes les pages, quel que soit leur nombre. C'est très pratique à utiliser lorsqu'il faut parser tous les résultats de toutes les pages
Télécharger l'exemple
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS
sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr
gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp
ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I
22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY
FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI
HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu
NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O
MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7
exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x
+JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L
itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy
KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18
bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq
iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU
tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY
11r9ASIaBUM=
Comme mentionné plus haut, il est possible de limiter dynamiquement le nombre de pages dans Use pages. Pour cela, il faut utiliser conjointement Use pages et Check next page. Complétons l'exemple qui a été examiné lors de la description de Use pages et ajoutons-y la fonction Check next page :
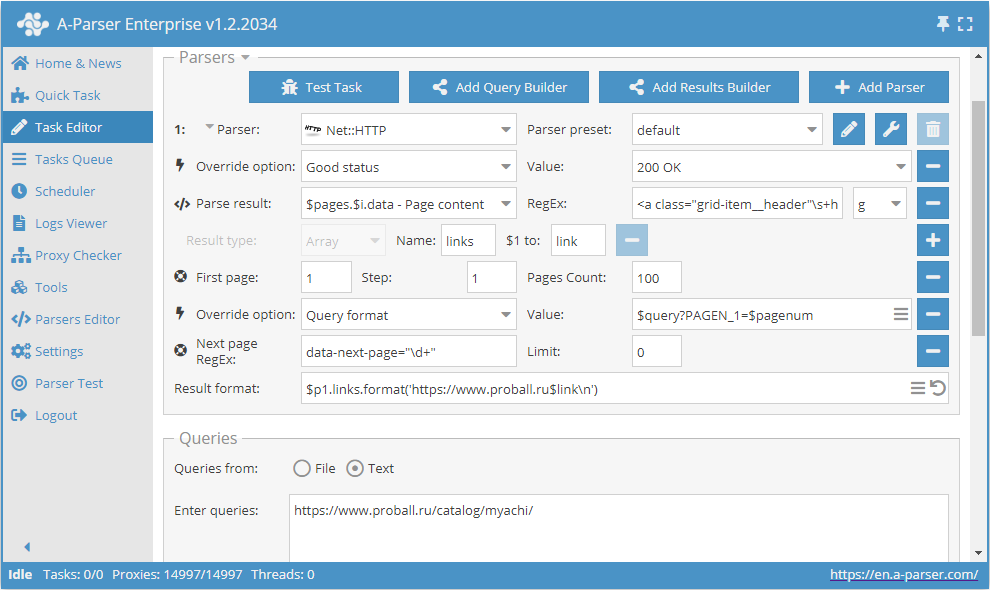
Ces deux fonctions travaillent en paire de la manière suivante : Use pages assure le parcours des pages, et Check next page vérifie si la suivante existe. Dès que Check next page ne trouve pas de page suivante, la collecte de données de cette catégorie sera arrêtée, sans attendre le parcours de toute la quantité indiquée dans Use pages. En combinant ces fonctions, nous ajoutons de l'efficacité au travail du scraper, économisant du temps et des ressources
Télécharger l'exemple
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF
XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG
eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY
LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve
u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals
SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8
Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g
45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa
eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS
mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x
GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ
NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ
EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0
0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g
KP8Byg3yDQ==
Utilisation des macros de substitution
Les macros de substitution permettent de réaliser une substitution séquentielle de valeurs à partir d'une plage spécifiée
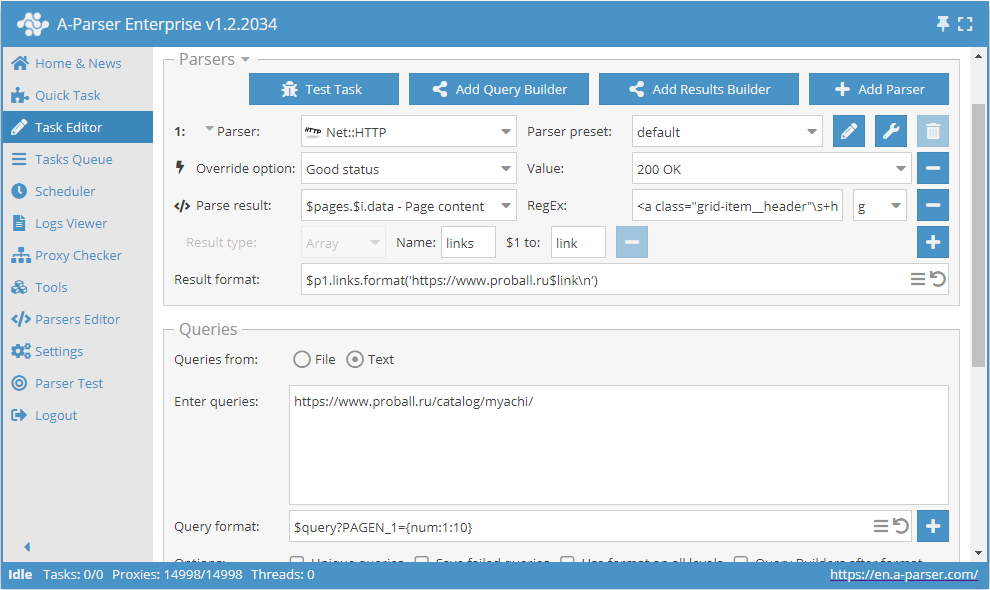
Ce préréglage fonctionnera de la manière suivante. En indiquant dans le format de requête le gabarit :
$query?PAGEN_1={num:1:10}
nous ajoutons la substitution des valeurs de 1 before 10 (on peut indiquer n'importe quelle plage) dans la requête elle-même. Ainsi, nous obtenons des requêtes qui assurent le parcours du nombre de pages souhaité, du type :
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
https://www.proball.ru/catalog/myachi/?PAGEN_1=2
...
https://www.proball.ru/catalog/myachi/?PAGEN_1=10
L'utilisation des macros de substitution pour le parcours de la pagination ressemble à la fonction Use pages et possède les mêmes limites, c'est-à-dire qu'il faut indiquer une plage de valeurs concrète. L'avantage de cette méthode est que via les macros de substitution, on peut substituer différentes valeurs, aussi bien numériques que textuelles, par exemple des mots ou des expressions. Ainsi, nous pouvons insérer de manière plus flexible les parties nécessaires dans les requêtes ou former les requêtes elles-mêmes à partir de parties qui seront placées dans différents fichiers, si la tâche l'exige
Télécharger l'exemple
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a
AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix
JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi
Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6
OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ
IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC
4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv
nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk
vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke
AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa
F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q
MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU
1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg==
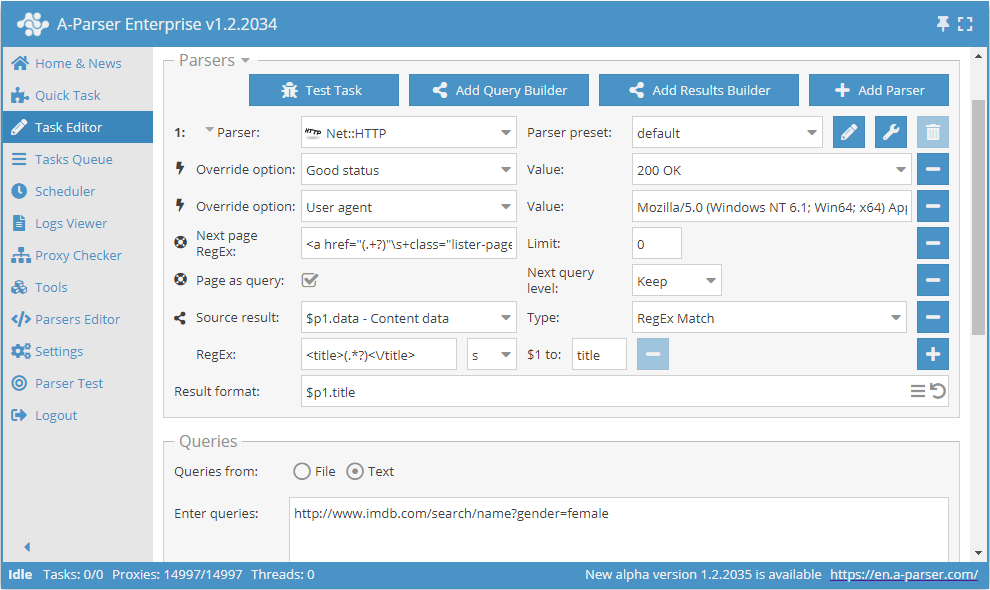
Utilisation de Page as query
Pour réduire la consommation de mémoire, la logique peut être définie à l'aide de l'option Page as query. Lors de son activation, les fonctions Check next page et Use pages substitueront chaque page suivante dans les requêtes comme une requête indépendante à part entière, évitant ainsi d'accumuler leur contenu en mémoire. Page as query permet également de définir s'il faut augmenter le niveau de la requête Increase (analogue au fonctionnement de l'outil tools.query.add), ou non Keep
Télécharger l'exemple
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM
tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA
DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z
ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv
dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i
pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr
mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa
VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1
Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl
CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa
lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0
ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn
5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob
7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD
yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj
geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8=
Paramètres possibles
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Good status | All | Choix de la réponse du serveur qui sera considérée comme réussie. Si lors de la collecte de données il y a une autre réponse du serveur, la requête sera répétée avec un autre proxy |
| Good code RegEx | Possibilité d'indiquer une expression régulière pour vérifier le code de réponse | |
| Ban Proxy Code RegEx | Possibilité de bannir le proxy pour un certain temps (Proxy ban time) sur la base du code de réponse du serveur | |
| Method | GET | Méthode de requête |
| POST body | Contenu à transmettre au serveur lors de l'utilisation de la méthode POST. Supporte les variables $query – URL de la requête, $query.orig – requête initiale et $pagenum - numéro de page lors de l'utilisation de l'option Use Pages. | |
| Cookies | Possibilité d'indiquer des cookies pour la requête. | |
| User agent | _Le user-agent de la version actuelle de Chrome est automatiquement substitué_ | En-tête User-Agent lors de la requête des pages |
| Additional headers | Possibilité d'indiquer des en-têtes de requête personnalisés avec le support des fonctionnalités du moteur de gabarit et l'utilisation de variables du constructeur de requêtes | |
| Read only headers | ☐ | Lire uniquement les en-têtes. Dans certains cas, cela permet d'économiser du trafic s'il n'est pas nécessaire de traiter le contenu |
| Detect charset on content | ☐ | Reconnaître l'encodage sur la base du contenu de la page |
| Emulate browser headers | ☑ | Émuler les en-têtes du navigateur |
| Max redirects count | 7 | Nombre maximal de redirections que le scraper suivra |
| Follow common redirects | ☑ | Permet de faire des redirections http <-> https et www.domain <-> domain au sein d'un même domaine en contournant la limite Max redirects count |
| Max cookies count | 16 | Nombre maximal de cookies à conserver |
| Engine | HTTP (Fast, JavaScript Disabled) | Permet de choisir le moteur HTTP (plus rapide, sans JavaScript) ou Chrome (plus lent, JavaScript activé) |
| Chrome Headless | ☐ | Si l'option est activée, le navigateur ne sera pas affiché |
| Chrome DevTools | ☐ | Permet d'utiliser les outils de débogage de Chromium |
| Chrome Log Proxy connections | ☐ | Si l'option est activée, les informations sur les connexions chrome seront affichées dans le log |
| Chrome Wait Until | networkidle2 | Détermine quand la page est considérée comme chargée. En savoir plus sur les valeurs. |
| Use HTTP/2 transport | ☐ | Détermine s'il faut utiliser HTTP/2 au lieu de HTTP/1.1. Certains sites bannissent immédiatement si on utilise HTTP/1.1, et d'autres au contraire ne fonctionnent pas en HTTP/2. |
| Try use HTTP/1.1 for Protocol error | ☑ | Indique au scraper de répéter la requête avec HTTP/1.1 si HTTP/2 était activé et qu'une erreur de protocole a été reçue (c'est-à-dire si le site ne fonctionne pas en HTTP/2) |
| Don't verify TLS certs | ☐ | Désactivation de la validation des certificats TLS |
| Randomize TLS Fingerprint | ☐ | Cette option permet de contourner le bannissement des sites par empreinte TLS |
| Bypass CloudFlare with Chrome | ☐ | Contournement automatique de la vérification CloudFlare |
| Bypass CloudFlare with Chrome Max Pages | 20 | Nombre max. de pages lors du contournement de CF via Chrome |
| Bypass CloudFlare with Chrome Headless | ☑ | Si l'option est activée, le navigateur ne sera pas affiché pendant le contournement de CF via Chrome |